Reflexões sobre estratégias de negociação de alta frequência (1)
Autora:Lydia., Criado: 2023-08-04 13:47:39, Atualizado: 2023-09-12 15:50:10
Reflexões sobre estratégias de negociação de alta frequência (1)
Escrevi dois artigos sobre negociação de alta frequência de moedas digitais, nomeadamente
Fonte de lucros de alta frequência
Em meus artigos anteriores, mencionei que as estratégias de alta frequência são particularmente adequadas para mercados com flutuações extremamente voláteis. As mudanças de preço de um instrumento de negociação dentro de um curto período de tempo consistem em tendências e oscilações gerais. Embora seja realmente lucrativo se pudermos prever com precisão as mudanças de tendência, este também é o aspecto mais desafiador. Neste artigo, vou me concentrar principalmente em estratégias de fabricantes de alta frequência e não vou mergulhar na previsão de tendência.
Problemas a serem resolvidos
-
O primeiro problema na implementação de uma estratégia que coloca ordens de compra e venda é determinar onde colocar essas ordens. Quanto mais próximas as ordens são colocadas à profundidade do mercado, maior a probabilidade de execução. No entanto, em condições de mercado altamente voláteis, o preço a que uma ordem é instantaneamente executada pode estar longe da profundidade do mercado, resultando em lucro insuficiente. Por outro lado, colocar ordens muito longe reduz a probabilidade de execução. Este é um problema de otimização que precisa ser abordado.
-
O controle de posição é crucial para gerenciar o risco. Uma estratégia não pode acumular posições excessivas por períodos prolongados. Isso pode ser abordado controlando a distância e a quantidade de ordens colocadas, bem como estabelecendo limites para as posições globais.
Para alcançar os objetivos acima, a modelagem e a estimativa são necessárias para vários aspectos, como probabilidades de execução, lucro de execuções e estimativa de mercado. Existem inúmeros artigos e artigos disponíveis sobre este tópico, usando palavras-chave como
Dados exigidos
A Binance oferecedados para descarregamentoPara fins de backtesting, dados comerciais agregados são suficientes. Neste artigo, usaremos o exemplo de dados HOOKUSDT-aggTrades-2023-01-27.
Em [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Os dados comerciais individuais incluem os seguintes:
- O valor da transação agregada é o valor da transação agregada.
- Preço: O preço ao qual a operação foi executada.
- Quantidade: a quantidade da transacção.
- O primeiro_trade_id: nos casos em que várias transacções são agregadas, representa o ID da primeira transação.
- Last_trade_id: O ID da última transação na agregação.
- transact_time: O carimbo de tempo da execução da operação.
- is_buyer_maker: Indica a direção do comércio.
True representa uma ordem de compra executada como um maker, enquanto uma ordem de venda é executada como um taker.
Pode-se ver que houve 660.000 transacções executadas naquele dia, indicando um mercado altamente ativo.
Em [4]:
trades = pd.read_csv('COMPUSDT-aggTrades-2023-07-02.csv')
trades
Fora[4]: Não, não, não, não, não, não, não, não, não, não, não, não, não, não...
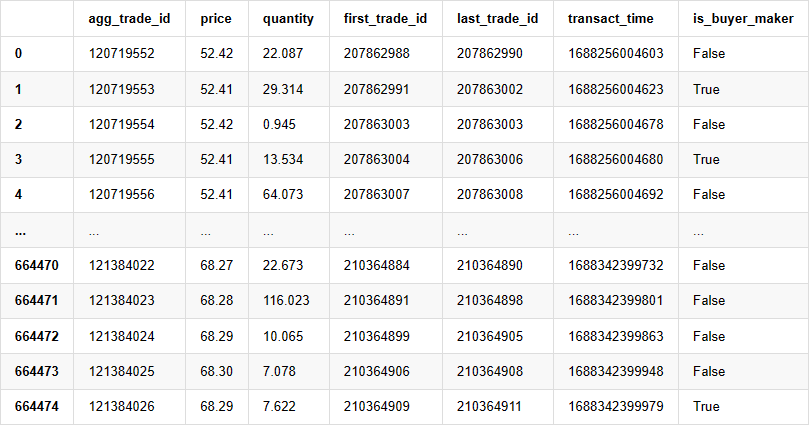
664475 linhas × 7 colunas
Modelagem do montante do comércio individual
Em primeiro lugar, os dados são processados dividindo as transações originais em dois grupos: ordens de compra executadas como fabricantes e ordens de venda executadas como tomadores. Além disso, os dados comerciais agregados originais combinam transações executadas ao mesmo tempo, no mesmo preço e na mesma direção em um único ponto de dados. Por exemplo, se houver uma única ordem de compra com um volume de 100, ela pode ser dividida em dois negócios com volumes de 60 e 40, respectivamente, se os preços forem diferentes. Isso pode afetar a estimativa dos volumes de ordem de compra. Portanto, é necessário agregar os dados novamente com base no transact_time. Após esta segunda agregação, o volume de dados é reduzido em 140.000 registros.
