디지털 통화 시장의 정량 분석
저자:리디아, 생성: 2023-01-06 10:28:01, 업데이트: 2023-09-20 10:27:27
디지털 통화 시장의 정량 분석
디지털 화폐에 대한 투기적 분석에 대한 데이터 기반 접근
비트코인 가격에 대해 어떻게 생각하십니까? 디지털 화폐의 가격 상승과 감소의 이유는 무엇입니까? 다른 알트코인의 시장 가격은 불가분의 관계 또는 크게 독립적입니까? 다음으로 일어날 일을 어떻게 예측할 수 있습니까?
비트코인, 이더리움 등 디지털 화폐에 관한 기사들은 현재 추측으로 가득하다. 수백 명의 자명 전문가들이 그들이 기대하는 추세를 옹호하고 있다. 이러한 분석의 많은 부분이 부족한 것은 기본적인 데이터와 통계 모델에 대한 견고한 기초이다.
이 문서의 목표는 파이썬을 사용하여 디지털 통화 분석에 대한 간략한 소개를 제공하는 것입니다. 우리는 간단한 파이썬 스크립트를 사용하여 다른 디지털 통화의 데이터를 검색, 분석 및 시각화 할 것입니다. 이 과정에서 우리는 이러한 변동의 시장 행동과 그들이 어떻게 발전하는지에 대한 흥미로운 추세를 찾을 것입니다.
이것은 디지털 화폐를 설명하는 기사가 아니며 특정 화폐가 증가하고 감소할 것이라는 의견도 아닙니다. 반대로, 이 튜토리얼에서 우리가 집중하는 것은 원래 데이터를 얻고 숫자에 숨겨진 이야기를 찾는 것입니다.
단계 1: 데이터 작업 환경을 설정
이 튜토리얼은 모든 기술 수준의 애호가, 엔지니어 및 데이터 과학자를 대상으로합니다. 업계 리더 또는 프로그래밍 초보자일지라도 필요한 유일한 기술은 파이썬 프로그래밍 언어의 기본 이해와 명령 줄 동작에 대한 충분한 지식입니다.
1.1 FMZ 퀀트 도커를 설치하고 아나콘다를 설정
- FMZ 퀀트 플랫폼의 도커 시스템 FMZ 퀀트 플랫폼FMZ.COM주요 주류 거래소에 대한 고품질의 데이터 소스를 제공 할뿐만 아니라 데이터 분석을 완료한 후 자동 거래를 수행하는 데 도움이되는 풍부한 API 인터페이스의 세트를 제공합니다. 이 인터페이스의 세트에는 계좌 정보를 검색하는 것, 높은, 개방된, 낮은, 수신 가격, 거래량 및 다양한 주류 거래소의 일반적으로 사용되는 기술 분석 지표와 같은 실용적인 도구가 포함됩니다. 특히 실제 거래 과정에서 주요 주류 거래소를 연결하는 공개 API 인터페이스에 대한 강력한 기술 지원을 제공합니다.
위의 모든 기능은 도커와 같은 시스템으로 캡슐화되어 있습니다. 우리가 해야 할 일은 우리의 클라우드 컴퓨팅 서비스를 구매하거나 임대하여 도커 시스템을 배포하는 것입니다.
FMZ 퀀트 플랫폼의 공식 명칭에서 이 도커 시스템은 도커 시스템이라고 불린다.
도커와 로봇을 어떻게 배포해야 하는지에 대한 제 이전 기사를 참조하시기 바랍니다:https://www.fmz.com/bbs-topic/9864.
독자들이 자신의 클라우드 컴퓨팅 서버를 구입하여 도커를 배포하고 싶다면 이 기사를 참조할 수 있습니다.https://www.fmz.com/digest-topic/5711.
클라우드 컴퓨팅 서버와 도커 시스템을 성공적으로 배포한 후, 다음으로 우리는 파이썬의 현재 가장 큰 유물을 설치합니다: 아나콘다
이 문서에서 요구되는 모든 관련 프로그램 환경 ( 의존성 라이브러리, 버전 관리 등) 을 구현하기 위해 가장 간단한 방법은 아나콘다를 사용하는 것입니다. 그것은 패키지 된 파이썬 데이터 과학 생태계 및 의존성 라이브러리 관리자입니다.
Anaconda를 클라우드 서비스에 설치하기 때문에 클라우드 서버에 Linux 시스템과 Anaconda의 명령 줄 버전을 설치하는 것이 좋습니다.
아나콘다의 설치 방법에 대해서는 아나콘다의 공식 가이드를 참조하십시오.https://www.anaconda.com/distribution/.
만약 당신이 경험이 많은 파이썬 프로그래머이고, 당신이 아나콘다를 사용할 필요가 없다고 느낀다면, 그것은 전혀 문제가 아닙니다. 필요한 의존 환경을 설치할 때 도움이 필요 없다고 가정합니다. 당신은 이 섹션을 직접 건너뛰을 수 있습니다.
