5.4 Tại sao chúng ta cần một thử nghiệm ngoài mẫu
Tác giả:Tốt, Tạo: 2019-05-10 09:13:53, Cập nhật:Tóm lại
Trong phần trước, chúng tôi đã chỉ cho bạn cách đọc báo cáo hiệu suất backtesting chiến lược bằng cách tập trung vào một số chỉ số hiệu suất quan trọng. Trên thực tế, không khó để viết một chiến lược kiếm lợi nhuận trong báo cáo hiệu suất backtesting. Thật khó để đánh giá liệu chiến lược này có tiếp tục có hiệu quả trong thị trường thực trong tương lai hay không. Vì vậy, hôm nay tôi sẽ giải thích bài kiểm tra ngoài mẫu và tầm quan trọng của nó.
Kiểm tra hậu quả không bằng thị trường thực
Nhiều người mới bắt đầu dễ dàng thuyết phục về chiến lược giao dịch của họ và sẵn sàng thực hiện suy nghĩ của họ với một báo cáo hiệu suất hoặc đường cong quỹ trông tốt.
Tôi đã thấy nhiều chiến lược giao dịch, và tỷ lệ thành công có thể đạt đến 50% khi kiểm tra lại. Dưới tiền đề của tỷ lệ thắng cao như vậy, vẫn có tỷ lệ lợi nhuận và lỗ cao hơn là 1: 1. Tuy nhiên, một khi các chiến lược này được thực hiện, tất cả chúng đều đang mất tiền. Có nhiều lý do cho điều này. Trong số những lý do này, mẫu dữ liệu quá nhỏ là lý do chính, dẫn đến sự lệch của dữ liệu.
Tuy nhiên, giao dịch là một điều rất phức tạp, và nó rất rõ ràng sau đó, nhưng nếu chúng ta quay lại bản gốc, chúng ta vẫn cảm thấy choáng ngợp. Điều này liên quan đến nguyên nhân gốc rễ của định lượng - những hạn chế của dữ liệu lịch sử. vì vậy, nếu chúng ta chỉ sử dụng dữ liệu lịch sử hạn chế để kiểm tra chiến lược giao dịch, thật khó để tránh vấn đề
Xét nghiệm ngoài mẫu là gì?
Làm thế nào để sử dụng đầy đủ dữ liệu hạn chế để kiểm tra khoa học chiến lược giao dịch khi dữ liệu hạn chế? Câu trả lời là phương pháp kiểm tra ngoài mẫu. Trong quá trình kiểm tra ngược, dữ liệu lịch sử được chia thành hai phân đoạn theo trình tự thời gian.
Nếu chiến lược của bạn luôn hợp lệ, sau đó tối ưu hóa một số tập hợp các thông số tốt nhất trong dữ liệu tập huấn, và áp dụng các tập hợp các thông số này cho dữ liệu tập hợp thử nghiệm để kiểm tra lại. Lý tưởng nhất, kết quả kiểm tra lại nên gần như giống với các tập hợp đào tạo, hoặc sự khác biệt nằm trong phạm vi hợp lý. Sau đó có thể nói rằng chiến lược này tương đối hiệu quả.
Nhưng nếu một chiến lược hoạt động tốt trong tập huấn, nhưng tập thử nghiệm hoạt động kém, hoặc thay đổi rất nhiều, và khi sử dụng các thông số khác vẫn giữ nguyên, thì chiến lược có thể có thiên vị di chuyển dữ liệu.
Ví dụ, giả sử bạn muốn kiểm tra lại thanh thép tương lai hàng hóa. Bây giờ thanh thép có dữ liệu trong khoảng 10 năm (2009 ~ 2019), bạn có thể sử dụng dữ liệu từ năm 2009 đến 2015 làm tập huấn, từ năm 2015 đến 2019, được sử dụng làm tập thử nghiệm. Nếu các thông số tốt nhất được đặt trong tập huấn là (15, 90), (5, 50), (10, 100)... thì chúng tôi đưa các tập hợp các thông số này vào tập thử nghiệm. Bằng cách so sánh hai báo cáo hiệu suất kiểm tra lại và đường cong quỹ xác định xem sự khác biệt của chúng có nằm trong phạm vi hợp lý hay không.
Nếu bạn không sử dụng thử nghiệm ngoài mẫu, chỉ cần trực tiếp sử dụng dữ liệu từ năm 2009 đến 2019 để kiểm tra chiến lược. Kết quả có thể là một báo cáo hiệu suất backtest tốt vì quá phù hợp với dữ liệu lịch sử, nhưng kết quả backtest như vậy có ý nghĩa ít đối với thị trường thực và không có tác dụng hướng dẫn, đặc biệt là các chiến lược có nhiều tham số hơn.
Xét nghiệm nâng cao ngoài mẫu
Như đã đề cập ở trên, dưới tiền đề thiếu dữ liệu lịch sử, nó là một ý tưởng tốt để chia dữ liệu thành hai phần để tạo ra dữ liệu trong và ngoài mẫu.
