Mạng thần kinh và chuỗi giao dịch định lượng tiền kỹ thuật số (2) - Học tập và đào tạo chuyên sâu Chiến lược giao dịch Bitcoin
Tác giả:Lydia., Tạo: 2023-01-12 16:49:09, Cập nhật: 2023-09-20 10:07:39
Mạng thần kinh và chuỗi giao dịch định lượng tiền kỹ thuật số (2) - Học tập và đào tạo chuyên sâu Chiến lược giao dịch Bitcoin
1. Lời giới thiệu
Trong bài viết trước, chúng tôi đã giới thiệu việc sử dụng mạng lưới LSTM để dự đoán giá của Bitcoin:https://www.fmz.com/bbs-topic/9879, như đã đề cập trong bài viết, đây chỉ là một dự án đào tạo nhỏ để làm quen với RNN và pytorch. Bài viết này sẽ giới thiệu việc sử dụng học tập chuyên sâu để đào tạo các chiến lược giao dịch trực tiếp. Mô hình học tập chuyên sâu là OpenAI nguồn mở PPO, và môi trường đề cập đến phong cách của phòng tập thể dục. Để tạo điều kiện dễ hiểu và thử nghiệm, mô hình PPO của LSTM và môi trường phòng tập thể dục cho backtesting được viết trực tiếp mà không sử dụng các gói sẵn sàng. PPO, hoặc tối ưu hóa chính sách gần, là một cải tiến tối ưu hóa của Policy Gradient. gym cũng được phát hành bởi OpenAI. Nó có thể tương tác với mạng chiến lược và phản hồi tình trạng và phần thưởng của môi trường hiện tại. Nó giống như thực hành học tập chuyên sâu. Nó sử dụng mô hình PPO của LSTM để thực hiện các hướng dẫn, chẳng hạn như mua, bán hoặc không hoạt động trực tiếp theo thông tin thị trường của Bitcoin. Phản hồi được cung cấp bởi môi trường backtest. Thông qua đào tạo, mô hình được tối ưu hóa liên tục để đạt được mục tiêu lợi nhuận chiến lược. Đọc bài viết này đòi hỏi một nền tảng nhất định về học tập chuyên sâu về Python, pytorch và DRL. Nhưng nó không quan trọng nếu bạn không thể. Nó dễ dàng để học và bắt đầu với mã được đưa ra trong bài viết này.www.fmz.comChào mừng bạn tham gia nhóm QQ: 863946592 để liên lạc.
2. Dữ liệu và tài liệu tham khảo học tập
Dữ liệu giá Bitcoin lấy từ nền tảng FMZ Quant Trading:https://www.quantinfo.com/Tools/View/4.html- Không. Một bài viết sử dụng DRL + gym để đào tạo các chiến lược giao dịch:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4. Một số ví dụ để bắt đầu với pytorch:https://github.com/yunjey/pytorch-tutorial- Không. Bài viết này sẽ thực hiện bởi mô hình LSTM-PPO trực tiếp:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py- Không. Các bài viết về PPO:https://zhuanlan.zhihu.com/p/38185553- Không. Nhiều bài viết về DRL:https://www.zhihu.com/people/flood-sung/posts. Về phòng tập thể dục, bài viết này không yêu cầu cài đặt, nhưng nó rất phổ biến trong học tập chuyên sâu:https://gym.openai.com/.
3. LSTM-PPO
Để giải thích chi tiết về PPO, bạn có thể tìm hiểu từ các tài liệu tham khảo trước đây. Đây chỉ là một giới thiệu đơn giản về các khái niệm. Phiên bản cuối cùng của mạng lưới LSTM chỉ dự đoán giá. Cách mua và bán dựa trên giá dự đoán sẽ phải được thực hiện riêng biệt. Nó là tự nhiên để nghĩ rằng đầu ra trực tiếp của hành động giao dịch sẽ trực tiếp hơn. Đây là trường hợp của Policy Gradient, có thể cung cấp xác suất của các hành động khác nhau theo thông tin môi trường đầu vào s. Mất của LSTM là sự khác biệt giữa giá dự đoán và giá thực tế, trong khi mất PG là - log § * Q, nơi p là xác suất của một hành động đầu ra, và Q là giá trị của hành động (như điểm thưởng trực quan).
