디지털 통화 요인 모델
저자:리디아, 창작: 2022-10-24 17:37:50, 업데이트: 2023-09-15 20:59:38
인자 모델 프레임워크
증권 시장의 다중 요인 모델에 대한 연구 보고서는 풍부한 이론과 관행으로 방대한 규모입니다. 디지털 통화 시장에서 통화 수, 총 시장 가치, 거래량, 파생물 시장 등에 관계없이 요인 연구를 수행하는 것이 충분합니다. 이 논문은 주로 양적 전략의 초보자를위한 것이며 복잡한 수학적 원리와 통계 분석을 포함하지 않습니다. 요인 지표를 평가하는 데 편리한 요인 연구를위한 간단한 프레임워크를 구축하기 위해 데이터 소스로 바이낸스 영구 미래 시장을 사용할 것입니다.
요인은 지표로 간주 될 수 있으며 표현식을 작성 할 수 있습니다. 요인은 미래의 소득 정보를 반영하여 끊임없이 변화합니다. 일반적으로 요인은 투자 논리를 나타냅니다.
예를 들어, 폐쇄 가격 요인 뒤에 있는 가정은 주식 가격이 미래의 수익을 예측할 수 있으며, 주식 가격이 높을수록 미래의 수익이 높을 것입니다 (또는 낮을 수 있습니다). 사실,이 요인에 기반한 포트폴리오를 구축하는 것은 정기적인 라운드에서 높은 가격 주식을 구매하는 투자 모델 / 전략입니다. 일반적으로는 과도한 이익을 지속적으로 창출 할 수있는 요인도 알파라고합니다. 예를 들어, 시장 가치 요인과 추진 요인은 학계와 투자 커뮤니티에 의해 효과적인 요인으로 검증되었습니다.
주식 시장과 디지털 통화 시장은 모두 복잡한 시스템이다. 미래 수익을 완전히 예측할 수 있는 요인은 없지만 여전히 어느 정도의 예측성을 가지고 있다. 효과적인 알파 (투자 모드) 는 더 많은 자본 투입으로 점차 무효가 될 것이다. 그러나, 이 과정은 시장에서 다른 모델을 생산하여 새로운 알파를 낳을 것이다. 시장 가치 요인은 A 주식 시장에서 매우 효과적인 전략이었다. 단순히 가장 낮은 시장 가치로 10개의 주식을 구입하고 하루에 한 번 조정한다. 2007년 이후 10년 후속은 전체 시장을 훨씬 뛰어넘어 400배 이상의 수익을 창출할 것이다. 그러나 2017년 백마 주식 시장 테스트는 작은 시장 가치 요인의 실패를 반영했고, 가치 요인은 대신 인기를 얻었다. 따라서 우리는 끊임없이 균형을 확인하고 알파를 사용하려고 노력해야 한다.
추구되는 요인은 전략을 수립하는 기초입니다. 더 나은 전략을 수립하는 것은 서로 관련이 없는 여러 가지 효과적인 요인을 결합함으로써 가능합니다.
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
데이터 리소스
현재까지 2022 년 초부터 현재까지 바이낸스 USDT 영구 선물의 시간 K 라인 데이터는 150 화폐를 초과했습니다. 앞서 언급했듯이, 요인 모델은 특정 화폐보다는 모든 화폐에 초점을 맞춘 통화 선택 모델입니다. K 라인 데이터에는 높은 오픈 및 낮은 종료 가격, 거래량, 거래량, 타자 구매량 및 기타 데이터가 포함됩니다. 이러한 데이터는 미국 주식 지수, 금리 증가 기대, 수익성, 체인 데이터, 소셜 미디어 인기와 같은 모든 요소의 근원이 아닙니다. 비정상적인 데이터 소스 또한 효과적인 알파를 찾을 수 있지만 기본 가격 부피도 충분합니다.
## Current trading pair
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
아웃:
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
아웃:
153
#Function to obtain any period of K-line
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
아웃:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
우리가 관심있는 데이터: 종료 가격, 개시 가격, 거래량, 거래 수, 타커 구매 비율은 먼저 K 라인 데이터에서 추출됩니다. 이러한 데이터에 기초하여 필요한 요소가 처리됩니다.
