ニューラルネットワークとデジタル通貨量的な取引シリーズ (2) - 密集的な学習とトレーニング ビットコイン取引戦略
作者: リン・ハーンリディア, 作成日:2023-01-12 16:49:09, 更新日:2023-09-20 10:07:39
ニューラルネットワークとデジタル通貨量的な取引シリーズ (2) - 密集的な学習とトレーニング ビットコイン取引戦略
1. 序言
前回の記事では,ビットコインの価格を予測するために LSTM ネットワークの使用を紹介しました.https://www.fmz.com/bbs-topic/9879この記事では,RNNとpytorchを直接トレーニングするための小型トレーニングプロジェクトである.この記事では,トレード戦略を直接訓練するための集中学習の使用を紹介します.集中学習モデルはOpenAIオープンソースのPPOであり,環境はジムのスタイルを指します.理解とテストを促進するために,LSTMのPPOモデルとバックテストのためのジムの環境は,準備済みのパッケージを使用せずに直接書かれています. PPO (Proximal Policy Optimization) は,ポリシーグラディエントの最適化改良である.gymは,OpenAIによってリリースされた.戦略ネットワークと相互作用し,現在の環境の状態と報酬をフィードバックすることができます.これは集中学習の実践のようなものです.それは,LSTMのPPOモデルを使用して,ビットコインの市場情報に従って直接購入,販売または操作しないなどの指示を作成します.フィードバックはバックテスト環境によって与えられます.トレーニングを通じて,モデルは戦略的利益の目標を達成するために継続的に最適化されます. この記事を読むには,Python,pytorch,DRLの深層集中学習の基礎が必要です. しかし,それができないかどうかは問題ではありません. この記事で示したコードで学習し始めることは簡単です. このチュートリアルはFMZ Quant Tradingプラットフォームによって作成されています (www.fmz.com) QQグループに参加してください: 863946592 コミュニケーションのために.
2.データと学習の参考資料
ビットコインの価格データは FMZ Quant トレーディングプラットフォームから入手:https://www.quantinfo.com/Tools/View/4.htmlわかったわ DRL+gym を使った記事です.https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4わかった pytorch を始めるためのいくつかの例:https://github.com/yunjey/pytorch-tutorialわかったわ この項目は,LSTM-PPOモデルによって直接実装されます:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.pyわかった PPO に 関する 記事:https://zhuanlan.zhihu.com/p/38185553わかったわ DRL に関する記事:https://www.zhihu.com/people/flood-sung/postsわかった この記事では体操について 設置は必要ありませんが 集中学習ではよく使われますhttps://gym.openai.com/.
3. LSTM-PPO
PPOの詳細な説明については,前回の参考資料から学ぶことができます.ここでは概念への簡単な紹介だけです.LSTMネットワークの最後の号では価格のみが予測されました.予測価格に基づいて購入および販売する方法は別々に実現する必要があります.取引アクションの直接的な出力がより直接的になると考えるのは自然なことです.これはポリシーのグラディエントの場合です.これは入力環境情報Sに応じてさまざまなアクションの確率を与えることができます.LSTMの損失は予測価格と実際の価格の違いであり,PGの損失は - log § * Qで,pは出力アクションの確率であり,Qはアクションの値 (インテュティブ報酬スコアなど) です.説明は,アクションの値が高くなった場合,ネットワークは損失を減らすための鍵となるはずです.PPOはより複雑ですが,その原理はどの程度高いかを評価し,それぞれのアクションの出力値を更新するのがよりよいかです.
LSTM-PPOのソースコードは以下のとおりで,以前のデータと組み合わせて理解できます.
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. ビットコインのバックテスト環境
Gymの形式に従って,リセット初期化方法があります.ステップはアクションを入力し,返される結果は (次の状態,アクション収入,終了するかどうか,追加の情報) です.バックテスト環境全体が60行です.より複雑なバージョンを自分で修正することができます.特定のコードは:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. 注目すべき 幾つ か の 詳細
- なぜ最初の口座には通貨があるのか?
バックテスト環境のリターンを計算する公式は:現在のリターン = 経費計算額 - 初期口座の現在の値. これは,ビットコインの価格が下がり,戦略がコイン販売操作を行う場合,総口座額が減少したとしても,戦略は実際に報酬を受けるべきであることを意味します. バックテストが長くかかる場合,初期口座はほとんど影響しないかもしれませんが,最初には大きな影響を与える可能性があります. 相対的リターンの計算は,正しい操作ごとにポジティブな報酬を得ることを保証します.
- なぜ訓練中に市場からサンプルを採取したのですか?
