Modelagem e análise da volatilidade do Bitcoin com base no modelo ARMA-EGARCH
Autora:Lydia., Criado: 2022-11-15 15:32:43, Atualizado: 2023-09-14 20:30:52E o processo foi omitido.
O grau de correspondência da distribuição normal normal não é tão bom quanto a distribuição t, o que também mostra que a distribuição de rendimento tem uma cauda mais espessa do que a distribuição normal.
Em [23]:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
Fora[23]: Iteração: 1, Função Contagem: 10, Negativo LLF: -1917.4262154917305
Resultados do modelo AR-GARCH
Modelo médio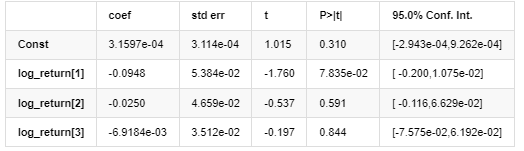
Modelo de volatilidade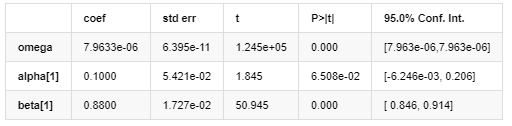
Distribuição
Estimador de covariância: robusto
Descrição da equação de volatilidade GARCH de acordo com a base de dados ARCH: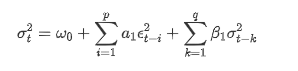
A equação de regressão condicional para a volatilidade pode ser obtida como: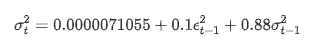
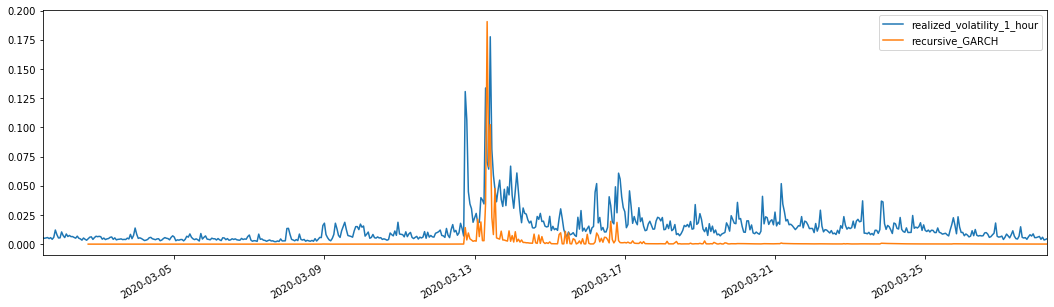
Combinado com a volatilidade prevista correspondente, compará-lo com a volatilidade real da amostra para ver o efeito.
Em [26]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Fora[26]: Erro absoluto médio (MAE): 0,0128 Percentual médio de erro absoluto (MAPE): 95,6 Erro médio quadrado da raiz (RMSE): 0,018
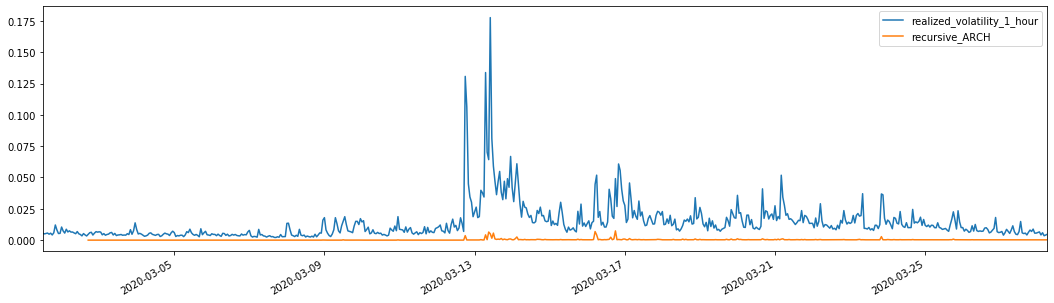
Para comparação, faça um ARCO da seguinte forma:
Em [27]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Fora[27]: Erro absoluto médio (MAE): 0,0136 Percentual médio de erro absoluto (MAPE): 98,1 Erro médio quadrado da raiz (RMSE): 0,02
7. Modelagem EGARCH
O próximo passo é executar o modelo EGARCH
Em [24]:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
Fora[24]: Iteração: 1, Func. Contagem: 11, Neg. LLF: -1966.610328148909
Resultados do modelo AR - EGARCH
Modelo médio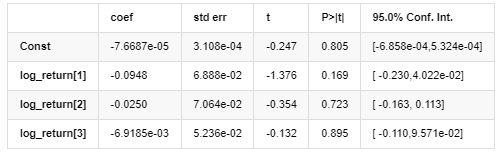
Modelo de volatilidade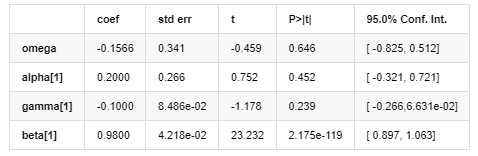
Distribuição
Estimador de covariância: robusto
