নিউরাল নেটওয়ার্ক এবং ডিজিটাল মুদ্রা পরিমাণগত ট্রেডিং সিরিজ (1) - LSTM বিটকয়েনের মূল্য পূর্বাভাস দেয়
লেখক:লিডিয়া, তৈরিঃ ২০২৩-০১-১২ 13:55:01, আপডেটঃ ২০২৩-০৯-২০ 10:06:28
নিউরাল নেটওয়ার্ক এবং ডিজিটাল মুদ্রা পরিমাণগত ট্রেডিং সিরিজ (1) - LSTM বিটকয়েনের মূল্য পূর্বাভাস দেয়
১. সংক্ষিপ্ত ভূমিকা
গভীর নিউরাল নেটওয়ার্ক সাম্প্রতিক বছরগুলিতে আরও বেশি জনপ্রিয় হয়ে উঠেছে। এটি অনেক ক্ষেত্রে অতীতে সমাধান করা যায়নি এমন সমস্যাগুলি সমাধান করেছে এবং এর শক্তিশালী ক্ষমতা প্রদর্শন করেছে। সময় সিরিজের পূর্বাভাসে, সাধারণভাবে ব্যবহৃত নিউরাল নেটওয়ার্ক মূল্যটি আরএনএন, কারণ এটিতে কেবল বর্তমান ডেটা ইনপুটই নয়, বরং historicalতিহাসিক ডেটা ইনপুটও রয়েছে। অবশ্যই, যখন আমরা আরএনএন দামের পূর্বাভাস সম্পর্কে কথা বলি, আমরা প্রায়শই আরএনএনগুলির মধ্যে একটি সম্পর্কে কথা বলিঃ এলএসটিএম। এই কাগজটি পাইটর্চের ভিত্তিতে বিটকয়েনের দাম পূর্বাভাসের জন্য একটি মডেল তৈরি করবে। যদিও ইন্টারনেটে প্রচুর প্রাসঙ্গিক তথ্য রয়েছে তবে এটি এখনও পর্যাপ্ত পরিমাণে নয় এবং পাইটর্চ ব্যবহারকারী তুলনামূলকভাবে অল্প লোক রয়েছে। এখনও একটি নিবন্ধ লিখতে হবে। চূড়ান্ত ফলাফলটি হ'ল বিটকয়েনের পরবর্তী উদ্বোধনী মূল্য, বন্ধের মূল্য, সর্বোচ্চ মূল্য, সর্বনিম্ন মূল্য এবং বন্ধের পরিমাণের পূর্বাভাস দেওয়া। আমার ব্যক্তিগত জ্ঞান এবং আপনার নিউরাল নেটওয়ার্কগুলির সমালোচনা এবং সংশোধন এই টিউটোরিয়ালটি FMZ Quant Trading প্ল্যাটফর্ম দ্বারা তৈরি করা হয়েছে (www.fmz.com) । যোগাযোগের জন্য QQ গ্রুপে যোগদানের জন্য স্বাগতমঃ 863946592।
২. তথ্য এবং রেফারেন্স
বিটকয়েনের মূল্যের তথ্য FMZ Quant Trading প্ল্যাটফর্ম থেকে সংগ্রহ করা হয়েছে:https://www.quantinfo.com/Tools/View/4.html.. দামের পূর্বাভাসের একটি সম্পর্কিত উদাহরণঃhttps://yq.aliyun.com/articles/538484.. RNN মডেলের একটি বিস্তারিত ভূমিকাঃhttps://zhuanlan.zhihu.com/p/27485750. RNN এর ইনপুট এবং আউটপুট বোঝাঃhttps://www.zhihu.com/question/41949741/answer/318771336.. পাইটোর্চ সম্পর্কে: সরকারি নথিপত্র:https://pytorch.org/docsঅন্যান্য তথ্যের জন্য, আপনি নিজেরাই অনুসন্ধান করতে পারেন। উপরন্তু, এই নিবন্ধটি পড়ার জন্য আপনার কিছু পূর্বের জ্ঞান দরকার, যেমন পান্ডা / পাইথন / ডেটা প্রসেসিং, তবে আপনি না থাকলে এটি গুরুত্বপূর্ণ নয়।
৩. পাইটোর্চ এলএসটিএম মডেলের পরামিতি
LSTM এর পরামিতিঃ
প্রথমবার যখন আমি নথিতে এই ঘন প্যারামিটারগুলো দেখলাম, তখন আমার প্রতিক্রিয়া ছিল: এটা কি?
