Máquinas de vetores de suporte no cérebro
 0
2106
0
2106
Máquinas de vetores de suporte no cérebro
A máquina vetorial de suporte (SVM) é um importante classificador de aprendizagem de máquina que usa uma engenhosa transformação não-linear para projetar características de baixa dimensão em alta dimensão e executar tarefas de classificação mais complexas. A SWM parece usar um truque matemático, mas coincidentemente corresponde ao mecanismo de codificação do cérebro. Podemos ler a partir de um artigo da Nature de 2013 para entender a ligação profunda entre o aprendizado de máquina e o funcionamento do cérebro. Nome do artigo: The importance of mixed selectivity in complex cognitive tasks (by Omri Barak al. )
- #### SVM
Em primeiro lugar, vamos falar sobre a natureza da codificação neural: os animais recebem um sinal e agem de acordo com ele, um é a conversão de sinais externos em sinais neuroeletrônicos, o outro é a conversão de sinais neuroeletrônicos em sinais de decisão, o primeiro processo é chamado de codificação, o segundo processo é chamado de decodificação. O verdadeiro propósito da codificação neural é a decodificação e depois a tomada de decisão. Portanto, a decodificação visual do código com aprendizagem de máquina, a maneira mais fácil de fazer isso é olhar para um classificador, ou mesmo um classificador linear de um modelo logístico, e assim classificar os sinais de entrada de acordo com certas características. Por exemplo, ver um tigre fugir, ver um macaco comer um filhote.
Então vamos ver como a codificação do neurônio é feita. Primeiro, o neurônio pode ser visto como um circuito RC que ajusta a resistência e a capacidade de acordo com a tensão externa. Quando o sinal externo é grande o suficiente, ele é conduzido, ou fechado, para representar um sinal através da frequência de emissão de eletricidade em um determinado tempo.
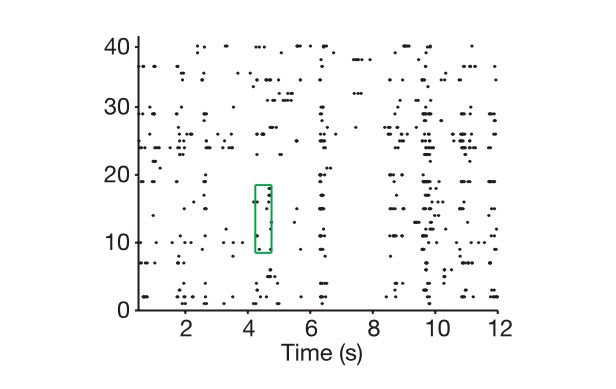
Graficamente, a vertical é a célula e a horizontal é o tempo, e isso mostra como extraímos o código neural.
É claro que há uma diferença entre o vector n-dimensional e o código neural em termos de dimensões reais. Como definir a dimensão real do código neural? Primeiro, entramos neste espaço n-dimensional marcado por um vector n-dimensional, depois damos todos os conjuntos possíveis de tarefas, como mostrar-lhe mil imagens, assumindo que estas imagens representam o mundo inteiro, marcando cada vez que recebemos um código neural como um ponto neste espaço, e finalmente, usando o pensamento da álgebra vetorial, vemos a dimensão do subespaço que compõe os mil pontos, ou seja, a dimensão real da representação neural.
Para além da dimensão real da codificação, temos um conceito de dimensão real do sinal externo, onde o sinal é o sinal externo expresso pela rede neural. Claro que temos que repetir todos os pormenores do sinal externo. É uma questão infinita, mas a base de classificação e decisão é sempre a característica chave, um processo de redução de dimensão, que é a ideia da PCA.
Então, os cientistas têm um problema central: por que usar uma dimensão de código e um número de neurónios muito maior do que o problema real para resolver este problema?
E a neurociência computacional e a aprendizagem de máquina juntas nos dizem que as características de alta dimensão das representações neurais são a base para a sua capacidade de aprendizagem superior. Quanto maior a dimensão da codificação, maior a capacidade de aprendizagem.
Observe que a codificação neural discutida aqui refere-se principalmente à codificação neural de centros nervosos superiores, como o pré-frontal cortex (PFC) discutido no texto, pois as leis de codificação de centros nervosos inferiores não envolvem muito classificação e decisão.
Regiões do cérebro superior representadas pelo PFC
O mistério da codificação neural também é revelado pela relação entre o número de neurônios, N, e a dimensão do problema real, K (uma diferença que pode chegar a 200 vezes). Por que um número de neurônios aparentemente redundante pode trazer um salto qualitativo? Primeiro, assumimos que, quando a nossa dimensão de codificação é igual à dimensão de uma variável chave na tarefa real, não seremos capazes de lidar com problemas de classificação não-lineares usando um classificador linear (assumindo que você quer separar um melão de um melão, você não pode separar o melão de um melão com uma borda linear), o que também é um problema típico que temos dificuldade em resolver quando o aprendizado profundo e o SVM não entram no aprendizado de máquina.
