Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (5)
Penulis:Lydia, Dicipta: 2023-08-10 15:57:27, Dikemas kini: 2023-09-12 15:51:54
Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (5)
Dalam artikel sebelumnya, pelbagai kaedah untuk mengira harga pertengahan diperkenalkan, dan harga pertengahan yang disemak semula dicadangkan.
Data yang diperlukan
Kami memerlukan data aliran pesanan dan data kedalaman untuk sepuluh peringkat atas buku pesanan, yang dikumpulkan dari perdagangan langsung dengan kekerapan kemas kini 100ms. demi kesederhanaan, kami tidak akan memasukkan kemas kini masa nyata untuk harga tawaran dan permintaan. Untuk mengurangkan saiz data, kami hanya menyimpan 100,000 baris data kedalaman dan memisahkan data pasaran tik-by-tik ke dalam lajur individu.
Dalam [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
Dalam [2]:
tick_size = 0.0001
Dalam [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
Dalam [4]:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
Dalam [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
Dalam [6]:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
Dalam [7]:
depths = depths.iloc[:100000]
Dalam [8]:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
Dalam [9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
Dalam [10]:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
Dalam [11]:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
Lihatlah pembahagian pasaran dalam 20 tahap ini. Ia adalah selaras dengan jangkaan, dengan lebih banyak pesanan yang diletakkan jauh dari harga pasaran. Di samping itu, pesanan beli dan pesanan jual kira-kira simetri.
Dalam [14]:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Keluar[14]:
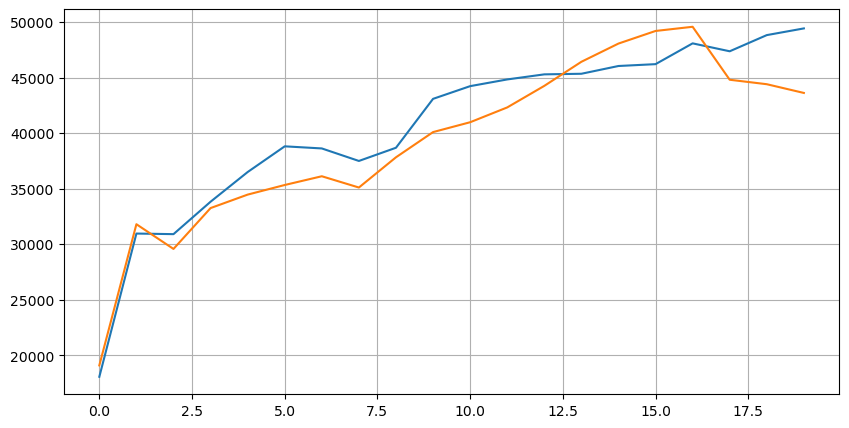
Gabungkan data kedalaman dengan data transaksi untuk memudahkan penilaian ketepatan ramalan. Pastikan data transaksi lebih lambat daripada data kedalaman. Tanpa mempertimbangkan latensi, langsung mengira kesilapan kuadrat purata antara nilai yang diramalkan dan harga transaksi sebenar. Ini digunakan untuk mengukur ketepatan ramalan.
Dari hasil, ralat adalah tertinggi untuk nilai purata harga tawaran dan permintaan (mid_price). Walau bagaimanapun, apabila ditukar kepada harga pertengahan yang ditimbang, ralat segera berkurangan dengan ketara. Penambahbaikan lebih lanjut diperhatikan dengan menggunakan harga pertengahan yang ditimbang yang disesuaikan. Selepas menerima maklum balas menggunakan I ^ 3 / 2 sahaja, ia diperiksa dan mendapati bahawa hasilnya lebih baik. Setelah merenung, ini mungkin disebabkan oleh kekerapan peristiwa yang berbeza. Apabila I dekat dengan -1 dan 1, ia mewakili peristiwa kebarangkalian rendah. Untuk membetulkan untuk peristiwa kebarangkalian rendah ini, ketepatan meramalkan peristiwa kekerapan tinggi terganggu. Oleh itu, untuk mengutamakan peristiwa kekerapan tinggi, beberapa penyesuaian dibuat (parameter ini semata-mata percubaan dan kesilapan dan mempunyai kepentingan praktikal yang terhad dalam perdagangan langsung).