আমি আস্তে আস্তে পড়ার সাথে সাথে অবশেষে বুঝতে পারলাম।

input_size: ভেক্টর x এর বৈশিষ্ট্যযুক্ত আকার ইনপুট করুন। যদি বন্ধের দাম বন্ধের দাম দ্বারা পূর্বাভাস দেওয়া হয়, তাহলে ইনপুট_সাইজ=1; যদি বন্ধের দাম উচ্চ খোলার এবং নিম্ন বন্ধের দ্বারা পূর্বাভাস দেওয়া হয়, তাহলে ইনপুট_সাইজ=4.hidden_size: অন্তর্নিহিত স্তর আকারnum_layers: RNN এর স্তর সংখ্যা।batch_first: যদি সত্য হয়, প্রথম ইনপুট মাত্রা batch_size হয়, যা খুব বিভ্রান্তিকর, এবং এটি বিস্তারিতভাবে নীচে বর্ণনা করা হবে।
ডাটা প্যারামিটার লিখুনঃ
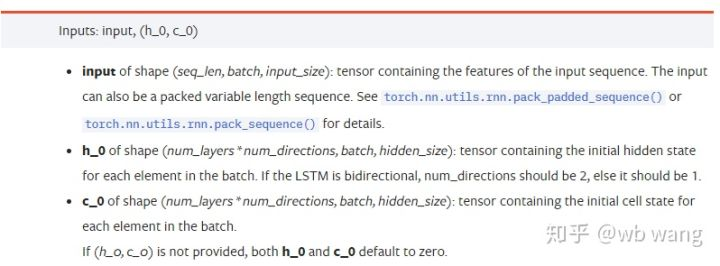
input: নির্দিষ্ট ইনপুট ডেটা একটি ত্রিমাত্রিক টেনসর, এবং নির্দিষ্ট আকৃতি হলঃ (seq_len, ব্যাচ, ইনপুট_সাইজ) । যেখানে, seq_len ক্রমের দৈর্ঘ্যকে বোঝায়, অর্থাৎ, LSTM কে ঐতিহাসিক ডেটা বিবেচনা করতে কতক্ষণ প্রয়োজন। মনে রাখবেন যে এটি কেবলমাত্র ডেটা ফর্ম্যাটকে বোঝায়, LSTM এর অভ্যন্তরীণ কাঠামো নয়। একই LSTM মডেলটি বিভিন্ন seqs_lenh_0: প্রাথমিক লুকানো অবস্থা, আকৃতি (num_layers * num_directions, batch, hidden_size), যদি এটি একটি দ্বি-মুখী নেটওয়ার্ক হয়, num_directions=2.c_0: কোষের প্রাথমিক অবস্থা, উপরের মত আকৃতি, অনির্দিষ্ট হতে পারে।
আউটপুট প্যারামিটারঃ
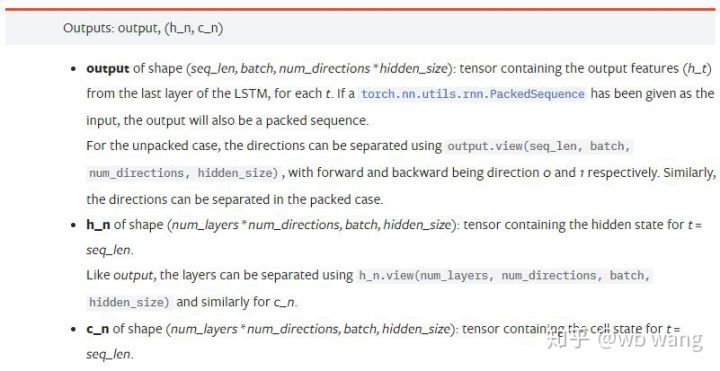
output: আউটপুট এর আকৃতি (seq_len, ব্যাচ, num_directions * hidden_size), এটি মডেল প্যারামিটার batch_first এর সাথে সম্পর্কিত।h_n: t = seq_len এর মুহুর্তে h অবস্থা, h_0 এর সাথে একই আকৃতির।c_n: t = seq_len এর মুহুর্তে c অবস্থা, c_0 এর সাথে একই আকৃতির।
4. LSTM ইনপুট এবং আউটপুট একটি সহজ উদাহরণ
প্রথমে প্রয়োজনীয় প্যাকেজ আমদানি করুন
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
LSTM মডেল সংজ্ঞায়িত করুন
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
ইনপুট ডেটা প্রস্তুত করুন
x = torch.randn(3,4,5)
# The value of x is:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
x এর আকৃতি হচ্ছে (3,4,5), কারণ আমরা সংজ্ঞায়িত করেছিbatch_first=Trueপূর্বে, এই সময়ে batch_size এর আকার 3, sqe_len 4, input_size 5, X [0] প্রথম ব্যাচের প্রতিনিধিত্ব করে।
যদি batch_first সংজ্ঞায়িত না করা হয়, তাহলে ডিফল্ট মানটি False হয়, তাহলে এই সময়ে ডেটা উপস্থাপনা সম্পূর্ণ ভিন্ন। ব্যাচের আকার 4, sqe_len 3, input_size 5. এই সময়ে, x [0] t=0 হলে সমস্ত ব্যাচের ডেটা উপস্থাপন করে, এবং তাই। আমি মনে করি এই সেটিংটি স্বজ্ঞাত নয়, তাই আমি প্যারামিটার যোগ করেছিbatch_first=True.
