Мысли о высокочастотных торговых стратегиях (5)
Автор:Лидия., Создано: 2023-08-10 15:57:27, Обновлено: 2023-09-12 15:51:54
Мысли о высокочастотных торговых стратегиях (5)
В предыдущей статье были представлены различные методы расчета средней цены, и была предложена пересмотренная средняя цена.
Требуемые данные
Нам нужны данные о потоке заказов и глубине данных для десяти верхних уровней книги заказов, собранные из живой торговли с частотой обновления 100 мс. Ради простоты мы не будем включать обновления в режиме реального времени для цены предложения и запроса. Чтобы уменьшить размер данных, мы сохранили только 100 000 строк данных о глубине и разделили данные о рынке тик-по-тик в отдельные колонки.
В [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
В [2]:
tick_size = 0.0001
В [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
В [4]:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
В [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
В [6]:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
В [7]:
depths = depths.iloc[:100000]
В [8]:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
В [9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
В [10]:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
В [11]:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
Посмотрите на распределение рынка на этих 20 уровнях. Это соответствует ожиданиям, с большей порцией заказов, размещенных дальше от рыночной цены. Кроме того, заказы на покупку и продажу примерно симметричны.
В [14]:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Выход[14]:
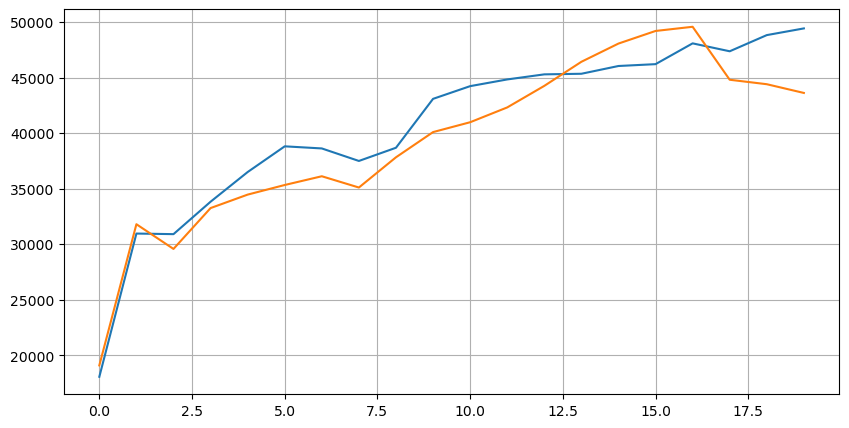
Объедините данные глубины с данными транзакции, чтобы облегчить оценку точности прогноза. Убедитесь, что данные транзакции позже, чем данные глубины. Без учета задержки, напрямую вычислите среднюю квадратную ошибку между прогнозируемым значением и фактической ценой транзакции. Это используется для измерения точности прогноза.
Из результатов ошибка наиболее высока для среднего значения цены предложения и запроса (средняя_цена). Однако, при изменении на взвешенную среднюю_цену, ошибка сразу же значительно уменьшается. Дальнейшее улучшение наблюдается с использованием скорректированной взвешенной средней_цены. После получения отзывов об использовании только I ^ 3 / 2, было проверено и установлено, что результаты были лучше. При размышлении, это, вероятно, связано с различной частотой событий. Когда I близка к -1 и 1, это представляет собой события с низкой вероятностью. Чтобы исправить эти события с низкой вероятностью, точность прогнозирования событий с высокой частотой находится в опасности. Поэтому, чтобы приоритетизировать события с высокой частотой, были внесены некоторые корректировки (эти параметры были чисто пробными и ошибовыми и имеют ограниченное практическое значение в живой торговле).
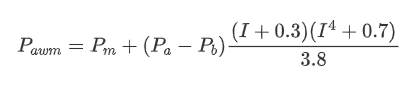
Результаты немного улучшились. Как упоминалось в предыдущей статье, стратегии должны опираться на больше данных для прогнозирования. С наличием большей глубины и данных о транзакциях с заказами улучшение, полученное от сосредоточения на книге заказов, уже слабо.
В [15]:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
В [17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
В [18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
Выход[18]:
Среднее значение Ошибка средней_цены: 0,0048751924999999845 Ошибка объема ожидаемых заказов с взвешенной средней ценой: 0,0048373440193987035 Ошибка скорректированной средней_цены: 0,004803654771638586 Ошибка скорректированной средней_цены_2: 0,004808216498329721 Ошибка скорректированной средней_цены_3: 0,004794984755260528 Ошибка скорректированной средней_цены_4: 0,0047909595497071375
Рассмотрим второй уровень глубины
Мы можем следовать подходу из предыдущей статьи, чтобы изучить различные диапазоны параметра и измерить его вклад в среднюю цену на основе изменений в цене транзакции.
Применяя тот же подход к второму уровню глубины, мы обнаруживаем, что, хотя эффект немного меньше, чем первый уровень, он все равно значителен и не должен быть проигнорирован.
Исходя из различных вкладов, мы присваиваем различные весы этим трем уровням параметров дисбаланса.
