Những suy nghĩ về các chiến lược giao dịch tần số cao (5)
Tác giả:Lydia., Tạo: 2023-08-10 15:57:27, Cập nhật: 2023-09-12 15:51:54
Những suy nghĩ về các chiến lược giao dịch tần số cao (5)
Trong bài viết trước, các phương pháp khác nhau để tính giá trung bình đã được giới thiệu, và một giá trung bình được sửa đổi đã được đề xuất.
Dữ liệu cần thiết
Chúng tôi cần dữ liệu luồng lệnh và dữ liệu độ sâu cho mười cấp trên của sổ lệnh, được thu thập từ giao dịch trực tiếp với tần số cập nhật 100ms. Vì sự đơn giản, chúng tôi sẽ không bao gồm các cập nhật thời gian thực cho giá thầu và giá hỏi. Để giảm kích thước dữ liệu, chúng tôi chỉ giữ 100.000 hàng dữ liệu độ sâu và tách dữ liệu thị trường tick-by-tick thành các cột riêng lẻ.
Trong [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
Trong [2]:
tick_size = 0.0001
Trong [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
Trong [4]:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
Trong [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
Trong [6]:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
Trong [7]:
depths = depths.iloc[:100000]
Trong [8]:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
Trong [9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
Trong [10]:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
Trong [11]:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
Hãy nhìn vào sự phân bố của thị trường trong 20 cấp độ này. Nó phù hợp với mong đợi, với nhiều lệnh được đặt xa hơn so với giá thị trường. Ngoài ra, lệnh mua và lệnh bán gần như đối xứng.
Trong [14]:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Ra khỏi [1]:
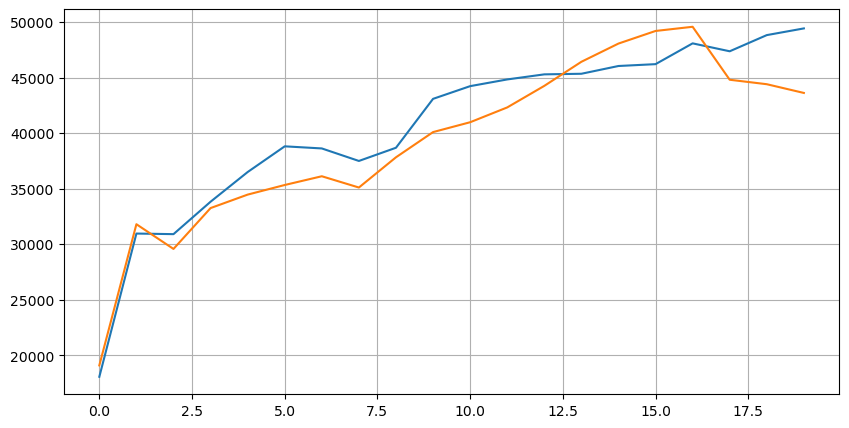
Kết hợp dữ liệu độ sâu với dữ liệu giao dịch để tạo thuận lợi cho việc đánh giá độ chính xác dự đoán. Đảm bảo dữ liệu giao dịch là sau dữ liệu độ sâu. Không xem xét độ trễ, trực tiếp tính lỗi bình phương trung bình giữa giá trị dự đoán và giá giao dịch thực tế. Điều này được sử dụng để đo độ chính xác của dự đoán.
Từ kết quả, lỗi là cao nhất đối với giá trị trung bình của giá thầu và giá hỏi (mid_price). Tuy nhiên, khi thay đổi sang giá trung bình được cân nhắc, lỗi ngay lập tức giảm đáng kể. Sự cải thiện hơn được quan sát thấy bằng cách sử dụng giá trung bình được cân nhắc được điều chỉnh. Sau khi nhận được phản hồi về chỉ sử dụng I ^ 3 / 2, nó đã được kiểm tra và thấy rằng kết quả tốt hơn. Sau khi suy nghĩ, điều này có thể là do tần suất khác nhau của các sự kiện. Khi I gần -1 và 1, nó đại diện cho các sự kiện có xác suất thấp. Để điều chỉnh cho các sự kiện có xác suất thấp này, độ chính xác dự đoán các sự kiện tần suất cao bị ảnh hưởng. Do đó, để ưu tiên các sự kiện tần suất cao, một số điều chỉnh đã được thực hiện (những thông số này hoàn toàn là thử nghiệm và sai sót và có ý nghĩa thực tế hạn chế trong giao dịch trực tiếp).
