Vergleich von 8 Algorithmen für maschinelles Lernen
 0
6946
0
6946
Vergleich von 8 Algorithmen für maschinelles Lernen
In diesem Artikel werden vor allem die folgenden Anpassungs-Szenarien für gängige Algorithmen und ihre Vor- und Nachteile beschrieben.
Es gibt so viele Algorithmen für das Maschinelle Lernen, in den Bereichen Klassifizierung, Regression, Aggregation, Empfehlung, Bilderkennung und so weiter, dass es wirklich nicht einfach ist, einen geeigneten Algorithmus zu finden, also experimentieren wir in der Praxis in der Regel mit inspiratorischen Lernmethoden.
Wenn wir anfangen, wählen wir die Algorithmen, mit denen wir uns einverstanden erklären, wie SVM, GBDT, Adaboost, aber jetzt ist Deep Learning in der Hölle und Neural Networks sind eine gute Wahl.
Wenn Sie sich für die Genauigkeit interessieren, ist es am besten, die einzelnen Algorithmen durch Cross-Validation zu testen, zu vergleichen, dann die Parameter anzupassen, um sicherzustellen, dass jeder Algorithmus die optimale Lösung erreicht, und schließlich die beste zu wählen.
Aber wenn Sie nur nach einem Algorithmus suchen, der gut genug ist, um Ihr Problem zu lösen, oder hier sind einige Tipps, die Sie verwenden können, analysieren Sie die Vor- und Nachteile der einzelnen Algorithmen, die es uns leichter machen, sie zu wählen.
- ## Abweichungen und Unterschiede
In der Statistik wird ein Modell in Bezug auf seine Qualität und Qualität anhand von Abweichungen und Differenzen gemessen, also lassen Sie uns die Abweichungen und Differenzen verallgemeinern:
Abweichung: Beschreibt die Abweichung zwischen dem erwarteten E und dem tatsächlichen Y des prognostizierten (bewerteten) Wertes. Je größer die Abweichung, desto weiter entfernt ist sie von den tatsächlichen Daten.
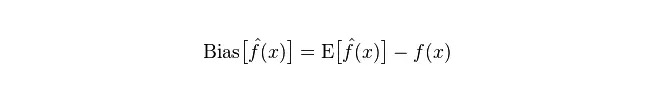
Die Differenz, die den Bereich der Veränderung des prognostizierten Wertes P beschreibt, ist die Differenz des prognostizierten Wertes, d. h. die Entfernung von seinem erwarteten Wert E. Je größer die Differenz, desto mehr verteilt sich die Daten.
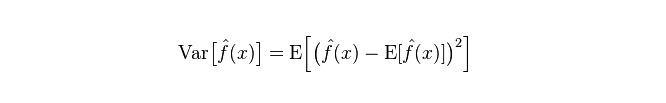
Der tatsächliche Modellfehler ist die Summe der beiden, wie folgt dargestellt:
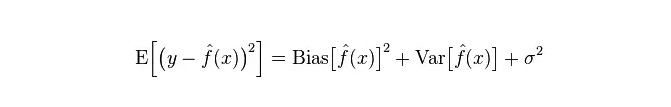
Wenn es sich um eine kleine Trainingsgruppe handelt, hat ein Klassifikator mit hoher Abweichung/niedriger Abweichung (z. B. naive Bayesian NB) einen großen Vorteil gegenüber einer Klassifizierung mit niedriger Abweichung/hoher Abweichung (z. B. KNN), da die letztere überfittet.
Aber mit zunehmender Anzahl an Trainingsätzen, mit der die Vorhersagefähigkeit des Modells für die ursprünglichen Daten verbessert wird, wird die Abweichung geringer, und die Low-Deviance/High-Deviance-Klassifikatoren zeigen allmählich ihren Vorteil (weil sie einen niedrigeren Annäherungsfehler haben), und die High-Deviance-Klassifikatoren sind zu diesem Zeitpunkt nicht mehr ausreichend, um ein genaues Modell zu liefern.
Natürlich kann man das auch als einen Unterschied zwischen dem Erzeugungsmodell (NB) und dem Beurteilungsmodell (KNN) ansehen.