Nguyên tắc cơ bản của thử nghiệm tái diễn: sử dụng dữ liệu lịch sử dài trước đó để đào tạo mô hình, và sau đó sử dụng dữ liệu tương đối ngắn để thử nghiệm mô hình, và sau đó liên tục di chuyển cửa sổ thời gian để lấy dữ liệu, lặp lại các bước đào tạo và thử nghiệm.
-
Dữ liệu đào tạo: 2000-2001, dữ liệu thử nghiệm: 2002;
-
Dữ liệu đào tạo: 2001-2002, dữ liệu thử nghiệm: 2003;
-
Dữ liệu đào tạo: 2002 đến 2003, dữ liệu thử nghiệm: 2004;
-
Dữ liệu đào tạo: 2003 đến 2004, dữ liệu thử nghiệm: 2005;
-
Dữ liệu đào tạo: 2004 đến 2005, dữ liệu thử nghiệm: 2006;
...và cứ thế...
Cuối cùng, kết quả thử nghiệm (2002, 2003, 2004, 2005, 2006...) đã được phân tích thống kê để đánh giá toàn diện hiệu suất của chiến lược.
Biểu đồ sau có thể giải thích nguyên tắc của thử nghiệm tái quy trực quan:
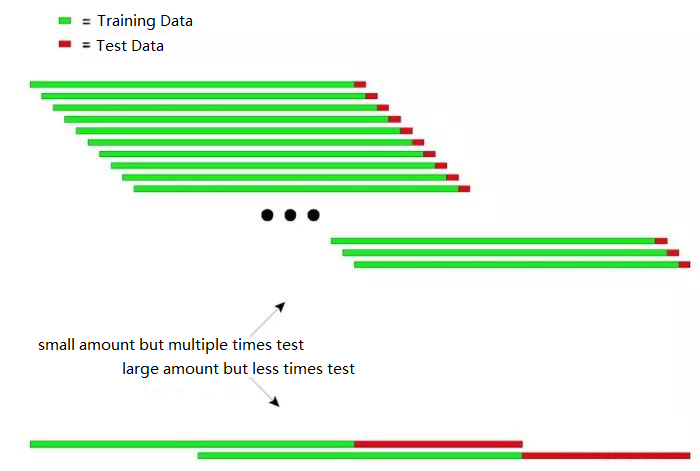
Hình trên cho thấy hai phương pháp thử nghiệm tái diễn.
Loại đầu tiên: số lượng nhỏ nhưng thử nhiều lần
Loại thứ hai: số lượng lớn nhưng thử nghiệm ít hơn
Trong các ứng dụng thực tế, nhiều thử nghiệm có thể được thực hiện bằng cách thay đổi chiều dài của dữ liệu thử nghiệm để xác định sự ổn định của mô hình để đáp ứng dữ liệu không tĩnh.
Nguyên tắc cơ bản của thử nghiệm kiểm tra chéo: chia tất cả dữ liệu thành N phần, sử dụng N-1 phần để đào tạo mỗi lần, và sử dụng phần còn lại để thử nghiệm.
Từ năm 2000 đến năm 2003, nó được chia thành bốn phần theo phân chia hàng năm.
-
Dữ liệu đào tạo: 2001-2003, dữ liệu thử nghiệm: 2000;
-
Dữ liệu đào tạo: 2000-2002, dữ liệu thử nghiệm: 2003;
-
Dữ liệu đào tạo: 2000, 2001, 2003, dữ liệu thử nghiệm: 2002;
-
Dữ liệu đào tạo: 2000, 2002, 2003, dữ liệu thử nghiệm: 2001;
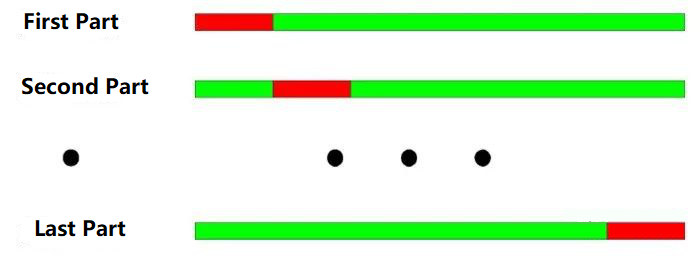
Như thể hiện trong hình trên: Ưu điểm lớn nhất của kiểm tra chéo là tận dụng đầy đủ các dữ liệu hạn chế, và mỗi dữ liệu đào tạo cũng là dữ liệu thử nghiệm.
-
Khi dữ liệu giá không ổn định, kết quả thử nghiệm của mô hình thường không đáng tin cậy. Ví dụ, sử dụng dữ liệu năm 2008 để đào tạo và dữ liệu năm 2005 để thử nghiệm. Rất có thể môi trường thị trường năm 2008 đã thay đổi rất nhiều so với năm 2005, do đó kết quả của các thử nghiệm mô hình không đáng tin cậy.
-
Tương tự như lần đầu tiên, trong thử nghiệm kiểm tra chéo, nếu mô hình được đào tạo với dữ liệu mới nhất và mô hình được thử nghiệm với dữ liệu cũ hơn, điều này không phải là rất hợp lý.
