Нейронные сети и цифровая валюта Количественная серия торговли (2) - Интенсивное обучение и обучение Стратегия торговли биткойнами
Автор:Лидия., Создано: 2023-01-12 16:49:09, Обновлено: 2023-09-20 10:07:39
Нейронные сети и цифровая валюта Количественная серия торговли (2) - Интенсивное обучение и обучение Стратегия торговли биткойнами
1. Введение
В предыдущей статье мы представили использование сети LSTM для прогнозирования цены биткоина:https://www.fmz.com/bbs-topic/9879, как упоминалось в статье, это всего лишь небольшой учебный проект для ознакомления с RNN и pytorch. В этой статье будет представлено использование интенсивного обучения для непосредственной подготовки торговых стратегий. Модель интенсивного обучения OpenAI открытый исходный код PPO, а среда относится к стилю тренажерного зала. Чтобы облегчить понимание и тестирование, модель PPO LSTM и среда тренажерного зала для бэкстестинга написаны непосредственно без использования готовых пакетов. PPO, или Проксимальная оптимизация политики, является улучшением оптимизации Policy Gradient. gym также был выпущен OpenAI. Он может взаимодействовать со стратегической сетью и отзывы о состоянии и вознаграждениях текущей среды. Это похоже на практику интенсивного обучения. Он использует модель PPO LSTM для выполнения инструкций, таких как покупка, продажа или отсутствие операции непосредственно в соответствии с рыночной информацией Bitcoin. Отзывы даются средой бэкстеста. Через обучение модель непрерывно оптимизируется для достижения цели стратегической прибыли. Для чтения этой статьи требуется определенная основа углубленного интенсивного обучения Python, pytorch и DRL. Но это не имеет значения, если вы не можете. Это легко узнать и начать с кода, данного в этой статье. Это обучение создано платформой FMZ Quant Trading (www.fmz.comДобро пожаловать в группу QQ: 863946592 для общения.
2. Данные и учебные справочники
Данные о ценах на биткоин получены на платформе FMZ Quant Trading:https://www.quantinfo.com/Tools/View/4.html- Да, конечно. Статья с использованием DRL+gym для обучения торговым стратегиям:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4- Да, конечно. Некоторые примеры начинающих с pytorch:https://github.com/yunjey/pytorch-tutorial- Да, конечно. Настоящая статья будет реализовывать модель LSTM-PPO непосредственно:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py- Да, конечно. Статьи о ППО:https://zhuanlan.zhihu.com/p/38185553Я не знаю. Больше статей о DRL:https://www.zhihu.com/people/flood-sung/posts- Да, конечно. В этой статье не требуется установка, но это очень распространено в интенсивном обучении:https://gym.openai.com/.
3. LSTM-PPO
Для более подробного объяснения PPO вы можете узнать из предыдущих справочных материалов. Вот простое введение в понятия. В последнем выпуске сети LSTM была предсказана только цена. Как купить и продать на основе предсказанной цены придется реализовать отдельно. Естественно думать, что прямой выход торгового действия будет более прямым. Это касается Policy Gradient, который может дать вероятность различных действий в соответствии с информацией входной среды s. Потеря LSTM - это разница между предсказанной ценой и фактической ценой, в то время как потеря PG - log § * Q, где p - вероятность выхода действия, а Q - значение действия (например, интуитивное вознаграждение).
Ниже приведен исходный код LSTM-PPO, который можно понять в сочетании с предыдущими данными:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Окружающая среда для обратного тестирования биткойнов
В соответствии с форматом gym, существует метод сброса инициализации. Step вводит действие, и возвращаемый результат (следующий статус, доход действия, завершится ли действие, дополнительная информация). Вся среда бэкстеста также составляет 60 строк. Вы можете модифицировать более сложные версии самостоятельно. Конкретный код:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Несколько примечательных деталей
- Почему на первоначальном счете есть валюта?
Формула для расчета доходности среды обратного теста: текущая доходность = стоимость текущего счета - текущая стоимость начального счета. Это означает, что если цена Биткоина снижается, и стратегия делает операцию по продаже монет, даже если общая стоимость счета снижается, стратегия должна быть фактически вознаграждена. Если обратный тест занимает много времени, первоначальный счет может иметь мало влияния, но в начале он окажет большое влияние. Расчет относительной доходности гарантирует, что каждая правильная операция получит положительное вознаграждение.