- ## Warum ist ein naiver Bayesianer hoch- oder niedrigdifferenziert?
Das ist die Antwort auf die Frage:
Angenommen, Sie kennen die Beziehung zwischen Trainings- und Testsätzen. Einfach gesagt, wir lernen ein Modell in der Trainings- und Testsammlung, und wenn wir die Testsätze haben, müssen wir die Fehlerquote der Testsätze messen.
Aber oft können wir nur annehmen, dass die Testsätze und die Trainingssätze in derselben Datenverteilung sind, aber wir bekommen keine echten Testdaten. Wie kann man dann die Testfehlerrate messen, wenn man nur die Trainingsfehlerrate sieht?
Da es nur wenige Trainingsproben gibt (zumindest nicht genug), ist das Modell, das durch Training gesammelt wird, nicht immer richtig. Selbst wenn es 100% richtig auf dem Trainingsset ist, kann dies nicht bedeuten, dass es eine echte Datenverteilung zeichnet. Es ist unser Ziel, die wahre Datenverteilung zu zeichnen, und nicht nur die begrenzten Datenpunkte des Trainingssets.
In der Praxis haben die Trainingsproben oft auch eine gewisse Geräuschfehler, so dass ein sehr komplexes Modell, das sich zu sehr um die Perfektion des Trainingssets bemüht, dazu führt, dass das Modell alle Fehler im Trainingsset als wahre Datenverteilungsmerkmale betrachtet, was zu einer falschen Datenverteilungsschätzung führt.
In diesem Fall ist die Fehlerquote bei echten Testsätzen sehr hoch (das Phänomen wird als Anpassung bezeichnet). Es ist jedoch auch nicht möglich, ein zu einfaches Modell zu verwenden, da das Modell bei einer komplizierteren Datenverteilung nicht ausreicht, um die Datenverteilung darzustellen (was sich auch in der Trainingsgruppe als sehr hohe Fehlerquote zeigt, die Phänomen ist weniger passend).
Über-übereinstimmend bedeutet, dass das Modell komplizierter ist als die tatsächliche Datenverteilung, und unter-übereinstimmend bedeutet, dass das Modell einfacher ist als die tatsächliche Datenverteilung.
Wenn man in einem statistischen Lernrahmen die Komplexität eines Modells darstellt, dann gibt es die Ansicht, dass “Error” = “Bias + Variance” ist. Der “Error” kann als die Prognosefehlerrate des Modells verstanden werden. Er besteht aus zwei Teilen: der ungenauen Schätzung, die durch die zu einfache Modellentwicklung (Bias) verursacht wird, und der größeren Unsicherheit, die durch die zu komplexe Modellentwicklung (Variance) verursacht wird.
So ist es leicht, einen simplen Bayes zu analysieren. Seine einfache Annahme, dass die einzelnen Daten unabhängig sind, ist ein stark vereinfachtes Modell. Für ein solches einfaches Modell ist der Bias in den meisten Fällen größer als der Variance, d. h. die Abweichung ist hoch, die Abweichung ist niedrig.
In der Praxis müssen wir bei der Auswahl der Modelle das Verhältnis von Bias und Variance ausgleichen, um den Fehler so gering wie möglich zu halten, also über- und unter-fitting ausgleichen.
Die Abweichungen und Quadratdifferenzen in Bezug auf die Komplexität des Modells werden in der folgenden Abbildung deutlich:
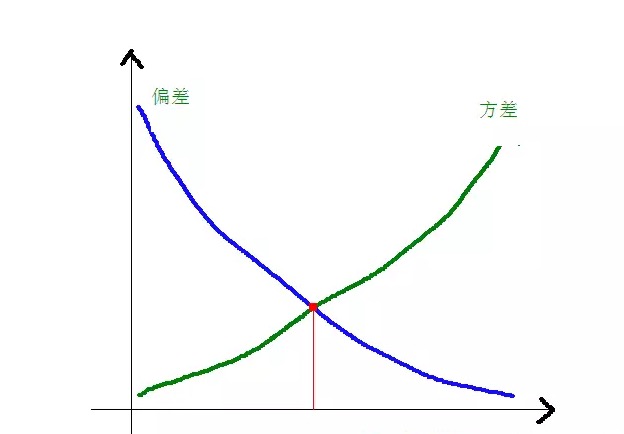
Wenn die Modellkomplexität steigt, wird die Abweichung kleiner und die Abweichung größer.
