Mô hình hóa và phân tích biến động Bitcoin dựa trên mô hình ARMA-EGARCH
Tác giả:Lydia., Tạo: 2022-11-15 15:32:43, Cập nhật: 2023-09-14 20:30:52ED, và quá trình đã bị bỏ qua.
Mức độ khớp của phân bố bình thường bình thường không tốt như phân bố t, điều này cũng cho thấy rằng phân bố năng suất có đuôi dày hơn so với phân bố bình thường.
Trong [23]:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
Ra khỏi [23]: Iteration: 1, Func. Count: 10, Neg. LLF: -1917.4262154917305
Kết quả mô hình AR - GARCH
Mô hình trung bình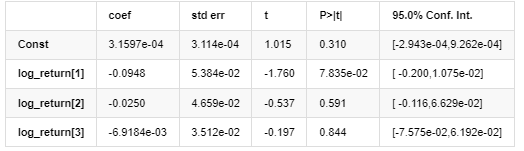
Mô hình biến động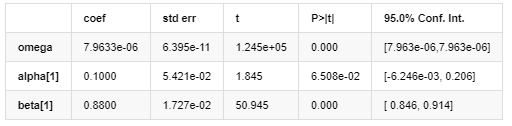
Phân phối
Ước tính sự tương đồng: mạnh mẽ
Mô tả phương trình biến động GARCH theo cơ sở dữ liệu ARCH: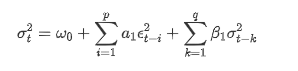
Phương trình hồi quy có điều kiện cho sự biến động có thể được lấy như sau: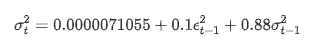
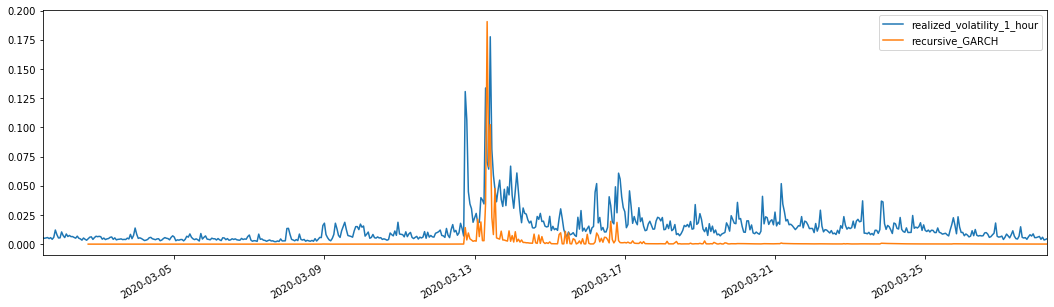
Kết hợp với sự biến động dự đoán phù hợp, so sánh nó với sự biến động thực hiện của mẫu để xem tác dụng.
Trong [26]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Ra khỏi [1]: Lỗi tuyệt đối trung bình (MAE): 0,0128 Lỗi trung bình tuyệt đối (MAPE): 95,6 Sai số trung bình vuông gốc (RMSE): 0,018
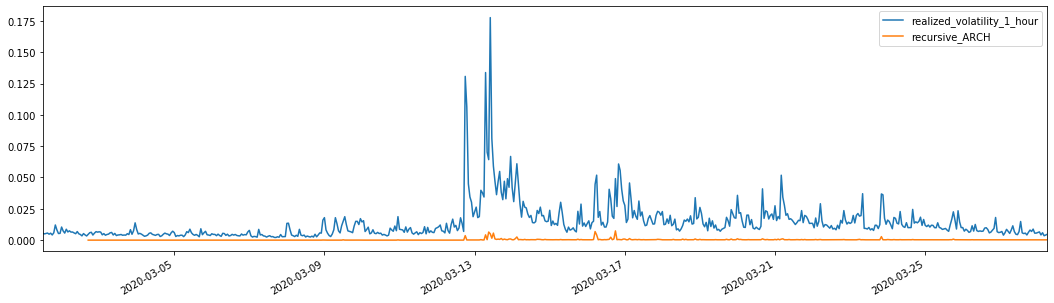
Để so sánh, hãy tạo ARCH như sau:
Trong [27]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Ra khỏi [1]: Lỗi tuyệt đối trung bình (MAE): 0,0136 Lỗi trung bình tuyệt đối (MAPE): 98,1 Sai số trung bình vuông gốc (RMSE): 0.02
7. mô hình EGARCH
Bước tiếp theo là thực hiện mô hình EGARCH
Trong [24]:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
Ra khỏi [1]: Iteration: 1, Func. Count: 11, Neg. LLF: -1966.610328148909
Kết quả mô hình AR - EGARCH
Mô hình trung bình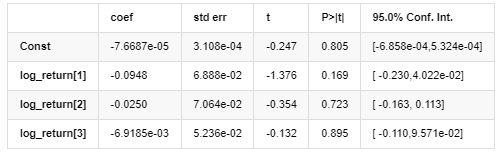
Mô hình biến động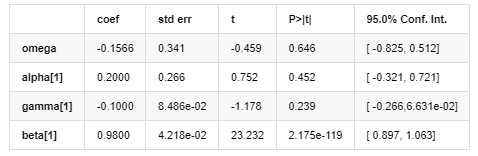
Phân phối
Ước tính sự tương đồng: mạnh mẽ
Phương trình biến động EGARCH được cung cấp bởi thư viện ARCH được mô tả như sau: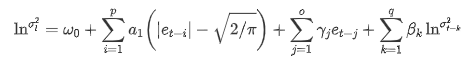
thay thế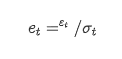
Phương trình hồi quy có điều kiện của biến động có thể được lấy như sau: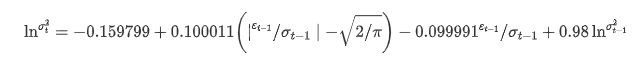
Trong số đó, hệ số ước tính của thuật ngữ đối xứng γ thấp hơn khoảng thời gian tin cậy, cho thấy có một sự biến động đáng kể trong tỷ lệ lợi nhuận Bitcoin.