এই দুইয়ের মধ্যে ডেটা রূপান্তরও খুব সুবিধাজনকঃx.permute (1,0,2)
ইনপুট এবং আউটপুট
LSTM এর ইনপুট এবং আউটপুটের আকৃতি খুব বিভ্রান্তিকর, এবং নিম্নলিখিত চিত্রটি আমাদের বুঝতে সাহায্য করতে পারেঃ
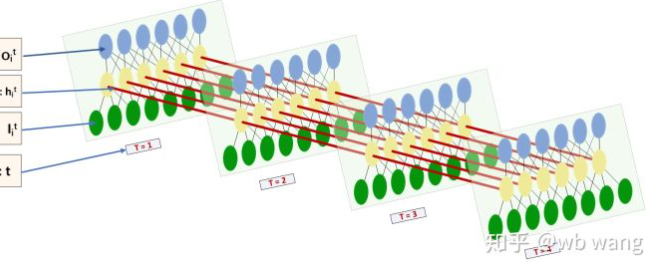
থেকেঃhttps://www.zhihu.com/question/41949741/answer/318771336.
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) # Thinking about it, what would be the size of the output if batch_first=False?
print(hn.size())
print(cn.size())
# result
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
আউটপুট ফলাফল পর্যবেক্ষণ করুন, যা পূর্ববর্তী পরামিতি ব্যাখ্যা সঙ্গে সামঞ্জস্যপূর্ণ। মনে রাখবেন যে hn.size() এর দ্বিতীয় মান 3, যা batch_size এর আকারের সাথে সামঞ্জস্যপূর্ণ, যার অর্থ হল যে মধ্যবর্তী অবস্থাটি hn এ সংরক্ষণ করা হয় না, শুধুমাত্র শেষ ধাপটি সংরক্ষণ করা হয়। যেহেতু আমাদের এলএসটিএম নেটওয়ার্কের দুটি স্তর রয়েছে, আসলে hn এর শেষ স্তরের আউটপুটটি আউটপুটের মান। আউটপুটের আকারটি [3, 4, 10], যা t = 0,1,2,3 এর সমস্ত সময়ে ফলাফলগুলি সংরক্ষণ করে, সুতরাংঃ
hn[-1][0] == output[0][-1] # The output of the first batch at the last level of hn is equal to the output of the first batch at t=3.
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
৫. বিটকয়েন মার্কেট ডেটা প্রস্তুত করুন
অনেক আগে বলা হয়েছে, যা শুধুমাত্র একটি প্রিলেডুয়েড। LSTM এর ইনপুট এবং আউটপুট বুঝতে খুব গুরুত্বপূর্ণ। অন্যথায়, ইন্টারনেট থেকে এলোমেলোভাবে কিছু কোড বের করে ভুল করা সহজ। সময় সিরিজের মধ্যে LSTM এর শক্তিশালী ক্ষমতার কারণে, এমনকি যদি মডেলটি ভুল হয় তবে শেষ পর্যন্ত ভাল ফলাফল পাওয়া যায়।
তথ্য সংগ্রহ
বিটফিনেক্স এক্সচেঞ্জে বিটিসি_ইউএসডি ট্রেডিং জোড়ার বাজার তথ্য ব্যবহার করা হয়।
import requests
import json
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1562658565')
data = resp.json()
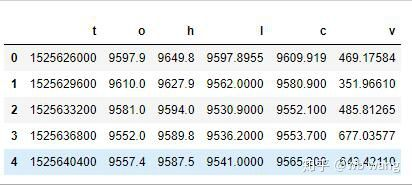
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
তথ্যের বিন্যাস নিম্নরূপঃ
ডেটা প্রিপ্রসেসিং
df.index = df['t'] # index is set to timestamp
df = (df-df.mean())/df.std() # The standardization of the data, otherwise the loss of the model will be very large, which is not conducive to convergence.
df['n'] = df['c'].shift(-1) # n is the closing price of the next period, which is our forecast target.
df = df.dropna()
df = df.astype(np.float32) # Change the data format to fit pytorch.
