Senjata AlphaGo: Algoritma Monte Carlo, anda akan memahaminya selepas membaca ini! (dengan contoh kod)--Cetak semula
 0
23883
0
23883
Algoritma Monte Carlo, anda akan faham!
Pada 9 hingga 15 Mac tahun ini, satu peristiwa besar berlaku di dunia Go, iaitu lima pertarungan besar antara manusia dan mesin di Seoul, Korea Selatan. Keputusan pertandingan itu adalah kekalahan manusia, juara dunia Go, Lee Hsien Loong, kalah 1-4 daripada AlphaGo, program kecerdasan buatan Google. Jadi, apa itu AlphaGo dan di mana kunci untuk menang? Di sini kita akan belajar tentang algoritma: Algoritma Monte Carlo.
- ### Algoritma AlphaGo dan Monte Carlo
AlphaGo adalah sebuah program permainan Go yang dibangunkan oleh pasukan DeepMind di Google, Amerika Syarikat, dan digelar sebagai “Alpha Dog” oleh peminat China.
Dalam artikel sebelumnya, kita telah membincangkan mengenai algoritma rangkaian saraf yang sedang dibangunkan oleh Google untuk membolehkan mesin belajar secara autonomi, dan AlphaGo adalah produk yang serupa.
Wakil Presiden Persatuan Automasi China, Setiausaha Agung Wang Liyuan berkata, pereka tidak perlu mahir dalam permainan Go, hanya perlu memahami peraturan asas permainan Go. AlphaGo adalah kumpulan saintis komputer yang cemerlang, tepatnya, pakar dalam bidang pembelajaran mesin.
Jadi, apa yang menjadi kunci untuk AlphaGo untuk menjadi seorang genius yang belajar sendiri?
Apakah Algoritma Monte Carlo? Untuk menjelaskan algoritma Monte Carlo yang biasa digunakan: Jika anda mempunyai 1000 buah epal di dalam keranjang, dan anda boleh memilih yang terbesar setiap kali mata anda tertutup, anda tidak boleh mengehadkan berapa kali anda boleh memilih. Jadi, anda boleh mengambil satu secara rawak dengan mata anda tertutup, kemudian anda boleh mengambil satu secara rawak dengan yang pertama, dan anda boleh meninggalkan yang besar, dan anda boleh mengambil satu lagi secara rawak, dan anda boleh membandingkannya dengan yang terakhir, dan anda boleh meninggalkan yang besar.
Iaitu, algoritma Monte Carlo adalah bahawa semakin banyak sampel, semakin banyak penyelesaian terbaik yang dapat dijumpai, tetapi tidak dijamin akan menjadi yang terbaik, kerana jika ada 10,000 buah epal, anda mungkin dapat mencari yang lebih besar.
Ia boleh dibandingkan dengan algoritma Las Vegas: Kononnya, jika ada kunci, ada 1000 kunci untuk dipilih, tetapi hanya 1 yang betul. Oleh itu, setiap kali anda mengambil 1 kunci secara rawak untuk mencuba dan tidak membuka, ganti 1 lagi.
Oleh itu, algoritma Las Vegas adalah penyelesaian terbaik yang mungkin, tetapi tidak semestinya dapat dijumpai. Anggaplah 1000 kunci, tidak ada kunci yang dapat dibuka, kunci sebenar adalah kunci ke-1001, tetapi dalam sampel tidak ada algoritma ke-1001, algoritma Las Vegas tidak dapat mencari kunci untuk membuka kunci.
Algoritma Monte Carlo AlphaGo Go merupakan permainan yang sangat sukar untuk dipelajari oleh kecerdasan buatan, kerana ia mempunyai banyak cara yang berbeza untuk dimainkan sehingga komputer tidak dapat memahaminya. Wang Jiyun berkata: Yang pertama, Go mempunyai terlalu banyak kemungkinan. Setiap langkah Go mempunyai banyak kemungkinan, pemain Go mempunyai 19 × 19 = 361 pilihan jatuh. Dalam satu permainan 150 pusingan, terdapat 10170 kemungkinan. Kedua, peraturan terlalu halus, dalam beberapa tahap, pilihan jatuh bergantung pada intuisi yang terbentuk oleh pengalaman. Selain itu, dalam permainan Go, komputer sukar untuk membezakan kelebihan dan kelemahan permainan. Oleh itu, cabaran Go disebut sebagai rancangan Apollo untuk kecerdasan buatan.
AlphaGo bukan sekadar algoritma Monte Carlo, tetapi ia adalah versi yang lebih baik daripada algoritma Monte Carlo.
AlphaGo menggunakan algoritma carian pokok Monte Carlo dan dua rangkaian saraf mendalam untuk menyelesaikan permainan catur. Sebelum berhadapan dengan Lee Hsien Loong, Google mula-mula melatih rangkaian saraf anjing Alpha dengan hampir 30 juta langkah pasangan manusia, supaya ia dapat memprediksi bagaimana pemain catur profesional manusia jatuh. Kemudian lebih jauh lagi, AlphaGo sendiri bermain catur dengan dirinya sendiri, sehingga menghasilkan skim catur baru yang besar. Jurutera Google pernah menyatakan bahawa AlphaGo dapat mencuba berjuta langkah sehari.
Tugas mereka adalah untuk bekerjasama dalam memilih langkah-langkah yang lebih menjanjikan, membuang yang jelas, dan mengawal pengiraan dalam apa yang boleh dilakukan oleh komputer. Pada dasarnya, ini adalah sama seperti yang dilakukan oleh pemain catur manusia.