A equação de volatilidade EGARCH fornecida pela biblioteca ARCH é descrita do seguinte modo: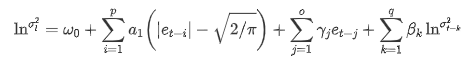
substituto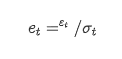
A equação de regressão condicional da volatilidade pode ser obtida da seguinte forma: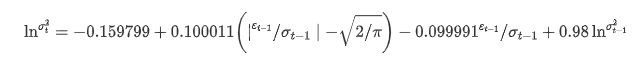
Entre eles, o coeficiente estimado do termo simétrico γ é menor que o intervalo de confiança, indicando que há uma
Combinados com a volatilidade prevista correspondente, os resultados são comparados com a volatilidade real da amostra da seguinte forma:
Em [28]:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
Fora[28]: Erro absoluto médio (MAE): 0,0201 Erro médio em percentagem absoluta (MAPE): 122 Erro médio quadrado da raiz (RMSE): 0,0279
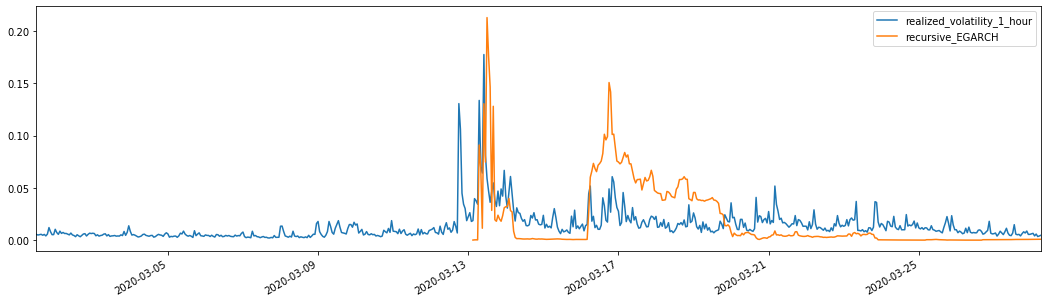
Pode-se ver que o EGARCH é mais sensível à volatilidade e corresponde melhor à volatilidade do que o ARCH e o GARCH.
8. Avaliação da previsão de volatilidade
Os dados por hora são selecionados com base na amostra, e o próximo passo é prever uma hora adiante. Selecionamos a volatilidade prevista das primeiras 10 horas dos três modelos, com RV como a volatilidade de referência. O valor de erro comparativo é o seguinte:
Em [29]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
Fora[29]: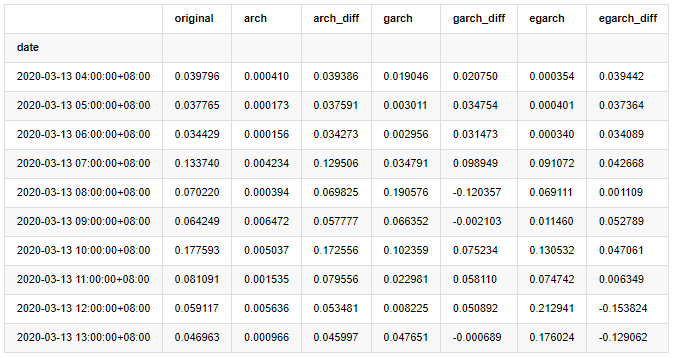
Em [30]:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
Fora[30]: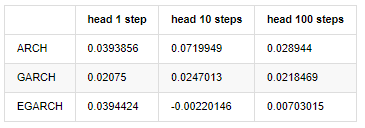
Vários testes foram realizados, nos resultados de previsão da primeira hora, a probabilidade do menor erro do EGARCH é relativamente grande, mas a diferença geral não é particularmente óbvia; Há algumas diferenças óbvias nos efeitos de previsão a curto prazo; O EGARCH tem a capacidade de previsão mais notável na previsão a longo prazo
Em [31]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
Fora[31]: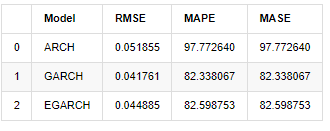
Em termos de indicadores, o GARCH e o EGARCH apresentam alguma melhoria em comparação com o ARCH, mas a diferença não é particularmente óbvia.