-
Allgemeine Vor- und Nachteile von Algorithmen
- ### 1. Naughty Bayes
Einfacher Bayesianismus gehört zu den erzeugenden Modellen (in Bezug auf die erzeugenden Modelle und die diskretionären Modelle, hauptsächlich bezüglich der Frage, ob eine gemeinsame Verteilung verlangt wird) und ist sehr einfach, man macht einfach eine Menge Berechnungen.
Wenn die Bedingungsunabhängigkeitsannahme ((eine strengere Bedingung)) gegeben ist, wird der naive Bayesianer schneller konvergieren als ein Determinierungsmodell wie die logische Regression, so dass weniger Trainingsdaten benötigt werden. Auch wenn die Bedingungsunabhängigkeitsannahme nicht zutrifft, kann der NB-Klassifikator in der Praxis sehr gut funktionieren.
Der Hauptnachteil ist, dass es keine Interaktionen zwischen den Charakteren lernen kann. Das R in mRMR ist die Charakter-Überflüssigkeit. Um ein eher klassisches Beispiel zu nennen, zum Beispiel, obwohl Sie einen Film mit Brad Pitt und Tom Cruise mögen, kann es nicht lernen, dass Sie einen Film nicht mögen, in dem sie zusammen sind.
Vorteile:
Das naive Bayesian Modell stammt aus der klassischen Theorie der Mathematik, hat eine solide mathematische Grundlage und eine stabile Klassifizierungseffizienz. Die Daten sind sehr gut für kleine Datenmengen, können einzeln mit mehreren Gruppen bearbeitet werden und sind für das Incremental Training geeignet. Die Algorithmen sind nicht so empfindlich auf fehlende Daten und sind relativ einfach und werden häufig für die Klassifizierung von Texten verwendet. Nachteile:
Es ist notwendig, die vorherige Wahrscheinlichkeit zu berechnen. Die Fehlerquote bei der Klassifizierung; Die Formen der Eingabedaten sind empfindlich.
- ### 2. Logische Regression
Es gibt viele Methoden zur Regulierung eines diskretionären Modells (L0, L1, L2, etc.), und man muss sich nicht so sehr um die Relevanz seiner Eigenschaften sorgen, wie man es mit einem simplen Bayesianismus tut.
Sie erhalten eine gute Probabilitäts-Interpretation im Vergleich zu einem Entscheidungsbaum und einer SVM-Maschine, und Sie können sogar die Modelle mit neuen Daten leicht aktualisieren (mit Online-Gradient-Descent).
Verwenden Sie es, wenn Sie eine Probabilitätsstruktur benötigen (z. B. um einfach Klassifizierungsstörungen zu regulieren, Unsicherheiten anzugeben, oder um Vertrauensabstände zu erhalten), oder wenn Sie später mehr Trainingsdaten schnell in das Modell integrieren möchten.
Sigmoid-Funktion:
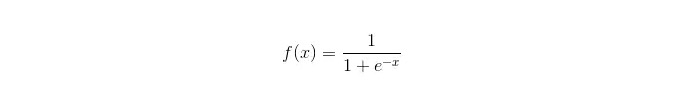
Vorteile: Einfache und umfassende Anwendung auf industrielle Fragen; Die Klassifizierung erfolgt mit sehr geringer Rechenleistung, sehr hoher Geschwindigkeit und geringen Speicherressourcen. Einfache Beobachtungs-Probabilitätspunkte; Bei der logischen Regression ist die Mehrfachkomlinearität kein Problem, das in Kombination mit der L2-Regulierung gelöst werden kann. Nachteile: Die logische Regression funktioniert nicht gut, wenn der Feature Space groß ist. Leicht zu misspassen, in der Regel mit geringer Genauigkeit Schwierigkeiten mit einer Vielzahl von Merkmalen oder Variablen; kann nur zwei Klassifizierungsfragen behandeln (softmax, der daraus abgeleitet wird, kann für mehrere Klassifizierungen verwendet werden) und muss linear teilbar sein; Für die nichtlinearen Merkmale ist eine Umwandlung erforderlich.
