Những suy nghĩ về các chiến lược giao dịch tần số cao (1)
Tác giả:Lydia., Tạo: 2023-08-04 13:47:39, Cập nhật: 2023-09-12 15:50:10
Những suy nghĩ về các chiến lược giao dịch tần số cao (1)
Tôi đã viết hai bài viết về giao dịch tần số cao của tiền kỹ thuật số, cụ thể là
Nguồn lợi nhuận tần số cao
Trong các bài viết trước đây, tôi đã đề cập rằng các chiến lược tần số cao đặc biệt phù hợp với các thị trường có biến động vô cùng biến động. Sự thay đổi giá của một công cụ giao dịch trong một khoảng thời gian ngắn bao gồm xu hướng và dao động tổng thể. Mặc dù thực sự có lợi nhuận nếu chúng ta có thể dự đoán chính xác những thay đổi xu hướng, nhưng đây cũng là khía cạnh khó khăn nhất. Trong bài viết này, tôi sẽ chủ yếu tập trung vào các chiến lược người tạo tần số cao và sẽ không đi sâu vào dự đoán xu hướng. Trong các thị trường dao động, bằng cách đặt lệnh thầu và yêu cầu một cách chiến lược, nếu tần số giao dịch là đủ cao và biên lợi nhuận là đáng kể, nó có thể trang trải những tổn thất tiềm ẩn do xu hướng. Bằng cách này, lợi nhuận có thể đạt được mà không cần dự đoán các biến động thị trường. Hiện nay, sàn giao dịch cung cấp giảm giá cho các giao dịch người tạo tần số, cũng là một thành phần của lợi nhuận.
Những vấn đề cần giải quyết
-
Vấn đề đầu tiên trong việc thực hiện một chiến lược đặt cả lệnh mua và bán là xác định vị trí đặt các lệnh này. Các lệnh càng gần với độ sâu thị trường, xác suất thực thi càng cao. Tuy nhiên, trong điều kiện thị trường biến động cao, giá mà một lệnh được thực thi ngay lập tức có thể xa độ sâu thị trường, dẫn đến lợi nhuận không đủ. Mặt khác, đặt lệnh quá xa làm giảm xác suất thực thi. Đây là một vấn đề tối ưu hóa cần phải được giải quyết.
-
Kiểm soát vị trí là rất quan trọng để quản lý rủi ro. Một chiến lược không thể tích lũy các vị trí quá nhiều trong thời gian dài. Điều này có thể được giải quyết bằng cách kiểm soát khoảng cách và số lượng lệnh được đặt, cũng như đặt giới hạn cho các vị trí tổng thể.
Để đạt được các mục tiêu trên, mô hình hóa và ước tính là cần thiết cho các khía cạnh khác nhau như xác suất thực hiện, lợi nhuận từ thực hiện và ước tính thị trường. Có rất nhiều bài báo và bài báo có sẵn về chủ đề này, sử dụng các từ khóa như
Dữ liệu yêu cầu
Binance cung cấpDữ liệu có thể tải xuốngcho các giao dịch cá nhân và lệnh mua/bán tốt nhất. Dữ liệu chiều sâu có thể được tải xuống thông qua API của họ bằng cách được liệt kê trắng, hoặc có thể được thu thập thủ công. Đối với mục đích kiểm tra lại, dữ liệu giao dịch tổng hợp là đủ. Trong bài viết này, chúng tôi sẽ sử dụng ví dụ về dữ liệu HOOKUSDT-aggTrades-2023-01-27.
Trong [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Dữ liệu thương mại cá nhân bao gồm:
- agg_trade_id: ID của giao dịch tổng hợp.
- Giá: Giá mà giao dịch được thực hiện.
- Số lượng: Số lượng giao dịch.
- first_trade_id: Trong trường hợp nhiều giao dịch được tổng hợp, đây đại diện cho ID giao dịch đầu tiên.
- last_trade_id: ID của giao dịch cuối cùng trong tổng hợp.
- Transaction_time: Thời gian thực hiện giao dịch.
- is_buyer_maker: Chỉ ra hướng giao dịch.
True đại diện cho lệnh mua được thực hiện như một người tạo, trong khi lệnh bán được thực hiện như một người nhận.
Có thể thấy rằng có 660.000 giao dịch được thực hiện trong ngày đó, cho thấy một thị trường hoạt động rất tích cực.