SVM (suporte para vectores):
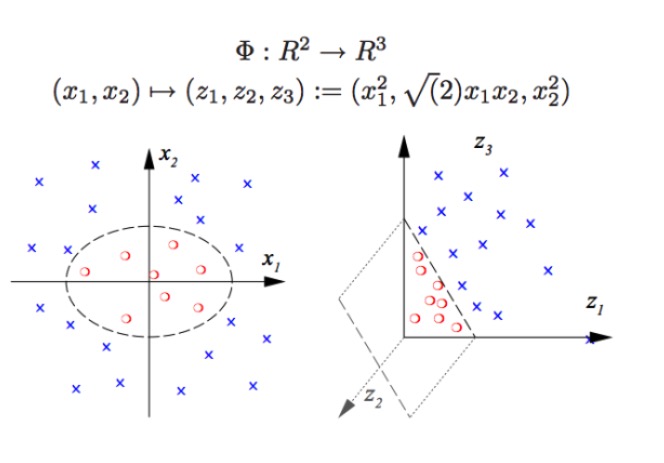
SVM pode fazer classificação não-linear, por exemplo, separar os pontos vermelhos e azuis do gráfico, com fronteiras lineares, não podemos separar os pontos vermelhos e azuis (imagem à esquerda), portanto, o método usado por SVM é aumentar a dimensão. Ao invés de simplesmente aumentar o número de variáveis, é impossível, por exemplo, mapear (x1, x2) para (x1, x2, x1 + x2) sistema de fato é um espaço linear bidimensional (desenhar um gráfico individual é dizer que os pontos vermelhos e os pontos azuis estão em um mesmo plano), apenas usando a função não-linear (x1 ^ 2, x1)*x2, x2^2) temos uma transição substancial de baixa dimensão para alta dimensão, então você coloca o ponto azul no ar, e você desenha um plano no ar, e você separa o ponto azul do ponto vermelho, como na figura à direita.
Na verdade, o que as redes neurais reais fazem é exatamente o mesmo. O tipo de classificação que um classificador linear como este pode fazer é muito maior, ou seja, temos uma capacidade de reconhecimento de padrões muito mais forte do que antes.
Então, como obter uma alta dimensão de neurônio codificado? O número de neurônios de luz é inútil. Porque aprendemos com a álgebra linear, sabemos que, se tivermos um grande número de N neurônios, e a descarga de cada neurônio é linearmente associada a apenas K características-chave, então a dimensão que finalmente representamos será igual à dimensão do problema em si, e seus N neurônios não terão qualquer função (… os neurônios excedentes são antes uma combinação linear de K neurônios).
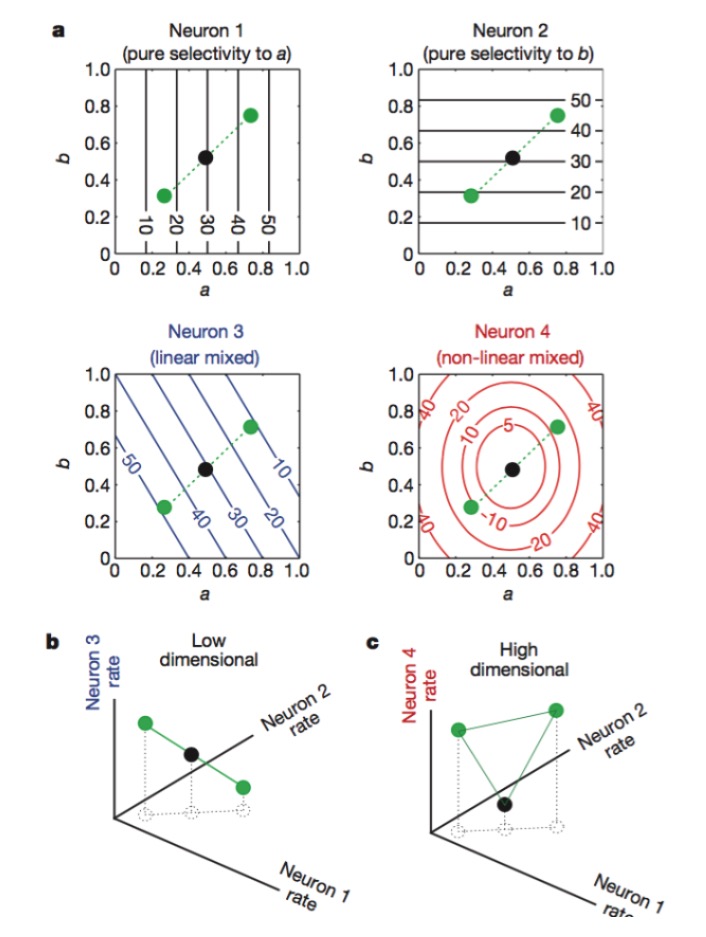
Figura: Os neurónios 1 e 2 são sensíveis apenas aos traços a e b, 3 aos traços a e b de mistura linear, e 4 aos traços de mistura não linear. Finalmente, apenas a combinação de neurónios 1, 2, 4 aumenta a dimensão da codificação neural (Figura abaixo).
