

Dieser Beitrag wurde von meinen Beobachtungen einiger häufiger Warnungen und Fallstricke inspiriert, nachdem ich während meiner Datenrecherche auf der Inventor Quant-Plattform versucht hatte, Techniken des maschinellen Lernens auf Handelsprobleme anzuwenden.
Wenn Sie meinen vorherigen Artikel nicht gelesen haben, empfehlen wir Ihnen, vor diesem Artikel meinen vorherigen Leitfaden zur automatisierten Datenrechercheumgebung auf der Inventor Quantitative Platform und zum systematischen Ansatz zur Entwicklung von Handelsstrategien zu lesen.
Die Adressen finden Sie hier: https://www.fmz.com/digest-topic/4187 und https://www.fmz.com/digest-topic/4169.
Über die Einrichtung einer Forschungsumgebung
Dieses Tutorial richtet sich an Enthusiasten, Ingenieure und Datenwissenschaftler aller Fähigkeitsstufen. Egal, ob Sie ein Branchenexperte oder ein Programmieranfänger sind, Sie benötigen lediglich grundlegende Kenntnisse der Programmiersprache Python und ausreichende Kenntnisse der Befehlszeilenoperationen. (Die Fähigkeit, ein Data-Science-Projekt aufzusetzen, ist ausreichend)
- Inventor Quant Hoster installieren und Anaconda einrichten
Zusätzlich zur Bereitstellung hochwertiger Datenquellen von den wichtigsten Mainstream-Börsen bietet die Inventor Quantitative Platform FMZ.COM auch eine Vielzahl von API-Schnittstellen, die uns dabei helfen, nach Abschluss der Datenanalyse automatisierte Transaktionen durchzuführen. Dieser Satz von Schnittstellen umfasst praktische Tools wie die Abfrage von Kontoinformationen, die Abfrage von Höchst-, Eröffnungs-, Tiefst- und Schlusskursen, Handelsvolumen, verschiedenen häufig verwendeten technischen Analyseindikatoren verschiedener Mainstream-Börsen usw., insbesondere für die Verbindung mit den wichtigsten Mainstream-Börsen in der Praxis Handelsprozesse. Die öffentliche API-Schnittstelle bietet leistungsstarken technischen Support.
Alle oben genannten Funktionen sind in einem Docker-ähnlichen System gekapselt. Wir müssen lediglich unseren eigenen Cloud-Computing-Dienst kaufen oder mieten und dann das Docker-System bereitstellen.
Im offiziellen Namen der Inventor Quantitative Platform wird dieses Docker-System als Hostsystem bezeichnet.
Weitere Informationen zum Bereitstellen von Hosts und Robotern finden Sie in meinem vorherigen Artikel: https://www.fmz.com/bbs-topic/4140
Leser, die ihren eigenen Cloud-Computing-Server-Bereitstellungshost erwerben möchten, können diesen Artikel lesen: https://www.fmz.com/bbs-topic/2848
Nach der erfolgreichen Bereitstellung des Cloud-Computing-Dienstes und des Hostsystems installieren wir das leistungsstärkste Python-Tool: Anaconda
Um alle für diesen Artikel relevanten Programmumgebungen (abhängige Bibliotheken, Versionsverwaltung etc.) zu realisieren, bietet sich am einfachsten die Verwendung von Anaconda an. Es handelt sich um ein gepacktes Python-Data-Science-Ökosystem und einen Abhängigkeitsmanager.
Da wir Anaconda auf einem Cloud-Dienst installieren, empfehlen wir Ihnen, das Linux-System und die Befehlszeilenversion von Anaconda auf dem Cloud-Server zu installieren.
Informationen zur Installationsmethode von Anaconda finden Sie im offiziellen Handbuch von Anaconda: https://www.anaconda.com/distribution/
Wenn Sie ein erfahrener Python-Programmierer sind und nicht das Bedürfnis haben, Anaconda zu verwenden, ist das völlig in Ordnung. Ich gehe davon aus, dass Sie bei der Installation der erforderlichen Abhängigkeiten keine Hilfe benötigen und diesen Abschnitt überspringen können.
Entwickeln Sie eine Handelsstrategie
Das Endergebnis einer Handelsstrategie sollte die folgenden Fragen beantworten:
-
Anleitung: Bestimmen Sie, ob ein Vermögenswert günstig, teuer oder angemessen bewertet ist.
-
Eröffnungsbedingungen: Wenn der Vermögenspreis günstig oder teuer ist, sollten Sie long oder short gehen.
-
Handel schließen: Wenn der Vermögenspreis fair ist und wir eine Position in diesem Vermögenswert haben (vorheriger Kauf oder Verkauf), sollten Sie die Position schließen?
