اے آر ایم اے-ایگارچ ماڈل پر مبنی بٹ کوائن کی اتار چڑھاؤ کا ماڈلنگ اور تجزیہ
مصنف:لیدیہ, تخلیق: 2022-11-15 15:32:43, تازہ کاری: 2023-09-14 20:30:52ED، اور عمل کو چھوڑ دیا گیا تھا.
نارمل نارمل ڈسٹری بیوشن کی مماثلت کی ڈگری t ڈسٹری بیوشن کی طرح اچھی نہیں ہے ، جس سے یہ بھی ظاہر ہوتا ہے کہ پیداوار کی تقسیم میں نارمل ڈسٹری بیوشن کے مقابلے میں موٹی دم ہے۔ اگلا ، ماڈلنگ کے عمل میں داخل ہوں ، log_return (logarithmic rate of return) کے لئے ایک ARMA-GARCH ((1,1) ماڈل رجسٹریشن انجام دیا جاتا ہے اور اس کا اندازہ مندرجہ ذیل ہے:
[23] میں:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
باہر[23]: تکرار: 1، فنکشن نمبر: 10، منفی ایل ایل ایف: -1917.4262154917305
اے آر - گارچ ماڈل کے نتائج
اوسط ماڈل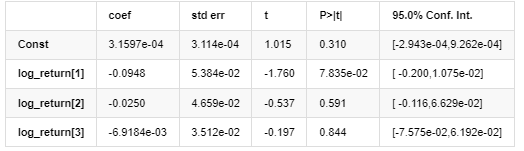
اتار چڑھاؤ کا ماڈل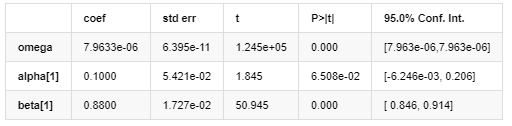
تقسیم
کوویریئنس کا تخمینہ: مضبوط
اے آر سی ایچ ڈیٹا بیس کے مطابق جی اے آر سی ایچ اتار چڑھاؤ مساوات کا بیان: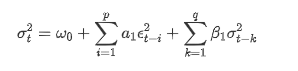
اتار چڑھاؤ کے لئے مشروط رجسٹریشن مساوات حاصل کی جاسکتی ہے: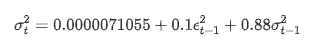
موازنہ شدہ پیش گوئی شدہ اتار چڑھاؤ کے ساتھ مل کر، اثر کو دیکھنے کے لئے نمونہ کے احساس شدہ اتار چڑھاؤ کے ساتھ اس کا موازنہ کریں.
[26] میں:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
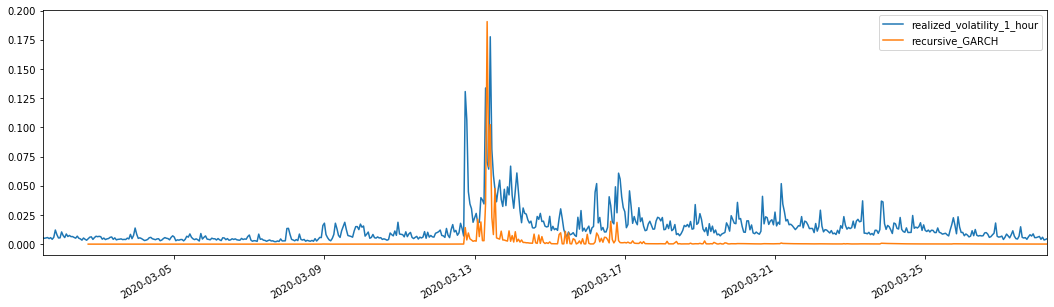
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
باہر[26]: اوسط مطلق غلطی (MAE): 0.0128 اوسط مطلق فیصد غلطی (MAPE): 95.6 روٹ میڈین اسکوائر غلطی (RMSE): 0.018
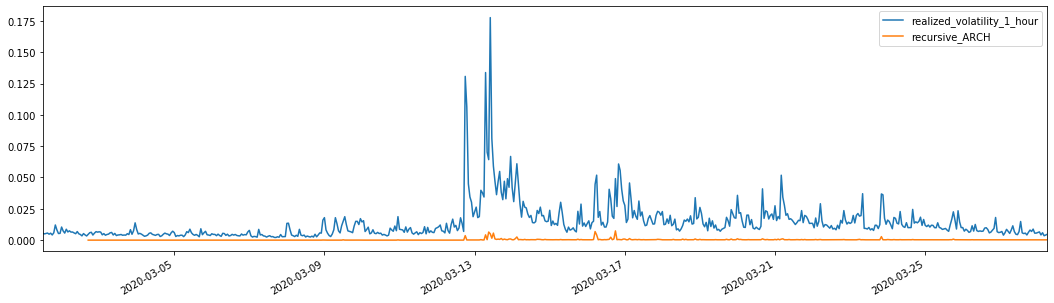