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
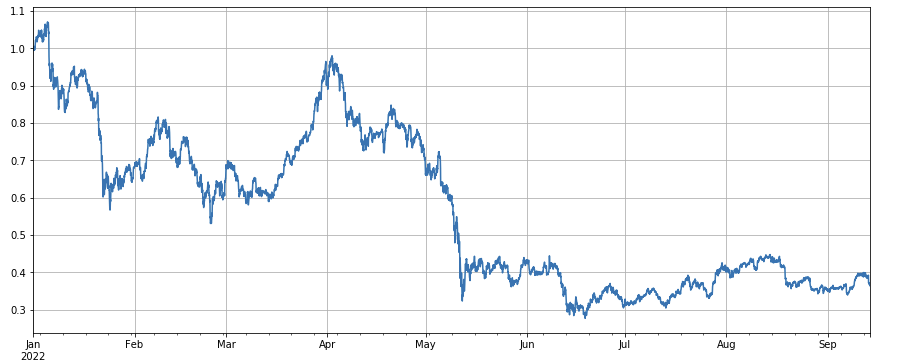
시장 지표의 전체적인 성과는 어둡고, 올해 초부터 최근 며칠 동안 60% 감소했습니다.
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #normalization
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#Final index profit chart
요인 유효성 판단
-
회귀 방법 다음 기간의 수익률은 종속 변수이며 테스트해야 할 인수는 독립 변수입니다. 회귀로 얻은 계수는 또한 인자의 수익률입니다. 회귀 방정식이 구성된 후, 요인의 유효성과 변동성은 일반적으로 계수 t 값의 절대 평균 값, 계수 t 값의 절대 값 순서 중 2보다 큰 비율, 연간 인수 수익률, 연간 인수 이익 변동성 및 인수 이익의 샤프 비율에 따라 간주됩니다. 여러 인자가 한 번에 회귀 할 수 있습니다. 자세한 내용은 바라 문서를 참조하십시오.
-
IC, IR 및 기타 표시기 소위 IC는 요인 및 다음 기간의 수익률 사이의 상관 계수입니다. 이제 RANK_ IC는 일반적으로 사용되기도 합니다. 그것은 요인 순위와 다음 주식 수익률 사이의 상관 계수입니다. IR는 일반적으로 IC 순서 / IC 순서 표준편차의 평균 값입니다.
-
계층화된 회귀 방법 이 논문에서는, 검증될 요인에 따라 통화를 분류하고, 그룹 백테스팅을 위해 N 그룹으로 나누고, 포지션 조정을 위해 일정한 기간을 사용하는 이 방법을 사용하겠습니다. 상황이 이상하다면, 그룹 N 통화의 수익률은 좋은 단조를 나타내며, 단조적으로 증가하거나 감소하며, 각 그룹의 소득 격차는 크습니다. 이러한 요인은 좋은 차별에 반영됩니다. 첫 번째 그룹이 가장 높은 수익을 가지고 있고 마지막 그룹이 가장 낮은 수익을 가지고 있다면, 첫 번째 그룹에서 장거리하고 마지막 그룹에서 단축하여 샤프 비율의 참조 지표인 최종 수익을 얻을 수 있습니다.
실제 백테스트 동작
선택해야 할 동전은 가장 작은 것부터 가장 큰 것까지의 요인 순위에 따라 3 그룹으로 나뉘어집니다. 각 통화 그룹은 전체의 약 1/3을 차지합니다. 요인이 효과적이라면 각 그룹에 있는 포인트 수가 작을수록 수익률이 높을 것이지만, 각 통화에는 상대적으로 더 많은 자금이 할당된다는 의미도 있습니다. 장기 및 단위 포지션이 각각 이중 레버리지이고, 첫 번째 그룹과 마지막 그룹이 각각 10 개의 통화라면, 하나의 통화는 전체의 10%를 차지합니다. 단위화 된 통화가 두 배로 증가하면 20%가 철수됩니다; 그룹 수가 50 인 경우 4%가 철수됩니다. 다변화 통화는 블랙 스완의 위험을 줄일 수 있습니다. 첫 번째 그룹 (최저 가치 요소) 을 길게 이동하면 세 번째 그룹으로 이동하십시오. 요인이 커지고, 수익이 높으면 단순히 요인을 뒤집어 긴 포지션이나 단위 또는 부정적인 수익으로 전환 할 수 있습니다.