1.2 아나콘다에 대한 데이터 분석 프로젝트 환경을 생성
아나콘다가 설치되면, 우리는 우리의 의존 패키지를 관리하는 새로운 환경을 만들어야합니다. 리눅스 명령 줄 인터페이스에서, 우리는 입력합니다:
conda create --name cryptocurrency-analysis python=3
우리의 프로젝트를 위해 새로운 아나콘다 환경을 만들기 위해.
다음으로 입력:
source activate cryptocurrency-analysis (linux/MacOS operating system)
or
activate cryptocurrency-analysis (windows operating system)
환경의 활성화를 위해서죠.
다음으로 입력:
conda install numpy pandas nb_conda jupyter plotly
이 프로젝트에 필요한 다양한 종속 패키지를 설치할 수 있습니다.
참고: 왜 아나콘다 환경을 사용합니까? 컴퓨터에서 많은 파이썬 프로젝트를 실행할 계획이라면 갈등을 피하기 위해 다른 프로젝트의 의존 패키지 (소프트웨어 라이브러리 및 패키지) 를 분리하는 것이 유용합니다. 아나콘다는 모든 패키지를 올바르게 관리하고 구별 할 수 있도록 각 프로젝트의 의존 패키지에 대한 특별한 환경 디렉토리를 만들 것입니다.
1.3 유피터 노트북을 만들자
환경과 의존 패키지가 설치된 후 실행:
jupyter notebook
아이파이썬 커널을 시작하려면http://localhost:8888/브라우저로 새로운 파이썬 노트북을 만들고,
Python [conda env:cryptocurrency-analysis]
커널

1.4 수입에 의존하는 패키지
빈 Jupyter 노트북을 만들고, 우리가 해야 할 첫 번째 일은 필요한 종속 패키지를 수입하는 것입니다.
import os
import numpy as np
import pandas as pd
import pickle
from datetime import datetime
우리는 또한 플롯을 가져와 오프라인 모드를 활성화해야 합니다:
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
단계 2: 디지털 화폐 가격 정보를 얻으십시오
준비는 완료되고 이제 분석할 데이터를 얻기 시작할 수 있습니다. 먼저, 우리는 FMZ 퀀트 플랫폼의 API 인터페이스를 사용하여 비트코인의 가격 데이터를 얻을 수 있습니다.
이것은 GetTicker 함수를 사용 합니다. 이 두 가지 함수의 사용에 대해 참조하십시오:https://www.fmz.com/api.
2.1 Quandl 데이터 수집 함수를 작성
데이터 획득을 촉진하기 위해 Quandl에서 데이터를 다운로드하고 동기화하는 함수를 작성해야 합니다 (quandl.com) 이것은 해외에서 높은 평판을 누리는 무료 금융 데이터 인터페이스입니다. FMZ 퀀트 플랫폼은 또한 실제 봇 거래에 주로 사용되는 유사한 데이터 인터페이스를 제공합니다. 기사는 주로 데이터 분석에 초점을 맞추고 있기 때문에 우리는 여전히 Quandl 데이터를 사용합니다.
실제 봇 트랜잭션 동안, 당신은 가격 데이터를 얻기 위해 파이썬에서 GetTicker 및 GetRecords 함수를 직접 호출할 수 있습니다. 그들의 사용에 대해 참조하십시오:https://www.fmz.com/api.
def get_quandl_data(quandl_id):
# Download and cache data columns from Quandl
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return df
이 경우, 피클 라이브러리는 데이터를 연쇄화하고 다운로드 된 데이터를 파일로 저장하는 데 사용됩니다. 이 기능을 사용하면 프로그램이 실행할 때마다 동일한 데이터를 다운로드하지 않습니다. 이 기능은 판다 데이터 프레임 형식으로 데이터를 반환합니다. 데이터 프레임의 개념에 익숙하지 않은 경우 강력한 엑셀로 상상할 수 있습니다.
2.2 크라켄 거래소의 디지털 통화 가격 데이터에 대한 액세스
예를 들어 크라켄 비트코인 거래소를 들어보죠.
# Get prices on the Kraken Bitcoin exchange
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
데이터 박스의 첫 다섯 줄을 보기 위해 헤드 (head) 방법을 사용하십시오.
btc_usd_price_kraken.head()
그 결과는 다음과 같습니다.
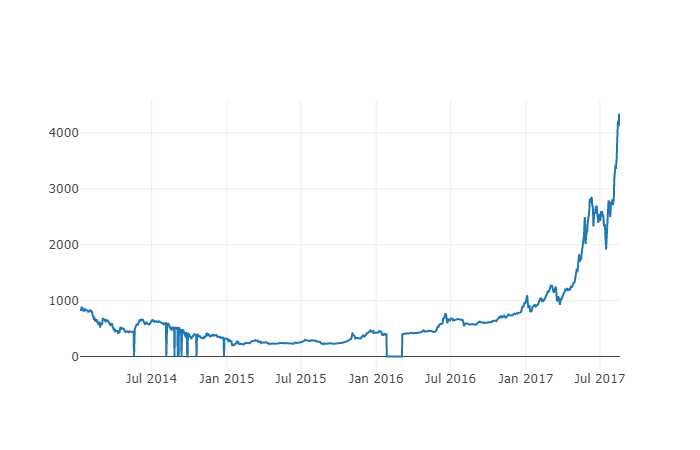
다음으로, 우리는 시각화를 통해 데이터의 정확성을 확인하기 위해 간단한 테이블을 만들 것입니다.
