ARMA-EGARCH 모델을 기반으로 비트코인 변동성의 모델링 및 분석
저자:리디아, 창작: 2022-11-15 15:32:43, 업데이트: 2023-09-14 20:30:52그리고 그 과정이 생략되었습니다.
정상 정상 분포의 일치 정도는 t 분포만큼 좋지 않으며, 이는 또한 양산 분포가 정상적인 분포보다 두꺼운 꼬리를 가지고 있음을 보여줍니다. 다음으로 모델링 프로세스에 입력하면 log_return (복귀의 로그리듬 비율) 를 위해 ARMA-GARCH(1,1) 모델 회귀가 실행되며 다음과 같이 추정됩니다.
[23]에서:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
아웃[23]: 반복: 1, 함수 수: 10, 부정 LLF: -1917.4262154917305
AR - GARCH 모델 결과
평균 모델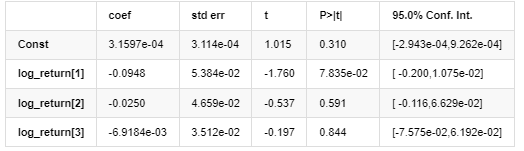
변동성 모델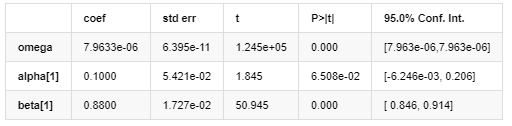
배포
코바리언스 추정치: 안정적
ARCH 데이터베이스에 따른 GARCH 변동성 방정식의 설명: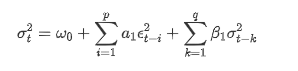
변동성에 대한 조건 회귀 방정식은 다음과 같이 얻을 수 있습니다.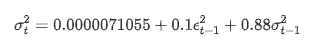
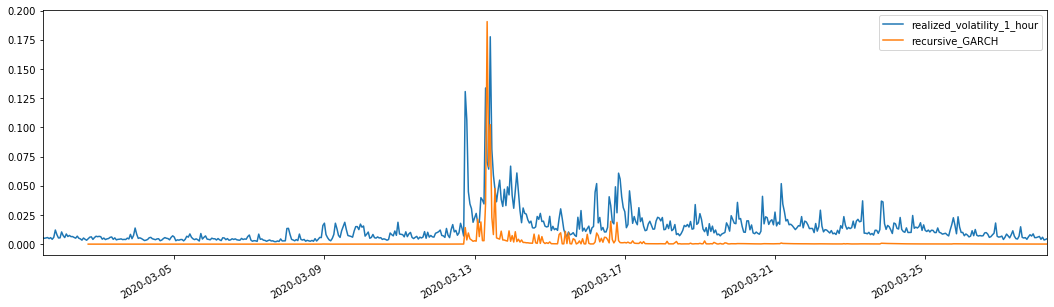
일치된 예측된 변동성과 결합하여 효과를 보기 위해 표본의 실현된 변동성과 비교합니다.
[26]에서:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
아웃[26]: 평균 절대 오류 (MAE): 0.0128 평균 절대 % 오류 (MAPE): 95.6 루트 평균 제곱 오류 (RMSE): 0.018
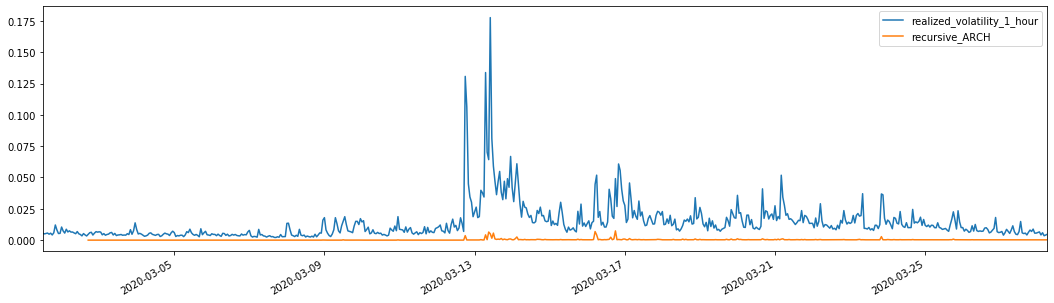
비교를 위해, 다음과 같이 ARCH를 만들어 보세요.
[27]에서:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
외출 [1]: 평균 절대 오류 (MAE): 0.0136 평균 절대 % 오류 (MAPE): 98.1 루트 평균 제곱 오류 (RMSE): 0.02
7. EGARCH 모델링
다음 단계는 EGARCH 모델을 수행하는 것입니다.