В [19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
Выход[19]:
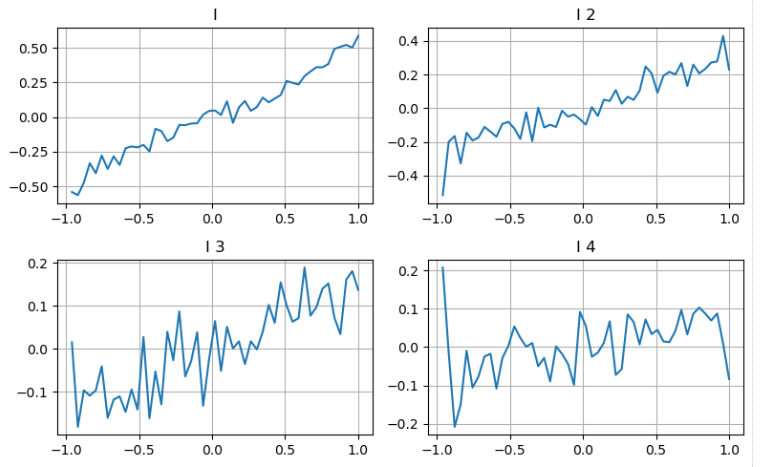
В [20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
В [21]:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
Выход[21]:
Ошибка скорректированной средней_цены_4: 0,0047909595497071375 Ошибка скорректированной средней_цены_5: 0,0047884350488318714 Ошибка скорректированной средней_цены_6: 0,0047778319053133735 Ошибка скорректированной средней_цены_7: 0,004773578540592192 Ошибка скорректированной средней_цены_8: 0,004771415189297518
Рассмотрение данных о сделках
Данные о транзакциях напрямую отражают степень длинных и коротких позиций. В конце концов, транзакции связаны с реальными деньгами, в то время как размещение заказов имеет гораздо более низкие затраты и может даже включать намеренное обман. Поэтому при прогнозировании средней_цены стратегии должны сосредоточиться на данных о транзакциях.
С точки зрения формы, мы можем определить дисбаланс среднего количества прибывших заказов как VI, причем Vb и Vs представляют собой среднее количество заказов на покупку и продажу в единичном временном интервале соответственно.
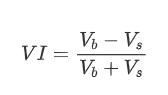
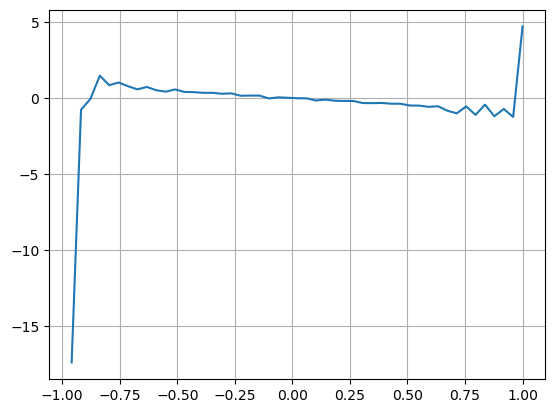
Результаты показывают, что количество прибытия в короткий промежуток времени оказывает наибольшее влияние на прогнозирование изменения цен. Когда VI находится между 0,1 и 0,9, оно отрицательно коррелирует с ценой, в то время как за пределами этого диапазона оно положительно коррелирует с ценой. Это говорит о том, что когда рынок не является экстремальным и в основном колеблется, цена имеет тенденцию возвращаться к среднему значению. Однако в экстремальных рыночных условиях, например, когда есть большое количество заказов на покупку, подавляющих заказы на продажу, возникает тенденция. Даже без учета этих сценариев с низкой вероятностью, если предположить отрицательную линейную связь между трендом и VI, значительно снижается погрешность прогнозирования средней цены. Коэффициент
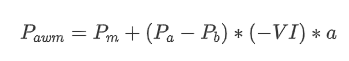
В [22]:
alpha=0.1
В [23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
В [24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
В [25]:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
В [26]:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
В [27]:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
Выход[27]:
В [28]:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
В [29]:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
Выход[29]:
Ошибка скорректированной средней_цены: 0,0048373440193987035 Ошибка скорректированной средней_цены_9: 0,004629586542840461 Ошибка скорректированной средней_цены_10: 0,004401790287167206
Всеобъемлющая средняя цена
Учитывая, что как дисбаланс ордерной книги, так и данные о транзакциях полезны для прогнозирования средней цены, мы можем объединить эти два параметра вместе. Присвоение весов в этом случае является произвольным и не учитывает пограничные условия. В крайних случаях прогнозируемая средняя цена может не падать между ценой предложения и ценой спроса. Однако, пока ошибка прогноза может быть уменьшена, эти детали не представляют большого беспокойства.
В итоге ошибка прогноза уменьшается с 0,00487 до 0,0043. На данном этапе мы не будем углубляться в тему. Есть еще много аспектов, которые нужно изучить, когда дело доходит до прогнозирования средней_цены, поскольку это, по сути, прогнозирование самой цены.
В [30]:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
В [31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
Выход[31]:
Ошибка скорректированной средней_цены_11: 0,0043001941412563575
Резюме
Статья сочетает в себе глубинные данные и данные транзакций для дальнейшего улучшения метода расчета средней цены. Она предоставляет метод измерения точности и улучшает точность прогноза изменения цены. В целом параметры не являются строгими и предназначены только для справки.
- Дельта-хеджирование опционов на биткоин с помощью кривой улыбки
- Мысли о высокочастотных торговых стратегиях (4)
- Размышления о стратегии высокочастотного трейдинга (5)
- Размышления о стратегии высокочастотного трейдинга (4)
- Мысли о высокочастотных торговых стратегиях (3)
- Размышления о стратегии высокочастотного трейдинга (3)
- Мысли о высокочастотных торговых стратегиях (2)
- Размышления о стратегии высокочастотного трейдинга (2)
- Мысли о высокочастотных торговых стратегиях (1)
- Размышления о стратегии высокочастотного трейдинга (1)
- Документ описания конфигурации Futu Securities