-
Preisspanne: Der Preis (oder die Spanne), zu dem der Handel eröffnet wird
-
Menge: Die Menge der gehandelten Mittel (z. B. die Menge der digitalen Währung oder die Anzahl der Lots von Rohstoff-Futures)
Zur Beantwortung jeder dieser Fragen kann maschinelles Lernen eingesetzt werden. Im weiteren Verlauf dieses Artikels konzentrieren wir uns jedoch auf die Beantwortung der ersten Frage, nämlich der Richtung des Handels.
Strategischer Ansatz
Für die Entwicklung von Strategien gibt es zwei Arten von Ansätzen: Einer basiert auf Modellen, der andere auf Data Mining. Dies sind im Grunde genommen zwei gegensätzliche Ansätze.
Bei der modellbasierten Strategiekonstruktion beginnen wir mit einem Modell der Marktineffizienzen, konstruieren mathematische Ausdrücke (z. B. Preise, Renditen) und testen ihre Wirksamkeit über längere Zeiträume. Bei dem Modell handelt es sich in der Regel um eine vereinfachte Version eines realen komplexen Modells, dessen Aussagekraft und Langzeitstabilität überprüft werden muss. Die üblichen Trendfolge-, Mittelwertumkehr- und Arbitragestrategien fallen in diese Kategorie.
Zum anderen suchen wir zunächst nach Preismustern und versuchen dabei Algorithmen in Data-Mining-Methoden einzusetzen. Die Ursachen dieser Muster sind nicht wichtig, da nur sicher ist, dass sich diese Muster in Zukunft wiederholen werden. Dabei handelt es sich um eine Blindanalysemethode und wir müssen die tatsächlichen Muster streng prüfen, um sie von den zufälligen Mustern unterscheiden zu können. Zu dieser Kategorie gehören „Versuch und Irrtum“, „Balkendiagrammmuster“ und „Feature-Massenregression“.
Offensichtlich eignet sich maschinelles Lernen gut für Data-Mining-Methoden. Sehen wir uns an, wie maschinelles Lernen zum Erstellen von Handelssignalen durch Data Mining genutzt werden kann.