# Make a table of BTC prices
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
여기, 우리는 시각화 부분을 완료하기 위해 Plotly를 사용합니다. Matplotlib과 같은 좀 더 성숙한 파이썬 데이터 시각화 라이브러리를 사용하는 것과 비교하면, Plotly는 덜 일반적인 선택이지만, D3.js
팁: 생성 된 차트는 다운로드 된 데이터가 일반적으로 일관성 있는지 확인하기 위해 빠른 무결성 검사로 주류 거래소의 비트코인 가격 차트 (OKX, Binance 또는 Huobi의 차트) 와 비교 할 수 있습니다.
2.3 주요 비트코인 거래소에서 가격 데이터를 얻으십시오
주의깊은 독자들은 특히 2014 년 말과 2016 년 초에 위의 데이터에 데이터가 결여되어 있음을 알아차렸을 수 있습니다. 특히 크라켄 거래소에서 이러한 유형의 데이터 손실은 특히 분명합니다. 이러한 결여된 데이터가 가격 분석에 영향을 줄 것으로 기대하지 않습니다.
디지털 통화 교환의 특징은 수요와 공급 관계가 통화 가격을 결정한다는 것입니다. 따라서 어떤 거래 가격도 시장의
각 교환의 데이터를 사전 유형으로 구성된 데이터 프레임에 다운로드하여 시작합시다.
# Download price data from COINBASE, BITSTAMP and ITBIT
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_df
2.4 모든 데이터를 하나의 데이터 프레임에 통합
다음으로, 우리는 각 데이터 프레임에 공통된 열을 새로운 데이터 프레임으로 통합하는 특수 함수를 정의합니다. merge_dfs_on_column 함수를 호출합니다.
def merge_dfs_on_column(dataframes, labels, col):
'''Merge a single column of each dataframe into a new combined dataframe'''
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
이제 모든 데이터 프레임은 각 데이터 세트의
# Integrate all data frames
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
마지막으로, 우리는
btc_usd_datasets.tail()
그 결과는 다음과 같습니다.
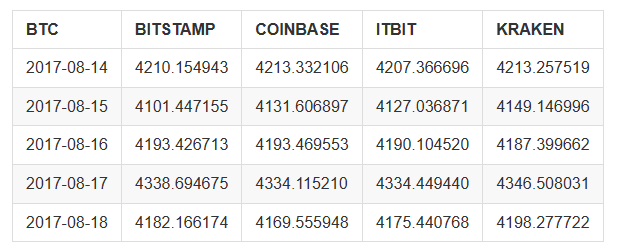
위의 표를 보면, 이 데이터가 우리의 예상과 일치한다는 것을 알 수 있습니다. 대략 동일한 데이터 범위이지만, 각각의 교환의 지연이나 특성에 따라 약간 다릅니다.
2.5 가격 데이터의 시각화 과정
분석 논리의 관점에서 다음 단계는 시각화를 통해 이러한 데이터를 비교하는 것입니다. 이를 위해 먼저 보조 함수를 정의해야합니다. 그래프를 만들기 위해 데이터를 사용하는 단일 라인 명령어를 제공함으로써 df_scatter 함수를 사용합니다.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
'''Generate a scatter plot of the entire dataframe'''
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
# Table tracking for each series
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
# Add a separate axis to the series
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
쉽게 이해할 수 있도록, 이 기사는 이 보조 기능의 논리 원리를 너무 많이 논의하지 않을 것입니다. 더 알고 싶다면, 팬더와 플롯리의 공식 문서를 확인하십시오.
이제 우리는 쉽게 비트코인 가격 데이터 차트를 만들 수 있습니다.
# Plot all BTC transaction prices
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
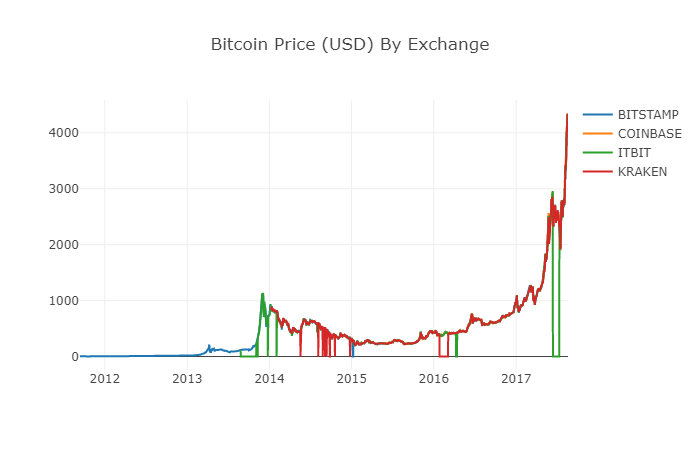
2.6 명확하고 집계된 가격 데이터
위 그래프에서 볼 수 있듯이, 네 개의 데이터 시리즈가 대략 같은 경로를 따라가지만, 여전히 불규칙한 변화가 있습니다. 우리는 이러한 불규칙한 변화를 제거하려고 노력할 것입니다.