データの総量は1万K線以上である.ループを毎回フルに実行すると,時間がかかるし,戦略は毎回同じ状況に直面すると,オーバーフィットすることが容易になるかもしれない.バックテストとして500バーを一度に取る.それでもオーバーフィットすることは可能だが,戦略は1万以上の異なるスタートに直面する.
- 貨幣やお金がないとしたら?
この状況はバックテスト環境では考慮されない.通貨が売り切れた場合または最低取引量に達できない場合,販売操作は実際に操作していないものと等価である.相対収益計算方法によると,価格が低下した場合,それは依然として戦略的ポジティブリターンに基づいている.この状況の影響は,戦略が市場が減少していると判断し,口座の残った通貨が販売できないとき,販売アクションと非運用アクションを区別することは不可能であるが,市場上の戦略そのものの判断には影響しない.
- なぜアカウント情報をステータスとして返す必要があるのか?
PPOモデルには,現在の状態の価値を評価するための価値ネットワークがあります.明らかに,戦略が価格が上昇すると判断した場合,現在の口座がビットコインを保有している場合にのみ,全体的な状態がポジティブな価値を持つでしょう.したがって,アカウント情報は価値ネットワーク判断のための重要な基盤です. 過去のアクション情報が状態として返されないことに注意してください.私は価値を判断することは役に立たないと考えています.
- いつ停止する?
戦略は,取引によってもたらされる収益が処理手数料をカバーできないと判断すると,非運用に戻るべきである.前述の説明は価格動向を判断するために繰り返し戦略を使用しているが,それは理解の便利のためにのみである.実際には,このPPOモデルは市場を予測するのではなく,3つの行動の確率のみを出力する.
6. データ取得と訓練
前回の記事と同様に,データ取得方法と形式は以下のとおりです. Bitfinex Exchange BTC_USD取引ペアの1時間期Kライン (2018年5月7日~2019年6月27日):
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
LSTM ネットワークを使用しているため,トレーニング時間は非常に長い.私はGPU バージョンに切り替えました.これは約3倍速いです.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
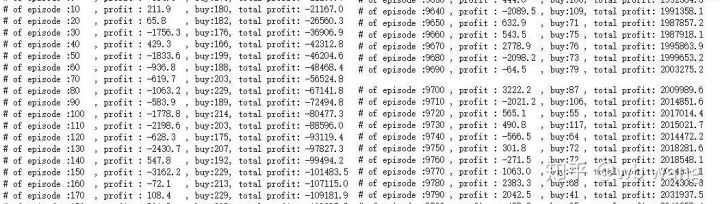
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. 訓練 結果 と 分析
長い待ち時間の後

まず,訓練データ市場を見てみましょう. 概して,前半は長期的な減少であり,後半は強い回復です.
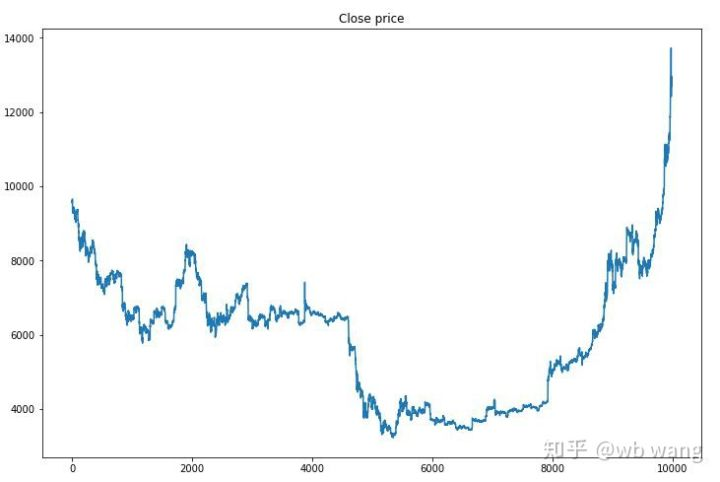
訓練の初期段階には多くの買い手取引があり,基本的に収益性のあるラウンドはありません.トレーニングの半ばまでに,買い手取引は徐々に減少し,利益の可能性も増加していますが,損失の可能性は依然として高いです.