Die Codebeispiele verwenden das Backtesting-Tool und die API-Schnittstelle für automatisierten Handel basierend auf der Inventor Quantitative Platform. Nachdem Sie den Hoster bereitgestellt und Anaconda im obigen Abschnitt installiert haben, müssen Sie nur noch die benötigte Data Science-Analysebibliothek und das bekannte maschinelle Lernmodell scikit-learn installieren. Auf diesen Teil werden wir nicht näher eingehen.
pip install -U scikit-learn
Verwenden von maschinellem Lernen zur Erstellung von Handelsstrategiesignalen
- Datengewinnung
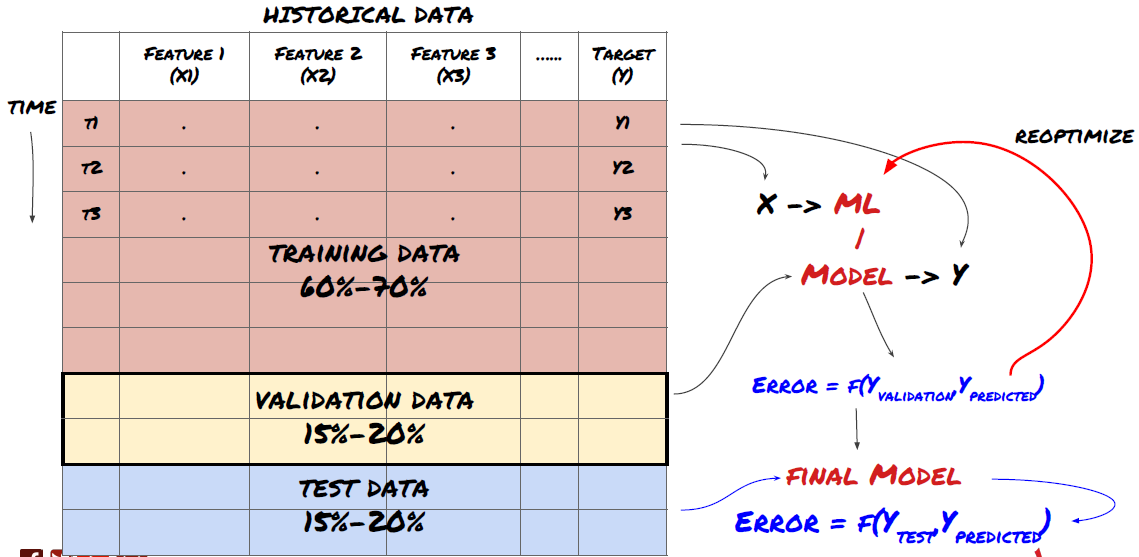
Bevor wir beginnen, sieht ein Standardproblem des maschinellen Lernens folgendermaßen aus:
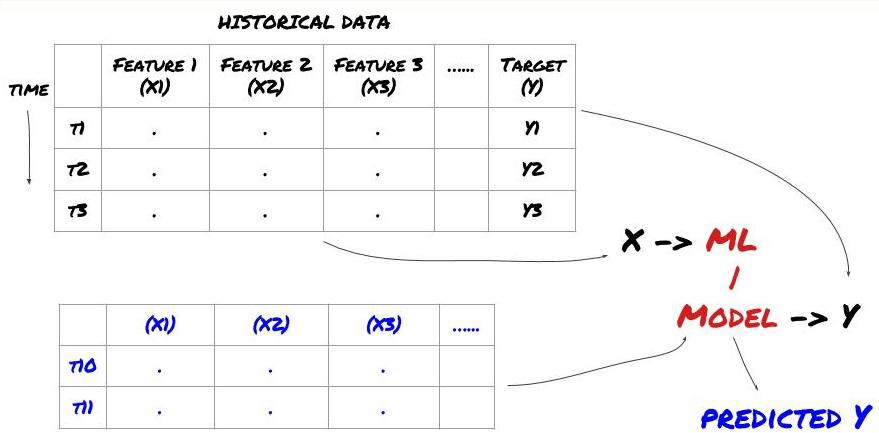
Problemrahmen für maschinelles Lernen
Die Features, die wir erstellen werden, müssen eine gewisse Vorhersagekraft (X) haben. Wir möchten die Zielvariable (Y) vorhersagen und die historischen Daten verwenden, um ein ML-Modell zu trainieren, das Y so nah wie möglich am tatsächlichen Wert vorhersagen kann. Schließlich verwenden wir dieses Modell, um Vorhersagen für neue Daten zu treffen, bei denen Y unbekannt ist. Dies führt uns zum ersten Schritt:
Schritt 1: Problem beschreiben
- Was möchten Sie vorhersagen? Was ist eine gute Prognose? Wie bewerten Sie die Vorhersageergebnisse?
Das heißt, was ist Y in unserem obigen Rahmen?
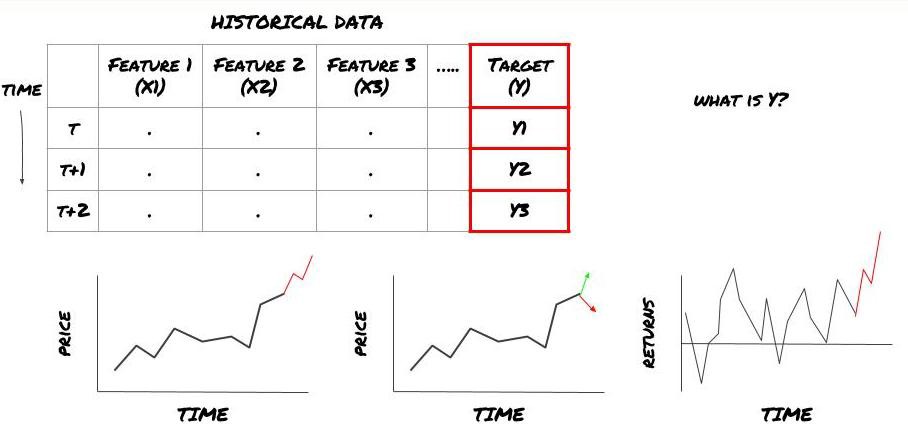
Was möchten Sie vorhersagen?
Möchten Sie zukünftige Preise, zukünftige Renditen/Gewinne und Verkaufssignale vorhersagen, Portfolioallokationen optimieren und versuchen, Trades effizient auszuführen usw.?
Angenommen, wir versuchen, den Preis zum nächsten Zeitstempel vorherzusagen. In diesem Fall ist Y(t) = Preis(t+1). Jetzt können wir unser Framework mit historischen Daten vervollständigen
Beachten Sie, dass Y(t) nur im Backtest bekannt ist, wir bei Verwendung unseres Modells jedoch den Preis zum Zeitpunkt t (t+1) nicht kennen. Wir verwenden unser Modell, um eine Vorhersage Y(vorhergesagt, t) zu treffen und vergleichen sie nur zum Zeitpunkt t+1 mit dem tatsächlichen Wert. Dies bedeutet, dass Sie Y nicht als Merkmal in einem Vorhersagemodell verwenden können.