ডাটা স্ট্যান্ডার্ডাইজেশনের পদ্ধতিটি খুবই রুক্ষ, এবং কিছু সমস্যা হবে। শুধু প্রদর্শনীর জন্য, আপনি ডাটা স্ট্যান্ডার্ডাইজেশন যেমন রিটার্ন রেট ব্যবহার করতে পারেন।
প্রশিক্ষণ তথ্য প্রস্তুত করুন
seq_len = 10 # Input 10 periods of data
train_size = 800 # Training set batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) # The change in shape, -1 represents the value that will be calculated automatically.
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
train_x এবং train_y এর চূড়ান্ত আকারগুলি হলঃ torch.Size ([800, 10, 5]), torch.Size ([800, 10, 1]). যেহেতু আমাদের মডেলটি 10 টি সময়ের তথ্যের উপর ভিত্তি করে পরবর্তী সময়ের বন্ধের মূল্য পূর্বাভাস দেয়, তাই তত্ত্বগতভাবে 800 টি ব্যাচ রয়েছে, যতক্ষণ না 800 টি পূর্বাভাস বন্ধের দাম রয়েছে। তবে প্রতিটি ব্যাচে ট্রেন_ওয়াইতে 10 টি ডেটা রয়েছে। আসলে, প্রতিটি ব্যাচের পূর্বাভাসের মধ্যবর্তী ফলাফল সংরক্ষিত থাকে। চূড়ান্ত ক্ষতি গণনা করার সময়, সমস্ত 10 টি পূর্বাভাসের ফলাফল বিবেচনা করা যেতে পারে এবং train_y এর প্রকৃত মানের সাথে তুলনা করা যেতে পারে। তাত্ত্বিকভাবে, আমরা কেবলমাত্র শেষ পূর্বাভাসের ফলাফলের ক্ষতি গণনা করতে পারি। কারণ LSTM মডেলটিতে আসলে seq_lenful পরামিতি নেই, তাই মডেলটি বিভিন্ন দৈর্ঘ্যে প্রয়োগ করা যেতে পারে, এবং মধ্যবর্তী ফলাফলের পূর্বাভাসও অর্থবহ, তাই আমি সংযুক্ত এবং হার গণনা করতে পছন্দ করি।
মনে রাখবেন যে প্রশিক্ষণ তথ্য প্রস্তুত করার সময়, উইন্ডোর আন্দোলন ঝাঁপিয়ে পড়েছে, এবং ইতিমধ্যে ব্যবহৃত ডেটা আর ব্যবহার করা হয় না। অবশ্যই, উইন্ডোটি একের পর এক সরানো যেতে পারে, যাতে প্রাপ্ত প্রশিক্ষণ সেটটি অনেক বড় হয়। তবে, আমি অনুভব করেছি যে সংলগ্ন ব্যাচের ডেটা খুব পুনরাবৃত্তি ছিল, তাই আমি বর্তমান পদ্ধতিটি গ্রহণ করেছি।
৬. এলএসটিএম মডেল তৈরি করুন
চূড়ান্ত মডেলটি নিম্নরূপ নির্মিত হয়েছে, এতে একটি দ্বি-স্তরীয় LSTM এবং একটি লিনিয়ার স্তর রয়েছে।
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # Linear layer, output the result of LSTM into a value.
def forward(self, x):
x, _ = self.rnn(x) # If you don't understand the change of data dimension in forward propagation, you can debug it separately.
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size is 5, which represents the high opening and low closing and trading volume. The implicit layer is 10.
৭. মডেলকে প্রশিক্ষণ দেওয়া শুরু করুন
অবশেষে আমরা প্রশিক্ষণ শুরু, কোড নিম্নরূপঃ
criterion = nn.MSELoss() # A simple mean square error loss function is used.
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # Optimize function, lr is adjustable.
for epoch in range(600): # Because of the speed, there are more epochs here.
out = net(train_x) # Due to the small amount of data, the full amount of data is directly used for calculation.
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # Reverse propagation losses
optimizer.step() # Update parameters
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
প্রশিক্ষণের ফলাফল নিম্নরূপঃ
৮. মডেল মূল্যায়ন
মডেলের পূর্বাভাস মানঃ
p = net(torch.from_numpy(data_X))[:,-1,0] # Only the last predicted value is taken here for comparison.