- Почему на рынке проводилась выборка во время обучения?
Общий объем данных составляет более 10 000 K-линий. Если вы выполняете петлю в полном объеме каждый раз, это займет много времени, и стратегия каждый раз сталкивается с одной и той же ситуацией, может быть проще перенастроиться. Принимая 500 баров за раз в качестве обратного теста. Хотя все еще возможно перенастроиться, стратегия сталкивается с более чем 10 000 различными возможными стартами.
- А если нет денег?
Эта ситуация не рассматривается в среде обратного тестирования. Если валюта была распродана или минимальное количество торгов не может быть достигнуто, то операция продажи эквивалентна фактическому отсутствию операции. Если цена снижается, согласно методу расчета относительной доходности, она все равно основана на стратегической положительной доходности. Влияние этой ситуации заключается в том, что когда стратегия считает, что рынок снижается, и оставшаяся валюта счета не может быть продана, невозможно отличить продажу от неоперационной акции, но это не влияет на суждение о самой стратегии на рынке.
- Почему я должен возвращать информацию о счете как статус?
Модель PPO имеет сеть ценностей для оценки стоимости текущего статуса. Очевидно, что если стратегия судит, что цена увеличится, весь статус будет иметь положительную стоимость только тогда, когда текущий счет держит Биткойн, и наоборот. Поэтому информация о счете является важной основой для суждения о сети ценностей.
- Когда он вернется к неоперации?
Когда стратегия считает, что доходы, принесенные сделкой, не могут покрыть комиссию за обработку, она должна вернуться к неоперации. Хотя предыдущее описание использует стратегии неоднократно для оценки ценовой тенденции, это только для удобства понимания. На самом деле, эта модель PPO не предсказывает рынок, но только выводит вероятность трех действий.
6. Получение данных и обучение
Как и в предыдущей статье, метод и формат сбора данных следуют: один-часовой период K-линия торговой пары Bitfinex Exchange BTC_USD с 7 мая 2018 года по 27 июня 2019 года:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Из-за использования сети LSTM время обучения очень длинное. Я перешел на версию GPU, которая примерно в три раза быстрее.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Результаты обучения и анализ
После долгого ожидания:

Во-первых, посмотрите на рынок данных о обучении.
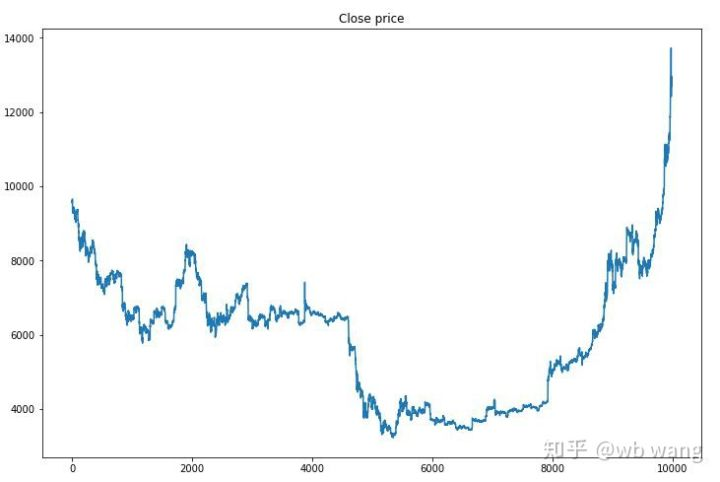
На ранней стадии обучения происходит много покупательных операций, и в основном нет выгодного раунда. к середине обучения покупательская операция постепенно уменьшается, и вероятность получения прибыли также увеличивается, но все еще есть большой шанс потери.