各ラウンドの利益を滑らかにすると 結果は次のようになります
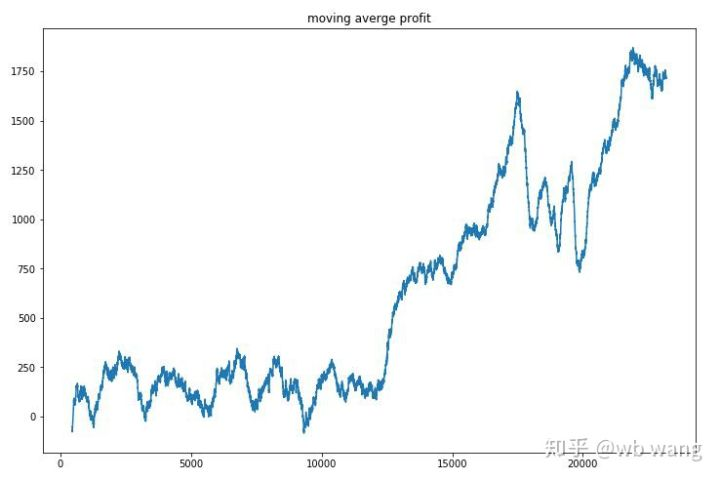
この戦略は早期返還が負であった状況から迅速に脱却したが,変動は大きかった.返還は10,000ラウンド後まで急速に増加しなかった.一般的に,モデルトレーニングは非常に困難であった.
最終的なトレーニングの後,モデルがすべてのデータを再び実行させ,そのパフォーマンスを確認します. この期間中,アカウントの総市場価値,保有するビットコインの数,ビットコイン価値の割合,総収益を記録します. 総収益はそれと類似します. 合計収益はこれと同じです.
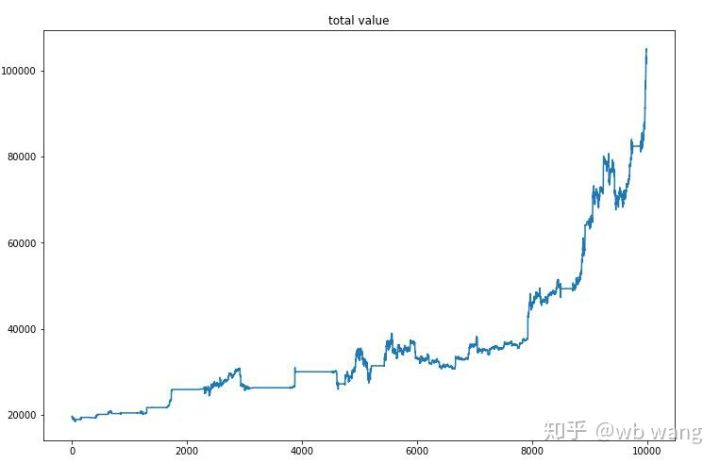
市場総額は初期の熊市ではゆっくりと上昇し,後期の牛市での増加に追いつきましたが,依然として周期的な損失がありました.
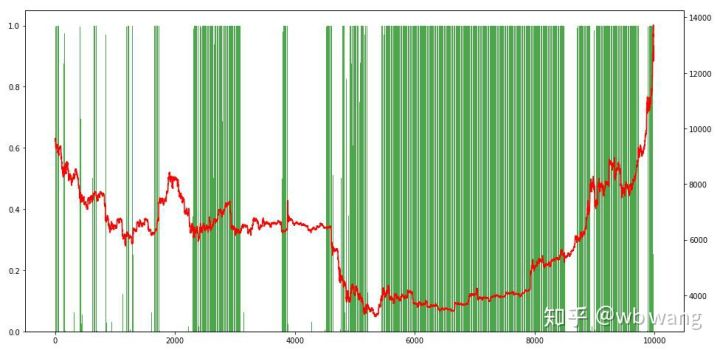
最後に,ポジションの比率を見てみましょう.チャートの左軸はポジションの比率であり,右軸は市場です.モデルがオーバーフィットしていると予備的に判断することができます. 初期の熊市ではポジションの頻度は低く,市場の底辺では高いです. また,モデルは長期的ポジションを保持することを学んでおらず,常に迅速に販売していることも見られます.
8. 試験データ分析
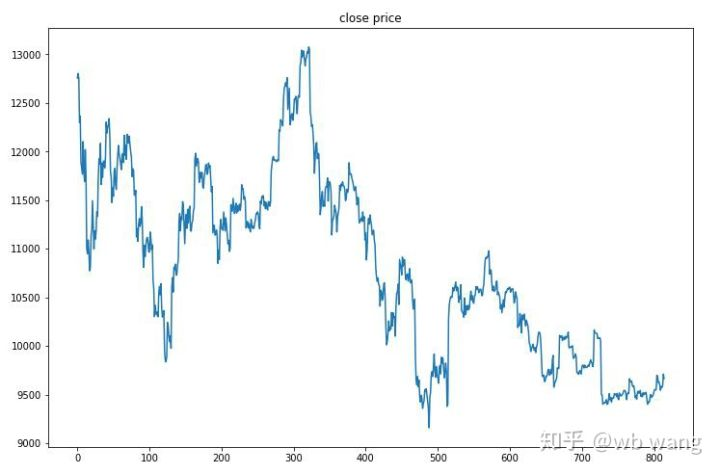
2019年6月27日から現在までの1時間のビットコイン市場はテストデータから得られた.チャートから見られるように,価格は13,000ドルから9000ドル以上に低下した.これはモデルにとって素晴らしいテストです.
