Reflexões sobre estratégias de negociação de alta frequência (5)
Autora:Lydia., Criado: 2023-08-10 15:57:27, Atualizado: 2023-09-12 15:51:54
Reflexões sobre estratégias de negociação de alta frequência (5)
No artigo anterior, vários métodos para calcular o preço médio foram introduzidos, e um preço médio revisto foi proposto.
Dados necessários
Precisamos de dados de fluxo de pedidos e dados de profundidade para os dez primeiros níveis da carteira de pedidos, coletados a partir de negociação ao vivo com uma frequência de atualização de 100ms. Por uma questão de simplicidade, não incluiremos atualizações em tempo real para os preços de oferta e demanda. Para reduzir o tamanho dos dados, mantivemos apenas 100.000 linhas de dados de profundidade e separamos os dados de mercado tick-by-tick em colunas individuais.
Em [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
Em [2]:
tick_size = 0.0001
Em [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
Em [4]:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
Em [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
Em [6]:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
Em [7]:
depths = depths.iloc[:100000]
Em [8]:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
Em [9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
Em [10]:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
Em [11]:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
A distribuição do mercado nesses 20 níveis está em linha com as expectativas, com mais ordens colocadas quanto mais longe do preço de mercado.
Em [14]:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Fora [1]:
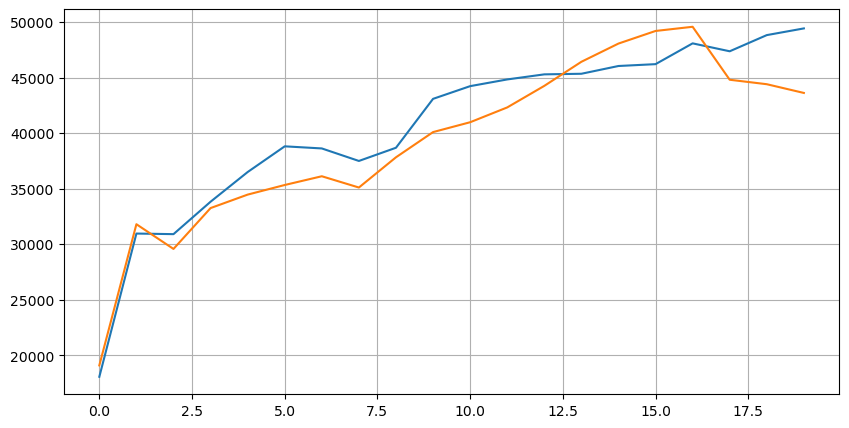
Combine os dados de profundidade com os dados de transação para facilitar a avaliação da precisão da previsão. Certifique-se de que os dados de transação sejam posteriores aos dados de profundidade. Sem considerar a latência, calcule diretamente o erro médio ao quadrado entre o valor previsto e o preço real da transação. Isso é usado para medir a precisão da previsão.
A partir dos resultados, o erro é maior para o valor médio dos preços de oferta e demanda (mid_price). No entanto, quando alterado para o preço médio ponderado, o erro diminui significativamente imediatamente. Uma melhoria adicional é observada usando o preço médio ponderado ajustado. Depois de receber feedback sobre o uso de apenas I ^ 3 / 2, foi verificado e descobriu-se que os resultados eram melhores. Após reflexão, isso é provavelmente devido às diferentes frequências de eventos. Quando eu estou perto de -1 e 1, isso representa eventos de baixa probabilidade. A fim de corrigir esses eventos de baixa probabilidade, a precisão de prever eventos de alta frequência é comprometida. Portanto, para priorizar eventos de alta frequência, alguns ajustes foram feitos (esses parâmetros foram puramente de teste e erro e têm um significado prático limitado na negociação ao vivo).
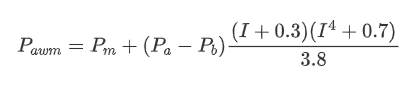
Os resultados melhoraram ligeiramente. Como mencionado no artigo anterior, as estratégias devem depender de mais dados para previsão. Com a disponibilidade de mais profundidade e dados de transações de pedidos, a melhoria obtida por se concentrar na carteira de pedidos já é fraca.
Em [15]:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
Em [17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
Em [18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
Fora [1]:
Valor médio Erro no preço médio: 0,0048751924999999845 Erro do volume de ordens pendentes ponderado no preço médio: 0,0048373440193987035 Erro do preço médio ajustado: 0,004803654771638586 Erro do preço médio ajustado: 0,004808216498329721 Erro do preço médio ajustado: 0,004794984755260528 Erro do preço médio ajustado: 0,0047909595497071375
Considere o Segundo Nível de Profundidade
Podemos seguir a abordagem do artigo anterior para examinar diferentes intervalos de um parâmetro e medir sua contribuição para o preço médio com base nas mudanças no preço da transação.
Aplicando a mesma abordagem ao segundo nível de profundidade, descobrimos que, embora o efeito seja ligeiramente menor do que o primeiro nível, ele ainda é significativo e não deve ser ignorado.
Com base nas diferentes contribuições, atribuímos diferentes ponderações a estes três níveis de parâmetros de desequilíbrio.