- ### 3. Lineare Regression
Lineare Regression wird für Regression verwendet, im Gegensatz zu Logistic Regression, die für Klassifizierung verwendet wird. Die Grundidee ist die Optimierung von Fehlerfunktionen in Form von Minimal-Doppel-Funktionen mit der gradientenmäßigen Regression. Natürlich kann die Lösung der Parameter auch direkt mit der Normal-Gleichung ermittelt werden, was folgendermaßen ausfällt:
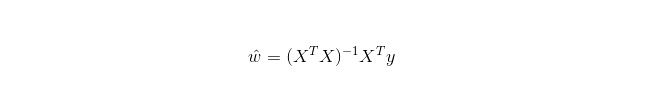
In der LWLR (Local Weighted Linear Regression) ist der berechnete Ausdruck für die Parameter:
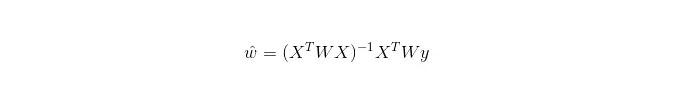
Das LWLR ist ein nicht-parametrisches Modell, da jedes Mal, wenn eine Regression berechnet wird, die Trainingsprobe mindestens einmal durchlaufen wird.
Vorteile: Einfache Implementierung, einfache Berechnung;
Nachteile: Nicht linear angepasste Daten.
- ### 4. Nächster Nachbar Algorithmus KNN
KNN ist ein Nearest-Neighbor-Algorithmus, dessen Hauptprozesse sind:
Berechnen Sie die Entfernung zu jedem Probepunkt in der Trainings- und Testprobe (die üblichen Entfernungsmessungen sind die Euler-Entfernung, die Marsch-Entfernung usw.)
Sortieren Sie alle oben genannten Abstandswerte.
Die Probe mit der geringsten Entfernung k vor der Auswahl;
Die Klassifizierung wird anhand dieser k Stichproben gewählt, um die endgültige Kategorie zu erhalten.
Wie man einen optimalen K-Wert wählt, hängt von den Daten ab. In der Regel reduzieren größere K-Werte bei der Klassifizierung die Auswirkungen von Geräuschen. Die Grenzen zwischen den Kategorien werden jedoch verschwommen.
Ein besserer K-Wert kann durch verschiedene Enlightenment-Techniken, wie z. B. Cross-Verification, erlangt werden. Zusätzlich beeinträchtigt die Anwesenheit von Geräuschen und unabhängigen Merkmalen die Genauigkeit von K-Algorithmen in der Nähe.
Nahe benachbarte Algorithmen weisen eine starke Konsistenz auf. Die Algorithmen garantieren eine Fehlerrate, die nicht mehr als das Doppelte der Bayesianischen Algorithmen-Fehlerrate überschreitet, wenn die Daten unendlich sind. Für einige gute K-Werte garantiert die Nahe benachbarte K-Fehlerrate, dass sie nicht mehr als die Bayesianische theoretische Fehlerrate überschreitet.
Vorteile des KNN-Algorithmus
Die Theorie ist ausgereift, die Gedanken sind einfach, und sie können sowohl zur Klassifizierung als auch zur Regression verwendet werden. Sie können für eine nichtlineare Klassifizierung verwendet werden. Die Trainingszeitkomplexität ist O (n). Es gibt keine Hypothesen für die Daten, sie sind sehr genau und nicht empfindlich für Auslierungen. Mangel
Die Berechnung ist groß. Probenungleichgewicht ((d.h. einige Kategorien haben eine hohe Anzahl von Proben, andere nur eine geringe); Es wird viel Speicher benötigt.
