ہائی فریکوئنسی ٹریڈنگ کی حکمت عملیوں کے بارے میں خیالات (5)
مصنف:لیدیہ, تخلیق: 2023-08-10 15:57:27, تازہ کاری: 2023-09-12 15:51:54
ہائی فریکوئنسی ٹریڈنگ کی حکمت عملیوں کے بارے میں خیالات (5)
پچھلے مضمون میں ، درمیانی قیمت کا حساب لگانے کے مختلف طریقے متعارف کرائے گئے تھے ، اور ایک نظر ثانی شدہ درمیانی قیمت کی تجویز پیش کی گئی تھی۔ اس مضمون میں ، ہم اس موضوع میں گہرائی سے گہرائی کریں گے۔
مطلوبہ ڈیٹا
ہمیں آرڈر بک کے سب سے اوپر دس سطحوں کے لئے آرڈر فلو ڈیٹا اور گہرائی کے ڈیٹا کی ضرورت ہے ، جو 100ms کی تازہ کاری کی تعدد کے ساتھ براہ راست تجارت سے اکٹھا کیا گیا ہے۔ سادگی کی خاطر ، ہم بولی اور پوچھ قیمتوں کے لئے ریئل ٹائم اپ ڈیٹس شامل نہیں کریں گے۔ اعداد و شمار کے سائز کو کم کرنے کے ل we ، ہم نے گہرائی کے اعداد و شمار کی صرف 100،000 قطاریں رکھی ہیں اور ٹک ٹاک مارکیٹ کے اعداد و شمار کو انفرادی کالموں میں الگ کردیا ہے۔
میں [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
[2] میں:
tick_size = 0.0001
میں [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
[4] میں:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
میں [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
[6] میں:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
میں [7]:
depths = depths.iloc[:100000]
[8] میں:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
[9] میں:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
[10] میں:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
[11] میں:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
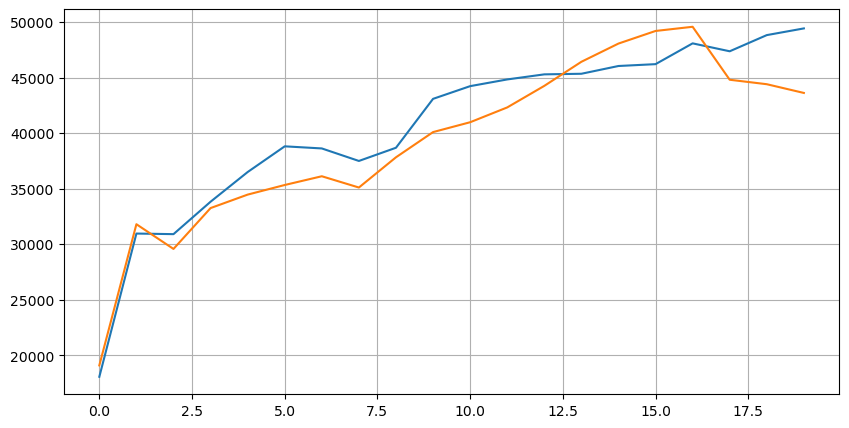
ان 20 سطحوں میں مارکیٹ کی تقسیم پر ایک نظر ڈالیں۔ یہ توقعات کے مطابق ہے ، زیادہ سے زیادہ آرڈرز مارکیٹ کی قیمت سے زیادہ دور رکھے جاتے ہیں۔ مزید برآں ، خریدنے کے احکامات اور فروخت کے احکامات تقریبا متوازی ہیں۔
[14] میں:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
باہر [1]:
گہرائی کے اعداد و شمار کو ٹرانزیکشن کے اعداد و شمار کے ساتھ ضم کریں تاکہ پیش گوئی کی درستگی کا اندازہ لگانے میں آسانی ہو۔ اس بات کو یقینی بنائیں کہ ٹرانزیکشن کے اعداد و شمار گہرائی کے اعداد و شمار سے بعد میں ہیں۔ تاخیر پر غور کیے بغیر ، براہ راست پیش گوئی کی قیمت اور اصل ٹرانزیکشن قیمت کے مابین اوسط مربع غلطی کا حساب لگائیں۔ یہ پیشن گوئی کی درستگی کی پیمائش کے لئے استعمال ہوتا ہے۔