Уравните прибыль каждого раунда, и результат будет следующим:
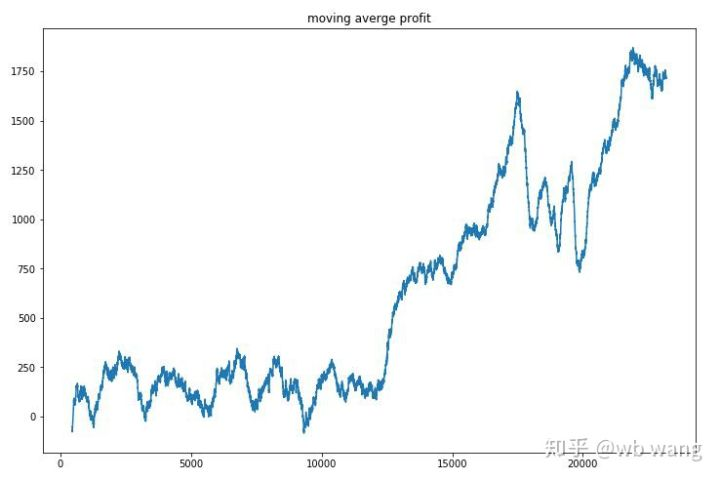
Стратегия быстро избавилась от ситуации, когда раннее возвращение было отрицательным, но колебания были большими.
После окончательного обучения позвольте модели снова запустить все данные, чтобы увидеть, как она работает. В течение периода запишите общую рыночную стоимость счета, количество Bitcoins, содержащихся, долю стоимости Bitcoin и общую прибыль. Во-первых, это общая рыночная стоимость, и общие доходы похожи на нее, они не будут опубликованы:
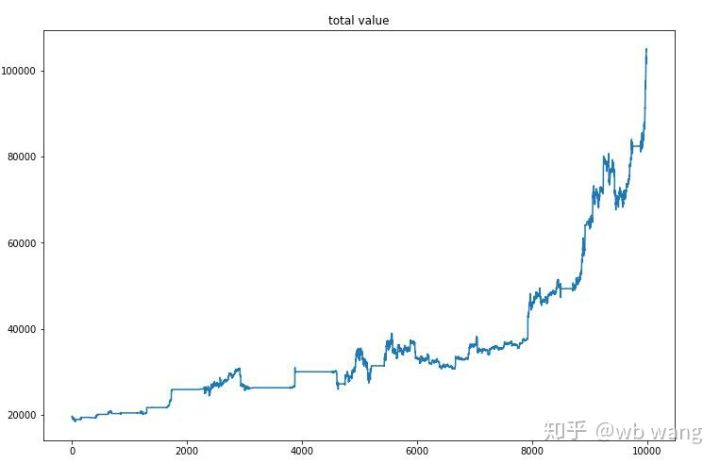
Общая рыночная стоимость медленно увеличивалась на раннем медвежьем рынке и не отставала от роста на более позднем бычьем рынке, но все еще наблюдались периодические потери.
Наконец, взгляните на долю позиций. Левая ось диаграмма - это доля позиций, а правая ось - это рынок. Можно предварительно судить, что модель перенапряжена. Частота позиций низка на раннем медвежьем рынке и высока на дне рынка.
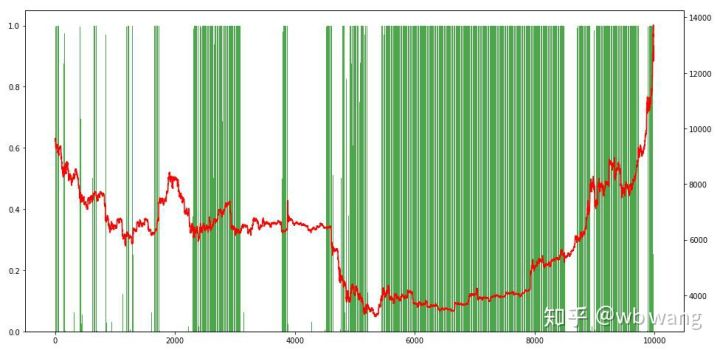
8. Анализ данных испытаний
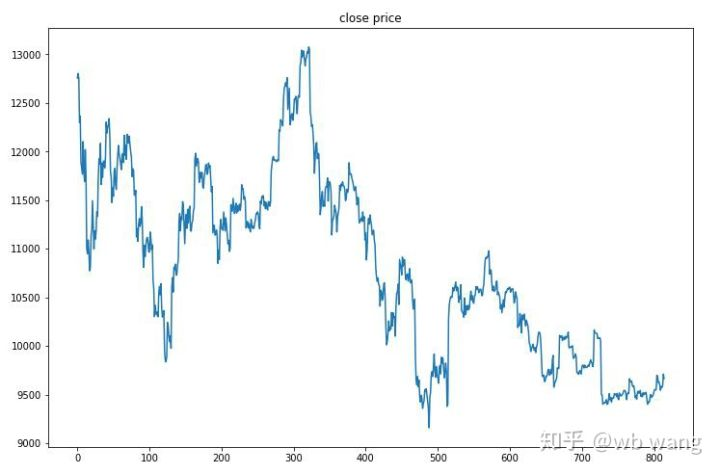
Одночасовой рынок биткоина с 27 июня 2019 года по настоящее время был получен из тестовых данных. Из диаграммы можно увидеть, что цена упала с 13 000 до более чем 9000 долларов, что является отличным тестом для модели.