Sobald wir unser Ziel Y kennen, können wir auch entscheiden, wie wir unsere Vorhersagen auswerten. Dies ist wichtig, um die verschiedenen Modelle zu unterscheiden, die wir anhand unserer Daten ausprobieren werden. Wählen Sie je nach dem zu lösenden Problem eine Metrik zur Messung der Effizienz unseres Modells. Wenn wir beispielsweise Preise vorhersagen, können wir den mittleren quadratischen Fehler als Maß verwenden. Einige häufig verwendete Indikatoren (gleitender Durchschnitt, MACD- und Varianz-Score usw.) wurden in der Inventor Quant-Toolbox vorcodiert und Sie können diese Indikatoren global über die API-Schnittstelle aufrufen.
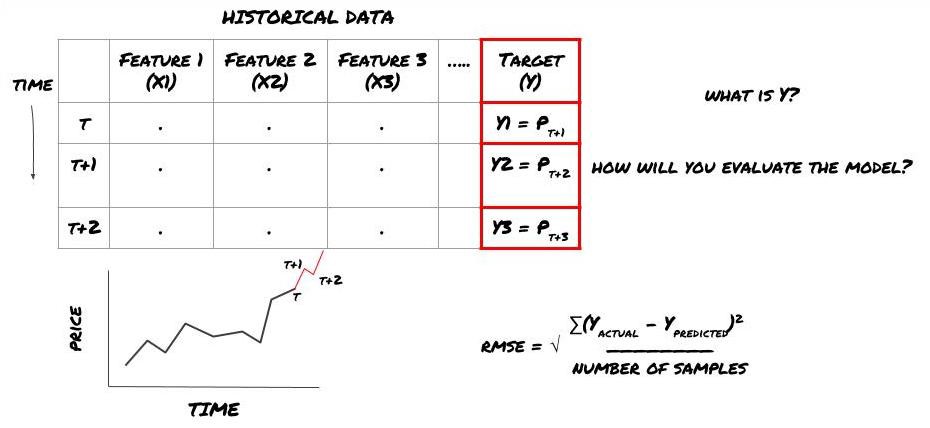
ML-Framework zur Vorhersage zukünftiger Preise
Zur Demonstration erstellen wir ein Prognosemodell zur Vorhersage des zukünftig erwarteten Basiswerts eines hypothetischen Anlageziels. Dabei gilt:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Da es sich um ein Regressionsproblem handelt, werden wir das Modell anhand des RMSE (Root Mean Squared Error) bewerten. Wir werden auch den Gesamtgewinn als Bewertungskriterium verwenden
Hinweis: Relevante mathematische Kenntnisse zu RMSE finden Sie im entsprechenden Inhalt der Baidu-Enzyklopädie
- Unser Ziel: ein Modell zu erstellen, das die vorhergesagten Werte so nahe wie möglich an Y bringt.
Schritt 2: Sammeln Sie zuverlässige Daten
Sammeln und bereinigen Sie Daten, die Ihnen bei der Lösung des vorliegenden Problems helfen können
Welche Daten müssen Sie berücksichtigen, um eine Vorhersagekraft für die Zielvariable Y zu haben? Wenn wir Preise vorhersagen, können Sie Zielpreisdaten, Daten zum Zielhandelsvolumen, ähnliche Daten für verwandte Ziele, allgemeine Marktindikatoren wie Zielindexstände, Preise anderer verwandter Vermögenswerte usw. verwenden.
Sie müssen Datenzugriffsberechtigungen für diese Daten einrichten, die Richtigkeit Ihrer Daten sicherstellen und fehlende Daten beheben (ein sehr häufiges Problem). Stellen Sie außerdem sicher, dass Ihre Daten unvoreingenommen sind und alle Marktbedingungen angemessen darstellen (z. B. die gleiche Anzahl von Gewinn-/Verlust-Szenarien), um eine Verzerrung in Ihrem Modell zu vermeiden. Möglicherweise müssen Sie die Daten auch hinsichtlich Dividenden, Portfolioaufteilungen, Fortsetzungen usw. bereinigen.
Wenn Sie die Inventor Quantitative Platform (FMZ.COM) verwenden, können wir auf kostenlose globale Daten von Google, Yahoo, NSE und Quandl zugreifen; auf detaillierte Daten von inländischen Rohstoff-Futures wie CTP und Yisheng; Binance, OKEX, Huobi und BitMex Die Inventor Quantitative Platform bereinigt und filtert diese Daten auch vorab, beispielsweise Aufteilungen von Anlagezielen und detaillierte Marktdaten, und stellt sie Strategieentwicklern in einem Format zur Verfügung, das für quantitative Mitarbeiter leicht verständlich ist.