نتائج سے ، غلطی بولی اور پوچھ قیمتوں (mid_price) کی اوسط قیمت کے لئے سب سے زیادہ ہے۔ تاہم ، جب وزن والے وسط_قیمت میں تبدیل کیا جاتا ہے تو ، غلطی فوری طور پر نمایاں طور پر کم ہوجاتی ہے۔ ایڈجسٹ شدہ وزن والے وسط_قیمت کا استعمال کرکے مزید بہتری دیکھی جاتی ہے۔ صرف I ^ 3 / 2 کا استعمال کرتے ہوئے آراء موصول ہونے کے بعد ، اس کی جانچ پڑتال کی گئی اور پتہ چلا کہ نتائج بہتر تھے۔ غور و فکر کے بعد ، اس کی وجہ واقعات کی مختلف تعدد ہے۔ جب میں -1 اور 1 کے قریب ہوتا ہے تو ، اس سے کم امکانات کے واقعات کی نمائندگی ہوتی ہے۔ ان کم امکانات کے واقعات کو درست کرنے کے ل high ، اعلی تعدد کے واقعات کی پیش گوئی کرنے کی درستگی کو سمجھوتہ کیا جاتا ہے۔ لہذا ، اعلی تعدد کے واقعات کو ترجیح دینے کے لئے ، کچھ ایڈجسٹمنٹ کی گئیں۔ (یہ پیرامیٹر خالصتا trial-and-error تھے اور لائیو ٹریڈنگ میں عملی اہمیت محدود ہے) ۔
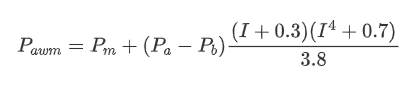
نتائج میں قدرے بہتری آئی ہے۔ جیسا کہ پچھلے مضمون میں ذکر کیا گیا ہے ، حکمت عملیوں کو پیش گوئی کے لئے زیادہ سے زیادہ اعداد و شمار پر انحصار کرنا چاہئے۔ زیادہ گہرائی اور آرڈر ٹرانزیکشن ڈیٹا کی دستیابی کے ساتھ ، آرڈر بک پر توجہ مرکوز کرنے سے حاصل ہونے والی بہتری پہلے ہی کمزور ہے۔
[15] میں:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
[17] میں:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
[18] میں:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
باہر [1]:
درمیانی قیمت میں خرابی: 0.0048751924999999845 زیر التواء آرڈر حجم کی غلطی درمیانی قیمت پر وزن: 0.0048373440193987035 ایڈجسٹ شدہ مڈ_پریس کی غلطی: 0.004803654771638586 ایڈجسٹ شدہ mid_price_2 کی غلطی: 0.004808216498329721 ایڈجسٹ شدہ mid_price_3 کی غلطی: 0.004794984755260528 ایڈجسٹ شدہ mid_price_4 کی غلطی: 0.0047909595497071375
گہرائی کی دوسری سطح پر غور کریں
ہم پچھلے مضمون سے نقطہ نظر پر عمل کرسکتے ہیں تاکہ کسی پیرامیٹر کی مختلف حدود کا جائزہ لیا جاسکے اور لین دین کی قیمت میں ہونے والی تبدیلیوں کی بنیاد پر اس کی وسط_قیمت میں اس کی شراکت کی پیمائش کی جاسکے۔ گہرائی کی پہلی سطح کی طرح ، جیسے جیسے میں بڑھتا جاتا ہوں ، لین دین کی قیمت میں اضافہ ہونے کا زیادہ امکان ہوتا ہے ، جس سے I کی طرف سے مثبت شراکت کی نشاندہی ہوتی ہے۔
گہرائی کی دوسری سطح پر بھی اسی نقطہ نظر کا اطلاق کرتے ہوئے ، ہمیں پتہ چلتا ہے کہ اگرچہ اثر پہلی سطح سے قدرے چھوٹا ہے ، لیکن پھر بھی یہ اہم ہے اور اسے نظرانداز نہیں کیا جانا چاہئے۔ گہرائی کی تیسری سطح بھی کمزور شراکت دکھاتی ہے ، لیکن کم یکساں ہے۔ گہری گہرائیوں میں حوالہ کی قدر کم ہے۔
مختلف شراکتوں کی بنیاد پر ، ہم عدم توازن کے پیرامیٹرز کی ان تین سطحوں کو مختلف وزن دیتے ہیں۔ حساب کتاب کے مختلف طریقوں کا جائزہ لینے سے ، ہم پیش گوئی کی غلطیوں میں مزید کمی کا مشاہدہ کرتے ہیں۔
[19] میں:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
باہر [1]:
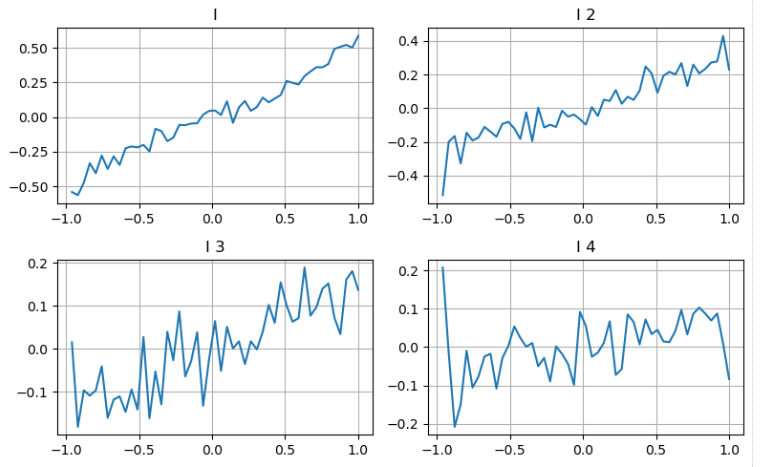