- ### 5. Entscheidungsbaum
Es ist leicht zu interpretieren. Es kann die Interaktionen zwischen den Merkmalen ohne Stress behandeln und ist nicht-parametrisch, so dass Sie sich nicht darum kümmern müssen, ob die Ausnahmewerte oder die Daten linear voneinander getrennt sind (zum Beispiel kann der Entscheidungsträucher leicht damit umgehen, dass die Kategorie A am Ende einer Merkmaldimension x, die Kategorie B in der Mitte und die Kategorie A am vorderen Ende der Merkmaldimension x erscheint).
Einer der Nachteile ist, dass es keine Unterstützung für Online-Lernen gibt, so dass die Entscheidungsträume nach der Ankunft neuer Proben komplett neu erstellt werden müssen.
Ein weiterer Nachteil ist, dass es leicht zu Über-Anpassung kommt, aber dies ist der Einstiegspunkt für Integrationsmethoden wie Random Forest RF (oder Boosted Tree).
Außerdem ist der Zufallswald oft der Gewinner bei vielen Klassifizierungsproblemen (in der Regel nur ein bisschen besser als Support-Vektormaschinen), er ist schnell und anpassungsfähig und man braucht sich keine Sorgen zu machen, wie bei Support-Vektormaschinen eine Menge Parameter zu ändern, so dass er in der Vergangenheit sehr beliebt war.
Ein wichtiger Punkt in einem Entscheidungsbaum ist die Auswahl eines Attributs, um zu verzweigen, also sollten Sie die Berechnungsformel für die Informationszunahme beachten und sie verstehen.
Die Berechnungsformel für die Infobüchse lautet:
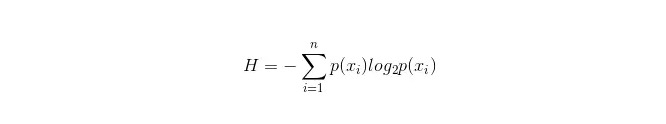
Dabei gibt es n Klassifikationskategorien: ((wenn es sich beispielsweise um eine Frage der Klasse 2 handelt, dann ist n = 2). Die Wahrscheinlichkeit p1 und p2, dass diese beiden Arten von Proben in der Gesamtprobe auftreten, kann berechnet werden, um die Informationsmasse vor der Verzweigung der nicht ausgewählten Eigenschaften zu berechnen.
Nun wird eine Eigenschaft xxi ausgewählt, um zu verzweigen, wobei die Verzweigungsregel lautet: Wenn xi = vxi = v, wird die Probe in einen Zweig des Baumes aufgeteilt; wenn nicht gleich, in einen anderen Zweig.
Es ist offensichtlich, dass die Stichprobe in der Verzweigung sehr wahrscheinlich zwei Kategorien umfasst. Berechnen Sie die beiden Verzweigungen H1 und H2 und berechnen Sie die gesamte Information nach der Verzweigung H = p1 H1 + p2 H2, dann erhöht sich die Information ΔH = H - H.
Die Vorzüge der Entscheidungsträume selbst
Die Berechnung ist einfach, leicht verständlich und interpretierbar. Es wird eine Vergleiche zwischen den Proben mit fehlenden Eigenschaften durchgeführt. Das ist eine sehr wichtige Aufgabe. In relativ kurzer Zeit sind wir in der Lage, für große Datenquellen praktikable und effektive Ergebnisse zu erzielen. Mangel
Überfütterungsgefährdet (Zufallswälder können überfütterungen erheblich reduzieren); Es ist nicht möglich, die Daten zu korrelieren, und es ist nicht möglich, die Daten zu korrelieren. Für die Daten, bei denen die Anzahl der Stichproben in den verschiedenen Kategorien nicht übereinstimmt, werden in den Entscheidungsträumen die Ergebnisse der Informationssteigerung gegenüber denjenigen mit mehr wertvollen Merkmalen bevorzugt (sofern eine Informationssteigerung verwendet wird, hat dies den Nachteil, wie bei RF).
- ### 5.1 Adaboosting
Adaboost ist ein Additionsmodell, bei dem jedes Modell auf der Fehlerrate des vorherigen Modells basiert. Es konzentriert sich übermäßig auf die fehlerhaften Proben und weniger auf die Proben, die richtig klassifiziert wurden. Nach einer Reihe von Iterationen erhält man ein relativ gutes Modell.