Der Einfachheit halber verwenden wir in diesem Artikel die folgenden Daten als virtuelles Investitionsziel „MQK“. Wir verwenden auch ein sehr praktisches quantitatives Tool namens Auquan's Toolbox. Weitere Informationen finden Sie unter: https://github.com/Auquan / auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Mit dem obigen Code hat Auquans Toolbox die Daten heruntergeladen und in das Datenrahmenwörterbuch geladen. Jetzt müssen wir die Daten in einem von uns bevorzugten Format vorbereiten. Die Funktion ds.getBookDataByFeature() gibt ein Wörterbuch mit Datenrahmen zurück, einen Datenrahmen pro Feature. Wir erstellen einen neuen Datenrahmen für Aktien mit allen Funktionen.
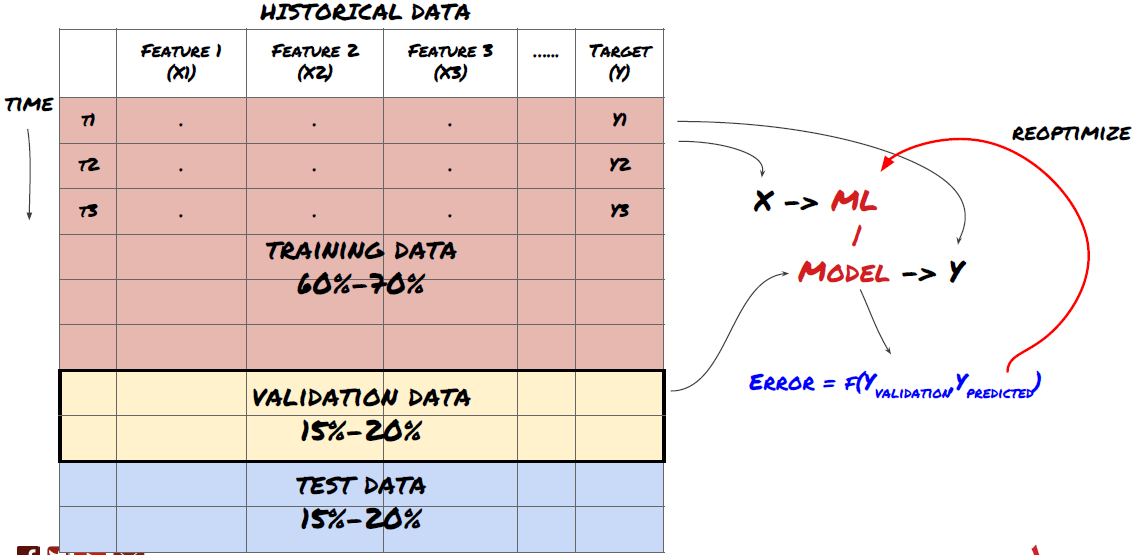
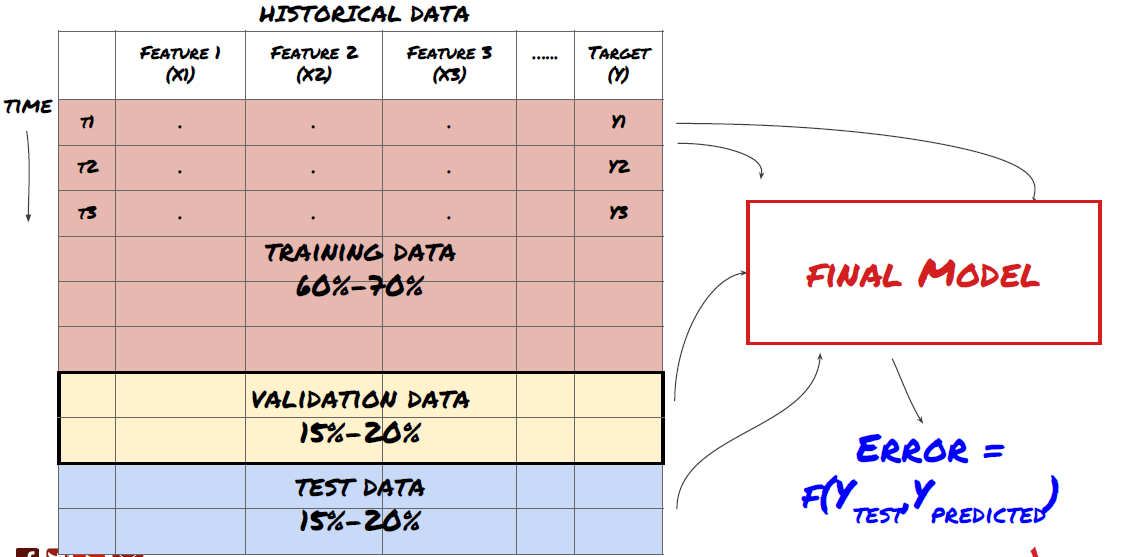
Schritt 3: Aufteilen der Daten
- Trainingssets aus Daten erstellen, kreuzvalidieren und testen
Dies ist ein sehr wichtiger Schritt! Bevor wir fortfahren, sollten wir die Daten in einen Trainingsdatensatz aufteilen, um Ihr Modell zu trainieren, und einen Testdatensatz, um die Modellleistung zu bewerten. Die empfohlene Aufteilung ist: 60-70% Trainingsdatensatz und 30-40% Testdatensatz
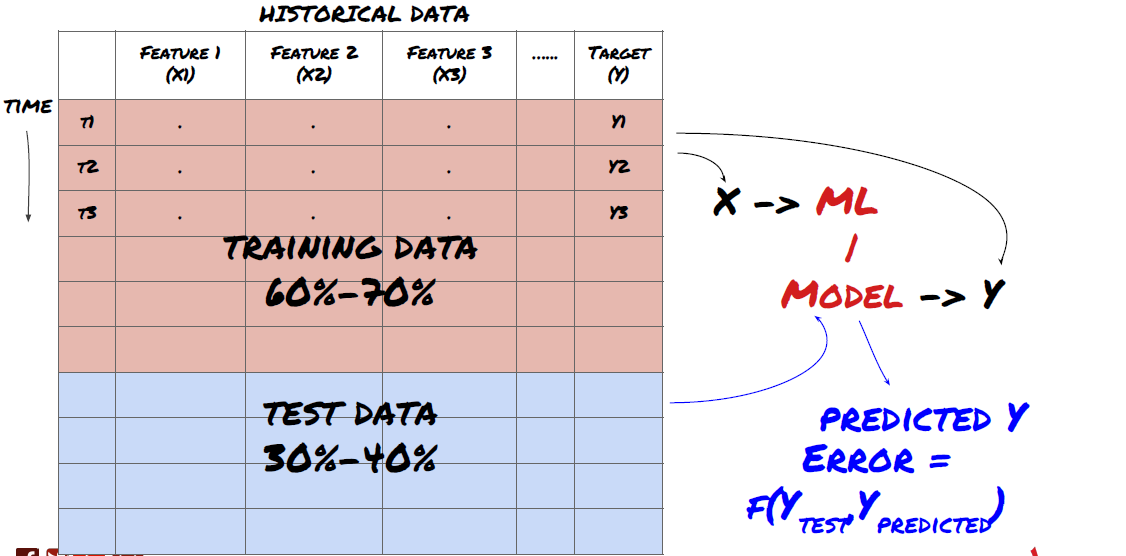
Teilen Sie die Daten in Trainings- und Testsätze auf