[20] میں:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
[21] میں:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
باہر[21]:
ایڈجسٹ شدہ mid_price_4 کی غلطی: 0.0047909595497071375 ایڈجسٹ شدہ mid_price_5 کی غلطی: 0.0047884350488318714 ایڈجسٹ شدہ mid_price_6 کی غلطی: 0.0047778319053133735 ایڈجسٹ شدہ mid_price_7 کی غلطی: 0.004773578540592192 ایڈجسٹ شدہ mid_price_8 کی غلطی: 0.004771415189297518
ٹرانزیکشن ڈیٹا پر غور
لین دین کے اعداد و شمار براہ راست لمبی اور مختصر پوزیشنوں کی حد کی عکاسی کرتے ہیں۔ بہر حال ، لین دین میں حقیقی رقم شامل ہوتی ہے ، جبکہ آرڈر دینے میں بہت کم لاگت آتی ہے اور اس میں جان بوجھ کر دھوکہ دہی بھی شامل ہوسکتی ہے۔ لہذا ، وسط_قیمت کی پیش گوئی کرتے وقت ، حکمت عملیوں کو لین دین کے اعداد و شمار پر توجہ دینی چاہئے۔
شکل کے لحاظ سے ، ہم اوسط آرڈر کی آمد کی مقدار کے عدم توازن کو VI کے طور پر بیان کرسکتے ہیں ، جس میں Vb اور Vs بالترتیب ایک یونٹ وقت کے وقفے کے اندر خرید اور فروخت کے احکامات کی اوسط مقدار کی نمائندگی کرتے ہیں۔
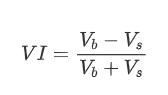
نتائج سے پتہ چلتا ہے کہ مختصر عرصے میں آنے والی مقدار کا قیمت کی تبدیلی کی پیش گوئی پر سب سے زیادہ اہم اثر پڑتا ہے۔ جب VI 0.1 اور 0.9 کے درمیان ہوتا ہے تو ، یہ قیمت کے ساتھ منفی طور پر وابستہ ہوتا ہے ، جبکہ اس حد سے باہر ، یہ قیمت کے ساتھ مثبت طور پر وابستہ ہوتا ہے۔ اس سے پتہ چلتا ہے کہ جب مارکیٹ انتہائی نہیں ہوتی ہے اور بنیادی طور پر دوڑ دوڑ کرتی ہے تو ، قیمت اوسط کی طرف لوٹنے کا رجحان رکھتی ہے۔ تاہم ، انتہائی مارکیٹ کے حالات میں ، جیسے جب خریدنے کے احکامات کی ایک بڑی تعداد ہوتی ہے تو فروخت کے احکامات پر قابو پانے والا رجحان سامنے آتا ہے۔ یہاں تک کہ ان کم امکانات والے منظرناموں پر غور کیے بغیر ، رجحان اور VI کے مابین منفی لکیری تعلقات کا فرض کرتے ہوئے وسط_قیمت کی پیش گوئی کی غلطی کو نمایاں طور پر کم کرتا ہے۔ ضارب
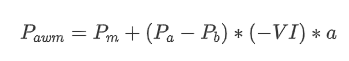
[22] میں:
alpha=0.1
[23] میں:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
[24] میں:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
[25] میں:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
[26] میں:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
[27] میں:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
باہر [1]:
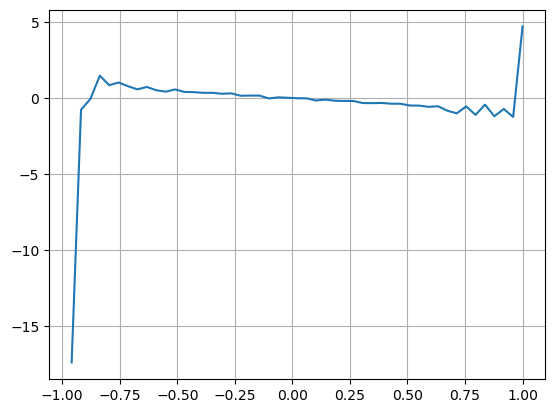
[28] میں:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
[29] میں:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
باہر[29]:
ایڈجسٹ شدہ مڈ_پریس کی غلطی: 0.0048373440193987035 ایڈجسٹ شدہ mid_price_9 کی غلطی: 0.004629586542840461 ایڈجسٹ شدہ mid_price_10 کی غلطی: 0.004401790287167206
جامع درمیانی قیمت
اس بات پر غور کرتے ہوئے کہ آرڈر بک عدم توازن اور لین دین کے اعداد و شمار دونوں درمیانی قیمت کی پیش گوئی کرنے میں مددگار ہیں ، ہم ان دونوں پیرامیٹرز کو ایک ساتھ جوڑ سکتے ہیں۔ اس معاملے میں وزن کی تفویض خود مختار ہے اور اس میں حدود کی شرائط کو مدنظر نہیں رکھا جاتا ہے۔ انتہائی معاملات میں ، پیش گوئی کی گئی درمیانی قیمت بولی اور قیمتوں کے درمیان نہیں پڑ سکتی ہے۔ تاہم ، جب تک پیش گوئی کی غلطی کو کم کیا جاسکتا ہے ، یہ تفصیلات بہت پریشان کن نہیں ہیں۔
آخر میں ، پیشن گوئی کی غلطی 0.00487 سے کم ہو کر 0.0043 ہوگئی ہے۔ اس مقام پر ، ہم اس موضوع میں مزید گہرائی نہیں کریں گے۔ جب مڈ_پریس کی پیش گوئی کی بات آتی ہے تو ابھی بھی بہت سارے پہلوؤں کی کھوج کی جاتی ہے ، کیونکہ یہ بنیادی طور پر قیمت کی پیش گوئی کر رہا ہے۔ ہر ایک کو اپنے طریقے اور تکنیک آزمانے کی ترغیب دی جاتی ہے۔
[30] میں:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
[31] میں:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
باہر [1]:
ایڈجسٹ شدہ mid_price_11 کی غلطی: 0.0043001941412563575
خلاصہ
اس مضمون میں درمیانی قیمت کے حساب کتاب کے طریقہ کار کو مزید بہتر بنانے کے لئے گہرائی کے اعداد و شمار اور لین دین کے اعداد و شمار کو جوڑ دیا گیا ہے۔ یہ درستگی کی پیمائش کرنے اور قیمت کی تبدیلی کی پیش گوئی کی درستگی کو بہتر بنانے کا ایک طریقہ فراہم کرتا ہے۔ مجموعی طور پر ، پیرامیٹرز سخت نہیں ہیں اور صرف حوالہ کے لئے ہیں۔ زیادہ درست درمیانی قیمت کے ساتھ ، اگلے مرحلے میں عملی ایپلی کیشنز میں درمیانی قیمت کا استعمال کرتے ہوئے بیک ٹیسٹنگ کرنا ہے۔ مواد کا یہ حصہ وسیع ہے ، لہذا اپ ڈیٹس کو کچھ عرصے کے لئے روک دیا جائے گا۔
- مسکراہٹ وکر کے ساتھ بٹ کوائن کے اختیارات کے لئے ڈیلٹا ہیجنگ
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملیوں کے بارے میں خیالات (4)
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملی کے بارے میں سوچنا (5)
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملی کے بارے میں سوچنا (4)
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملیوں کے بارے میں خیالات (3)
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملی کے بارے میں سوچنا (3)
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملیوں کے بارے میں خیالات (2)
- ہائی فریکوئینسی ٹریڈنگ کی حکمت عملی کے بارے میں سوچنا (2)
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملیوں کے بارے میں خیالات (1)
- ہائی فریکوئنسی ٹریڈنگ کی حکمت عملی کے بارے میں سوچنا (1)
- فٹو سیکیورٹیز کی تشکیل کی تفصیل کا دستاویز