Trong [4]:
trades = pd.read_csv('COMPUSDT-aggTrades-2023-07-02.csv')
trades
Ra khỏi [1]: ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
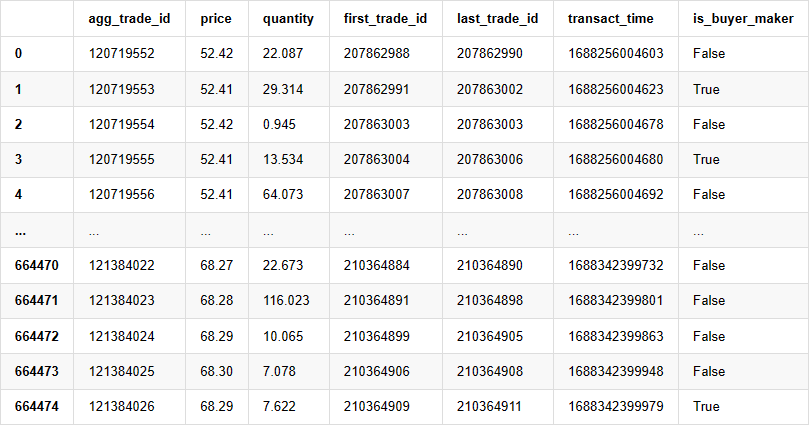
664475 hàng × 7 cột
Mô hình hóa số tiền giao dịch cá nhân
Đầu tiên, dữ liệu được xử lý bằng cách chia các giao dịch ban đầu thành hai nhóm: lệnh mua được thực hiện như người tạo và lệnh bán được thực hiện như người nhận. Ngoài ra, dữ liệu giao dịch tổng hợp ban đầu kết hợp các giao dịch được thực hiện cùng một lúc, cùng một mức giá và theo cùng một hướng thành một điểm dữ liệu duy nhất. Ví dụ, nếu có một đơn đặt hàng mua duy nhất với khối lượng 100, nó có thể được chia thành hai giao dịch với khối lượng lần lượt 60 và 40, nếu giá khác nhau. Điều này có thể ảnh hưởng đến ước tính khối lượng lệnh mua. Do đó, cần phải tổng hợp dữ liệu một lần nữa dựa trên thời gian giao dịch. Sau lần tổng hợp thứ hai này, khối lượng dữ liệu được giảm 140.000 hồ sơ.
Trong [6]:
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
sell_trades = trades[trades['is_buyer_maker']==True].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
sell_trades = sell_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
sell_trades['interval']=sell_trades['transact_time'] - sell_trades['transact_time'].shift()
Trong [10]:
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
Bên ngoài [10]: 146181
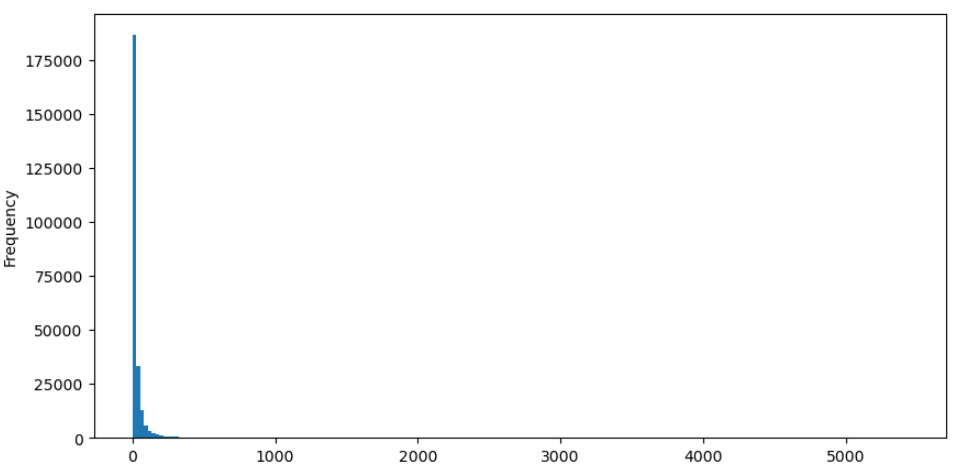
Lấy lệnh mua làm ví dụ, hãy đầu tiên vẽ biểu đồ. Có thể quan sát thấy rằng có một hiệu ứng đuôi dài đáng kể, với phần lớn dữ liệu tập trung về phía phần bên trái của biểu đồ. Tuy nhiên, cũng có một vài giao dịch lớn được phân phối về phía cuối đuôi.