Da die Trainingsdaten zur Auswertung der Modellparameter verwendet werden, ist es möglich, dass Ihr Modell überangepasst an diese Trainingsdaten ist und die Trainingsdaten die Modellleistung verfälschen. Wenn Sie keine separaten Testdaten aufbewahren und alle Daten zum Training verwenden, wissen Sie nicht, wie gut oder schlecht Ihr Modell bei neuen, unbekannten Daten funktioniert. Dies ist einer der Hauptgründe, warum trainierte ML-Modelle bei Live-Daten versagen: Die Leute trainieren mit allen verfügbaren Daten und sind von den Trainingsdatenmetriken begeistert, aber das Modell kann keine sinnvollen Vorhersagen auf der Grundlage von Live-Daten treffen, mit denen es nicht trainiert wurde. .
Teilen Sie die Daten in Trainings-, Validierungs- und Testsätze auf
Dieser Ansatz ist mit Problemen verbunden. Wenn wir wiederholt mit Trainingsdaten trainieren, die Leistung anhand von Testdaten bewerten und unser Modell optimieren, bis wir mit der Leistung zufrieden sind, schließen wir die Testdaten implizit als Teil der Trainingsdaten ein. Letztendlich kann es sein, dass unser Modell mit diesem Satz an Trainings- und Testdaten gute Ergebnisse liefert, es gibt jedoch keine Garantie dafür, dass es auch neue Daten gut vorhersagen kann.
Um dieses Problem zu beheben, können wir einen separaten Validierungsdatensatz erstellen. Jetzt können Sie mit den Daten trainieren, die Leistung anhand der Validierungsdaten bewerten, optimieren, bis Sie mit der Leistung zufrieden sind, und schließlich mit den Testdaten testen. Auf diese Weise werden die Testdaten nicht verfälscht und wir verwenden keine Informationen aus den Testdaten, um unser Modell zu verbessern.