일반적으로 인자 예측 능력은 최종 백테스트의 반환률과 샤프 비율에 따라 대략적으로 평가 될 수 있습니다. 또한 인자 표현이 간단하고 그룹 크기에 민감하고 위치 조정 간격에 민감하며 백테스트의 초기 시간에 민감한지 참조해야합니다.
포지션 조정 빈도에 관해서는 주식 시장은 일반적으로 5 일, 10 일 및 1 개월의 기간을 가지고 있습니다. 그러나 디지털 통화 시장의 경우 그러한 기간은 의심할 여지없이 너무 길고 실제 봇의 시장은 실시간으로 모니터링됩니다. 다시 포지션을 조정하려면 특정 기간에 충실 할 필요가 없습니다. 따라서 실제 봇에서는 실시간 또는 짧은 시간 내에 포지션을 조정합니다.
포지션을 닫는 방법에 관해서는, 전통적인 방법에 따르면, 포지션은 다음 번에 정렬할 때 그룹에 있지 않은 경우 닫을 수 있습니다. 그러나 실시간 포지션 조정의 경우, 일부 화폐가 경계선에있을 수 있으며, 이는 앞뒤로 포지션 폐쇄로 이어질 수 있습니다. 따라서이 전략은 그룹 변경을 기다리는 방법을 채택하고, 반대 방향으로 포지션이 열릴 필요가있을 때 포지션을 닫습니다. 예를 들어, 첫 번째 그룹은 길게 이동합니다. 긴 포지션 상태의 화폐가 세 번째 그룹으로 나뉘어지면 포지션을 닫고 짧게 이동하십시오. 포지션은 매일 또는 8 시간마다 일정한 기간에 닫히면 그룹에 있지 않고도 포지션을 닫을 수 있습니다. 가능한 한 더 많이 시도하십시오.
#Backtest engine
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #Initial assets
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #Net of fees
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #Close position first
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #Profits
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #Update assets
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#Function of test factor
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
간단한 요인 테스트
거래량 요인: 거래량이 낮은 간단한 긴 화폐와 거래량이 높은 짧은 화폐, 매우 좋은 성과, 인기있는 화폐가 감소하는 경향이 있음을 나타냅니다.
거래 가격 요인: 낮은 가격으로 긴 통화와 높은 가격으로 짧은 통화의 효과는 모두 일반적입니다.
거래량 요인: 성능은 거래량과 매우 유사하다. 거래량 요인과 거래량 요인 사이의 상관관계가 매우 높다는 것은 분명하다. 사실, 서로 다른 통화에서 그 사이의 평균 상관관계는 0.97에 달하며 두 요인이 매우 유사하다는 것을 나타낸다. 여러 요인을 합성할 때 이 요인을 고려해야 한다.
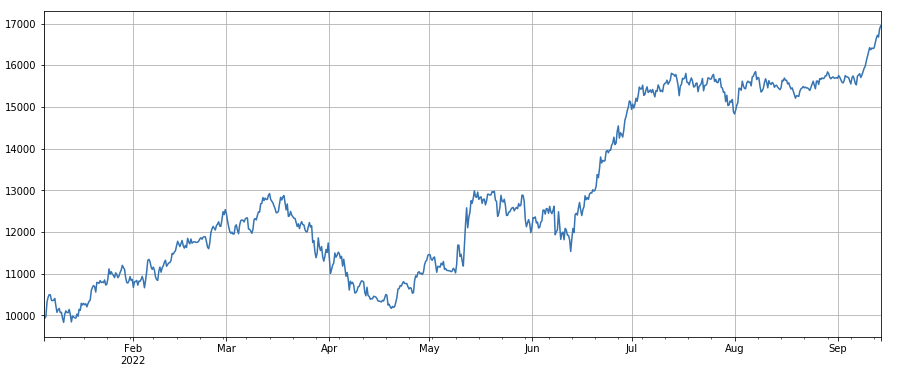
3h 모멘텀 요인: (df_close - df_close. shift (3)) /df_ close. shift ((3). 즉 요인의 3 시간 상승. 백테스트 결과는 3 시간 상승이 명백한 회귀 특성을 가지고 있음을 보여줍니다. 즉, 상승이 나중에 떨어지는 것이 더 쉽습니다. 전반적인 성능은 괜찮지만 긴 철수 기간과 진동도 있습니다.