Em [19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
Fora [1]:
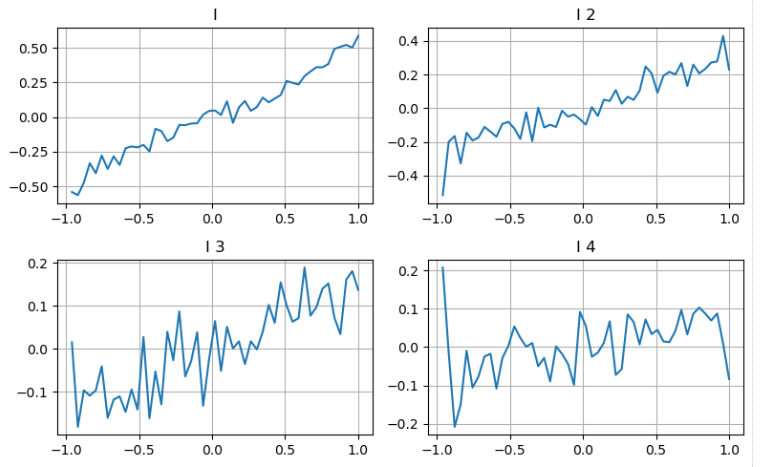
Em [20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
Em [21]:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
Fora[21]:
Erro do preço médio ajustado: 0,0047909595497071375 Erro do preço médio ajustado: 0,0047884350488318714 Erro do preço médio ajustado: 0,0047778319053133735 Erro do preço médio ajustado: 0,004773578540592192 Erro do preço médio ajustado: 0,004771415189297518
Considerando os dados de transacções
Os dados de transação refletem diretamente a extensão das posições longas e curtas. Afinal, as transações envolvem dinheiro real, enquanto a colocação de ordens tem custos muito menores e pode até envolver engano intencional. Portanto, ao prever o preço médio, as estratégias devem se concentrar nos dados da transação.
Em termos de forma, podemos definir o desequilíbrio da quantidade média de chegada de ordens como VI, com Vb e Vs representando a quantidade média de ordens de compra e venda dentro de um intervalo de tempo unitário, respectivamente.
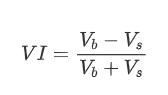
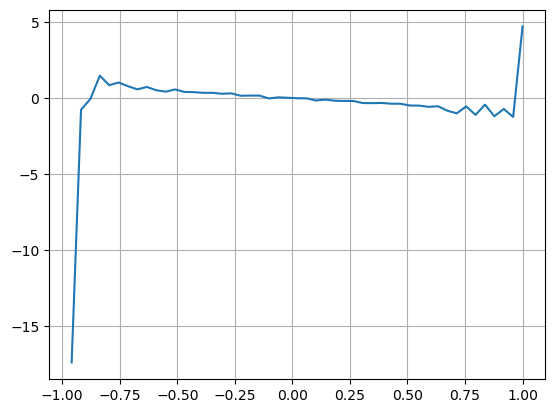
Os resultados mostram que a quantidade de chegada em um curto período de tempo tem o impacto mais significativo na previsão da mudança de preço. Quando VI está entre 0,1 e 0,9, ele está negativamente correlacionado com o preço, enquanto fora dessa faixa, ele está positivamente correlacionado com o preço. Isso sugere que quando o mercado não é extremo e principalmente oscila, o preço tende a retornar à média. No entanto, em condições extremas de mercado, como quando há um grande número de ordens de compra esmagadoras ordens de venda, uma tendência surge. Mesmo sem considerar esses cenários de baixa probabilidade, assumindo uma relação linear negativa entre a tendência e VI reduz significativamente a previsão do erro do preço médio. O coeficiente
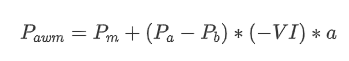
Em [22]:
alpha=0.1
Em [23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
Em [24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
Em [25]:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
Em [26]:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
Em [27]:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
Fora[27]:
Em [28]:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
Em [29]:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
Fora[29]:
Erro do preço médio ajustado: 0,0048373440193987035 Erro do preço médio ajustado: 0,004629586542840461 Erro do preço médio ajustado_10: 0,004401790287167206
O preço médio abrangente
Considerando que tanto o desequilíbrio da carteira de pedidos quanto os dados de transação são úteis para prever o preço médio, podemos combinar esses dois parâmetros juntos. A atribuição de pesos neste caso é arbitrária e não leva em conta as condições de limite. Em casos extremos, o preço médio previsto pode não cair entre os preços de oferta e demanda. No entanto, enquanto o erro de previsão puder ser reduzido, esses detalhes não são de grande preocupação.
No final, o erro de previsão é reduzido de 0,00487 para 0,0043. Neste ponto, não vamos aprofundar mais no tópico. Ainda há muitos aspectos a serem explorados quando se trata de prever o preço médio, pois é essencialmente prever o preço em si. Todos são encorajados a tentar suas próprias abordagens e técnicas.
Em [30]:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
Em [31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
Fora[31]:
Erro do preço médio ajustado_11: 0,0043001941412563575
Resumo
O artigo combina dados de profundidade e dados de transação para melhorar ainda mais o método de cálculo do preço médio. Ele fornece um método para medir a precisão e melhora a precisão da previsão de mudança de preço. No geral, os parâmetros não são rigorosos e são apenas para referência. Com um preço médio mais preciso, o próximo passo é realizar backtesting usando o preço médio em aplicações práticas. Esta parte do conteúdo é extensa, por isso as atualizações serão interrompidas por um período de tempo.
- Delta hedge com curva de sorrisos para opções de Bitcoin
- Reflexões sobre estratégias de negociação de alta frequência (4)
- Pensamento sobre estratégias de negociação de alta frequência (5)
- Pensamento sobre estratégias de negociação de alta frequência (4)
- Reflexões sobre estratégias de negociação de alta frequência (3)
- Reflexões sobre estratégias de negociação de alta frequência (3)
- Reflexões sobre estratégias de negociação de alta frequência (2)
- Pensamento sobre estratégias de negociação de alta frequência (2)
- Reflexões sobre estratégias de negociação de alta frequência (1)
- Reflexões sobre estratégias de negociação de alta frequência (1)
- Documento de Descrição da Configuração dos Títulos Futu