Mã nguồn của LSTM-PPO được đưa ra dưới đây, có thể được hiểu kết hợp với dữ liệu trước đây:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Môi trường kiểm tra lại Bitcoin
Theo định dạng của gym, có một phương pháp khởi tạo đặt lại. Step nhập hành động, và kết quả được trả về là (tình trạng tiếp theo, thu nhập hành động, có phải kết thúc hay không, thông tin bổ sung). Toàn bộ môi trường backtest cũng có 60 dòng. Bạn có thể tự sửa đổi các phiên bản phức tạp hơn. Mã cụ thể là:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Một số chi tiết đáng chú ý
- Tại sao tài khoản ban đầu có tiền tệ?
Công thức tính toán lợi nhuận của môi trường backtest là: lợi nhuận hiện tại = giá trị tài khoản hiện tại - giá trị hiện tại của tài khoản ban đầu. Điều này có nghĩa là nếu giá Bitcoin giảm và chiến lược thực hiện một hoạt động bán tiền xu, ngay cả khi tổng giá trị tài khoản giảm, chiến lược thực sự nên được thưởng. Nếu kiểm tra lại mất nhiều thời gian, tài khoản ban đầu có thể có ít tác động, nhưng nó sẽ có tác động lớn ở đầu. Việc tính toán lợi nhuận tương đối đảm bảo rằng mỗi hoạt động chính xác sẽ nhận được một phần thưởng tích cực.
- Tại sao thị trường được lấy mẫu trong quá trình đào tạo?
Số lượng dữ liệu tổng cộng là hơn 10.000 đường K. Nếu bạn chạy một vòng lặp đầy đủ mỗi lần, nó sẽ mất nhiều thời gian, và chiến lược phải đối mặt với cùng một tình huống mỗi lần, nó có thể dễ dàng hơn để quá phù hợp. Lấy 500 thanh tại một thời điểm như một backtest. Mặc dù vẫn có thể quá phù hợp, chiến lược phải đối mặt với hơn 10.000 khởi động khác nhau.
- Nếu không có tiền tệ hay tiền thì sao?
Tình huống này không được xem xét trong môi trường backtest. Nếu tiền tệ đã được bán hết hoặc số lượng giao dịch tối thiểu không thể đạt được, thì hoạt động bán hàng tương đương với không hoạt động thực tế. Nếu giá giảm, theo phương pháp tính toán lợi nhuận tương đối, nó vẫn dựa trên lợi nhuận tích cực chiến lược. Tác động của tình huống này là khi chiến lược đánh giá thị trường đang giảm và tiền tệ còn lại của tài khoản không thể được bán, thì không thể phân biệt hành động bán hàng với hành động không hoạt động, nhưng nó không ảnh hưởng đến đánh giá của chính chiến lược trên thị trường.
- Tại sao tôi nên trả về thông tin tài khoản như trạng thái?
Mô hình PPO có một mạng lưới giá trị để đánh giá giá trị của trạng thái hiện tại. Rõ ràng, nếu chiến lược đánh giá rằng giá sẽ tăng, toàn bộ trạng thái sẽ có giá trị tích cực chỉ khi tài khoản hiện tại nắm giữ Bitcoin, và ngược lại. Do đó, thông tin tài khoản là một cơ sở quan trọng để đánh giá mạng lưới giá trị.
- Khi nào nó sẽ trở lại không hoạt động?
Khi chiến lược đánh giá rằng lợi nhuận được mang lại bởi giao dịch không thể trang trải phí xử lý, nó nên quay lại không hoạt động. Mặc dù mô tả trước đây sử dụng các chiến lược nhiều lần để đánh giá xu hướng giá, nhưng chỉ để dễ hiểu. Trên thực tế, mô hình PPO này không dự đoán thị trường, nhưng chỉ đưa ra xác suất của ba hành động.