2012~2017년 기간 동안 비트코인의 가격이 0에 해당하지 않았다는 것을 알고 있습니다. 그래서 먼저 데이터 프레임에서 모든 0값을 제거합니다.
# Clear the "0" value
btc_usd_datasets.replace(0, np.nan, inplace=True)
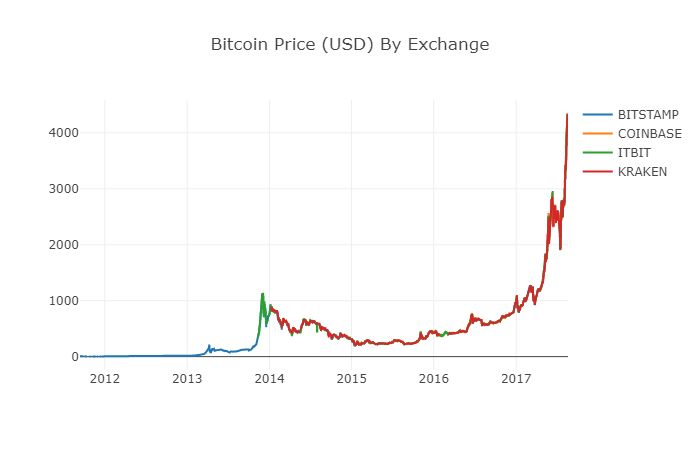
데이터 프레임을 재구성하면 더 이상 데이터가 없는 보다 명확한 차트를 볼 수 있습니다.
# Plot the revised data frame
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
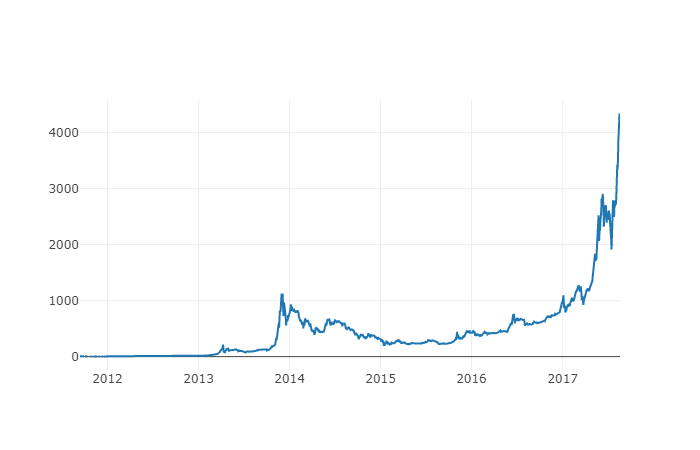
이제 새로운 열을 계산할 수 있습니다. 모든 거래소의 하루 평균 비트코인 가격입니다.
# Calculate the average BTC price as a new column
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
새로운 열은 비트코인의 가격 지표입니다. 데이터를 잘못 보여지는지 확인하기 위해 다시 그려봅시다.
# Plot the average BTC price
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])
나중에, 우리는 다른 디지털 화폐와 USD 사이의 환율을 결정하기 위해 이 집계된 가격 시리즈 데이터를 계속 사용할 것입니다.
단계 3: Altcoin의 가격을 수집합니다.
지금까지, 우리는 비트코인 가격의 시간 계열 데이터를 가지고 있습니다. 다음으로, 비 비트코인 디지털 화폐, 즉 Altcoins의 일부 데이터를 살펴보자. 물론, Altcoins라는 용어는 약간 과장 될 수 있지만, 현재 디지털 화폐의 발전에 관해서는, 시장 가치 (비트코인, 이더리움, EOS, USDT 등) 의 상위 열 개를 제외하면, 대부분은 Altcoins라고 불릴 수 있습니다. 거래할 때 이러한 화폐를 멀리하려고 노력해야 합니다. 왜냐하면 그들은 너무 혼란스럽고 속임수이기 때문입니다.
3.1 Poloniex 거래소의 API를 통해 보조 기능을 정의
먼저, 우리는 디지털 통화 거래의 데이터 정보를 얻기 위해 Poloniex 거래소의 API를 사용합니다. Altcoins와 관련된 데이터를 얻기 위해 두 가지 보조 기능을 정의합니다. 이 두 가지 기능은 주로 API를 통해 JSON 데이터를 다운로드하고 캐시합니다.
먼저, get_json_data 함수를 정의합니다. 이 함수는 주어진 URL에서 JSON 데이터를 다운로드하고 캐시합니다.
def get_json_data(json_url, cache_path):
'''Download and cache JSON data, return as a dataframe.'''
