Моделирование и анализ волатильности биткоина на основе модели ARMA-EGARCH
Автор:Лидия., Создано: 2022-11-15 15:32:43, Обновлено: 2023-09-14 20:30:52ЭД, и процесс был пропущен.
Сравнительная степень Нормального нормального распределения не так хороша, как t-распределение, что также показывает, что распределение дохода имеет более толстый хвост, чем нормальное распределение.
В [23]:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
Выход[23]: Итерация: 1, Функция: 10, отрицание: -1917.4262154917305
Результаты модели AR - GARCH
Средняя модель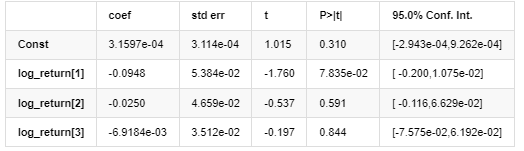
Волатильность модели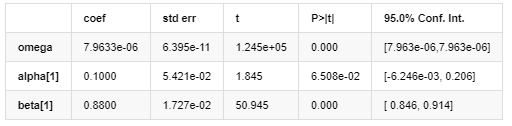
Распределение
Оценщик ковариантности: надежный
Описание уравнения волатильности GARCH согласно базе данных ARCH: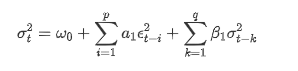
Уравнение условной регрессии для волатильности можно получить следующим образом: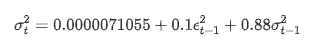
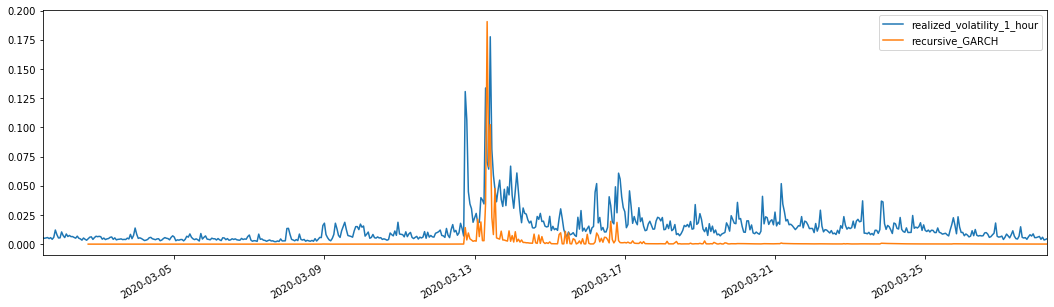
В сочетании с соответствующей прогнозируемой волатильностью сравнить ее с реализованной волатильностью выборки, чтобы увидеть эффект.
В [26]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Выход[26]: Средняя абсолютная ошибка (MAE): 0,0128 Средняя абсолютная процентная ошибка (MAPE): 95,6 Ошибка среднего квадратного корня (RMSE): 0,018
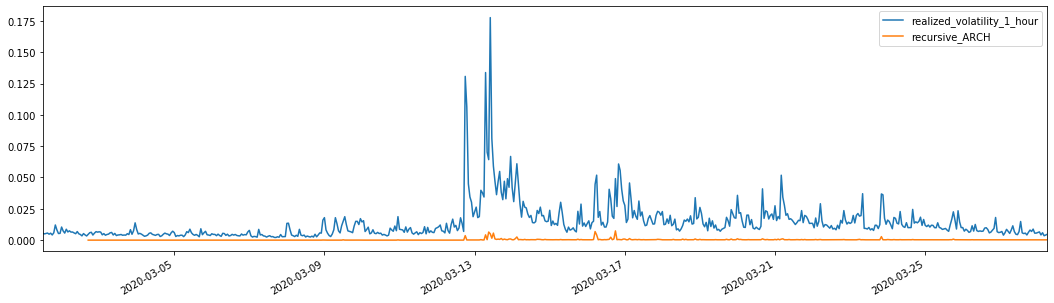
Для сравнения, сделайте ARCH следующим образом:
В [27]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Выход[27]: Средняя абсолютная ошибка (MAE): 0,0136 Средняя абсолютная процентная ошибка (MAPE): 98,1 Средняя квадратная ошибка корня (RMSE): 0,02
7. Моделирование EGARCH
Следующим шагом является выполнение моделирования EGARCH
В [24]:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
Выход[24]: Итерация: 1, число функций: 11, отрицательные LLF: -1966.610328148909
Результаты модели AR - EGARCH
Средняя модель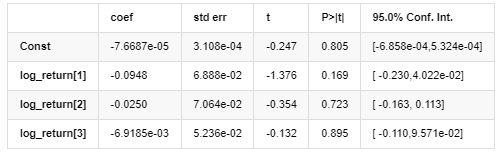
Волатильность модели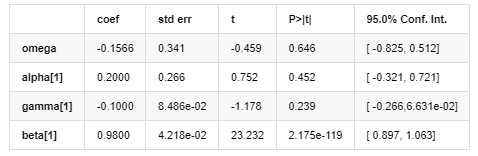
Распределение
Оценщик ковариантности: надежный
Уравнение волатильности EGARCH, предоставленное библиотекой ARCH, описано следующим образом: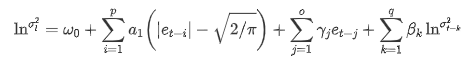
Заместитель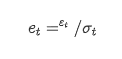
Уравнение условной регрессии волатильности можно получить следующим образом: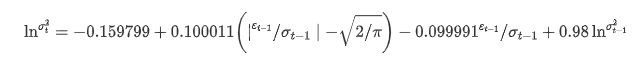
Среди них оценочный коэффициент симметричного термина γ меньше доверительного интервала, что указывает на наличие значительной
В сочетании с соответствующей прогнозируемой волатильностью результаты сравниваются с реализованной волатильностью выборки следующим образом:
В [28]:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
Выход[28]: Средняя абсолютная ошибка (MAE): 0,0201 Средняя абсолютная процентная ошибка (MAPE): 122 Средняя квадратная ошибка корня (RMSE): 0,0279
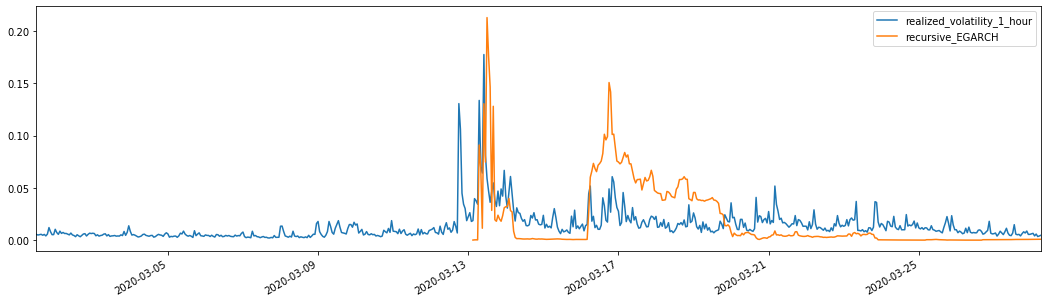
Можно видеть, что EGARCH более чувствителен к волатильности и лучше соответствует волатильности, чем ARCH и GARCH.