6. Thu thập dữ liệu và đào tạo
Như trong bài viết trước, phương pháp và định dạng thu thập dữ liệu là như sau: K-line khoảng thời gian một giờ của cặp giao dịch Bitfinex Exchange BTC_USD từ ngày 7 tháng 5 năm 2018 đến ngày 27 tháng 6 năm 2019:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Do sử dụng mạng lưới LSTM, thời gian đào tạo rất dài. Tôi đã chuyển sang phiên bản GPU, nhanh hơn khoảng ba lần.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
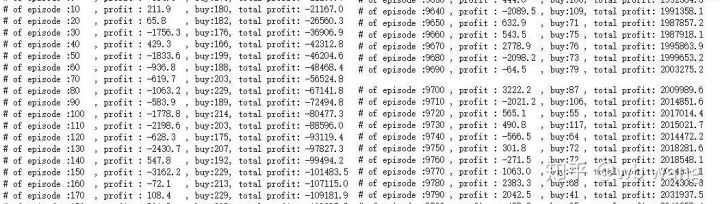
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Kết quả đào tạo và phân tích
Sau một thời gian dài chờ đợi:

Trước hết, hãy nhìn vào thị trường dữ liệu đào tạo. nói chung, nửa đầu là một sự suy giảm lâu dài, và nửa sau là một sự phục hồi mạnh mẽ.
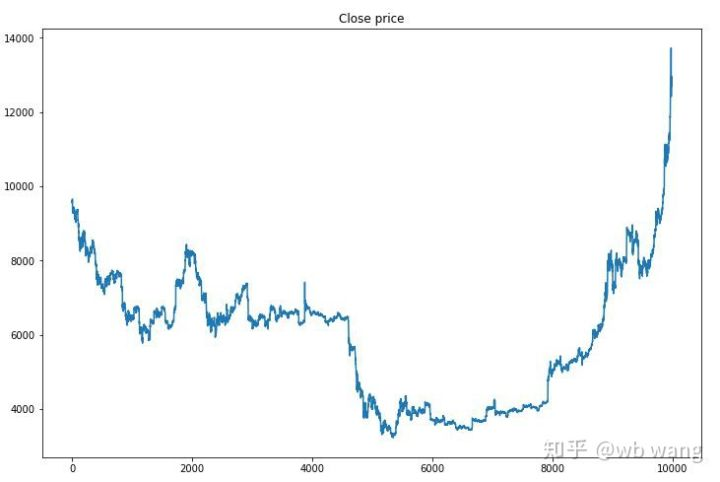
Có nhiều giao dịch mua trong giai đoạn đầu của đào tạo, và về cơ bản không có một vòng lợi nhuận nào. Đến giữa khóa đào tạo, giao dịch mua đã dần giảm, và xác suất lợi nhuận cũng tăng lên, nhưng vẫn còn một cơ hội thua lỗ lớn.
Đơn giản hóa lợi nhuận của mỗi vòng, và kết quả là như sau:
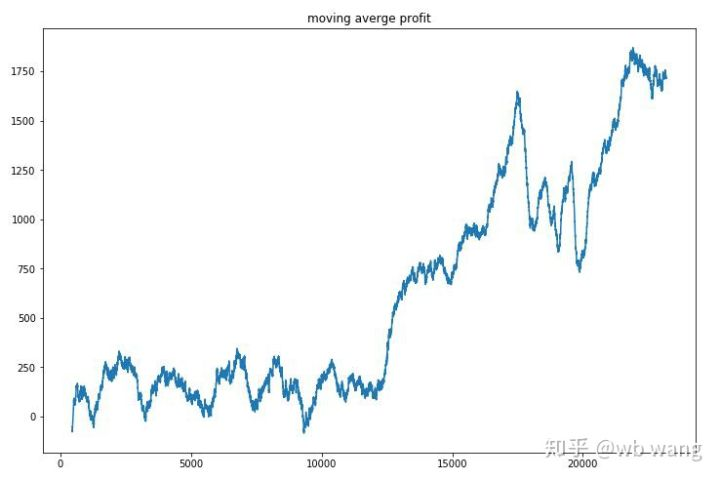
Chiến lược này nhanh chóng loại bỏ tình huống mà lợi nhuận sớm là tiêu cực, nhưng sự biến động là lớn. Lợi nhuận không tăng nhanh cho đến sau 10.000 vòng.