[24]에서:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
아웃[24]: 반복: 1, 함수 수: 11, 부정 LLF: -1966.610328148909
AR - EGARCH 모델 결과
평균 모델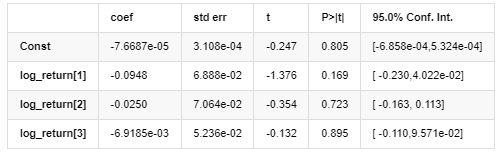
변동성 모델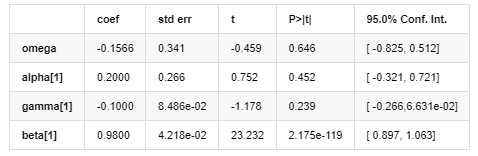
배포
코바리언스 추정치: 안정적
ARCH 라이브러리에서 제공하는 EGARCH 변동성 방정식은 다음과 같이 설명됩니다.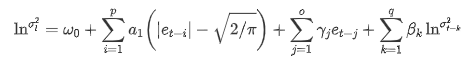
대체자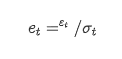
변동성의 조건 회귀 방정식은 다음과 같이 얻을 수 있습니다.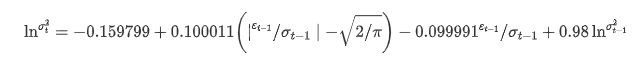
이 중 대칭 용어의 추정 계수는 신뢰도 간격보다 작으며, 이는 비트코인 수익률의 변동성에서 상당한 불균형이 있음을 나타냅니다.
일치된 예측 변동성과 결합하여 결과는 표본의 실현 변동성과 다음과 같이 비교됩니다.
[28]에서:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
외출[28]: 평균 절대 오류 (MAE): 0.0201 평균 절대 % 오류 (MAPE): 122 루트 평균 제곱 오류 (RMSE): 0.0279
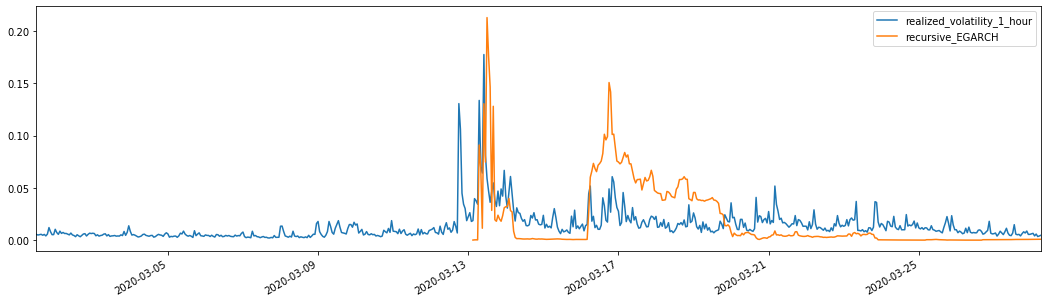
에가르치 (EGARCH) 는 변동성에 더 민감하고 ARCH와 가르치 (GARCH) 보다 변동성을 더 잘 맞추는 것을 볼 수 있습니다.
8. 변동성 예측 평가
시간적 데이터는 표본에 기초하여 선택되며 다음 단계는 1시간 앞을 예측하는 것입니다. 우리는 RV를 기준 변동성으로 삼고 세 가지 모델의 첫 10시간의 예측 변동성을 선택합니다. 비교 오류 값은 다음과 같습니다.
[29]에서:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
외출[29]: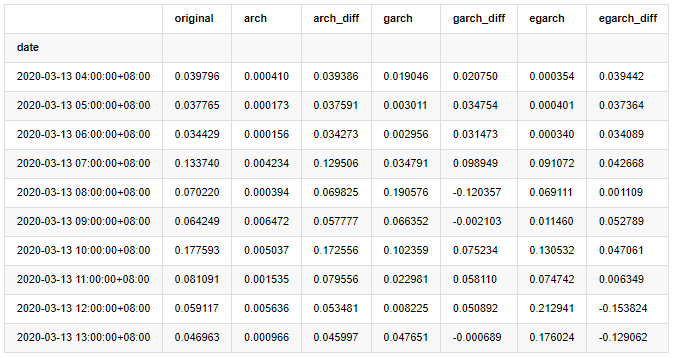
[30]에서:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
외출[30]: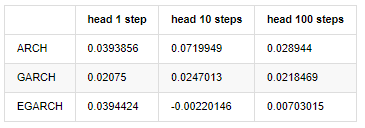
여러 테스트가 수행되었습니다, 첫 번째 시간 예측 결과에서, 가장 작은 오류의 확률 EGARCH는 상대적으로 크지만 전체적인 차이점은 특히 명백하지 않습니다; 단기 예측 효과에 몇 가지 명백한 차이점이 있습니다; EGARCH는 장기 예측에서 가장 뛰어난 예측 능력을 가지고 있습니다.