O nome oficial para esta codificação é “mixed selectivity” (codificação mista), que nos pareceu incompreensível quando não se descobriu o princípio de tal codificação, uma vez que é uma rede neural que responde a um tipo de sinal de forma desordenada. No sistema nervoso circundante, os neurônios atuam como sensores, extraindo e reconhecendo diferentes características do sinal. A função de cada neurônio é bastante específica, como os rods e cones da retina são responsáveis por receber os fotônios, e depois a célula gangelion continua a codificar, cada neurônio é como um sentinela treinado.
Cada detalhe da Natureza é um subconjunto, uma grande quantidade de redundância e de codificação mista que parece não ser profissional, que parece um sinal confuso, que acaba por obter uma melhor capacidade de computação.
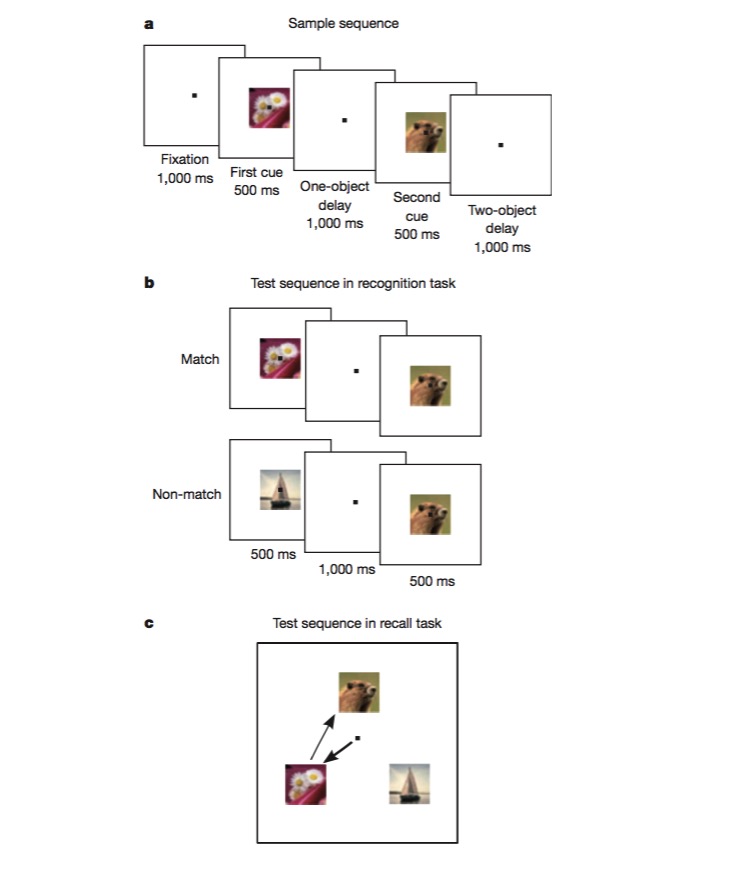
Nesta tarefa, os macacos são treinados primeiro para distinguir se uma imagem é a mesma que a anterior (reconhecimento), e depois são treinados para julgar a sequência em que duas imagens diferentes aparecem (recolha). Para realizar essa tarefa, os macacos precisam ser capazes de codificar diferentes aspectos da tarefa, como o tipo de tarefa (recolha ou reconhecimento), o tipo de imagem, etc., o que é um excelente teste para testar se há um mecanismo de codificação não linear híbrido.
Depois de ler este artigo, percebemos que a criação de redes neurais pode melhorar muito a capacidade de reconhecimento de padrões, se introduzirmos algumas unidades não-lineares, e o SVM, por acaso, aplicou isso para lidar com o problema de classificação não-linear.
Estudamos o funcionamento das áreas do cérebro, processando dados com métodos de aprendizagem de máquina, como encontrar as dimensões-chave do problema com o PCA, depois com o pensamento que reconhece o padrão de aprendizagem de máquina para entender a codificação e decodificação neural, e finalmente, se tivermos alguma inspiração nova, podemos melhorar o método de aprendizagem de máquina. Para o cérebro ou para o algoritmo de aprendizagem de máquina, o mais importante é obter a melhor representação adequada da informação, e com uma boa representação, tudo é mais fácil.
A tecnologia do navio de cruzeiro