24h 운동 요인: 24h 위치 조정 기간의 결과는 좋고, 수익은 3h 운동과 비슷하며, 철수는 작습니다.
거래량 변화 요인: df_ volume.rolling ((24).mean() /df_ volume. rolling (96). mean(), 즉, 지난 날 거래량과 지난 3일 거래량의 비율. 포지션은 8시간마다 조정됩니다. 백테스팅의 결과는 좋으며 인출도 상대적으로 낮았으며, 활성 거래량이 더 감소하는 경향이 있음을 나타냅니다.
트랜잭션 번호의 변화 요인: df_ count.rolling ((24).mean() /df_ count.rolling ((96). mean (), 즉, 지난 날 트랜잭션 번호와 지난 3 일 동안의 트랜잭션 번호의 비율. 포지션은 8 시간마다 조정됩니다. 백테스팅의 결과는 좋으며 인출도 상대적으로 낮으며, 활성 트랜잭션 부피가있는 사람들이 감소 할 가능성이 더 높다는 것을 나타냅니다.
단일 거래 가치의 변화 요인: - ((df_volume.rolling(24).mean()/df_count.rolling(24.mean())/(df_volume.rolling(24.mean()/df_count.rolling(96.mean()) , 즉 마지막 날의 거래 가치와 지난 3 일간의 거래 가치의 비율, 그리고 포지션은 8 시간마다 조정됩니다. 이 요인은 또한 거래량 요인과 밀접한 상관관계를 가지고 있습니다.
트랜잭션 비율에 따라 타인의 변화 요인: df_buy_ratio.rolling ((24).mean() /df_buy_ratio.rolling ((96).mean(), 즉, 지난 날의 전체 거래량과 지난 3 일 동안의 거래 가치에 대한 타인의 비율입니다. 이 요인은 8 시간마다 조정됩니다. 이 요인은 상당히 잘 수행되며 거래량 요인과 상관 관계가 거의 없습니다.
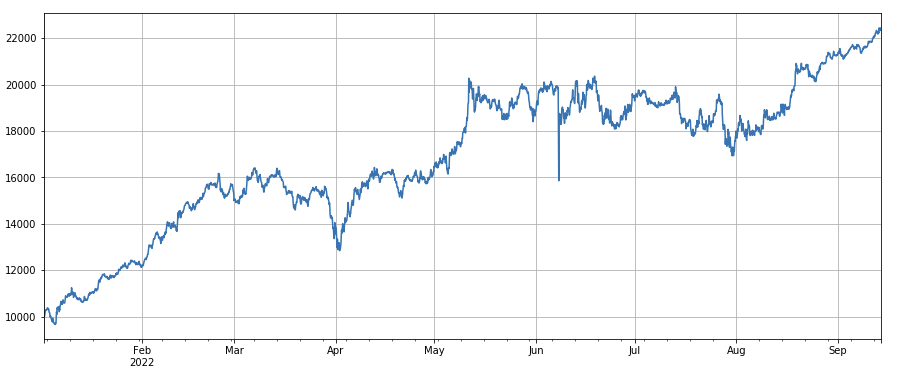
변동성 요인: (df_close/df_open).rolling ((24).std ((), 낮은 변동성을 가진 긴 통화를 이동, 그것은 특정 효과를 가지고 있습니다.