Trong [36]:
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
Bên ngoài [36]:
Để quan sát dễ dàng hơn, hãy cắt đuôi và phân tích dữ liệu.
Trong [37]:
buy_trades['quantity'][buy_trades['quantity']<200].plot.hist(bins=200,figsize=(10, 5));
Bên ngoài [37]:
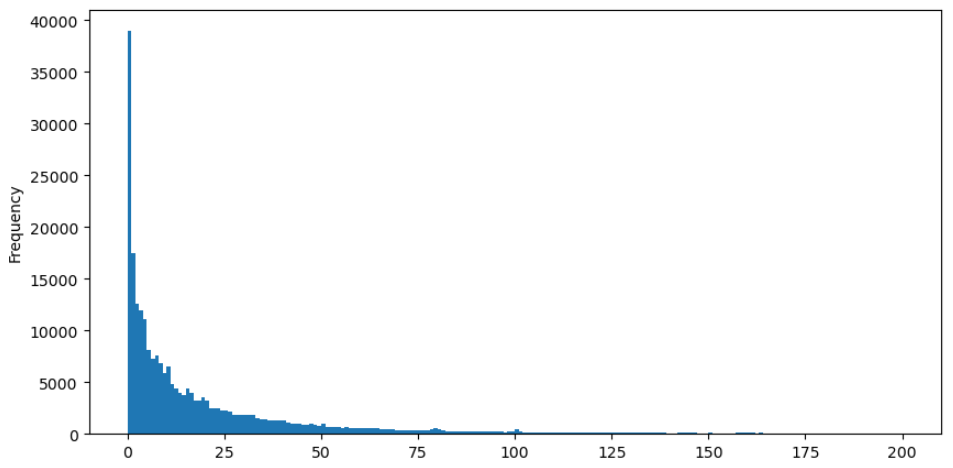
Có rất nhiều nghiên cứu về sự phân bố số lượng giao dịch. Đã phát hiện ra rằng số lượng giao dịch tuân theo sự phân bố theo quy luật năng lượng, còn được gọi là phân bố Pareto, đó là sự phân bố xác suất phổ biến trong vật lý thống kê và khoa học xã hội. Trong sự phân bố theo quy luật năng lượng, xác suất của một sự kiện có kích thước (hoặc tần suất) tỷ lệ thuận với một biểu số âm của kích thước của sự kiện đó. Đặc điểm chính của sự phân phối này là tần suất của các sự kiện lớn (tức là những sự kiện xa trung bình) cao hơn dự kiến trong nhiều phân phối khác. Đây chính xác là đặc điểm của sự phân phối số lượng giao dịch. Hình thức của sự phân bố Pareto được đưa ra bởi P ((x) = C ((x ^ - α). Hãy kiểm chứng bằng thực nghiệm.
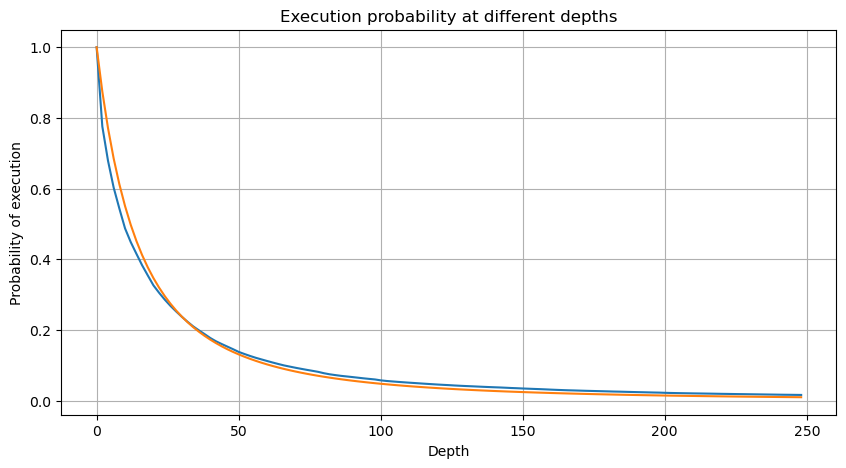
Biểu đồ dưới đây đại diện cho xác suất số lượng giao dịch vượt quá một giá trị nhất định. Dòng màu xanh đại diện cho xác suất thực tế, trong khi đường màu cam đại diện cho xác suất mô phỏng. Xin lưu ý rằng chúng tôi sẽ không đi vào các thông số cụ thể tại thời điểm này. Có thể quan sát thấy rằng sự phân phối thực sự tuân theo sự phân phối Pareto. Vì xác suất số lượng giao dịch lớn hơn 0 là 1, và để đáp ứng bình thường hóa, phương trình phân phối nên như sau:
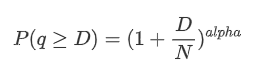
Ở đây, N là tham số cho bình thường hóa. Chúng ta sẽ chọn số lượng giao dịch trung bình, M, và đặt alpha là -2.06. Ước tính cụ thể của alpha có thể được thu được bằng cách tính toán giá trị P khi D = N. Cụ thể, alpha = log (((P(d>M)) / log ((2). Việc chọn các điểm khác nhau có thể dẫn đến sự khác biệt nhỏ trong giá trị của alpha.