موازنہ کے لئے، مندرجہ ذیل طور پر ایک ARCH بنائیں:
[27] میں:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
باہر[27]: اوسط مطلق غلطی (MAE): 0.0136 اوسط مطلق فیصد غلطی (MAPE): 98.1 جڑ اوسط مربع غلطی (RMSE): 0.02
7. EGARCH ماڈلنگ
اگلا قدم EGARCH ماڈلنگ انجام دینا ہے
[24] میں:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
آؤٹ [1]: تکرار: 1، فنکشن نمبر: 11، منفی ایل ایل ایف: -1966.610328148909
اے آر - ای جی آر ایچ ماڈل کے نتائج
اوسط ماڈل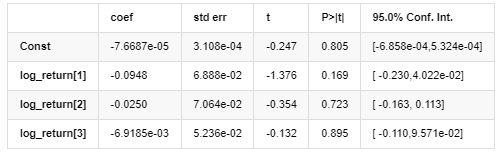
اتار چڑھاؤ کا ماڈل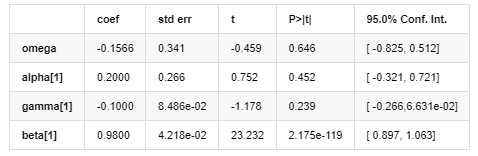
تقسیم
کوویریئنس کا تخمینہ: مضبوط
اے آر سی ایچ لائبریری کے ذریعہ فراہم کردہ ای جی اے آر سی ایچ اتار چڑھاؤ مساوات مندرجہ ذیل طور پر بیان کی گئی ہے: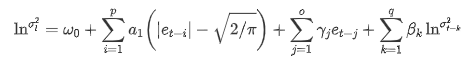
متبادل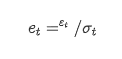
اتار چڑھاؤ کا مشروط رجسٹریشن مساوات مندرجہ ذیل طور پر حاصل کیا جا سکتا ہے: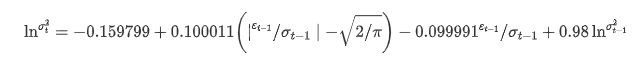
ان میں ، متوازن اصطلاح γ کا تخمینہ شدہ گتانک اعتماد کے وقفے سے کم ہے ، جس سے یہ ظاہر ہوتا ہے کہ بٹ کوائن کی واپسی کی شرحوں میں اتار چڑھاؤ میں ایک اہم
نتائج کو متوازن متوقع اتار چڑھاؤ کے ساتھ مل کر نمونہ کی حقیقت میں اتار چڑھاؤ کے ساتھ مندرجہ ذیل طریقے سے موازنہ کیا جاتا ہے۔
[28] میں:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
باہر[28]: اوسط مطلق غلطی (MAE): 0.0201 اوسط مطلق فیصد غلطی (MAPE): 122 جڑ اوسط مربع غلطی (RMSE): 0.0279
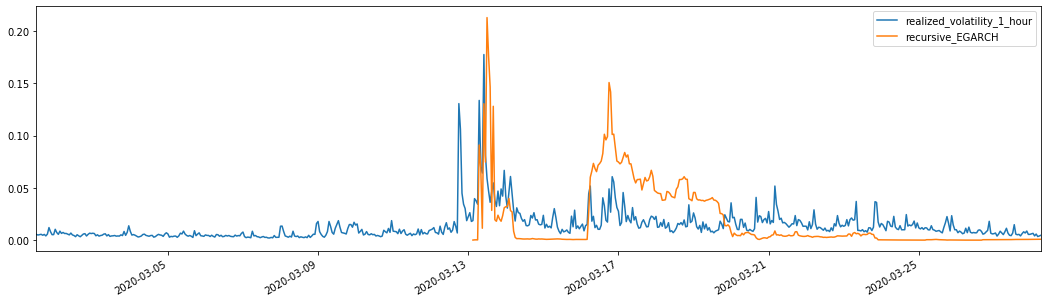
یہ دیکھا جا سکتا ہے کہ ایگارچ اتار چڑھاؤ پر زیادہ حساس ہے اور اے آر سی اور گارچ کے مقابلے میں اتار چڑھاؤ کو بہتر طور پر ملتا ہے.