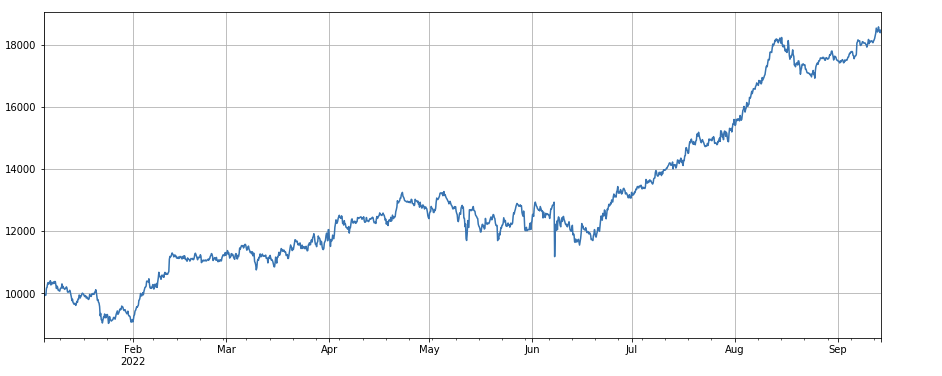
거래량과 종료 가격 사이의 상관 요인: df_close.rolling ((96).corr ((df_volume), 지난 4 일 동안의 종료 가격은 거래량과의 상관 요인을 가지고 있으며 전반적으로 좋은 성과를 거두었습니다.
여기에 나열 된 요인은 가격 부피에 기반합니다. 사실 요인 공식의 조합은 명백한 논리가없는 매우 복잡 할 수 있습니다. 유명한 ALPHA101 요인 구성 방법을 참조 할 수 있습니다.https://github.com/STHSF/alpha101.
#transaction volume
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
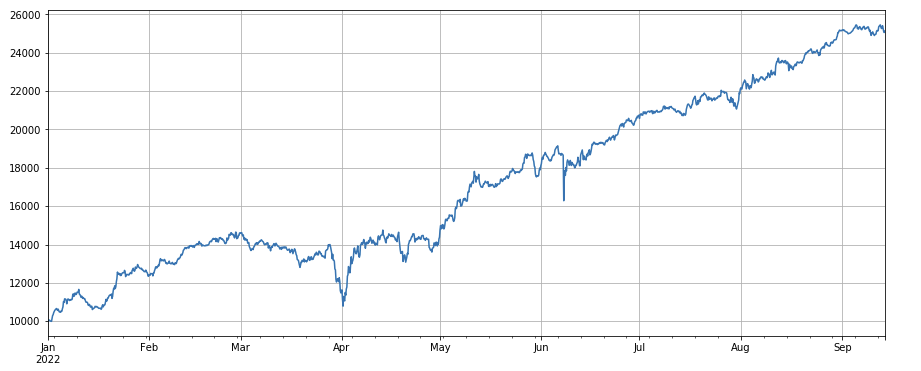
#transaction price
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
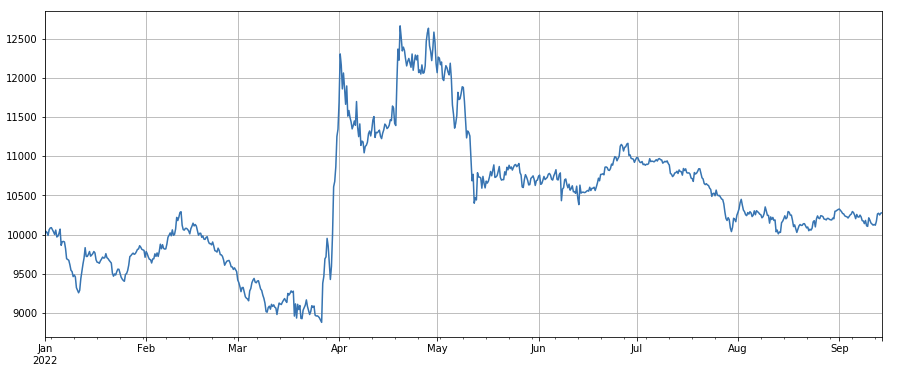
#transaction count
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
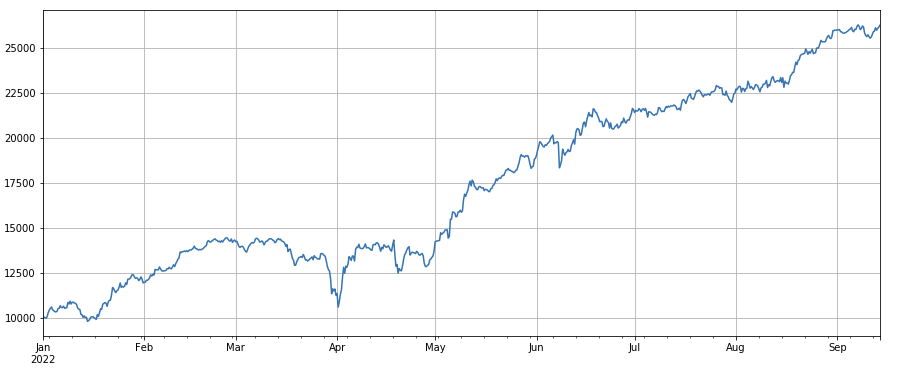
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3h momentum factor