Sau khi đào tạo cuối cùng, hãy để mô hình chạy tất cả dữ liệu một lần nữa để xem nó hoạt động như thế nào. Trong thời gian đó, ghi lại tổng giá trị thị trường của tài khoản, số lượng Bitcoin được giữ, tỷ lệ giá trị Bitcoin và tổng lợi nhuận. Đầu tiên là tổng giá trị thị trường, và tổng lợi nhuận tương tự như nó, chúng sẽ không được đăng:
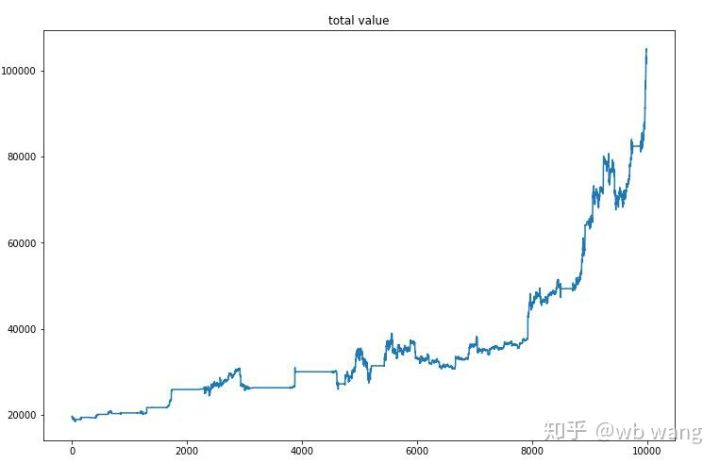
Tổng giá trị thị trường tăng chậm trong thị trường gấu đầu tiên, và theo kịp với sự gia tăng trong thị trường tăng sau đó, nhưng vẫn có những tổn thất định kỳ.
Cuối cùng, hãy nhìn vào tỷ lệ các vị trí. Trục trái của biểu đồ là tỷ lệ các vị trí, và trục phải là thị trường. Có thể đánh giá sơ bộ rằng mô hình quá phù hợp. Tần suất các vị trí thấp trong thị trường gấu sớm và cao ở đáy thị trường. Cũng có thể thấy rằng mô hình chưa học cách nắm giữ các vị trí dài hạn và luôn bán nhanh.
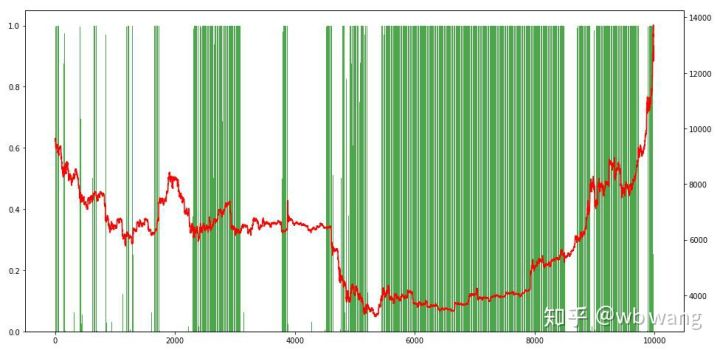
8. Phân tích dữ liệu thử nghiệm
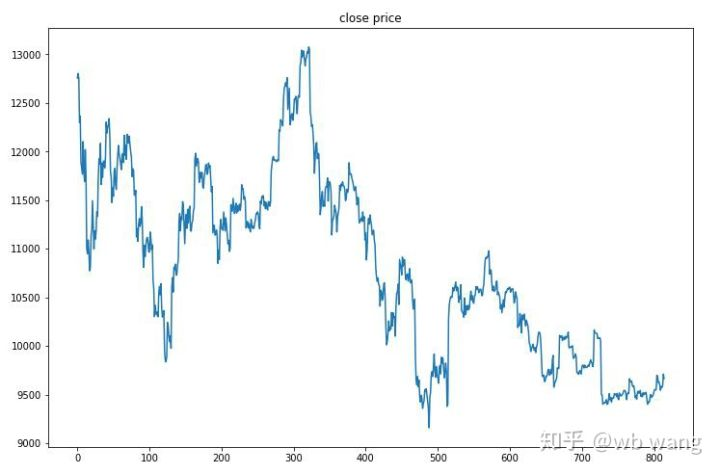
Thị trường một giờ của Bitcoin từ ngày 27 tháng 6 năm 2019 cho đến nay được thu được từ dữ liệu thử nghiệm. Có thể thấy từ biểu đồ rằng giá đã giảm từ 13.000 USD xuống còn hơn 9.000 USD, đó là một thử nghiệm tuyệt vời cho mô hình.