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached {} at {}'.format(json_url, cache_path))
return df
다음으로, 우리는 Poloniex API의 HTTP 요청을 생성하는 새로운 함수를 정의하고 호출의 데이터 결과를 저장하기 위해 방금 정의된 get_json_data 함수를 호출합니다.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # Data acquisition since 2015
end_date = datetime.now() # Until today
pediod = 86400 # pull daily data (86,400 seconds per day)
def get_crypto_data(poloniex_pair):
'''Retrieve cryptocurrency data from poloniex'''
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_df
위의 함수는 디지털 화폐의 일치하는 문자 코드를 추출하고 두 화폐의 역사적 가격을 포함하는 데이터 프레임을 반환합니다.
3.2 Poloniex에서 거래 가격 데이터를 다운로드하십시오.
대부분의 알트코인은 USD로 직접 구입할 수 없습니다. 이러한 디지털 통화를 얻기 위해 개인은 일반적으로 먼저 비트코인을 구입하고 그 가격 비율에 따라 알트코인으로 변환해야 합니다. 따라서 각 디지털 통화의 환율을 비트코인으로 다운로드하고, 기존의 비트코인 가격 데이터를 사용하여 USD로 변환해야 합니다. 우리는 Ethereum, Litecoin, Ripple, EthereumClassic, Stellar, Dash, Siacoin, Monero, NEM 등 9개의 주요 디지털 통화의 환율 데이터를 다운로드합니다.
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_df
이제, 우리는 9개의 데이터 프레임을 포함하는 사전을 가지고 있습니다. 각각의 프레임들은 Altcoin과 Bitcoin 사이의 역사적 하루 평균 가격 데이터를 포함하고 있습니다.
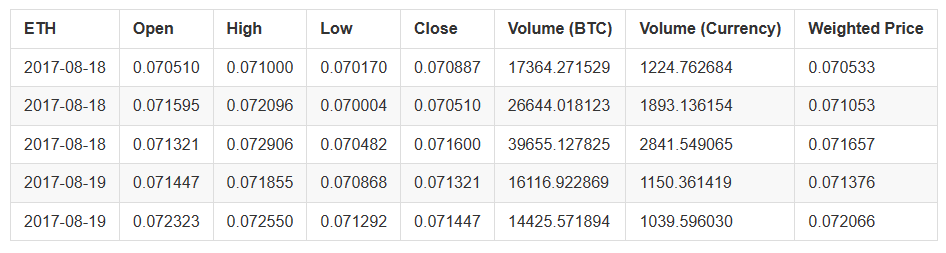
우리는 이더리움 가격 표의 마지막 몇 줄을 통해 데이터가 맞는지 확인할 수 있습니다.
altcoin_data['ETH'].tail()
3.3 모든 가격 데이터의 통화 단위를 USD로 통일
이제 우리는 BTC와 Altcoin의 환율 데이터를 비트코인 가격 지표와 결합하여 각 Altcoin의 역사적 가격을 직접 계산할 수 있습니다.
# Calculate USD Price as a new column in each altcoin data frame
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
여기, 우리는 각 Altcoin 데이터 프레임에 대한 새로운 열을 추가하여 해당 USD 가격을 저장합니다.
다음으로, 우리는 이전에 정의된 merge_dfs_on_column 함수를 재사용하여 결합된 데이터 프레임을 만들고 각 디지털 화폐의 USD 가격을 통합할 수 있습니다.
# Combine the USD price of each Altcoin into a single data frame
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
다 됐어!
이제 합병된 데이터 프레임의 마지막 열로 비트코인 가격을 더해봅시다.
# Add BTC price to data frame
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
이제 우리는 우리가 확인하고 있는 10개의 디지털 화폐의 일일 USD 가격을 포함하는 독특한 데이터 프레임을 가지고 있습니다.
이전 함수를 다시 df_scatter라고 부르고, 모든 Altcoin의 대응 가격을 차트 형태로 표시합니다.
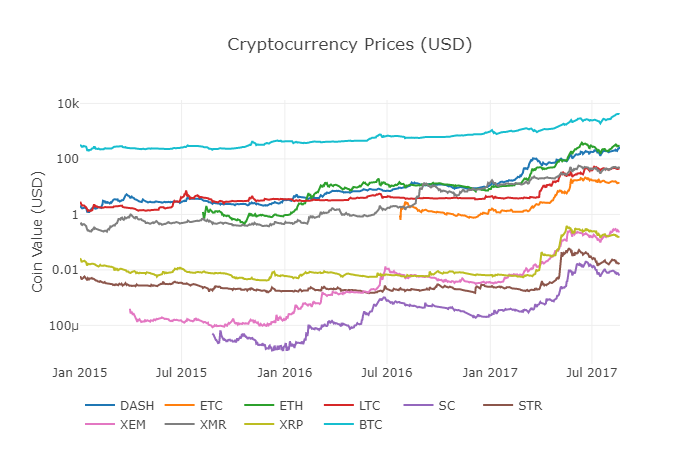
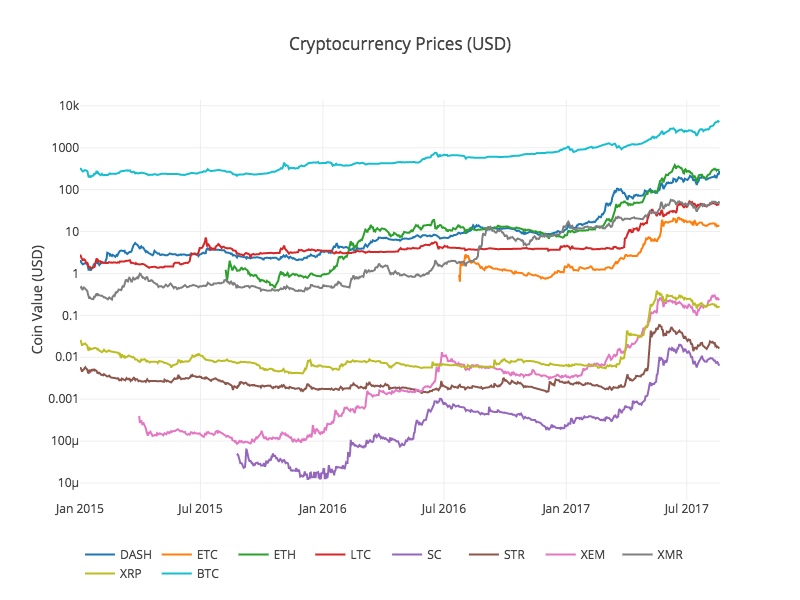
그래프에 문제가 없는 것 같습니다. 이 그래프는 지난 몇 년 동안 각 디지털 화폐의 환율 변화의 완전한 그림을 보여줍니다.