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
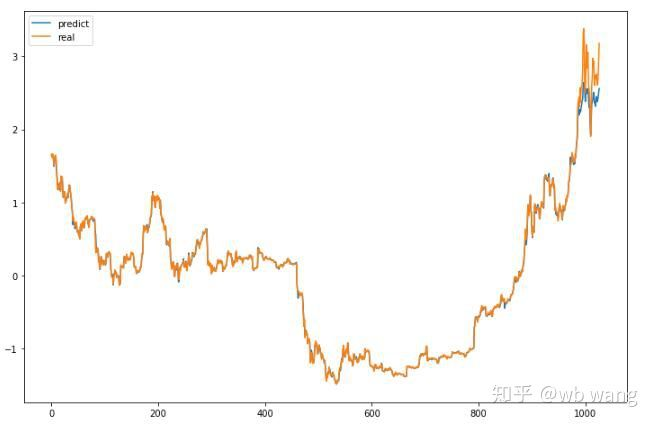
এটি চার্ট থেকে দেখা যায় যে প্রশিক্ষণের ডেটা (৮০০ এর আগে) খুব ধারাবাহিক, তবে বিটকয়েনের দাম পরবর্তী সময়ে বেড়েছে। মডেলটি এই ডেটা দেখেনি, তাই পূর্বাভাসটি অপর্যাপ্ত। এটিও দেখায় যে ডেটা স্ট্যান্ডার্ডাইজেশনে সমস্যা রয়েছে। যদিও পূর্বাভাস মূল্য সঠিক নাও হতে পারে, ক্রমবর্ধমান এবং হ্রাসের পূর্বাভাসের সঠিকতা কত? পূর্বাভাস তথ্য একটি সেগমেন্ট নিতে দেখুনঃ
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
ফলস্বরূপ, উত্থান ও পতনের পূর্বাভাসের নির্ভুলতার হার ৮১.৪% পৌঁছেছে, যা আমার প্রত্যাশা অতিক্রম করেছে। আমি জানি না কিছু ভুল আছে কিনা।
অবশ্যই, এই মডেল বাস্তব বট প্রযোজ্য নয়, কিন্তু এটি সহজ এবং সহজেই বোঝা যায়. শুধু এটি দিয়ে শুরু করুন. পরবর্তী, ডিজিটাল মুদ্রা quantification মধ্যে নিউরাল নেটওয়ার্ক অ্যাপ্লিকেশন আরো ভূমিকা কোর্স হবে.
- ক্রিপ্টোকারেন্সি মার্কেটে মৌলিক বিশ্লেষণের পরিমাণ নির্ধারণঃ তথ্য নিজের জন্য কথা বলতে দিন!
- মুদ্রাচক্রের মৌলিক পরিমাণগত গবেষণা - এখন আর সব ধরনের ধাঁধাবাদী শিক্ষকদের বিশ্বাস করা বন্ধ করুন, তথ্য অবজেক্টিভভাবে কথা বলছে!
- কোয়ালিফাইড লেনদেনের জন্য একটি অপরিহার্য সরঞ্জাম - উদ্ভাবক কোয়ালিফাইড ডেটা এক্সপ্লোরার মডিউল
- সবকিছু আয়ত্ত করা - এফএমজেড ট্রেডিং টার্মিনালের নতুন সংস্করণে ভূমিকা (টিআরবি আর্বিট্রেজ সোর্স কোড সহ)
- এফএমজেডের নতুন ট্রেডিং টার্মিনালের সাথে পরিচিত হোন (ট্র্যাফিক কোড সহ)
- FMZ Quant: ক্রিপ্টোকারেন্সি মার্কেটে সাধারণ প্রয়োজনীয়তা ডিজাইন উদাহরণগুলির বিশ্লেষণ (II)
- কিভাবে 80 লাইন কোডে একটি উচ্চ ফ্রিকোয়েন্সি কৌশল সঙ্গে মস্তিষ্কহীন বিক্রয় বট শোষণ
- এফএমজেড পরিমাণঃ ক্রিপ্টোকারেন্সি বাজারের সাধারণ চাহিদা ডিজাইন উদাহরণ বিশ্লেষণ (২)
- ৮০ লাইন কোডের উচ্চ-প্রবাহের কৌশল ব্যবহার করে মস্তিষ্কবিহীন রোবটকে কীভাবে বিক্রি করা যায়
- FMZ Quant: ক্রিপ্টোকারেন্সি মার্কেটে সাধারণ প্রয়োজনীয়তা ডিজাইন উদাহরণগুলির বিশ্লেষণ (I)
- এফএমজেড কোয়াটিফিকেশনঃ ক্রিপ্টোকারেন্সি মার্কেটের সাধারণ চাহিদা ডিজাইন উদাহরণ বিশ্লেষণ