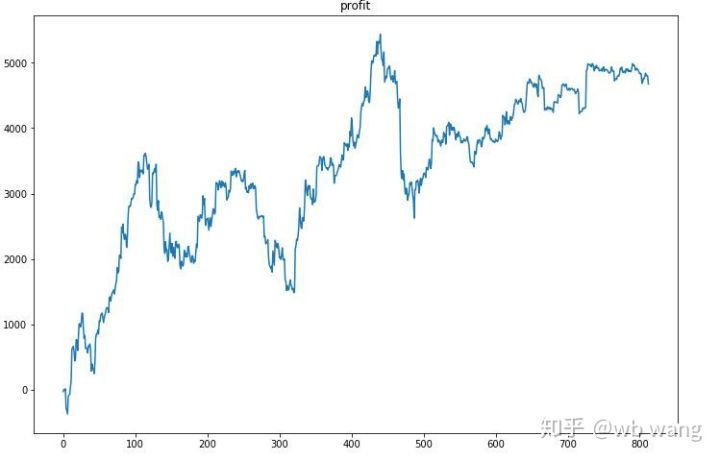
負債は負債の返済で 負債は負債で
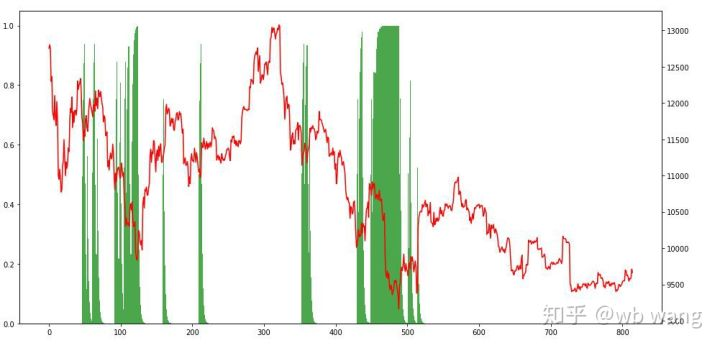
ポジション状況を見ると,このモデルは急落後購入し,リバウンド後売却する傾向があると推測できます.ビットコイン市場は近期はわずかに変動しており,このモデルはショートポジションにあります.
9. 概要
この論文では,ビットコイン自動取引ロボットは,深い集中学習方法であるPPOの助けで訓練され,いくつかの結論が得られる.限られた時間のために,モデルにはまだ改善すべきいくつかの側面があります.議論を歓迎します.最大の教訓は,データ標準化方法については,スケーリングやその他の方法を使用しないでください.そうでなければモデルは価格と市場の関係をすぐに覚え,過度に適合に陥ります.標準化された変動率は相対データであり,モデルが市場との関係性を覚えることが困難になり,変化率と増加と減少の関係を見つけることを余儀なくされています.
過去 の 記事 の 紹介: 高周波の戦略を明らかにしました かつては非常に有利でしたhttps://www.fmz.com/bbs-topic/9886.
- 暗号通貨市場の基本分析を定量化する: データが自分で話せ!
- 通貨圏の基礎的な定量化研究 - 数字を客観的に話すために,あらゆる
教師を信頼しなくていい! - 量化取引の必須ツール - 発明者による量化データ探索モジュール
- すべてをマスターする - FMZの新バージョンの取引ターミナルへの紹介 (TRB仲裁ソースコード)
- FMZの新バージョンの取引端末のご紹介 (TRBの利息ソースコード追加)
- FMZ Quant: 仮想通貨市場における共通要件設計例の分析 (II)
- 80行のコードで高周波戦略で 脳のない販売ボットを利用する方法
- FMZ定量化:仮想通貨市場の常用需要設計事例解析 (II)
- 80行コードの高周波戦略で脳のないロボットを搾取して売る方法
- FMZ Quant: 仮想通貨市場における共通要件設計例の分析 (I)
- FMZ定量化:仮想通貨市場の常用需要設計事例解析 (1)