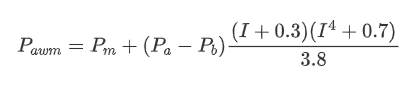
Kết quả đã được cải thiện một chút. Như đã đề cập trong bài viết trước, các chiến lược nên dựa vào nhiều dữ liệu hơn để dự đoán. Với sự sẵn có của nhiều dữ liệu chi tiết hơn và giao dịch lệnh, sự cải thiện đạt được từ việc tập trung vào sổ đơn đặt hàng đã yếu.
Trong [15]:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
Trong [17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
Trong [18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
Ra khỏi [1]:
Giá trị trung bình Lỗi trong giá giữa: 0.0048751924999999845 Lỗi khối lượng lệnh đang chờ trọng số giá trung bình: 0.0048373440193987035 Lỗi của giá trung bình điều chỉnh: 0,004803654771638586 Lỗi của giá trung bình được điều chỉnh: 0.004808216498329721 Lỗi của giá trung bình được điều chỉnh: 0.004794984755260528 Lỗi của giá trung bình được điều chỉnh: 0,0047909595497071375
Hãy xem xét mức độ thứ hai của sự sâu sắc
Chúng ta có thể theo cách tiếp cận từ bài viết trước để kiểm tra các phạm vi khác nhau của một tham số và đo đóng góp của nó vào giá trung bình dựa trên những thay đổi trong giá giao dịch. Tương tự như mức độ độ sâu đầu tiên, khi I tăng, giá giao dịch có nhiều khả năng tăng, cho thấy đóng góp tích cực từ I.
Nếu áp dụng cách tiếp cận tương tự đối với mức độ độ sâu thứ hai, chúng ta thấy rằng mặc dù hiệu ứng nhỏ hơn một chút so với mức độ đầu tiên, nhưng nó vẫn quan trọng và không nên bỏ qua.
Dựa trên những đóng góp khác nhau, chúng tôi gán trọng lượng khác nhau cho ba mức độ tham số mất cân bằng này. Bằng cách kiểm tra các phương pháp tính toán khác nhau, chúng tôi quan sát thấy sự giảm thêm các lỗi dự đoán.
Trong [19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
Ra khỏi [1]:
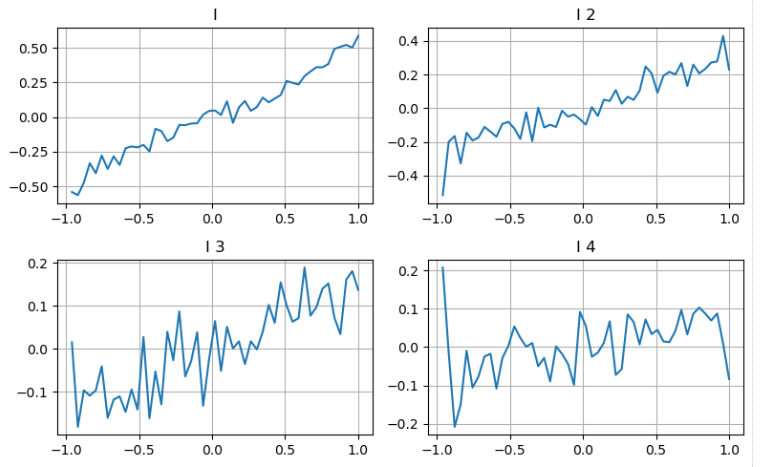
Trong [20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
Trong [21]:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
Ra khỏi [1]:
Lỗi của giá trung bình được điều chỉnh: 0,0047909595497071375 Lỗi của giá trung bình được điều chỉnh: 0,0047884350488318714 Lỗi của giá trung bình được điều chỉnh: 0,0047778319053133735 Lỗi của giá trung bình được điều chỉnh: 0,004773578540592192 Lỗi của giá trung bình được điều chỉnh: 0,004771415189297518
Xem xét dữ liệu giao dịch
Dữ liệu giao dịch trực tiếp phản ánh mức độ của các vị trí dài và ngắn. Sau tất cả, giao dịch liên quan đến tiền thật, trong khi đặt lệnh có chi phí thấp hơn nhiều và thậm chí có thể liên quan đến sự lừa dối có chủ ý. Do đó, khi dự đoán giá giữa, các chiến lược nên tập trung vào dữ liệu giao dịch.
Về hình thức, chúng ta có thể xác định sự mất cân bằng của số lượng đơn đặt hàng trung bình đến là VI, với Vb và Vs đại diện cho số lượng trung bình của các đơn đặt hàng mua và bán trong khoảng thời gian đơn vị, tương ứng.