Pengkaji Institut Automasi Akademi Sains China, Yi Jianqiang, mengatakan bahawa perisian permainan permainan tradisional Liu, biasanya menggunakan carian ganas, termasuk komputer biru gelap, yang membina pokok carian untuk semua hasil yang mungkin (setiap hasil adalah buah di pokok), dan melakukan pencarian merentasi sesuai dengan keperluan. Kaedah ini juga boleh dilaksanakan dalam bidang catur, catur, dan lain-lain, tetapi tidak dapat dilaksanakan untuk permainan go, kerana go merentasi 19 baris, kemungkinan jatuhnya terlalu besar sehingga komputer tidak dapat membina pokok ini (terlalu banyak buah) untuk melakukan pencarian merentasi.
Dia menjelaskan bahawa satu unit yang paling asas dalam rangkaian saraf mendalam adalah seperti neuron dalam otak manusia, dengan banyak lapisan yang disambungkan seolah-olah ia adalah rangkaian saraf dalam otak manusia. Dua rangkaian saraf AlphaGo adalah rangkaian strategi dan rangkaian penilaian.
Rangkaian strategi kebal digunakan terutamanya untuk menghasilkan strategi kejatuhan. Dalam proses bermain catur, ia tidak mempertimbangkan bagaimana ia harus turun, tetapi memikirkan bagaimana tangan manusia yang lebih baik akan turun. Iaitu, ia akan meramalkan di mana permainan catur manusia akan datang berdasarkan keadaan semasa papan catur input, dan mengemukakan beberapa keputusan yang boleh dilaksanakan yang paling sesuai dengan pemikiran manusia.
Walau bagaimanapun, rangkaian strategi tidak tahu sama ada langkah yang mereka keluarkan adalah baik atau tidak, ia hanya tahu sama ada langkah itu sama dengan langkah manusia, dan ketika itu rangkaian penilaian diperlukan untuk berfungsi.
Mengulas mengenai strategi yang digunakan dalam rangkaian penaksiran, Dr. Dungach berkata: “Rangkaian penaksiran penaksiran penaksiran penaksiran akan menilai keseluruhan penataan untuk setiap pilihan yang boleh dilakukan, dan kemudian memberikan penaksiran kadar kemenangan. Nilai-nilai ini akan dikemukakan ke dalam algoritma carian pokok Monte Carlo, yang akan menghasilkan langkah dengan penaksiran tertinggi dengan proses berulang seperti di atas. Algoritma carian pokok Monte Carlo memutuskan bahawa rangkaian strategi hanya akan diteruskan di mana penaksiran penaksiran penaksiran yang lebih tinggi, sehingga dapat membuang beberapa laluan, tanpa mengira jalan ke hitam”.
AlphaGo menggunakan kedua-dua alat ini untuk menganalisis keadaan dan menilai kelebihan dan kekurangan setiap strategi yang akan datang, seperti pemain permainan manusia yang akan menilai keadaan semasa dan mengandaikan keadaan masa depan. Dengan menggunakan algoritma carian pokok Monte Carlo untuk menganalisis contohnya 20 langkah masa depan, ia dapat menentukan di mana peluang kemenangan yang akan datang akan tinggi.
Walau bagaimanapun, tidak ada keraguan bahawa algoritma Monte Carlo adalah salah satu teras AlphaGo.
Dua eksperimen kecil Akhirnya, lihat dua eksperimen kecil dengan algoritma Monte Carlo.
- ### 1. Hitung peratusan pi.
Prinsip: Mula-mula lukis sebuah segi empat, lukislah bulatan di dalamnya, kemudian lukis titik rawak di dalam segi empat, dan letakkan titik di dalam bulatan kira-kira P, maka P = kawasan bulatan / kawasan segi empat. P=(Pi*R*R)/(2R*2R) = Pi/4, iaitu Pi = 4P
Langkah seterusnya: 1. Letakkan pusat bulatan pada titik asal dan buat bulatan dengan R sebagai radius, maka 1⁄4 kawasan bulatan pada kuadran pertama adalah Pi*R*R/4 2. Buat segi empat luar lingkaran 1 / 4, koordinat adalah ((0,0) ((0,R) ((R,0) ((R,R), maka kawasan segi empat adalah R*R 3. Pilih titik ((X,Y)), sehingga 0<=X<=R dan 0<=Y<=R, iaitu titik dalam segi empat 4. Melalui formula X*X+Y*Y*R menilai titik dalam 1⁄4 lingkaran. 5. Letakkan semua titik ((iaitu bilangan percubaan) adalah N, dan titik dalam 1⁄4 lingkaran ((iaitu titik yang memenuhi langkah 4) adalah M,
P=M/N, Pi=4*N/M
 Gambar 1
Gambar 1
Hasil M_C(10000) ialah 3.1424
- ### 2. Monte Carlo mensimulasikan nilai terma fungsi, mengelakkan terjerumus ke dalam nilai terma tempatan
# di antara[-2,2] secara rawak menghasilkan satu nombor, mencari y yang sesuai, dan mencari yang terbesar di dalamnya yang dianggap sebagai fungsi di[-2,2] nilai maksimum
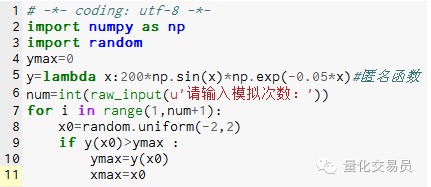 Gambar 2
Gambar 2
Simulasi 1000 kali menemui nilai maksimum 185.12292832389875 (sangat tepat)
Lihat ini, anda faham. Kod boleh ditulis dengan tangan, ia menarik! Dipetik daripada WeChat Public