Kết hợp với sự biến động dự đoán phù hợp, các kết quả được so sánh với sự biến động thực hiện của mẫu như sau:
Trong [28]:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
Ra ngoài[28]: Lỗi tuyệt đối trung bình (MAE): 0,0201 Lỗi trung bình tuyệt đối (MAPE): 122 Sai số trung bình vuông gốc (RMSE): 0,0279
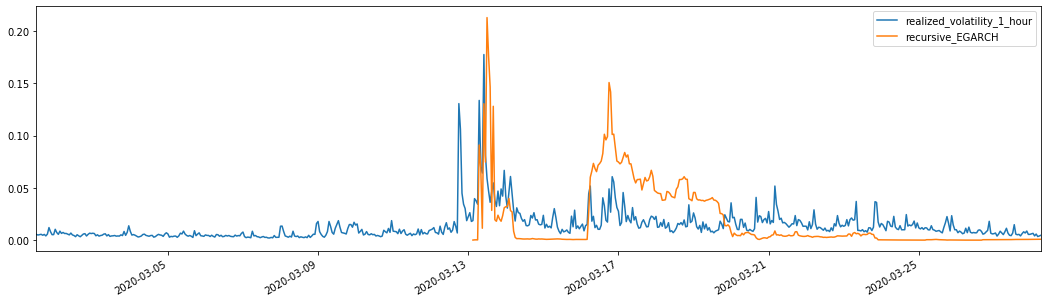
Có thể thấy rằng EGARCH nhạy cảm hơn với biến động và phù hợp với biến động hơn ARCH và GARCH.
8. Đánh giá dự đoán biến động
Dữ liệu hàng giờ được chọn dựa trên mẫu và bước tiếp theo là dự đoán một giờ trước. Chúng tôi chọn biến động dự đoán trong 10 giờ đầu tiên của ba mô hình, với RV là biến động chuẩn. Giá trị lỗi so sánh là như sau:
Trong [29]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
Ra khỏi [1]: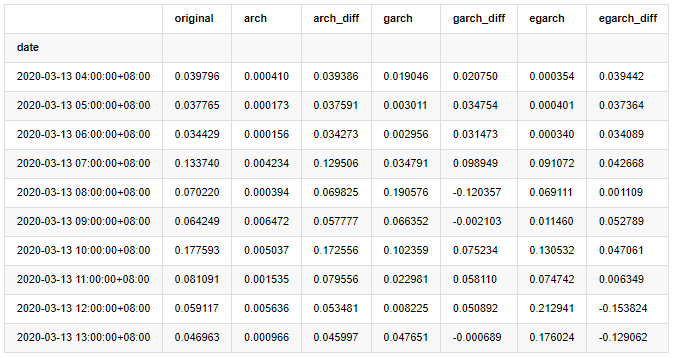
Trong [30]:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
Rút ra[30]: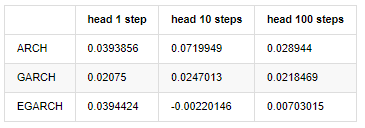
Một số thử nghiệm đã được thực hiện, trong kết quả dự đoán của giờ đầu tiên, xác suất của lỗi nhỏ nhất của EGARCH là tương đối lớn, nhưng sự khác biệt tổng thể không đặc biệt rõ ràng; Có một số sự khác biệt rõ ràng trong hiệu ứng dự đoán ngắn hạn; EGARCH có khả năng dự đoán nổi bật nhất trong dự đoán dài hạn
Trong [31]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
Ra khỏi [1]: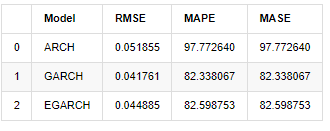
Về các chỉ số, GARCH và EGARCH có một số cải thiện so với ARCH, nhưng sự khác biệt không đặc biệt rõ ràng. Sau khi lựa chọn và xác minh khoảng thời gian đa mẫu, EGARCH sẽ có hiệu suất tốt hơn, chủ yếu là bởi vì EGARCH giải thích sự dị tính của các mẫu tốt.