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
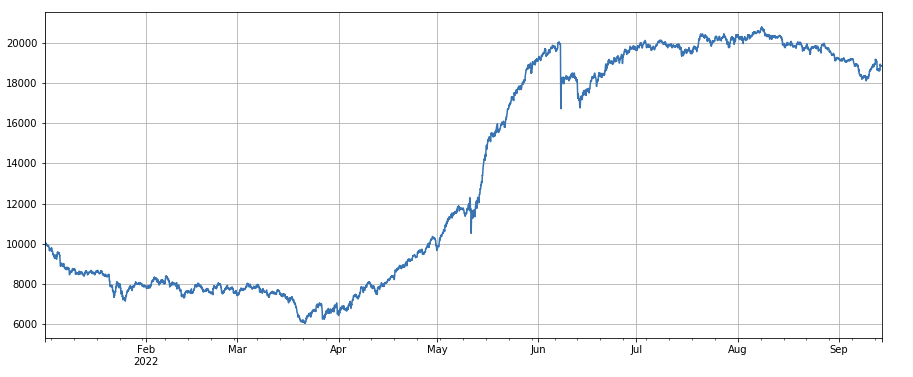
#24h momentum factor
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
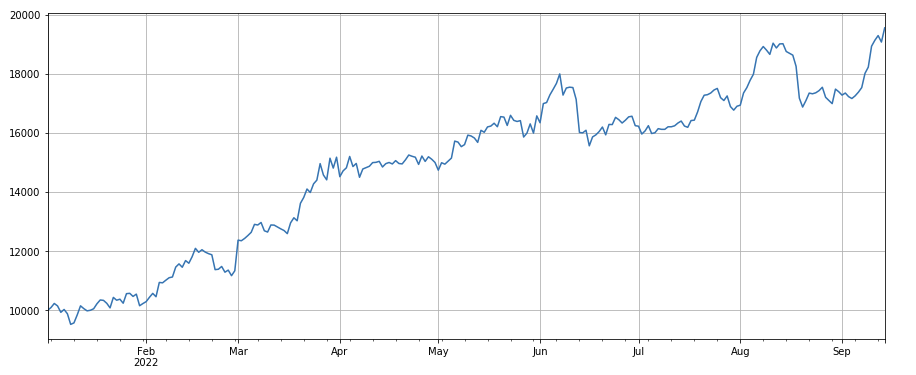
#factor of transaction volume
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
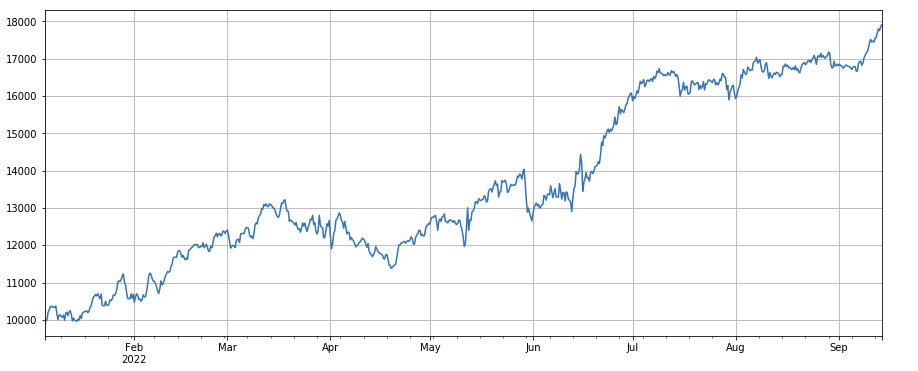
#factor of transaction number
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
#factor correlation
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#single transaction value factor
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
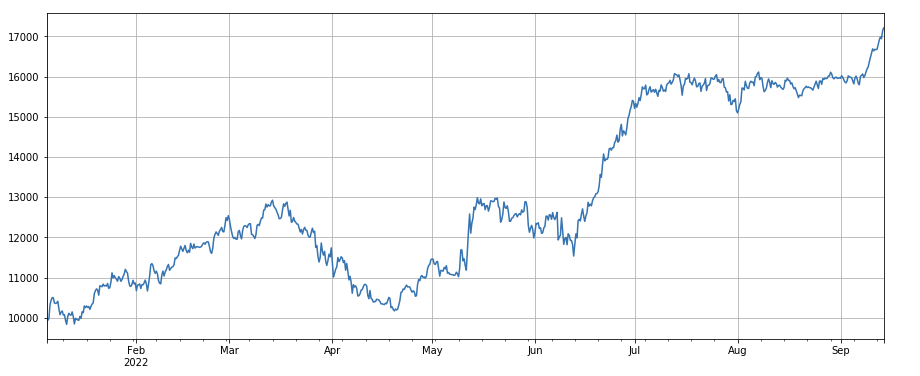
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#proportion factor of taker by transaction