Denken Sie daran: Wenn Sie die Leistung anhand der Testdaten überprüft haben, gehen Sie nicht zurück und versuchen Sie nicht, das Modell weiter zu optimieren. Wenn Sie feststellen, dass Ihr Modell keine guten Ergebnisse liefert, verwerfen Sie das Modell vollständig und beginnen Sie von vorne. Die vorgeschlagene Aufteilung könnte 60 % Trainingsdaten, 20 % Validierungsdaten und 20 % Testdaten sein.
Für unser Problem stehen uns drei Datensätze zur Verfügung und wir verwenden einen als Trainingssatz, den zweiten als Validierungssatz und den dritten als Testsatz.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Zu jedem dieser Werte addieren wir die Zielvariable Y, definiert als Mittelwert der nächsten fünf Basiswerte
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Schritt 4: Feature Engineering
Analysieren Sie das Verhalten von Daten und erstellen Sie Features mit Vorhersagekraft
Jetzt beginnt der eigentliche Bau des Projektes. Die goldene Regel der Merkmalsauswahl besteht darin, dass die Vorhersagekraft in erster Linie von den Merkmalen und nicht vom Modell abhängt. Sie werden feststellen, dass die Auswahl der Funktionen einen viel größeren Einfluss auf die Leistung hat als die Wahl des Modells. Einige Hinweise zur Funktionsauswahl:
-
Wählen Sie nicht willkürlich eine große Menge an Features aus, ohne deren Beziehung zur Zielvariablen zu untersuchen.
-
Eine geringe oder keine Beziehung zur Zielvariablen kann zu einer Überanpassung führen
-
Die von Ihnen ausgewählten Merkmale können stark miteinander korreliert sein. In diesem Fall kann eine geringere Anzahl von Merkmalen auch das Ziel erklären.
-
Normalerweise erstelle ich einige Features, die intuitiv Sinn ergeben, und schaue mir an, wie die Zielvariable mit diesen Features korreliert und wie sie untereinander korrelieren, um zu entscheiden, welche ich verwenden soll.
-
Sie können auch versuchen, Kandidatenfunktionen basierend auf dem Maximum Information Coefficient (MIC) zu bewerten, eine Hauptkomponentenanalyse (PCA) durchzuführen und andere Methoden anzuwenden.
Merkmalstransformation/Normalisierung:
ML-Modelle funktionieren mit Normalisierung tendenziell gut. Bei der Verarbeitung von Zeitreihendaten ist die Normalisierung jedoch schwierig, da der zukünftige Datenbereich unbekannt ist. Ihre Daten liegen möglicherweise außerhalb des normalisierten Bereichs, wodurch das Modell falsch ist. Sie können jedoch dennoch versuchen, ein gewisses Maß an Stationarität zu erzwingen:
-
Skalierung: Aufteilen von Merkmalen nach Standardabweichung oder Interquartilsabstand
-
Zentrieren: Subtrahieren Sie den historischen Durchschnitt vom aktuellen Wert
-
Normalisierung: Zwei Rückblickperioden der oben genannten (x - Mittelwert) / Standardabweichung
-
Konventionelle Normalisierung: Normalisieren Sie die Daten auf einen Bereich von -1 bis +1 und zentrieren Sie sie innerhalb des Rückblickzeitraums (x-min)/(max-min) neu.
Beachten Sie, dass der normalisierte Wert des Features zu unterschiedlichen Zeitpunkten unterschiedliche tatsächliche Werte darstellt, da wir den historischen gleitenden Mittelwert, die Standardabweichung sowie den Maximal- oder Minimalwert über den Rückblickzeitraum verwenden. Wenn beispielsweise der aktuelle Wert eines Features 5 ist und der laufende Durchschnitt der letzten 30 Perioden 4,5 beträgt, wird er nach der Zentrierung in 0,5 konvertiert. Wenn der gleitende Durchschnitt der letzten 30 Perioden später 3 beträgt, wird aus dem Wert 3,5 0,5. Dies könnte der Grund sein, warum das Modell falsch ist. Die Regularisierung ist also schwierig und Sie müssen herausfinden, was die Leistung des Modells tatsächlich verbessert (falls überhaupt etwas).
Für die erste Iteration unseres Problems haben wir mithilfe der Mischparameter eine große Anzahl von Features erstellt. Später werden wir versuchen, die Anzahl der Funktionen zu reduzieren
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Schritt 5: Modellauswahl
Wählen Sie das geeignete Statistik-/ML-Modell für das gewählte Problem
Die Wahl des Modells hängt von der Problemformulierung ab. Lösen Sie ein überwachtes (jeder Punkt X in der Merkmalsmatrix wird einer Zielvariable Y zugeordnet) oder ein unüberwachtes Lernproblem (es ist keine Zuordnung gegeben und das Modell versucht, unbekannte Muster zu lernen)? Lösen Sie eine Regression (Vorhersage des tatsächlichen Preises zu einem zukünftigen Zeitpunkt) oder ein Klassifizierungsproblem (Vorhersage nur der Richtung (Anstieg/Senkung) des Preises zu einem zukünftigen Zeitpunkt).