9. Kết luận
Từ phân tích đơn giản ở trên, có thể thấy rằng tỷ lệ lợi nhuận logaritm của Bitcoin không phù hợp với sự phân bố bình thường, được đặc trưng bởi đuôi mỡ dày, và sự biến động có hiệu ứng tổng hợp và đòn bẩy, trong khi cho thấy sự dị biệt có điều kiện rõ ràng.
Trong việc dự đoán và đánh giá tỷ lệ lợi nhuận logaritm, khả năng dự đoán tĩnh trong mẫu của mô hình ARMA tốt hơn đáng kể so với phương pháp động, điều này cho thấy phương pháp lăn rõ ràng tốt hơn phương pháp lặp lại và có thể tránh các vấn đề quá phù hợp và khuếch đại lỗi.
Ngoài ra, khi đối phó với hiện tượng đuôi dày của Bitcoin, tức là sự phân bố đuôi dày của lợi nhuận, người ta thấy rằng sự phân bố GED (lỗi tổng quát) tốt hơn so với sự phân bố t và phân bố bình thường đáng kể, có thể cải thiện độ chính xác đo lường rủi ro đuôi. Đồng thời, EGARCH có nhiều lợi thế hơn trong việc dự đoán biến động dài hạn, điều này giải thích tốt tính bất đồng của mẫu. hệ số ước tính đối xứng trong sự phù hợp mô hình nhỏ hơn khoảng thời gian tin cậy, cho thấy có một sự biến động đáng kể
Toàn bộ quá trình mô hình đầy những giả định táo bạo, và không có xác định nhất quán dựa trên tính hợp lệ, vì vậy chúng ta chỉ có thể xác minh một số hiện tượng một cách cẩn thận. Lịch sử chỉ có thể hỗ trợ xác suất dự đoán tương lai trong thống kê, nhưng tỷ lệ chính xác và chi phí vẫn còn một hành trình khó khăn dài.
So với các thị trường truyền thống, việc có sẵn dữ liệu tần số cao của Bitcoin dễ dàng hơn.
Tuy nhiên, những điều trên chỉ giới hạn trong lý thuyết. Dữ liệu tần số cao hơn thực sự có thể cung cấp phân tích chính xác hơn về hành vi của các nhà giao dịch. Nó không chỉ có thể cung cấp các bài kiểm tra đáng tin cậy hơn cho các mô hình lý thuyết tài chính, mà còn cung cấp thông tin ra quyết định phong phú hơn cho các nhà giao dịch, thậm chí hỗ trợ dự đoán luồng thông tin và luồng vốn, và hỗ trợ thiết kế các chiến lược giao dịch định lượng chính xác hơn. Tuy nhiên, thị trường Bitcoin rất biến động đến nỗi dữ liệu lịch sử quá dài không thể phù hợp với thông tin ra quyết định hiệu quả, vì vậy dữ liệu tần số cao chắc chắn sẽ mang lại lợi thế thị trường lớn hơn cho các nhà đầu tư tiền kỹ thuật số.
Cuối cùng, nếu bạn nghĩ rằng nội dung trên là hữu ích, bạn cũng có thể cung cấp một chút BTC để mua cho tôi một tách Cola.
- Xác định số lượng phân tích cơ bản trong thị trường tiền điện tử: Hãy để dữ liệu nói cho chính nó!
- Các nghiên cứu định lượng cơ bản của vòng đồng tiền - đừng tin vào những giáo viên mờ nhạt, nói khách quan về dữ liệu!
- Một công cụ thiết yếu trong lĩnh vực giao dịch định lượng - nhà phát minh mô-đun khám phá dữ liệu định lượng
- Kiểm soát mọi thứ - giới thiệu về FMZ Phiên bản mới của Terminal giao dịch (với mã nguồn TRB Arbitrage)
- Có tất cả các thông tin về FMZ phiên bản mới của giao dịch đầu cuối (được thêm mã nguồn TRB)
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (II)
- Làm thế nào để khai thác robot bán hàng không có não với một chiến lược tần số cao trong 80 dòng mã
- FMZ định lượng: Phân tích các trường hợp thiết kế nhu cầu phổ biến của thị trường tiền điện tử (II)
- Cách khai thác robot vô trí tuệ để bán bằng chiến lược tần số cao 80 dòng mã
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (I)
- FMZ định lượng: Các nhu cầu phổ biến của thị trường tiền điện tử