[31]에서:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
아웃[31]: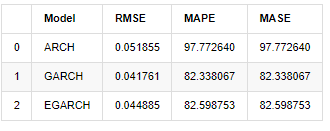
지표의 측면에서, GARCH와 EGARCH는 ARCH에 비해 어느 정도 개선되었지만, 그 차이는 특별히 명백하지 않습니다. 다중 샘플 간격 선택과 검증 후, EGARCH는 더 나은 성능을 갖게 될 것입니다. 이는 주로 EGARCH가 샘플의 이성분열성을 잘 설명하기 때문입니다.
9. 결론
위의 간단한 분석에서, 비트코인의 로그리듬적 수익률은 두꺼운 지방 꼬리가 특징인 정상적인 분포에 적합하지 않으며, 변동성은 집적 및 레버리지 효과를 가지고 있지만 명백한 조건적 이질성을 나타냅니다.
로그리듬적 수익률의 예측 및 평가에서 ARMA 모델의 샘플 내 정적 예측 능력은 동적보다 현저하게 낫고, 이는 롤링 방법이 반복 방법보다 분명히 낫다는 것을 보여줍니다. 과잉 일치 및 오류 증폭의 문제를 피할 수 있습니다. 샘플 외부의 수익률은 예측하기가 어렵고 시장의 약한 효율성 가정에 만족합니다.
또한, 비트코인의 두꺼운 꼬리 현상, 즉 수익률의 두꺼운 꼬리 분포를 다루는 경우, GED (일반 오류) 분포가 t 분포와 정상적인 분포보다 훨씬 낫다는 것이 밝혀졌으며, 이는 꼬리 위험의 측정 정확도를 크게 향상시킬 수 있습니다. 동시에, EGARCH는 장기 변동성을 예측하는 데 더 많은 이점을 가지고 있으며, 이는 표본의 이성분화성을 잘 설명합니다. 모델 매칭의 대칭 추정 계수는 신뢰도 간격보다 작으며, 이는 비트코인의 수익률 변동에 상당한 asasymmetry가 있음을 나타냅니다.
전체 모델링 프로세스는 다양한 대담한 가정으로 가득 차 있으며 유효성에 따라 일관성 식별이 없기 때문에 일부 현상을 신중하게 확인할 수 있습니다. 역사는 통계에서 미래를 예측하는 확률만을 지원 할 수 있지만 정확성과 비용 성능 비율은 여전히 긴 힘든 길을 가야합니다.
전통적인 시장과 비교하면 비트코인의 고주파 데이터의 사용성이 더 쉬워진다. 고주파 데이터에 기반한 다양한 지표의 측정은 단순하고 중요해진다. 비 파라미터적 측정이 발생한 시장에 대한 빠른 관측을 제공할 수 있고, 파라미터적 측정이 모델의 입력 정확성을 향상시킬 수 있다면, 모델의
그러나 위의 내용은 이론에 국한되어 있습니다. 높은 주파수 데이터는 실제로 거래자의 행동에 대한 더 정확한 분석을 제공할 수 있습니다. 금융 이론 모델에 대한 더 신뢰할 수있는 테스트를 제공할 수있을뿐만 아니라 거래자에게 더 풍부한 의사 결정 정보를 제공 할 수 있으며 정보 흐름과 자본 흐름의 예측을 지원하고 더 정확한 양적 거래 전략을 설계하는 데 도움을 줄 수 있습니다. 그러나 비트코인 시장은 너무 긴 역사적 데이터가 효과적인 의사 결정 정보와 일치 할 수 없기 때문에 높은 주파수 데이터는 확실히 디지털 통화 투자자에게 더 큰 시장 이점을 가져다 줄 것입니다.
마지막으로, 위의 내용이 도움이 된다고 생각한다면, 코라 한 잔을 사주기 위해 BTC를 줄 수도 있습니다. 하지만 저는 커피가 필요하지 않습니다.
- 암호화폐 시장의 근본 분석을 정량화: 데이터를 스스로 이야기하도록!
- 동전圈의 기초적인 양적 연구 - 더 이상 모든
선생님들을 믿지 말고, 데이터를 객관적으로 이야기하십시오! - 양적 거래의 필수 도구 - 발명자 양적 데이터 탐색 모듈
- 모든 것을 마스터 - FMZ에 대한 소개 트레이딩 터미널의 새로운 버전 (TRB 중재 소스 코드)
- FMZ의 새로운 거래 단말기 소개 (TRB 리비트 소스 추가)
- FMZ 퀀트: 암호화폐 시장에서 공통 요구 사항 설계 예제 분석 (II)
- 80 줄의 코드에서 고주파 전략으로 뇌 없는 판매봇을 이용하는 방법
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (II)
- 80줄의 코드의 고주파 전략으로 뇌 없는 로봇을 파는 방법
- FMZ Quant: 암호화폐 시장에서 공통 요구 사항 디자인 예의 분석 (I)
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (1)