참고: 여기 우리는 로그아리듬 사양의 y축을 사용하여 동일한 차트에 있는 모든 디지털 화폐를 비교합니다. 또한 다른 입장에서 데이터를 이해하기 위해 다른 매개 변수 (예: 스케일=
3.4 상관 분석 시작
신중한 독자들은 디지털 화폐의 가격이 관련이있는 것처럼 보이지만 통화 가치는 광범위하게 변하고 매우 변동적입니다. 특히 2017 년 4 월 급격한 상승 이후 많은 작은 변동이 전체 시장의 변동과 동시에 발생하는 것처럼 보입니다.
물론, 데이터에 근거한 결론은 이미지에 근거한 직관보다 더 설득력 있습니다.
위의 상관관계 가설을 검증하기 위해 판다스 corr() 함수를 사용할 수 있습니다. 이 테스트 방법은 다른 열에 대응하는 데이터 프레임의 각 열의 피어슨 상관관계 계수를 계산합니다.
2017년 8월 22일 개정 참고: 이 섹션은 상관률을 계산할 때 가격의 절대값 대신 일일 수익률을 사용하도록 수정되었습니다.
비탄력적인 시간 계열 (무료 가격 데이터와 같이) 에 기반한 직접 계산은 상관 계수의 오차로 이어질 수 있습니다. 이 문제를 해결하기 위해 우리의 해결책은 pct_change (), pct_change ()) 방법을 사용하여 데이터 프레임의 각 가격의 절대 값을 해당 일일 수익률으로 변환하는 것입니다.
예를 들어, 2016년에 상관 계수를 계산해보죠.
# Calculating the Pearson correlation coefficient for digital currencies in 2016
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')
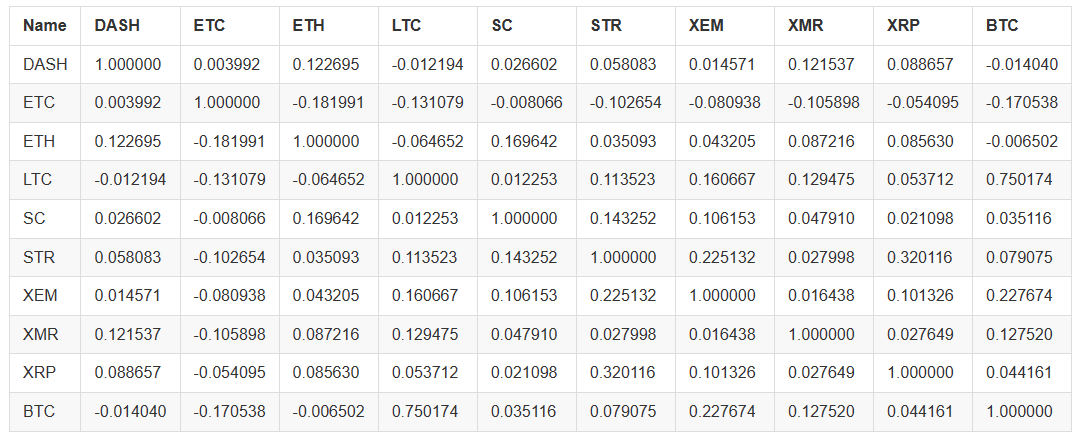
위의 차트에서는 상관 계수를 나타냅니다. 계수가 1 또는 -1에 가까워지면, 이 시리즈가 각각 긍정적으로 상관관계 또는 부정적으로 상관관계된다는 것을 의미합니다. 상관 계수가 0에 가까워지면, 해당 물체가 상관관계가 없으며 변동이 서로 독립된다는 것을 의미합니다.