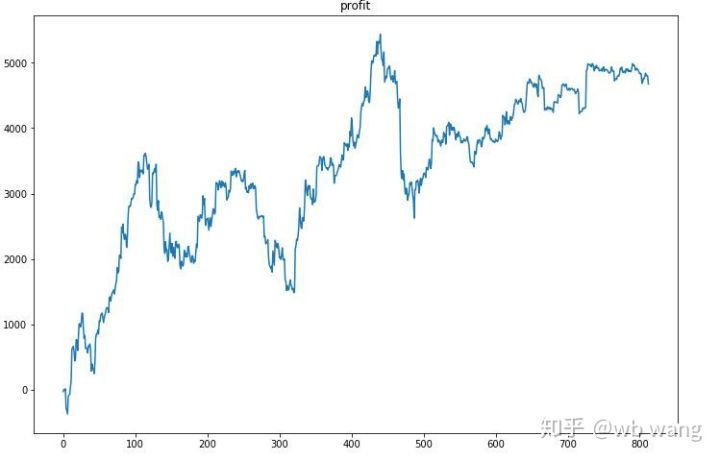
Trước hết, kết quả tương đối cuối cùng đã thực hiện như vậy, nhưng không có tổn thất.
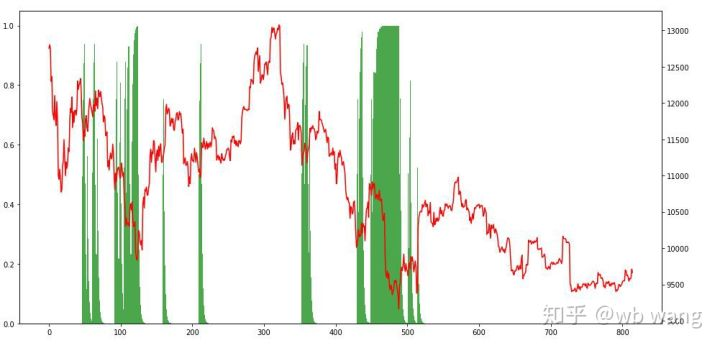
Nhìn vào tình hình vị trí, chúng ta có thể đoán rằng mô hình có xu hướng mua sau khi giảm mạnh và bán sau khi phục hồi.
9. Tóm lại
Trong bài báo này, một robot giao dịch tự động Bitcoin được đào tạo với sự giúp đỡ của PPO, một phương pháp học tập chuyên sâu, và một số kết luận được thu được. Do thời gian hạn chế, vẫn còn một số khía cạnh cần được cải thiện trong mô hình. Chào mừng cuộc thảo luận. Bài học lớn nhất là đối với phương pháp chuẩn hóa dữ liệu, đừng sử dụng quy mô và các phương pháp khác, nếu không mô hình sẽ nhanh chóng nhớ mối quan hệ giữa giá và thị trường, và rơi vào tình trạng quá phù hợp. Tỷ lệ thay đổi chuẩn hóa là dữ liệu tương đối, khiến mô hình khó nhớ mối quan hệ với thị trường và buộc phải tìm mối quan hệ giữa tỷ lệ thay đổi và tăng và giảm.
Giới thiệu các bài viết trước: Một chiến lược tần số cao mà tôi tiết lộ đã từng rất có lợi:https://www.fmz.com/bbs-topic/9886.
- Xác định số lượng phân tích cơ bản trong thị trường tiền điện tử: Hãy để dữ liệu nói cho chính nó!
- Các nghiên cứu định lượng cơ bản của vòng đồng tiền - đừng tin vào những giáo viên mờ nhạt, nói khách quan về dữ liệu!
- Một công cụ thiết yếu trong lĩnh vực giao dịch định lượng - nhà phát minh mô-đun khám phá dữ liệu định lượng
- Kiểm soát mọi thứ - giới thiệu về FMZ Phiên bản mới của Terminal giao dịch (với mã nguồn TRB Arbitrage)
- Có tất cả các thông tin về FMZ phiên bản mới của giao dịch đầu cuối (được thêm mã nguồn TRB)
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (II)
- Làm thế nào để khai thác robot bán hàng không có não với một chiến lược tần số cao trong 80 dòng mã
- FMZ định lượng: Phân tích các trường hợp thiết kế nhu cầu phổ biến của thị trường tiền điện tử (II)
- Cách khai thác robot vô trí tuệ để bán bằng chiến lược tần số cao 80 dòng mã
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (I)
- FMZ định lượng: Các nhu cầu phổ biến của thị trường tiền điện tử