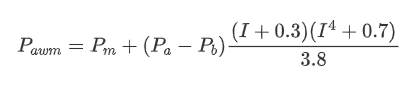
Hasilnya telah sedikit bertambah baik. Seperti yang disebutkan dalam artikel sebelumnya, strategi harus bergantung pada lebih banyak data untuk ramalan. Dengan ketersediaan lebih banyak data transaksi dan pesanan, peningkatan yang diperolehi daripada memberi tumpuan kepada buku pesanan sudah lemah.
Dalam [15]:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
Dalam [17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
Dalam [18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
Keluar [1]:
Nilai purata Kesalahan dalam harga pertengahan: 0.0048751924999999845 Kesilapan jumlah pesanan yang menunggu ditimbang harga pertengahan: 0.0048373440193987035 Kesilapan harga pertengahan yang disesuaikan: 0.004803654771638586 Kesilapan harga pertengahan yang diselaraskan: 0.004808216498329721 Kesilapan harga_tengah_3 yang disesuaikan: 0.004794984755260528 Kesilapan harga_tengah_4 yang disesuaikan: 0.0047909595497071375
Pertimbangkan Tahap Kedua Kedalaman
Kita boleh mengikuti pendekatan dari artikel sebelumnya untuk memeriksa pelbagai julat parameter dan mengukur sumbangannya kepada harga pertengahan berdasarkan perubahan harga transaksi.
Menggunakan pendekatan yang sama untuk tahap kedua kedalaman, kita mendapati bahawa walaupun kesannya sedikit lebih kecil daripada tahap pertama, ia masih signifikan dan tidak boleh diabaikan.
Berdasarkan sumbangan yang berbeza, kami menetapkan berat yang berbeza kepada tiga tahap parameter ketidakseimbangan ini. Dengan memeriksa kaedah pengiraan yang berbeza, kami melihat pengurangan lagi dalam kesilapan ramalan.
Dalam [19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
Keluar[19]:
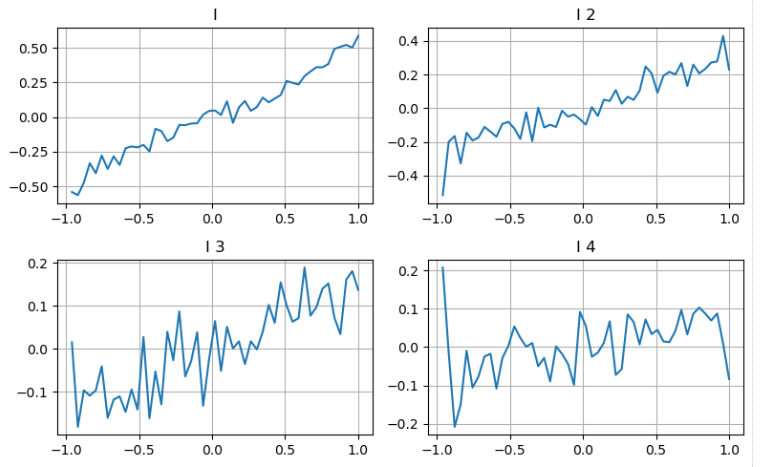
Dalam [20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
Dalam [21]:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
Keluar[21]:
Kesilapan harga_tengah_4 yang disesuaikan: 0.0047909595497071375 Kesilapan harga_tengah_5 yang disesuaikan: 0.0047884350488318714 Kesilapan harga_tengah_terakord: 0.0047778319053133735 Kesilapan harga_tengah_7 yang disesuaikan: 0.004773578540592192 Kesilapan harga_tengah_terakord: 0.004771415189297518
Mempertimbangkan Data Transaksi
Data transaksi secara langsung mencerminkan tahap kedudukan panjang dan pendek. Lagipun, transaksi melibatkan wang sebenar, sementara meletakkan pesanan mempunyai kos yang jauh lebih rendah dan bahkan boleh melibatkan penipuan yang disengajakan. Oleh itu, ketika meramalkan harga pertengahan, strategi harus memberi tumpuan kepada data transaksi.
Dari segi bentuk, kita boleh mentakrifkan ketidakseimbangan purata kuantiti pesanan yang tiba sebagai VI, dengan Vb dan Vs mewakili purata kuantiti pesanan beli dan jual dalam selang masa satu unit, masing-masing.