결과를 더 잘 시각화하기 위해 새로운 시각적 도움 기능을 만들었습니다.
def correlation_heatmap(df, title, absolute_bounds=True):
'''Plot a correlation heatmap for the entire dataframe'''
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
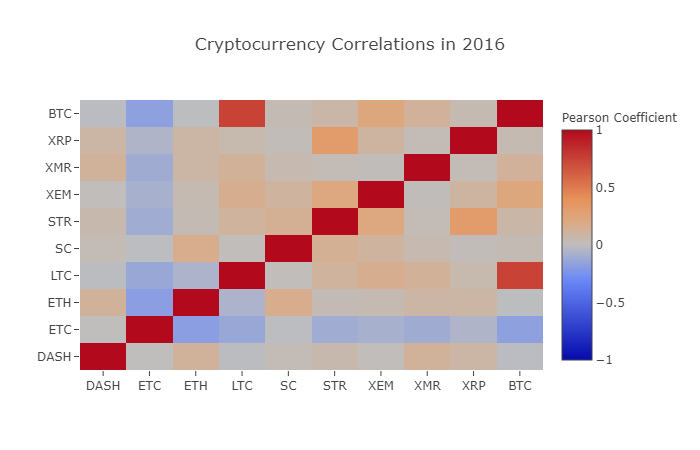
여기, 어두운 빨간색 값은 강한 상관관계를 나타냅니다 (각 화폐는 분명히 자신과 밀접한 상관관계를 나타냅니다), 그리고 어두운 파란색 값은 역 상관관계를 나타냅니다. 중간에 있는 모든 색상 - 밝은 파란색 / 주황색 / 회색 / 타운이 - 는 약한 상관관계 또는 상관관계의 다양한 정도를 나타내는 값을 가지고 있습니다.
이 그래프는 우리에게 무엇을 알려줍니다? 기본적으로 2016년에 다른 디지털 화폐 가격의 변동을 보여줍니다. 통계적으로 유의미한 상관관계가 거의 없습니다.
이제, 지난 몇 달 동안 디지털 화폐의 상관관계가 증가했다는 가설을 검증하기 위해 2017년의 데이터를 사용하여 같은 테스트를 반복할 것입니다.
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')
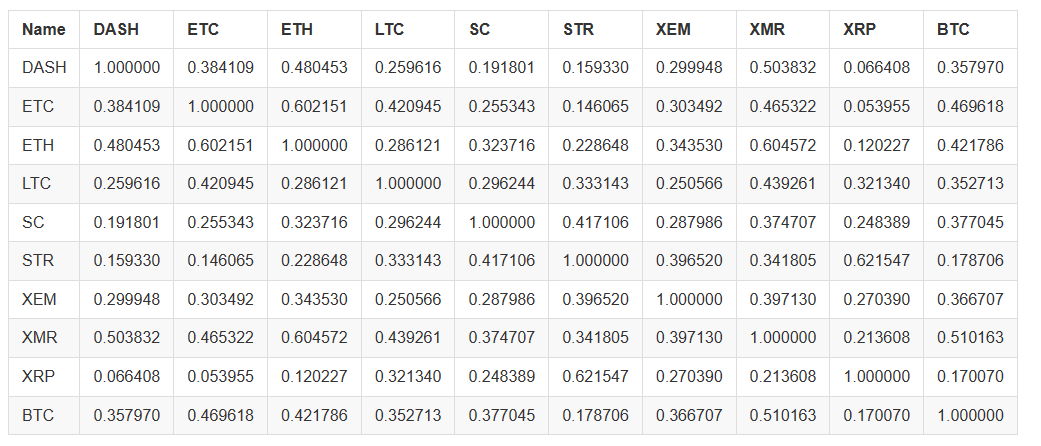
위의 자료들은 더 관련성이 있는가? 투자에 대한 판단 기준으로 사용하기에 충분합니까? 답은 아닙니다.
그러나 거의 모든 디지털 화폐가 점점 더 상호 연결되고 있다는 점에 주목할 필요가 있습니다.
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")
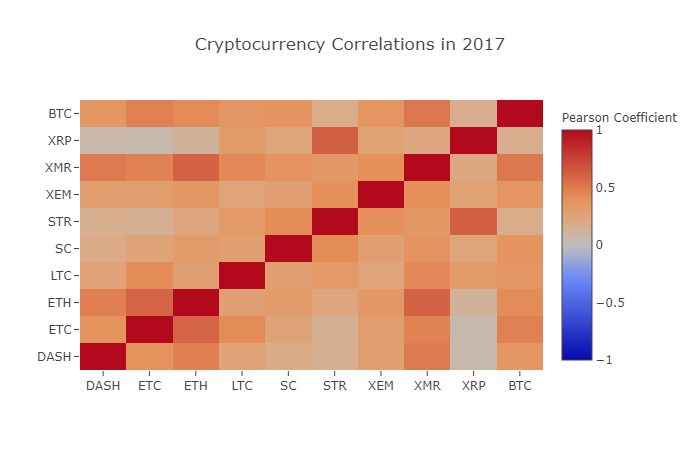
위의 차트에서 볼 수 있듯이, 상황은 점점 더 흥미로워지고 있습니다.