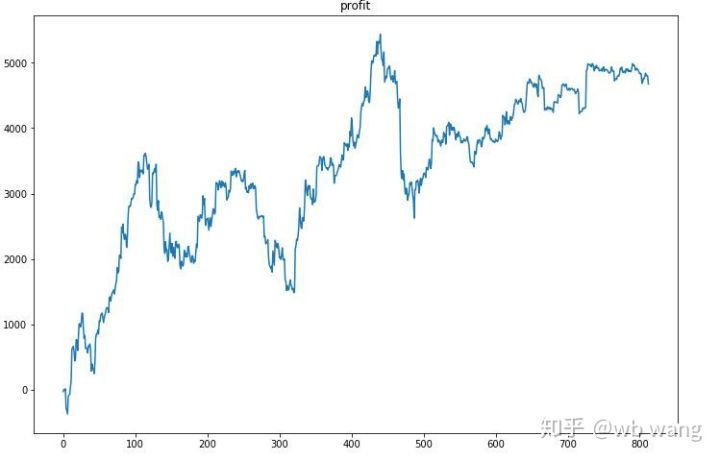
Во-первых, конечная относительная отдача выполнялась так-то, но убытков не было.
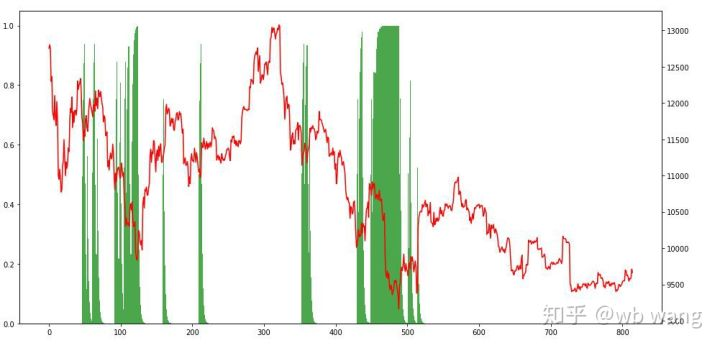
Если посмотреть на ситуацию с позицией, то можно предположить, что модель имеет тенденцию покупать после резкого падения и продавать после отскока.
9. Резюме
В этой статье робот автоматической торговли Биткойном обучается с помощью PPO, метода глубокого интенсивного обучения, и получаются некоторые выводы. Из-за ограниченного времени в модели все еще есть некоторые аспекты, которые необходимо улучшить. Приветствуем обсуждение. Самый большой урок заключается в том, что для метода стандартизации данных не используйте масштабирование и другие методы, иначе модель быстро запомнит связь между ценой и рынком и попадет в переподборку. Стандартизированный коэффициент изменения - это относительные данные, которые затрудняют модели запоминать связь с рынком и вынуждены находить связь между коэффициентом изменения и увеличением и уменьшением.
Введение в предыдущие статьи: Стратегия высокой частоты, которую я раскрыл, когда-то была очень прибыльной:https://www.fmz.com/bbs-topic/9886.
- Количественный анализ фундаментального анализа на рынке криптовалют: пусть данные говорят сами за себя!
- Не стоит больше верить всяким хитроумным учителям, которые говорят, что данные объективны.
- Необходимый инструмент для количественной торговли - изобретатель модуля количественного исследования данных
- Освоение всего - Введение в FMZ Новая версия торгового терминала (с TRB Arbitrage Source Code)
- Ознакомьтесь с новым типом терминала FMZ (с кодом TRB)
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (II)
- Как использовать бесмозговых роботов с высокочастотной стратегией в 80 строках кода
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (II)
- Как использовать высокочастотную стратегию 80-линейного кода для эксплуатации безмозговых роботов
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (I)
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (1)