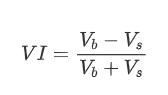
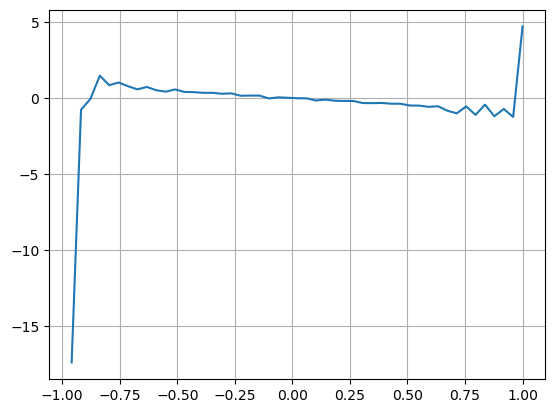
Hasilnya menunjukkan bahawa kuantiti kedatangan dalam tempoh masa yang singkat mempunyai kesan yang paling signifikan terhadap ramalan perubahan harga. Apabila VI adalah antara 0.1 dan 0.9, ia berkorelasi negatif dengan harga, sementara di luar julat ini, ia berkorelasi positif dengan harga. Ini menunjukkan bahawa apabila pasaran tidak melampau dan terutama berayun, harga cenderung kembali ke purata. Walau bagaimanapun, dalam keadaan pasaran yang melampau, seperti apabila terdapat sebilangan besar pesanan beli yang melampaui pesanan jual, trend muncul. Walaupun tanpa mempertimbangkan senario kebarangkalian rendah ini, mengandaikan hubungan linear negatif antara trend dan VI mengurangkan ramalan kesilapan harga pertengahan dengan ketara. Gabungan
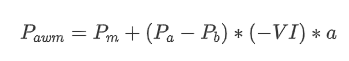
Dalam [22]:
alpha=0.1
Dalam [23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
Dalam [24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
Dalam [25]:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
Dalam [26]:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
Dalam [27]:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
Keluar[27]:
Dalam [28]:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
Dalam [29]:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
Keluar[29]:
Kesilapan harga pertengahan yang disesuaikan: 0.0048373440193987035 Kesilapan harga_tengah_9 yang disesuaikan: 0.004629586542840461 Kesilapan harga_tengah_10 yang disesuaikan: 0.004401790287167206
Harga Pertengahan Komprehensif
Memandangkan kedua-dua data buku pesanan dan data urus niaga adalah berguna untuk meramalkan harga pertengahan, kita boleh menggabungkan kedua-dua parameter ini bersama-sama. Penugasan berat dalam kes ini adalah sewenang-wenang dan tidak mengambil kira keadaan sempadan. Dalam kes yang melampau, harga pertengahan yang diramalkan mungkin tidak jatuh antara harga tawaran dan harga permintaan. Walau bagaimanapun, selagi kesilapan ramalan dapat dikurangkan, butiran ini tidak menjadi perhatian besar.
Pada akhirnya, ralat ramalan dikurangkan dari 0.00487 kepada 0.0043. Pada ketika ini, kita tidak akan menggali lebih lanjut dalam topik ini. Masih ada banyak aspek yang perlu diterokai ketika meramalkan harga pertengahan, kerana pada dasarnya meramalkan harga itu sendiri. Semua orang digalakkan untuk mencuba pendekatan dan teknik mereka sendiri.
Dalam [30]:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
Dalam [31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
Keluar[31]:
Kesilapan harga_tengah_11 yang disesuaikan: 0.0043001941412563575
Ringkasan
Artikel ini menggabungkan data kedalaman dan data transaksi untuk meningkatkan lagi kaedah pengiraan harga pertengahan. Ia menyediakan kaedah untuk mengukur ketepatan dan meningkatkan ketepatan ramalan perubahan harga. Secara keseluruhan, parameter tidak ketat dan hanya untuk rujukan. Dengan harga pertengahan yang lebih tepat, langkah seterusnya adalah untuk menjalankan backtesting menggunakan harga pertengahan dalam aplikasi praktikal. Bahagian kandungan ini luas, jadi kemas kini akan dihentikan untuk tempoh masa.
- Delta Hedge Bitcoin Options dengan Gelak Curve
- Pemikiran mengenai Strategi Perdagangan Frekuensi Tinggi (4)
- Berfikir tentang strategi perdagangan frekuensi tinggi (5)
- Memikirkan strategi perdagangan frekuensi tinggi (4)
- Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (3)
- Pemikiran mengenai strategi perdagangan frekuensi tinggi (3)
- Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (2)
- Berfikir tentang strategi perdagangan frekuensi tinggi ((2)
- Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (1)
- Memikirkan strategi perdagangan frekuensi tinggi (1)
- Dokumen Penerangan Konfigurasi Sekuriti Futu