왜 이런 일이 일어나는 걸까요?
좋은 질문이지만, 진실은...
나의 첫 번째 반응은 헤지 펀드가 최근 디지털 통화 시장에서 공개적으로 거래하기 시작했다는 것입니다. 이 펀드는 일반 거래자보다 훨씬 더 많은 자본을 보유하고 있습니다. 펀드가 여러 디지털 통화 사이에서 투자 된 자본을 헤지 할 때 독립적인 변수 (증권 시장과 같은) 에 따라 각 통화에 대해 유사한 거래 전략을 사용합니다. 이러한 관점에서 증가하는 상관관계의 추세가 발생할 것이라는 것은 의미가 있습니다.
XRP와 STR에 대한 더 깊은 이해
예를 들어 위의 차트에서 XRP (리플
흥미롭게도, 스텔라와 리플은 매우 유사한 금융 기술 플랫폼이며, 둘 다 은행 간의 국경 간 송금의 지루한 단계를 줄이는 것을 목표로합니다. 일부 대형 플레이어와 헤지 펀드는 블록체인 서비스에서 사용하는 토큰의 유사성을 고려하여 스텔라와 리플에 대한 투자에 유사한 거래 전략을 사용할 수 있습니다. 이것이 XRP가 다른 디지털 통화보다 STR에 더 관련이있는 이유입니다.
네 차례야!
위의 설명들은 대부분 추측에 근거하고 있습니다. 우리가 놓은 기초를 바탕으로 데이터에 포함된 이야기를 계속 탐구할 수 있는 수백 가지 다른 방법이 있습니다.
다음 과 같은 것 들 은 내 제안 들 중 일부 이다. 독자 들 은 다음 과 같은 방향 에서 연구 를 참조 할 수 있다.
- 전체 분석에 더 많은 디지털 통화 데이터를 추가합니다.
- 최적화 된 또는 거친 곡물 추세 시각을 얻기 위해 상관 분석의 시간 범위와 세분성을 조정하십시오.
- 거래량이나 블록체인 데이터 마이닝에서 트렌드를 찾아보세요. 원본 가격 데이터와 비교하면 미래의 가격 변동을 예측하려면 구매/판매 양 비율 데이터가 더 필요할 수 있습니다.
- 주식, 재화 및 비공식 화폐에 대한 가격 데이터를 추가하여 디지털 화폐에 관련있는 것이 무엇인지 결정합니다 (하지만 오래된 말을 잊지 마십시오.
- 이벤트 레지스트리, GDELT 및 Google 트렌드를 사용하여 특정 디지털 화폐를 둘러싼
핫 워드 의 수를 정량화하십시오. - 데이터를 사용하여 예측 가능한 기계 학습 모델을 훈련하여 내일의 가격을 예측하십시오. 더 야심 찬 사람이라면 위의 교육을 위해 반복 신경 네트워크 (RNN) 를 사용할 수도 있습니다.
- 분석을 사용하여 자동 거래 로봇을 만들 수 있습니다. 해당 응용 프로그램 프로그래밍 인터페이스 (API) 를 통해
Polonex FMZ.COM) 를 추천합니다.또는 Coinbase 의 거래소 웹 사이트에 적용 할 수 있습니다.
비트코인과 디지털 화폐의 가장 좋은 부분은 일반적으로 그들의 분산적 성격으로, 다른 어떤 자산보다 더 자유롭고 민주적입니다. 당신은 당신의 분석을 오픈 소스, 커뮤니티에 참여하거나 블로그를 작성할 수 있습니다! 나는 당신이 자기 분석에 필요한 기술을 마스터하고 미래에 어떤 투기적인 디지털 화폐 기사를 읽을 때 변증적으로 생각할 수 있는 능력을 가지고 있기를 바랍니다. 특히 데이터 지원이없는 예측. 읽어 주셔서 감사합니다. 이 튜토리얼에 대한 의견, 제안 또는 비판이 있다면, 이 튜토리얼에 메시지를 남겨주세요.https://www.fmz.com/bbs.
- 암호화폐 시장의 근본 분석을 정량화: 데이터를 스스로 이야기하도록!
- 동전圈의 기초적인 양적 연구 - 더 이상 모든
선생님들을 믿지 말고, 데이터를 객관적으로 이야기하십시오! - 양적 거래의 필수 도구 - 발명자 양적 데이터 탐색 모듈
- 모든 것을 마스터 - FMZ에 대한 소개 트레이딩 터미널의 새로운 버전 (TRB 중재 소스 코드)
- FMZ의 새로운 거래 단말기 소개 (TRB 리비트 소스 추가)
- FMZ 퀀트: 암호화폐 시장에서 공통 요구 사항 설계 예제 분석 (II)
- 80 줄의 코드에서 고주파 전략으로 뇌 없는 판매봇을 이용하는 방법
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (II)
- 80줄의 코드의 고주파 전략으로 뇌 없는 로봇을 파는 방법
- FMZ Quant: 암호화폐 시장에서 공통 요구 사항 디자인 예의 분석 (I)
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (1)