Trong [55]:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
alpha = np.log(np.mean(buy_trades['quantity'] > mean_quantity))/np.log(2)
mean_quantity = buy_trades['quantity'].mean()
probabilities_s = np.array([(1+depth/mean_quantity)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Ra ngoài[55]:
Trong [56]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
Ra ngoài[56]:
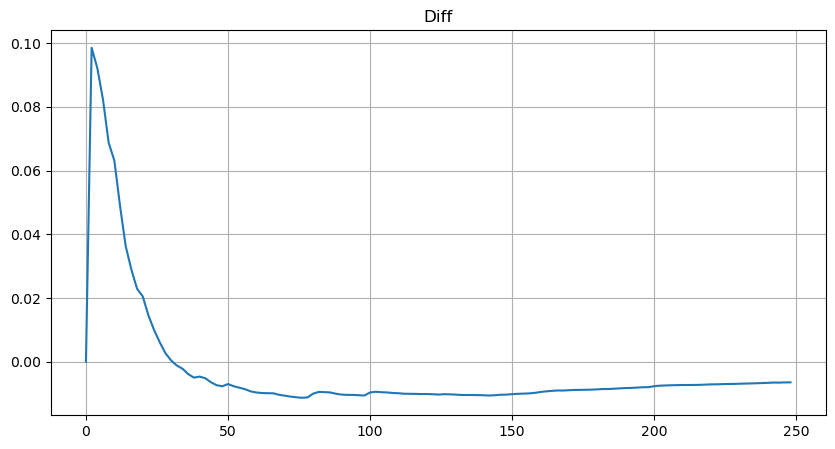
Tuy nhiên, ước tính này chỉ là ước tính, như được hiển thị trong biểu đồ nơi chúng tôi vẽ sự khác biệt giữa các giá trị mô phỏng và thực tế. Khi số lượng giao dịch nhỏ, độ lệch là đáng kể, thậm chí gần 10%. Mặc dù chọn các điểm khác nhau trong ước tính tham số có thể cải thiện độ chính xác của xác suất của điểm cụ thể đó, nhưng nó không giải quyết vấn đề lệch tổng thể. Sự khác biệt này phát sinh từ sự khác biệt giữa sự phân phối quy luật điện và sự phân phối thực tế. Để có được kết quả chính xác hơn, phương trình của sự phân phối quy luật điện cần phải được sửa đổi. Quá trình cụ thể không được xây dựng ở đây, nhưng tóm tắt, sau một khoảnh khắc hiểu biết, nó được tìm thấy rằng phương trình thực tế nên như sau:
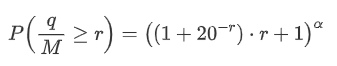
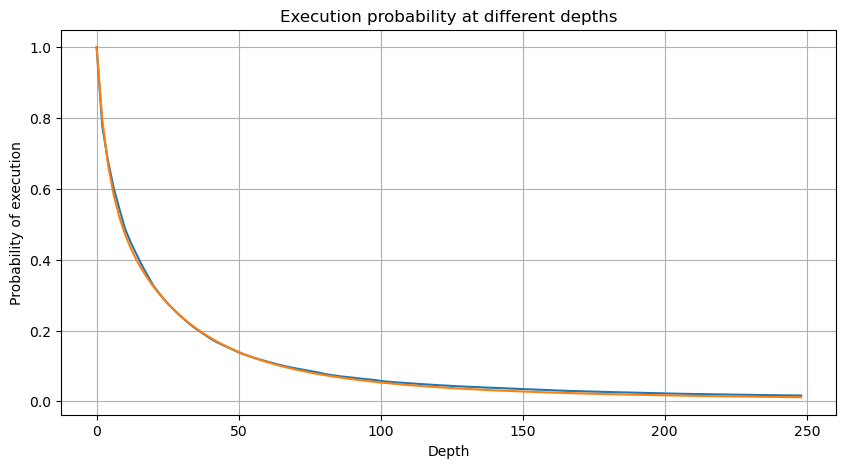
Để đơn giản hóa, hãy sử dụng r = q / M để đại diện cho số lượng giao dịch bình thường. Chúng ta có thể ước tính các tham số bằng cách sử dụng cùng một phương pháp như trước đây. Biểu đồ sau cho thấy sau khi sửa đổi, độ lệch tối đa không quá 2%. Về lý thuyết, có thể thực hiện các điều chỉnh thêm, nhưng mức độ chính xác này đã đủ.