9. Conclusão
A partir da análise simples acima, pode-se concluir que a taxa de retorno logarítmico do Bitcoin não está em conformidade com a distribuição normal, que é caracterizada por caudas grossas, e a volatilidade tem efeito de agregação e alavancagem, ao mesmo tempo em que mostra óbvia heterogeneidade condicional.
Na previsão e avaliação da taxa de retorno logarítmico, a capacidade de previsão estática intra amostra do modelo ARMA é significativamente melhor do que a dinâmica, o que mostra que o método de rolagem é obviamente melhor do que o método iterativo, e pode evitar os problemas de supercomparação e amplificação de erro.
Além disso, ao lidar com o fenômeno da cauda grossa do Bitcoin, ou seja, a distribuição de cauda grossa dos retornos, descobriu-se que a distribuição GED (erro generalizado) é melhor do que a distribuição t e a distribuição normal significativamente, o que pode melhorar significativamente a precisão de medição do risco de cauda. Ao mesmo tempo, o EGARCH tem mais vantagens na previsão da volatilidade a longo prazo, o que explica bem a heteroscedasticidade da amostra. O coeficiente de estimativa simétrica na correspondência do modelo é menor do que o intervalo de confiança, o que indica que há uma significativa
Todo o processo de modelagem está cheio de várias suposições ousadas, e não há identificação de consistência dependendo da validade, por isso só podemos verificar cuidadosamente alguns fenômenos.
Em comparação com os mercados tradicionais, a disponibilidade de dados de alta frequência do Bitcoin é mais fácil. A medição de vários indicadores baseados em dados de alta frequência torna-se simples e importante. Se medidas não paramétricas podem fornecer uma observação rápida para o mercado que ocorreu, e medidas com parâmetros podem melhorar a precisão de entrada do modelo, então tomar as medidas não paramétricas realizadas como os hiperparâmetros do modelo pode estabelecer um modelo mais completo.
No entanto, o exposto acima é limitado à teoria. Os dados de frequência mais alta podem realmente fornecer uma análise mais precisa do comportamento dos traders. Não só podem fornecer testes mais confiáveis para modelos teóricos financeiros, mas também fornecer informações de tomada de decisão mais abundantes para os traders, até mesmo apoiar a previsão do fluxo de informações e fluxo de capital e ajudar a projetar estratégias de negociação quantitativas mais precisas. No entanto, o mercado Bitcoin é tão volátil que dados históricos muito longos não podem corresponder a informações de tomada de decisão eficazes, portanto, os dados de alta frequência certamente trarão maiores vantagens de mercado para os investidores de moeda digital.
Finalmente, se você achar que o conteúdo acima é útil, você também pode oferecer um pouco de BTC para me comprar uma xícara de Cola.
- Quantificar a análise fundamental no mercado de criptomoedas: deixe os dados falarem por si mesmos!
- A pesquisa quantitativa básica do círculo monetário - deixe de acreditar em todos os professores de matemática loucos, os dados são objetivos!
- Uma ferramenta indispensável no campo da transação quantitativa - inventor do módulo de exploração de dados quantitativos
- Dominar tudo - Introdução ao FMZ Nova versão do Terminal de Negociação (com TRB Arbitrage Source Code)
- Conheça tudo sobre a nova versão do terminal de negociação da FMZ
- FMZ Quant: Análise de Exemplos de Design de Requisitos Comuns no Mercado de Criptomoedas (II)
- Como explorar robôs de venda sem cérebro com uma estratégia de alta frequência em 80 linhas de código
- Quantificação FMZ: Análise de casos de design de necessidades comuns do mercado de criptomoedas (II)
- Como usar estratégias de 80 linhas de código de alta frequência para explorar robôs sem cérebro para venda
- FMZ Quant: Análise de Exemplos de Design de Requisitos Comuns no Mercado de Criptomoedas (I)
- Quantificação FMZ: Análise de casos de design de necessidades comuns do mercado de criptomoedas (I)