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
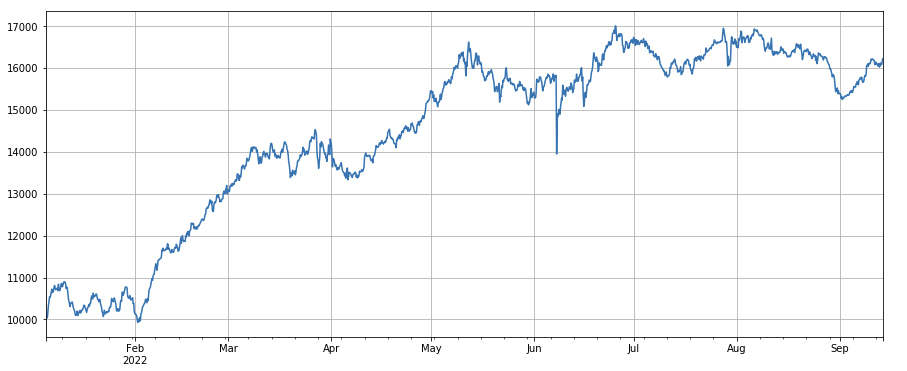
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#volatility factor
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
#correlation factor between transaction volume and closing price
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
다중 인자 합성
새로운 효과적인 요인을 지속적으로 발견하는 것이 전략 구축 과정의 가장 중요한 부분이지만 좋은 요인 합성 방법이 없으면 훌륭한 단일 알파 요인이 최대 역할을 할 수 없습니다. 일반적인 다중 요인 합성 방법에는 다음과 같습니다.
동등한 무게 방법: 합성 할 모든 요소는 합성 후 새로운 요소를 얻기 위해 동등한 무게로 더됩니다.
역사적인 요인 수익률의 가중화 방법: 결합해야 할 모든 요인은 합성 후 새로운 요인을 얻기 위해 중량으로 최신 기간의 역사적인 요인 수익률의 수학적 평균에 따라 추가됩니다.이 방법에서 잘 수행하는 요인은 더 높은 무게를 가지고 있습니다.