Em [6]:
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
sell_trades = trades[trades['is_buyer_maker']==True].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
sell_trades = sell_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
sell_trades['interval']=sell_trades['transact_time'] - sell_trades['transact_time'].shift()
Em [10]:
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
Fora [10]: Câmara de deputados
O resultado é que a maioria das transações é distribuída na parte mais esquerda do histograma, mas há também algumas grandes transações distribuídas na parte mais baixa.
Em [36]:
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
Fora [36]:
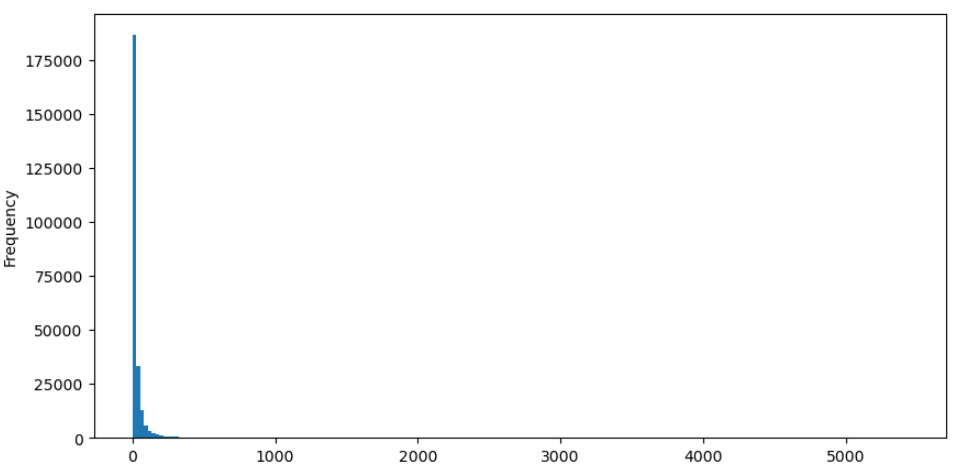
Para uma observação mais fácil, vamos cortar a cauda e analisar os dados.
Em [37]:
buy_trades['quantity'][buy_trades['quantity']<200].plot.hist(bins=200,figsize=(10, 5));
Fora [37]:
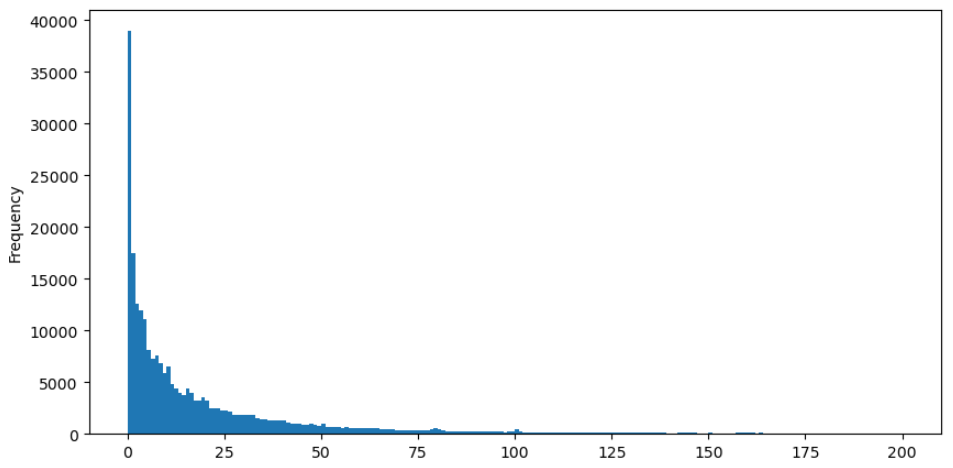
Houve inúmeros estudos sobre a distribuição de quantidades de comércio. Verificou-se que as quantidades de comércio seguem uma distribuição de lei de potência, também conhecida como distribuição de Pareto, que é uma distribuição de probabilidade comum na física estatística e ciências sociais. Em uma distribuição de lei de potência, a probabilidade de um evento de tamanho (ou frequência) é proporcional a um expoente negativo do tamanho desse evento. A principal característica desta distribuição é que a frequência de grandes eventos (ou seja, aqueles distantes da média) é maior do que o esperado em muitas outras distribuições. Esta é precisamente a característica da distribuição de quantidades de comércio.
