高周波取引戦略について考える (5)
作者: リン・ハーンリディア, 作成日:2023-08-10 15:57:27, 更新日:2023-09-12 15:51:54
高周波取引戦略について考える (5)
前回の記事では,中間価格を計算するための様々な方法が紹介され,修正された中間価格が提案されました.この記事では,このテーマを深く探します.
必要なデータ
オーダーブック上位10レベルのオーダーフローデータと深度データが必要です. 100msの更新頻度でライブ取引から収集されています. 単純化のために,オードとオード価格のリアルタイム更新は含まれません. データサイズを減らすために,深度データの100,000行だけ保持し,ティック・バイ・ティック市場データを個々の列に分割しました.
[1] において
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
[2] において
tick_size = 0.0001
[3] において
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
[4] において
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
[5] において
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
[6] において
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
[7]:
depths = depths.iloc[:100000]
[8] で:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
[9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
[10] で:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
[11] で:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
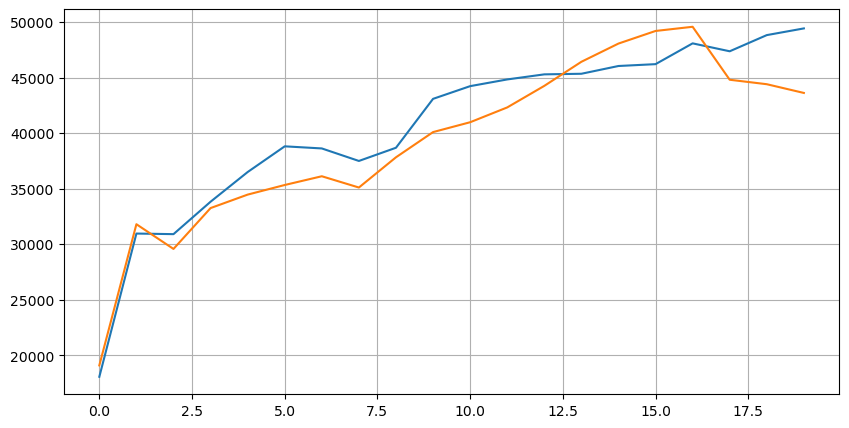
この20レベルにおける市場の分布を見てみましょう. 予想通りです. 市場価格から遠ければ遠ければ遠ければ遠くなるほど,より多くの注文が表示されます. さらに,購入注文と販売注文はほぼ対称です.
[14] では:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
アウト[14]:
予測精度評価を容易にするため,深度データをトランザクションデータと統合する.トランザクションデータが深度データよりも遅れていることを確認する.遅延を考慮せずに,予測値と実際のトランザクション価格の間の平均二乗誤差を直接計算する.これは予測の精度を測定するために使用されます.
結果から, bid と ask 価格 (mid_price) の平均値ではエラーが最大である.しかし,重量化された mid_price に変更すると,エラーはすぐに大幅に減少する.調整された重量化された mid_price を使用することでさらなる改善が観察される.I^3/2のみを使用したフィードバックを受け取った後,それは確認され,結果がより良いことが判明した.反省すると,これはイベントの異なる周波数による可能性が高い.I が -1 と 1 に近いとき,低確率イベントを表す.これらの低確率イベントの修正のために,高頻度のイベントを予測する精度は損なわれる.したがって,高頻度のイベントを優先するために,いくつかの調整が行われた (これらのパラメータは純粋に試行錯誤であり,実用的な意味が限られており,ライブ取引において限られている).
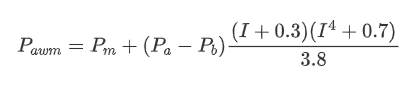
結果はわずかに改善した.前回の記事で述べたように,戦略は予測のためにより多くのデータに依存すべきである.より深いデータとオーダートランザクションデータが利用可能であるため,オーダーブックに焦点を当てることで得られる改善はすでに弱である.
[15] について
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
[17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
[18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
アウト[18]:
平均値 中間値の誤り: 0.0048751924999999845 待機中のオーダーボリュームのミッド_プライス重量化エラー: 0.0048373440193987035 調整されたミッド_価格のエラー: 0.004803654771638586 調整された中値の誤り: 0.004808216498329721 調整された中値の誤り: 0.004794984755260528 調整された中値の誤り: 0.0047909595497071375
深い こと の 二つ の レベル を 考え て ください
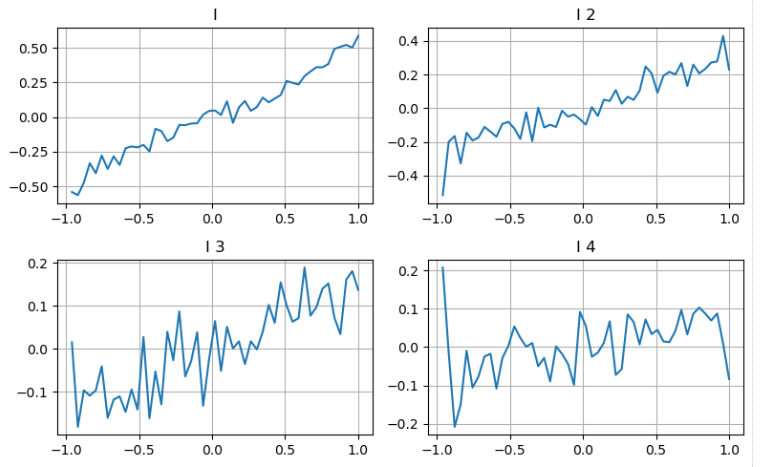
前回の記事からのアプローチに従って,パラメータの異なる範囲を調査し,取引価格の変化に基づいて,そのミッド_価格への貢献を測定することができます.最初の深度レベルと同様に,Iが増加すると,取引価格が増加する可能性が高く,Iからのポジティブな貢献を示します.