최대 IC_IR 가중화 방법: 역사의 한 기간 동안 복합 요소의 평균 IC 값은 다음 기간의 복합 요소의 IC 값의 추정치로 사용되며, 역사 IC 값의 동변성 행렬은 다음 기간의 복합 요소의 변동성의 추정치로 사용됩니다. IC_IR에 따르면 IC의 예상 값과 IC의 표준편차로 나눈 IC의 표준편차로 나
주요 구성 요소 분석 (PCA): PCA는 데이터 차원성 감축의 일반적인 방법이며, 요소들 사이의 상관관계는 높을 수 있습니다. 차원성 감축 후 주요 구성 요소들은 합성 요소로 사용됩니다.
이 문서에서는 인자 유효성 할당을 수동으로 참조합니다. 위에서 설명한 방법은 참조 할 수 있습니다.ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
단일 인자를 테스트 할 때 정렬은 고정되어 있지만 다중 인자 합성은 완전히 다른 데이터를 결합해야하므로 모든 인자가 표준화되어야하며 극단적 인 값과 부족한 값은 일반적으로 제거해야합니다. 여기서 우리는 합성을 위해 df_ 부피 \ 인자_ 1 \ 인자_ 7 \ 인자_ 6 \ 인자_ 8를 사용합니다.
#standardize functions, remove missing values and extreme values, and standardize
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
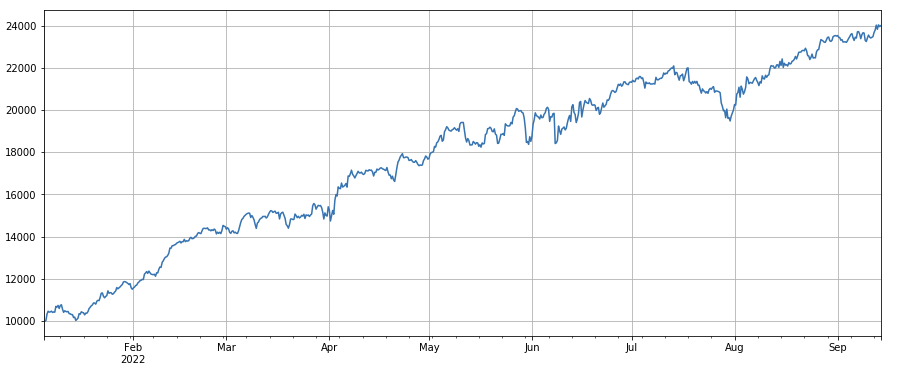
요약
이 논문은 단일 인자의 테스트 방법을 소개하고 일반적인 단일 인자를 테스트하고 초기에는 멀티 인자 합성 방법을 소개합니다. 그러나 멀티 인자의 많은 연구 내용이 있습니다. 논문에서 언급 된 모든 점은 추가 개발 될 수 있습니다. 그것은 알파 인자의 탐구로 다양한 전략에 대한 연구를 전환하는 실행 가능한 방법입니다. 인자 방법론의 사용은 거래 아이디어의 검증을 크게 가속화 할 수 있으며 참조 자료가 많이 있습니다.
- 암호화폐 시장의 근본 분석을 정량화: 데이터를 스스로 이야기하도록!
- 동전圈의 기초적인 양적 연구 - 더 이상 모든
선생님들을 믿지 말고, 데이터를 객관적으로 이야기하십시오! - 양적 거래의 필수 도구 - 발명자 양적 데이터 탐색 모듈
- 모든 것을 마스터 - FMZ에 대한 소개 트레이딩 터미널의 새로운 버전 (TRB 중재 소스 코드)
- FMZ의 새로운 거래 단말기 소개 (TRB 리비트 소스 추가)
- FMZ 퀀트: 암호화폐 시장에서 공통 요구 사항 설계 예제 분석 (II)
- 80 줄의 코드에서 고주파 전략으로 뇌 없는 판매봇을 이용하는 방법
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (II)
- 80줄의 코드의 고주파 전략으로 뇌 없는 로봇을 파는 방법
- FMZ Quant: 암호화폐 시장에서 공통 요구 사항 디자인 예의 분석 (I)
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (1)