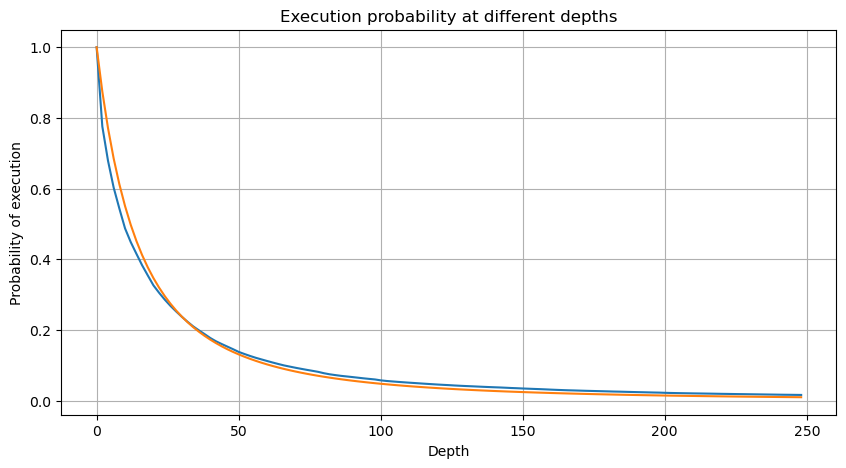
O gráfico a seguir representa a probabilidade de quantidades de negociação excederem um certo valor. A linha azul representa a probabilidade real, enquanto a linha laranja representa a probabilidade simulada. Observe que não vamos entrar nos parâmetros específicos neste ponto. Pode-se observar que a distribuição realmente segue uma distribuição de Pareto. Uma vez que a probabilidade de quantidades de negociação serem maiores que zero é 1, e para satisfazer a normalização, a equação de distribuição deve ser a seguinte:
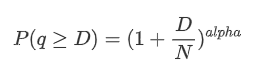
Aqui, N é o parâmetro para a normalização. Vamos escolher o valor médio do comércio, M, e definir alfa para -2.06. A estimativa específica de alfa pode ser obtida calculando o valor P quando D=N. Especificamente, alfa = log (((P(d>M)) / log ((2). A escolha de pontos diferentes pode resultar em pequenas diferenças no valor de alfa.
Em [55]:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
alpha = np.log(np.mean(buy_trades['quantity'] > mean_quantity))/np.log(2)
mean_quantity = buy_trades['quantity'].mean()
probabilities_s = np.array([(1+depth/mean_quantity)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Fora[55]:
Em [56]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
Fora[56]:
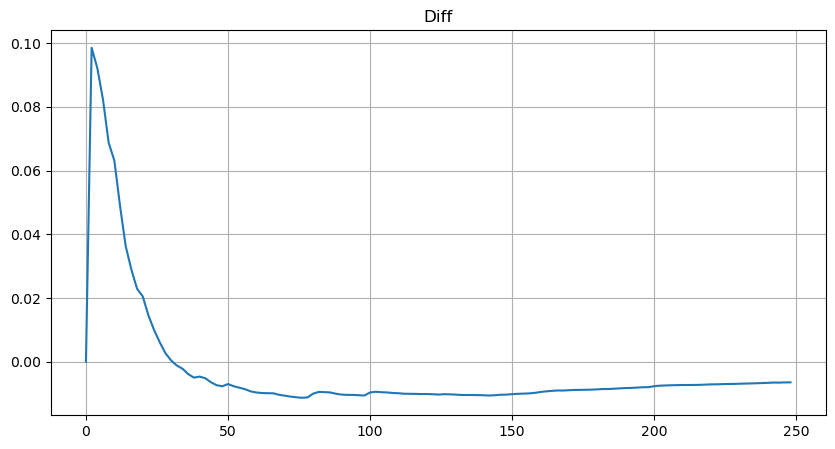
No entanto, esta estimativa é apenas aproximada, como mostrado no gráfico onde traçamos a diferença entre os valores simulados e reais. Quando o valor do comércio é pequeno, o desvio é significativo, chegando a 10%. Embora a seleção de diferentes pontos durante a estimativa do parâmetro possa melhorar a precisão da probabilidade desse ponto específico, não resolve o problema de desvio como um todo. Esta discrepância surge da diferença entre a distribuição da lei de potência e a distribuição real. Para obter resultados mais precisos, a equação da distribuição da lei de potência precisa ser modificada.