8. اتار چڑھاؤ کی پیش گوئی کا جائزہ
گھنٹہ وار اعداد و شمار کا انتخاب نمونہ کی بنیاد پر کیا جاتا ہے ، اور اگلا مرحلہ ایک گھنٹہ آگے کی پیش گوئی کرنا ہے۔ ہم تینوں ماڈلز میں سے پہلے 10 گھنٹوں کی متوقع اتار چڑھاؤ کا انتخاب کرتے ہیں ، جس میں RV کو بینچ مارک اتار چڑھاؤ کے طور پر استعمال کیا جاتا ہے۔ تقابلی غلطی کی قیمت مندرجہ ذیل ہے۔
[29] میں:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
باہر[29]: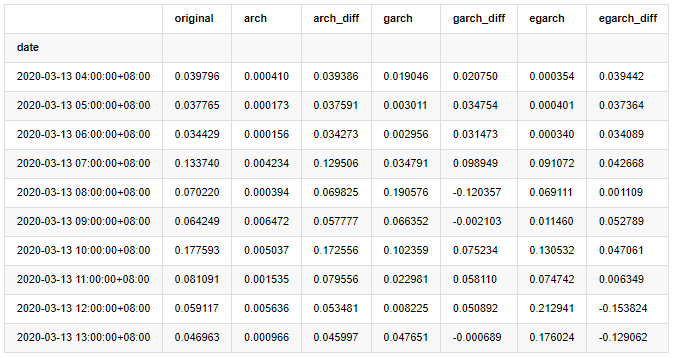
[30] میں:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
باہر[30]: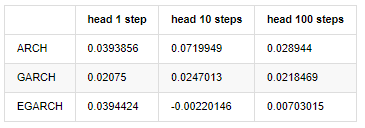
کئی ٹیسٹ کئے گئے ہیں، پہلے گھنٹے کی پیشن گوئی کے نتائج میں، EGARCH کی سب سے چھوٹی غلطی کا امکان نسبتا بڑا ہے، لیکن مجموعی فرق خاص طور پر واضح نہیں ہے؛ مختصر مدت کی پیشن گوئی کے اثرات میں کچھ واضح اختلافات ہیں؛ EGARCH طویل مدتی پیشن گوئی میں سب سے زیادہ شاندار پیشن گوئی کی صلاحیت ہے
[31] میں:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
باہر [1]: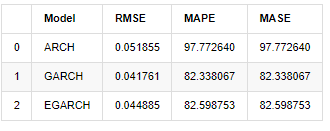
اشارے کے لحاظ سے ، GARCH اور EGARCH میں ARCH کے مقابلے میں کچھ بہتری ہے ، لیکن فرق خاص طور پر واضح نہیں ہے۔ کثیر نمونہ وقفے کے انتخاب اور تصدیق کے بعد ، EGARCH میں بہتر کارکردگی ہوگی ، جس کی بنیادی وجہ یہ ہے کہ EGARCH نمونے کی ہیٹروسکیڈاسٹیسیٹی کو اچھی طرح سے بیان کرتا ہے۔
9. اختتام
مندرجہ بالا سادہ تجزیہ سے ، یہ پایا جاسکتا ہے کہ بٹ کوائن کی لوگرتھمک ریٹرن کی شرح معمول کی تقسیم کے مطابق نہیں ہے ، جس کی خصوصیات موٹی چربی کی دموں سے ہوتی ہے ، اور اتار چڑھاؤ میں مجموعی اور فائدہ اٹھانے کا اثر ہوتا ہے ، جبکہ واضح مشروط heterogeneity دکھاتا ہے۔
لوگرتھمک شرح واپسی کی پیش گوئی اور تشخیص میں ، اے آر ایم اے ماڈل
اس کے علاوہ ، جب بٹ کوائن کے موٹے دم کے رجحان ، یعنی واپسی کی موٹی دم کی تقسیم سے نمٹنے کے ل it ، یہ معلوم ہوتا ہے کہ جی ای ڈی (عمومی غلطی) تقسیم ٹی تقسیم اور عام تقسیم سے نمایاں طور پر بہتر ہے ، جو دم کے خطرے کی پیمائش کی درستگی کو نمایاں طور پر بہتر بنا سکتی ہے۔ اسی وقت ، ای جی اے آر سی ایچ کے طویل مدتی اتار چڑھاؤ کی پیش گوئی کرنے میں زیادہ فوائد ہیں ، جو نمونے کی ہیٹروسکیڈاسٹیسیٹی کی اچھی طرح وضاحت کرتا ہے۔ ماڈل میچنگ میں متوازن تخمینہ گتانک اعتماد کے وقفے سے کم ہے ، جس سے یہ ظاہر ہوتا ہے کہ بٹ کوائن کی واپسی کی شرح میں اتار چڑھاؤ میں ایک اہم