Trong [52]:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([(((1+20**(-depth/mean))*depth+mean)/mean)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Ra ngoài[52]:
Trong [53]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
Ra ngoài[53]:
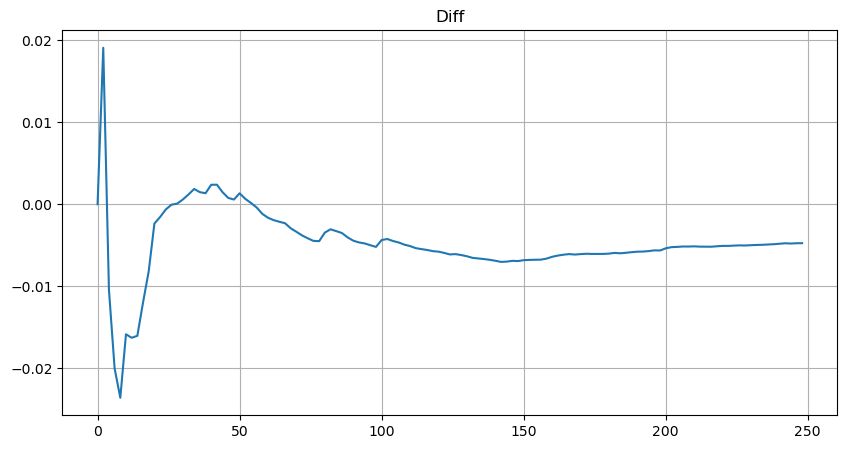
Với phương trình ước tính phân phối số lượng giao dịch, điều quan trọng cần lưu ý là xác suất trong phương trình không phải là xác suất thực tế, mà là xác suất có điều kiện. Tại thời điểm này, chúng ta có thể trả lời câu hỏi: xác suất lệnh tiếp theo sẽ lớn hơn một giá trị nhất định là bao nhiêu? Chúng ta cũng có thể xác định xác suất lệnh ở độ sâu khác nhau được thực hiện (trong kịch bản lý tưởng, mà không xem xét việc thêm lệnh, hủy và xếp hàng ở cùng độ sâu).
Tại thời điểm này, văn bản đã khá dài, và vẫn còn nhiều câu hỏi cần được trả lời.
- Đặt rủi ro Delta đối với các tùy chọn Bitcoin bằng đường cong cười
- Những suy nghĩ về các chiến lược giao dịch tần số cao (5)
- Những suy nghĩ về các chiến lược giao dịch tần số cao (4)
- Tư duy về chiến lược giao dịch tần số cao (5)
- Tư duy về chiến lược giao dịch tần số cao (4)
- Những suy nghĩ về các chiến lược giao dịch tần số cao (3)
- Tư duy về chiến lược giao dịch tần số cao (3)
- Những suy nghĩ về các chiến lược giao dịch tần số cao (2)
- Tư duy về chiến lược giao dịch tần số cao (2)
- Tư duy về chiến lược giao dịch tần số cao (1)
- Tài liệu mô tả cấu hình chứng khoán Futu
- FMZ Quant Uniswap V3 Exchange Pool Liquidity Related Operations Guide (Phần 1)
- FMZ định lượng Uniswap V3 hướng dẫn hoạt động liên quan đến lưu lượng trao đổi hồ ()