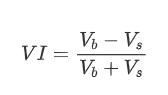
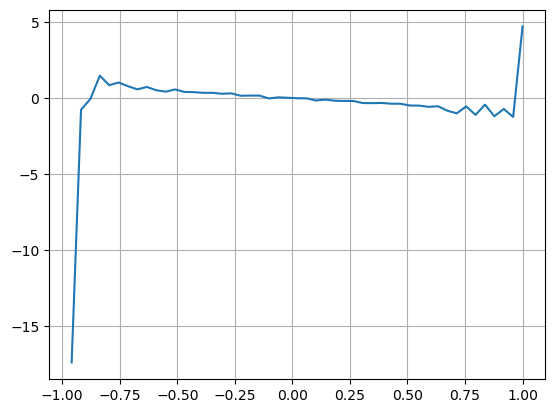
Kết quả cho thấy số lượng đến trong một khoảng thời gian ngắn có tác động đáng kể nhất đến dự đoán thay đổi giá. Khi VI nằm trong khoảng từ 0,1 đến 0,9, nó có mối tương quan tiêu cực với giá, trong khi bên ngoài phạm vi này, nó có mối tương quan tích cực với giá. Điều này cho thấy rằng khi thị trường không cực đoan và chủ yếu dao động, giá có xu hướng quay trở lại mức trung bình. Tuy nhiên, trong điều kiện thị trường cực đoan, chẳng hạn như khi có một số lượng lớn lệnh mua áp đảo các lệnh bán, một xu hướng xuất hiện. Ngay cả khi không xem xét các kịch bản xác suất thấp này, giả định một mối quan hệ tuyến tính tiêu cực giữa xu hướng và VI làm giảm đáng kể sự dự đoán lỗi giá giữa.
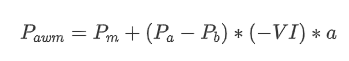
Trong [22]:
alpha=0.1
Trong [23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
Trong [24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
Trong [25]:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
Trong [26]:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
Trong [27]:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
Ra khỏi [1]:
Trong [28]:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
Trong [29]:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
Ra khỏi [1]:
Lỗi của giá trung bình điều chỉnh: 0,0048373440193987035 Lỗi của giá trung bình được điều chỉnh: 0.004629586542840461 Lỗi của giá trung bình được điều chỉnh_10: 0.004401790287167206
Giá trung bình toàn diện
Xem xét rằng cả sự mất cân bằng sổ lệnh và dữ liệu giao dịch đều hữu ích để dự đoán giá giữa, chúng ta có thể kết hợp hai tham số này với nhau. Việc gán trọng lượng trong trường hợp này là tùy ý và không tính đến điều kiện ranh giới. Trong trường hợp cực đoan, giá giữa dự đoán có thể không rơi giữa giá thầu và giá yêu cầu. Tuy nhiên, miễn là lỗi dự đoán có thể được giảm, các chi tiết này không phải là mối quan tâm lớn.
Cuối cùng, lỗi dự đoán được giảm từ 0,00487 xuống còn 0,0043. Tại thời điểm này, chúng tôi sẽ không đi sâu hơn vào chủ đề này. Vẫn còn nhiều khía cạnh cần khám phá khi dự đoán giá giữa, vì nó về cơ bản là dự đoán chính giá. Mọi người được khuyến khích thử cách tiếp cận và kỹ thuật của riêng họ.
Trong [30]:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
Trong [31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
Ra khỏi [1]:
Lỗi của giá trung bình điều chỉnh_11: 0.0043001941412563575
Tóm lại
Bài viết kết hợp dữ liệu độ sâu và dữ liệu giao dịch để cải thiện thêm phương pháp tính toán của giá trung bình. Nó cung cấp một phương pháp để đo độ chính xác và cải thiện độ chính xác của dự đoán thay đổi giá. Nhìn chung, các tham số không nghiêm ngặt và chỉ dành cho tham khảo. Với giá trung bình chính xác hơn, bước tiếp theo là tiến hành kiểm tra lại bằng cách sử dụng giá trung bình trong các ứng dụng thực tế. Phần nội dung này là rộng rãi, vì vậy các bản cập nhật sẽ được tạm dừng trong một khoảng thời gian.
- Đặt rủi ro Delta đối với các tùy chọn Bitcoin bằng đường cong cười
- Những suy nghĩ về các chiến lược giao dịch tần số cao (4)
- Tư duy về chiến lược giao dịch tần số cao (5)
- Tư duy về chiến lược giao dịch tần số cao (4)
- Những suy nghĩ về các chiến lược giao dịch tần số cao (3)
- Tư duy về chiến lược giao dịch tần số cao (3)
- Những suy nghĩ về các chiến lược giao dịch tần số cao (2)
- Tư duy về chiến lược giao dịch tần số cao (2)
- Những suy nghĩ về các chiến lược giao dịch tần số cao (1)
- Tư duy về chiến lược giao dịch tần số cao (1)
- Tài liệu mô tả cấu hình chứng khoán Futu