Оценка прогноза волатильности
Часовые данные выбираются на основе выборки, и следующим шагом является прогнозирование на один час вперед. Мы выбираем прогнозируемую волатильность первых 10 часов трех моделей, с RV как эталонной волатильностью. Значение сравнительной ошибки следующее:
В [29]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
Выход[29]: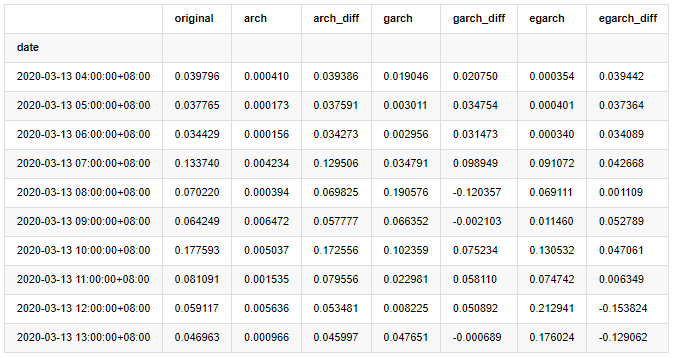
В [30]:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
Выход[30]: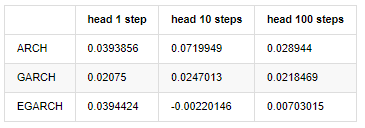
Было проведено несколько тестов, в результате прогнозирования первого часа вероятность наименьшей ошибки EGARCH относительно велика, но общая разница не особенно очевидна; Есть некоторые очевидные различия в краткосрочных эффектах прогнозирования; EGARCH имеет наиболее выдающуюся способность прогнозирования в долгосрочном прогнозировании
В [31]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
Выход[31]: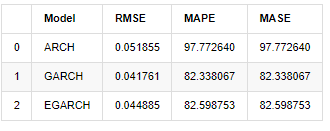
С точки зрения показателей GARCH и EGARCH имеют некоторое улучшение по сравнению с ARCH, но разница не особенно очевидна.
9. Заключение
Из приведенного выше простого анализа можно выяснить, что логарифмическая ставка доходности Биткойна не соответствует нормальному распределению, которое характеризуется толстыми жирными хвостами, а волатильность имеет эффект агрегации и рычага, показывая при этом очевидную условную гетерогенность.
При прогнозировании и оценке логарифмической скорости возврата способность статического прогнозирования внутрипробки модели ARMA значительно лучше динамической, что показывает, что методы прокатки, очевидно, лучше, чем методы итерации, и могут избежать проблем свертывания и усиления ошибок.
Кроме того, когда речь идет о феномене толстого хвоста биткойна, то есть толстого хвостового распределения доходности, выясняется, что распределение GED (общие ошибки) значительно лучше, чем распределение t и нормальное распределение, что может значительно улучшить точность измерения хвостового риска. В то же время EGARCH имеет больше преимуществ в прогнозировании долгосрочной волатильности, что хорошо объясняет гетероцедастичность выборки.
Весь процесс моделирования полон различных смелых предположений, и нет идентификации согласованности в зависимости от действительности, поэтому мы можем только тщательно проверить некоторые явления. История может только поддержать вероятность прогнозирования будущего в статистике, но соотношение точности и производительности затрат все еще имеет долгий трудный путь.
По сравнению с традиционными рынками, доступность высокочастотных данных биткоина проще.
Однако вышеперечисленное ограничивается теорией. Более высокая частота данных действительно может обеспечить более точный анализ поведения трейдеров. Она может не только обеспечить более надежные тесты для финансовых теоретических моделей, но и предоставить более богатую информацию для принятия решений для трейдеров, даже поддержать прогноз информационного потока и потока капитала и помочь в разработке более точных количественных торговых стратегий. Однако рынок биткойнов настолько волатилен, что слишком длинные исторические данные не могут соответствовать эффективной информации для принятия решений, поэтому высокочастотные данные, безусловно, принесут большие рыночные преимущества инвесторам цифровой валюты.
Наконец, если вы считаете, что вышеприведенный контент полезен, вы также можете предложить немного BTC, чтобы купить мне чашку Колы.
- Количественный анализ фундаментального анализа на рынке криптовалют: пусть данные говорят сами за себя!
- Не стоит больше верить всяким хитроумным учителям, которые говорят, что данные объективны.
- Необходимый инструмент для количественной торговли - изобретатель модуля количественного исследования данных
- Освоение всего - Введение в FMZ Новая версия торгового терминала (с TRB Arbitrage Source Code)
- Ознакомьтесь с новым типом терминала FMZ (с кодом TRB)
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (II)
- Как использовать бесмозговых роботов с высокочастотной стратегией в 80 строках кода
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (II)
- Как использовать высокочастотную стратегию 80-линейного кода для эксплуатации безмозговых роботов
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (I)
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (1)