Vorteil
adaboost ist ein sehr präziser Klassifikator. Es gibt verschiedene Methoden, um einen Unterklassifikator zu erstellen. Das Adaboost-Algorithmus bietet den Rahmen. Bei einfachen Klassifikatoren sind die Berechnungen nachvollziehbar, bei schwachen Klassifikatoren ist die Konstruktion extrem einfach. Einfach, ohne das Filtern der Merkmale. Überfüllung ist unwahrscheinlich Zu Kombinationsalgorithmen wie Random Forests und GBDT, siehe: Machine Learning - Zusammenfassung der Kombinationsalgorithmen
Nachteile: Empfindlich für Outlier
- ### 6. SVM unterstützt Vektormaschinen
Die hohe Genauigkeit bietet eine gute theoretische Garantie gegen Überpassung, und es funktioniert gut, wenn die Daten linear nicht voneinander getrennt werden können, wenn man ihnen eine geeignete Kernfunktion gibt.
Es ist besonders beliebt bei der Klassifizierung von Texten in dynamischen und hochdimensionalen Formen. Leider ist es sehr speicherbedürftig und schwer zu interpretieren, und die Bedienung und Kommentierung sind etwas lästig, während der Zufallswald diese Nachteile vermeidet und praktisch ist.
Vorteil Es ist eine sehr interessante Methode, um das Problem der hohen Dimensionen zu lösen, also der großen Eigenschaftsraum. Interaktionen zwischen nichtlinearen Merkmalen; Es ist nicht nötig, sich auf die gesamte Datenbank zu verlassen. Das ist eine sehr wichtige Frage.
Mangel Es ist nicht sehr effizient, wenn man viele Proben beobachtet. Es gibt keine allgemeine Lösung für die nichtlinearen Probleme, und es ist manchmal schwierig, eine geeignete Kernfunktion zu finden. Sensibilität für fehlende Daten; Die Auswahl der Kernfunktionen ist sehr geschickt (libsvm verfügt über vier Kernfunktionen: lineare Kernfunktionen, polymorphische Kernfunktionen, RBF-Kernfunktionen und sigmoide Kernfunktionen):
Erstens, wenn die Anzahl der Proben geringer als die Anzahl der Merkmale ist, ist es nicht notwendig, einen nicht-linearen Kern zu wählen, sondern einfach einen linearen Kern zu verwenden.
Zweitens, wenn die Anzahl der Proben größer als die Anzahl der Merkmale ist, kann ein nichtlinearer Kern verwendet werden, um die Proben in eine höhere Dimension zu übertragen, was in der Regel zu besseren Ergebnissen führt.
Drittens, wenn die Anzahl der Proben und die Anzahl der Merkmale gleich sind, kann ein nichtlinearer Kern verwendet werden, der den gleichen Grundsatz wie der zweite hat.
Für den ersten Fall ist es auch möglich, die Daten zu reduzieren und dann einen nichtlinearen Kern zu verwenden, was auch eine Methode ist.
- ### 7. Die Vor- und Nachteile von Neuronalen Netzwerken
Die Vorteile eines künstlichen Neuronalnetzwerks: Die Klassifizierung ist sehr genau. Die Datenbank verfügt über eine starke Parallelverarbeitung, eine starke Speicherung und eine starke Lernfähigkeit. Sie haben eine starke Robustheit und Fehlerverträglichkeit gegenüber den Geräuschnerven, die komplexe nichtlineare Beziehungen nahebringen können. Die Funktion der Erinnerung an die Ereignisse.
Das sind die Nachteile eines künstlichen Neuronalnetzes: Neuronale Netze benötigen eine große Anzahl von Parametern, wie z. B. die Topologie des Netzwerks, die Anfangswerte von Werten und Schwellenwerten. Es ist nicht möglich, den Lernprozess zwischen den Beobachtungen zu beobachten, und die Ausgabe der Ergebnisse ist schwer zu interpretieren, was die Glaubwürdigkeit und Akzeptanz der Ergebnisse beeinträchtigt. Das Studium dauert zu lange und kann sogar zu kurz sein.