Ngoài ra, khi thử nghiệm mô hình chiến lược định lượng, cả thử nghiệm tái quy và thử nghiệm kiểm tra chéo đều gặp vấn đề chồng chéo dữ liệu.
Khi phát triển mô hình chiến lược giao dịch, hầu hết các chỉ số kỹ thuật đều dựa trên dữ liệu lịch sử của một khoảng thời gian nhất định. Ví dụ, sử dụng các chỉ số xu hướng để tính toán dữ liệu lịch sử trong 50 ngày qua, nhưng cho ngày giao dịch tiếp theo, được tính toán từ dữ liệu trong 50 ngày đầu tiên của ngày giao dịch, dữ liệu để tính toán hai chỉ số là giống nhau trong 49 ngày. Điều này sẽ dẫn đến một sự thay đổi rất không đáng kể trong chỉ số cho mỗi hai ngày liền kề.
Sự chồng chéo dữ liệu có thể có các hiệu ứng sau:
-
Sự thay đổi chậm trong kết quả dự đoán bởi mô hình dẫn đến một sự thay đổi chậm trong vị trí, đó là sự biến động của các chỉ số mà chúng ta thường nói.
-
Một số giá trị thống kê để kiểm tra kết quả mô hình không có sẵn. Do mối tương quan chuỗi do dữ liệu lặp lại, kết quả của một số thử nghiệm thống kê không đáng tin cậy.
Một chiến lược giao dịch tốt sẽ có lợi trong tương lai. thử nghiệm ngoài mẫu, ngoài việc phát hiện khách quan các chiến lược giao dịch, hiệu quả hơn trong việc tiết kiệm thời gian cho các nhà giao dịch định lượng. Trong hầu hết các trường hợp, rất nguy hiểm khi sử dụng các thông số tối ưu của tất cả các mẫu trực tiếp.
Nếu tất cả các dữ liệu lịch sử trước thời điểm tối ưu hóa tham số được phân biệt, và dữ liệu được chia thành dữ liệu trong mẫu và dữ liệu bên ngoài mẫu, tham số được tối ưu hóa bằng cách sử dụng dữ liệu trong mẫu, và sau đó mẫu bên ngoài mẫu được sử dụng cho thử nghiệm ngoài mẫu.
Tóm lại
Giống như việc giao dịch, chúng ta không bao giờ có thể quay lại thời gian và đưa ra quyết định chính xác cho chính mình. Nếu bạn có khả năng đi lại thời gian, bạn sẽ không cần phải giao dịch.
Tuy nhiên, ngay cả với dữ liệu lịch sử khổng lồ, trước tương lai vô tận và không thể đoán trước, lịch sử cực kỳ khan hiếm. Do đó, hệ thống giao dịch dựa trên lịch sử cuối cùng sẽ chìm theo thời gian. Bởi vì lịch sử không thể làm cạn kiệt tương lai. Do đó, một hệ thống giao dịch kỳ vọng tích cực hoàn chỉnh phải được hỗ trợ bởi các nguyên tắc và logic vốn có của nó.
Các bài tập sau giờ học
-
Những hiện tượng nào trong cuộc sống thực là thiên vị của người sống sót?
-
Sử dụng nền tảng FMZ Quant để so sánh backtest trong và ngoài mẫu.
- Khi nào bạn có thể thêm một sàn giao dịch cà phê?
- Có lẽ vì lý do gì khi cài đặt Linux host trên điện thoại qua thiết bị mô phỏng thiết bị cuối cùng hiển thị bad system call?
- Bạn có thể điều chỉnh số độ sâu mà GetDepth trả về không?
- Làm thế nào để triển khai một robot trên một nền tảng, Win hoặc Mac
- Có một lỗi trong việc thêm token vào sàn giao dịch tương lai.
- Người quản trị có thể cung cấp mã kết nối wss cho Deribit không?
- BitMax sử dụng tổng hợp
- Hãy hỏi chương trình trực quan làm thế nào để ghi lại giá cao nhất
- Có cách nào để có được giá cả cho nhiều cặp tiền kỹ thuật số cùng một lúc không?
- 5.5 Tối ưu hóa chiến lược giao dịch
- 5.3 Làm thế nào để đọc báo cáo hiệu suất backtest chiến lược
- Câu hỏi thường gặp
- Trong thử nghiệm tiền kỹ thuật số, nếu chu kỳ nền của tick là 1 phút, bạn có thể mô phỏng một số tick dữ liệu mỗi phút?
- Một số chiến lược định lượng Bitcoin và tiền kỹ thuật số đáng học
- 5.2 Làm thế nào để thực hiện backtesting giao dịch định lượng
- Xin hỏi, trong bài kiểm tra chiến lược tiền kỹ thuật số, cách chụp là đóng cửa với thanh hiện tại hay mở cửa với thanh tiếp theo?
- Hỏi trong đánh giá chiến lược tiền kỹ thuật số, khối lượng giao dịch mở ngang là nhỏ, tại sao thường không được giao dịch, vị trí đóng băngFrozenAmount > 0
- 5.1 Ý nghĩa và cái bẫy của backtesting
- 4.6 Cách thực hiện các chiến lược trong ngôn ngữ C++
- Một câu hỏi khác về Emma.