ماڈلنگ کا پورا عمل مختلف جرات مندانہ مفروضوں سے بھرا ہوا ہے ، اور موزونیت پر منحصر مستقل مزاجی کی شناخت نہیں ہے ، لہذا ہم صرف کچھ مظاہر کو احتیاط سے تصدیق کرسکتے ہیں۔ تاریخ صرف اعدادوشمار میں مستقبل کی پیش گوئی کے امکان کی حمایت کرسکتی ہے ، لیکن درستگی اور لاگت کی کارکردگی کا تناسب ابھی بھی ایک طویل مشکل سفر طے کرنا ہے۔
روایتی منڈیوں کے مقابلے میں ، بٹ کوائن کے اعلی تعدد کے اعداد و شمار کی دستیابی آسان ہے۔ اعلی تعدد کے اعداد و شمار کی بنیاد پر مختلف اشارے کی
تاہم ، مذکورہ بالا نظریہ تک ہی محدود ہے۔ اعلی تعدد کے اعداد و شمار دراصل تاجروں کے طرز عمل کا زیادہ درست تجزیہ فراہم کرسکتے ہیں۔ یہ نہ صرف مالی نظریاتی ماڈلز کے لئے زیادہ قابل اعتماد ٹیسٹ فراہم کرسکتے ہیں ، بلکہ تاجروں کے لئے زیادہ کثرت سے فیصلہ سازی کی معلومات بھی فراہم کرسکتے ہیں ، یہاں تک کہ معلومات کے بہاؤ اور سرمایہ کے بہاؤ کی پیش گوئی کی حمایت کرسکتے ہیں ، اور زیادہ درست مقداری تجارتی حکمت عملیوں کے ڈیزائن میں مدد کرسکتے ہیں۔ تاہم ، بٹ کوائن مارکیٹ اتنی اتار چڑھاؤ والی ہے کہ بہت طویل تاریخی اعداد و شمار موثر فیصلہ سازی کی معلومات سے مماثل نہیں ہوسکتے ہیں ، لہذا اعلی تعدد کے اعداد و شمار یقینی طور پر ڈیجیٹل کرنسی کے سرمایہ کاروں کے لئے زیادہ سے زیادہ مارکیٹ کے فوائد لائیں گے۔
آخر میں ، اگر آپ کو مذکورہ بالا مواد مددگار لگتا ہے تو ، آپ مجھے ایک کپ کولا خریدنے کے لئے تھوڑا سا بی ٹی سی بھی پیش کرسکتے ہیں۔ لیکن مجھے کافی کی ضرورت نہیں ہے ، میں اسے پینے کے بعد سو جاؤں گا۔
- کریپٹوکرنسی مارکیٹ میں بنیادی تجزیہ کی مقدار: اعداد و شمار کو اپنے لئے بولنے دیں!
- ایک بار پھر ، ہم نے ایک بار پھر اس بات کا یقین کرلیا ہے کہ یہ ایک بہت بڑا مسئلہ ہے ، لیکن ہم اس کے بارے میں مزید نہیں جانتے ہیں۔
- کوانٹائزڈ ٹرانزیکشنز کے لیے ایک لازمی ٹول۔
- ہر چیز پر قابو پانا - ایف ایم زیڈ ٹریڈنگ ٹرمینل کا نیا ورژن (ٹی آر بی آربیٹریج سورس کوڈ کے ساتھ) کا تعارف
- FMZ کے نئے ورژن کے ٹرانزیکشن ٹرمینل کے بارے میں سب کچھ جاننے کے لئے یہاں کلک کریں
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (II)
- 80 لائنوں کے کوڈ میں ہائی فریکوئینسی حکمت عملی کے ساتھ دماغ کے بغیر سیلز بوٹس کا استحصال کیسے کریں
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (ب)
- 80 لائنوں کے کوڈ کے ساتھ ہائی فریکوئینسی کی حکمت عملی کے ساتھ فروخت کے لیے بے دماغ روبوٹ کا استحصال کیسے کیا گیا؟
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (I)
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (1)