- ### 8. K-Means-Gruppierung
Ich habe zuvor einen Artikel über die K-Means-Cluster geschrieben, in dem es um eine starke Konzeption von K-Means geht.
Vorteil Die Algorithmen sind einfach und leicht umzusetzen. Für große Datensätze ist der Algorithmus relativ skalierbar und effizient, da seine Komplexität ungefähr O{\displaystyle O} {\displaystyle O{\displaystyle O}{\displaystyle O}{\displaystyle O{\displaystyle O}{\displaystyle O{\displaystyle O}{\displaystyle O{\displaystyle O}{\displaystyle n}{\displaystyle O{\displaystyle O}{\displaystyle O{\displaystyle O}{\displaystyle O{\displaystyle O}{\displaystyle O}{\displaystyle O{\displaystyle O}{\displaystyle O{\displaystyle O}{\displaystyle O}{\displaystyle O}{\displaystyle O}{\displaystyle O{\displaystyle O}{\mathrm {O}{\mathrm {O}{\mathrm {O}}{\mathrm {O}{\mathrm {O}{\mathrm {O}}{\mathrm {O}{\mathrm {O}{\mathrm {O}{\mathrm {O}{n}}}}}}}} ist, wobei n die Anzahl aller Objekte ist, k die Anzahl Der Algorithmus versucht, die k-Teilungen zu finden, die die Quadratfehlerfunktion am kleinsten machen. Die Klassifizierung funktioniert besser, wenn die Kohlenhydrate dicht, kugelförmig oder klungförmig sind, und die Unterscheidung zwischen Kohlenhydraten und Kohlenhydraten deutlich ist.
Mangel Höhere Anforderungen an die Datentypen, geeignet für numerische Daten; Möglicherweise lokal geringfügig, langsamer auf großen Datenmengen K-Werte sind schwieriger zu erfassen. Sensitivität für die Zentralwerte der Anfangswerte, die zu unterschiedlichen Clusteringsergebnissen führen können; Nicht geeignet für die Entdeckung von nicht konvulsiven oder sehr unterschiedlichen Größen. Für die Sensitivität von Lärm- und Isolierungspunktdaten kann eine geringe Menge solcher Daten einen großen Einfluss auf die Durchschnittswerte haben.
Algorithmus für die Referenzwahl
Ein Artikel, der bereits einige Artikel aus dem Ausland übersetzt hat, gibt einen einfachen Tipp zur Auswahl eines Algorithmus:
Als erste Option sollte man die logische Regression wählen. Wenn sie nicht so gut funktioniert, können die Ergebnisse als Referenz verwendet werden, um sie mit anderen Algorithmen zu vergleichen.
Dann probieren Sie die Entscheidungsträume (Random Forests) aus, um zu sehen, ob Sie die Leistung Ihres Modells erheblich verbessern können. Selbst wenn Sie es nicht als endgültiges Modell betrachten, können Sie den Random Forest verwenden, um die Geräuschvariablen zu entfernen und die Merkmale zu wählen.
Wenn die Anzahl der Merkmale und die Anzahl der beobachteten Proben besonders hoch ist, ist die Verwendung der SVM eine Option, wenn die Ressourcen und die Zeit ausreichen (was wichtig ist).
In der Regel: GBDT>=SVM>=RF>=Adaboost>=Other… , jetzt ist Deep Learning sehr beliebt, es wird in vielen Bereichen verwendet, es basiert auf neuronalen Netzwerken, ich lerne derzeit auch selbst, aber das theoretische Wissen ist nicht sehr dick, das Verständnis ist nicht tief genug, deshalb werde ich hier keine Einführung machen.
Algorithmen sind zwar wichtig, aber gute Daten sind besser als gute Algorithmen, und gute Designmerkmale sind von großem Nutzen. Wenn Sie einen sehr großen Datensatz haben, kann es keinen großen Einfluss auf die Klassifizierungsleistung haben, welchen Algorithmus Sie verwenden (Sie können dann nach Geschwindigkeit und Benutzerfreundlichkeit entscheiden).
-
Verweise