2度目の深さレベルにも同じアプローチを適用すると,その効果が1度目のレベルよりもわずかに小さいが,それでも重要であり,無視すべきではないことが判明する. 3度目の深さレベルも弱い貢献を示しているが,単調性が少ない.より深い深さは基準値がほとんどない.
異なる貢献に基づいて,これらの3つのレベルの不均衡パラメータに異なる重みを割り当てます.異なる計算方法を調べることで,予測誤差のさらなる減少を観察します.
[19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
アウト[19]:
[20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
[21]では:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
アウト[21]:
調整された中値の誤り: 0.0047909595497071375 調整された中値の誤り: 0.0047884350488318714 調整された中値の誤り: 0.0047778319053133735 調整された中値の誤り: 0.004773578540592192 調整された中値の誤り: 0.004771415189297518
トランザクションデータを考慮する
トランザクションデータは,ロングとショートポジションの範囲を直接反映しています.結局,トランザクションには実際のお金が含まれていますが,オーダーを出すにはコストがはるかに低く,意図的な欺瞞さえ含まれます.したがって,ミッド_プライスを予測する際に,戦略はトランザクションデータに焦点を当てなければなりません.
形式的には,平均注文到着量の不均衡を VI と定義できます. Vb と Vs は,単位時間間隔内の平均購入注文と販売注文を表します.
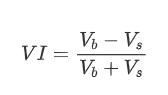
結果は,短期間の到着量が価格変化予測に最も有意な影響を及ぼすことを示している.VIが0.1から0.9の間であるとき,それは価格と否定的に相関し,この範囲の外では価格と肯定的に相関する.これは,市場は極端ではなく,主に振動しているとき,価格は平均値に戻る傾向があることを示唆している.しかし,極端な市場状況では,例えば大量の購入注文が売り注文を圧倒する時,傾向が現れる.これらの低い確率シナリオを考慮せずに,傾向とVIの間の負の線形関係を仮定しても,ミッド_価格の予測誤差を大幅に減少させる.係数
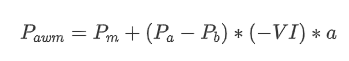
[22]:
alpha=0.1
[23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
[24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
[25]では:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
[26] で:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
[27]:
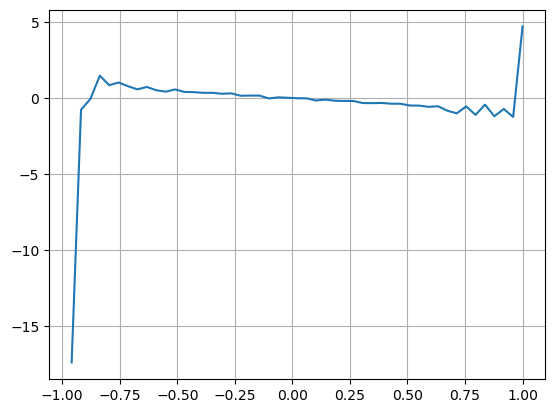
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
アウト[27]:
[28]では:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
[29]では:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
出場[29]:
調整されたミッド_価格のエラー: 0.0048373440193987035 調整されたミッド_プライス_9のエラー: 0.004629586542840461 調整された中値_10の誤り: 0.004401790287167206
総合 的 中間 価格
オーダーブック不均衡とトランザクションデータの両方が,ミッド_価格を予測するのに役立つことを考慮すると,これらの2つのパラメータを組み合わせることができます.この場合の重度の割り当ては任意で,境界条件を考慮しない.極端な場合,予測されたミッド_価格がオファーとオファー価格の間に落ちない可能性があります.しかし,予測誤差が軽減できる限り,これらの詳細は大きな懸念はありません.
最終的には,予測誤差が 0.00487 から 0.0043 に減少します.この時点で,我々はその話題に深く触れないでしょう.それは本質的に価格そのものを予測しているため,ミッド_価格を予測する際には,まだ多くの側面を探求する必要があります.誰もが独自のアプローチと技術を実験することをお勧めします.
[30]では:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
[31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
アウト[31]:
調整された中値_11の誤り: 0.0043001941412563575
概要
この記事では,深度データと取引データを組み合わせ,中間価格の計算方法をさらに改善する.正確さを測定する方法を提供し,価格変化予測の正確性を向上させる.全体として,パラメータは厳格ではなく,参照のみである.より正確な中間価格で,次のステップは,実用的なアプリケーションで中間価格を使用してバックテストを行うことである.この内容の部分は広範であるため,更新はしばらくの間一時停止する.