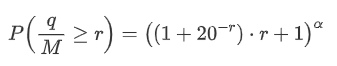
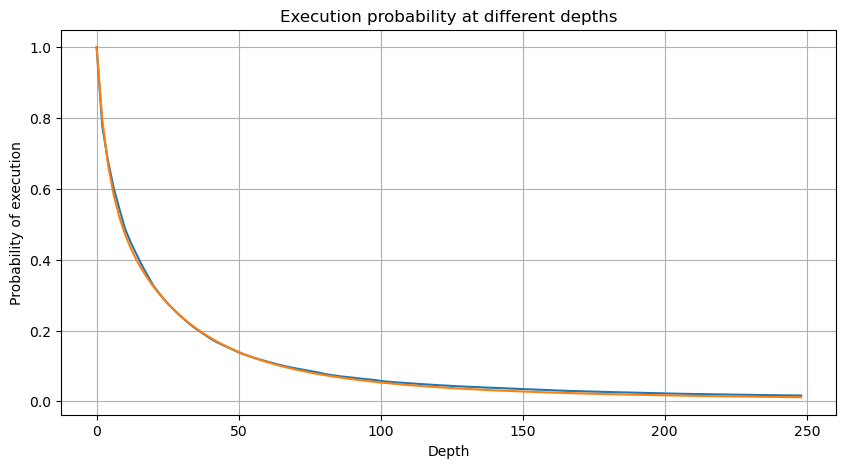
Para simplificar, vamos usar r = q / M para representar o valor do comércio normalizado. Podemos estimar os parâmetros usando o mesmo método que antes. O gráfico a seguir mostra que, após a modificação, o desvio máximo não é superior a 2%.
Em [52]:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([(((1+20**(-depth/mean))*depth+mean)/mean)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Fora[52]:
Em [53]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
Fora[53]:
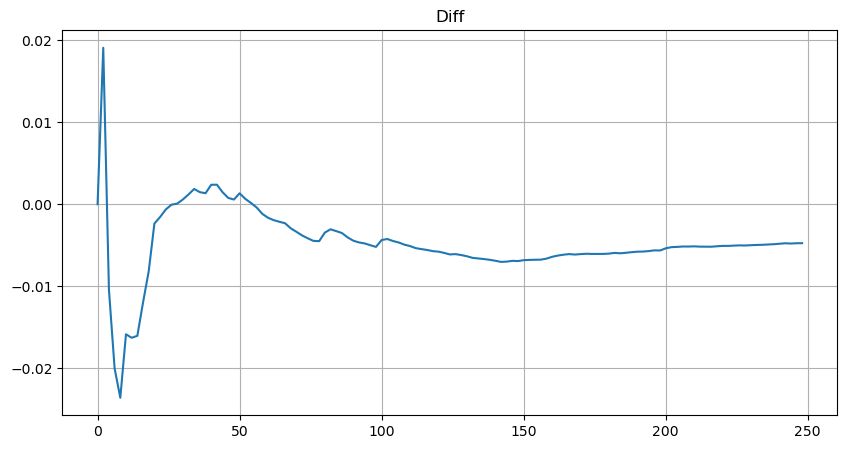
Com a equação estimada para a distribuição do valor do comércio, é importante notar que as probabilidades na equação não são as probabilidades reais, mas as probabilidades condicionais. Neste ponto, podemos responder à pergunta: Qual é a probabilidade de que a próxima ordem seja maior do que um determinado valor?
Neste ponto, o texto já é bastante longo, e ainda há muitas perguntas a serem respondidas.
- Delta hedge com curva de sorrisos para opções de Bitcoin
- Reflexões sobre estratégias de negociação de alta frequência (5)
- Reflexões sobre estratégias de negociação de alta frequência (4)
- Pensamento sobre estratégias de negociação de alta frequência (5)
- Pensamento sobre estratégias de negociação de alta frequência (4)
- Reflexões sobre estratégias de negociação de alta frequência (3)
- Reflexões sobre estratégias de negociação de alta frequência (3)
- Reflexões sobre estratégias de negociação de alta frequência (2)
- Pensamento sobre estratégias de negociação de alta frequência (2)
- Reflexões sobre estratégias de negociação de alta frequência (1)
- Documento de Descrição da Configuração dos Títulos Futu
- FMZ Quant Uniswap V3 Guia de operações relacionadas com a liquidez dos bancos de câmbio (parte 1)
- FMZ Quantificação Uniswap V3 Guia de operação relacionado à liquidez do reservatório de câmbio (1)