Überwachtes oder unüberwachtes Lernen

Regression oder Klassifizierung
Einige gängige Algorithmen für überwachtes Lernen können Ihnen den Einstieg erleichtern:
-
LinearRegression(Parameter, Regression)
-
Logistische Regression (Parameter, Klassifizierung)
-
K-Nearest-Neighbor (KNN)-Algorithmus (instanzbasiert, Regression)
-
SVM, SVR (Parameter, Klassifizierung und Regression)
-
Entscheidungsbaum
-
Entscheidungswald
Ich empfehle, mit einem einfachen Modell wie einer linearen oder logistischen Regression zu beginnen und von dort aus nach Bedarf komplexere Modelle zu erstellen. Es wird außerdem empfohlen, dass Sie sich mit der Mathematik hinter dem Modell vertraut machen, statt es blind als Blackbox zu verwenden.
Schritt 6: Training, Validierung und Optimierung (Schritte 4-6 wiederholen)
Trainieren und optimieren Sie Ihr Modell mit den Trainings- und Validierungsdatensätzen
Jetzt können Sie endlich mit dem Bau Ihres Modells beginnen. In dieser Phase iterieren Sie eigentlich nur das Modell und die Modellparameter. Trainieren Sie Ihr Modell anhand der Trainingsdaten, messen Sie seine Leistung anhand der Validierungsdaten, gehen Sie dann zurück, optimieren Sie, trainieren Sie erneut und bewerten Sie. Wenn Sie mit der Leistung eines Modells nicht zufrieden sind, versuchen Sie es mit einem anderen Modell. Sie durchlaufen diese Phase mehrere Male, bis Sie schließlich ein Modell haben, mit dem Sie zufrieden sind.
Erst wenn Ihnen ein Modell gefällt, können Sie mit dem nächsten Schritt fortfahren.
Für unser Demonstrationsproblem beginnen wir mit einer einfachen linearen Regression
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
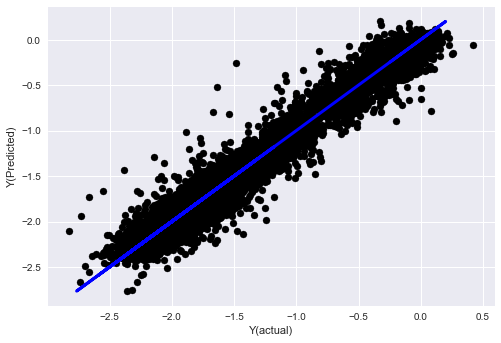
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
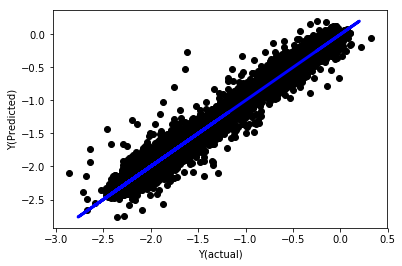
Lineare Regression ohne Normalisierung
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Schauen Sie sich die Modellkoeffizienten an. Wir können sie nicht wirklich vergleichen oder sagen, welche wichtig sind, weil sie alle auf unterschiedlichen Skalen liegen. Versuchen wir, sie durch Normalisierung auf den gleichen Maßstab zu bringen und auch eine gewisse Stationarität zu erzwingen.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
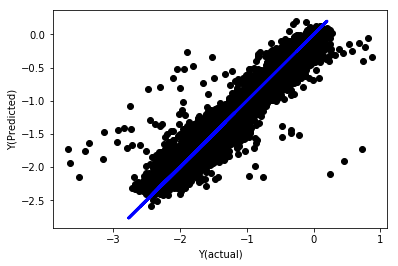
Normalisierte lineare Regression
Mean squared error: 0.05
Variance score: 0.90
Dieses Modell stellt gegenüber dem Vorgängermodell keine Verbesserung dar, ist aber auch nicht schlechter. Jetzt können wir die Koeffizienten tatsächlich vergleichen und sehen, welche tatsächlich signifikant sind.
Schauen wir uns die Koeffizienten an
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Das Ergebnis ist:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Wir können deutlich erkennen, dass einige Merkmale im Vergleich zu anderen Merkmalen höhere Koeffizienten aufweisen und wahrscheinlich eine stärkere Vorhersagekraft haben.
Schauen wir uns die Korrelation zwischen verschiedenen Merkmalen an.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
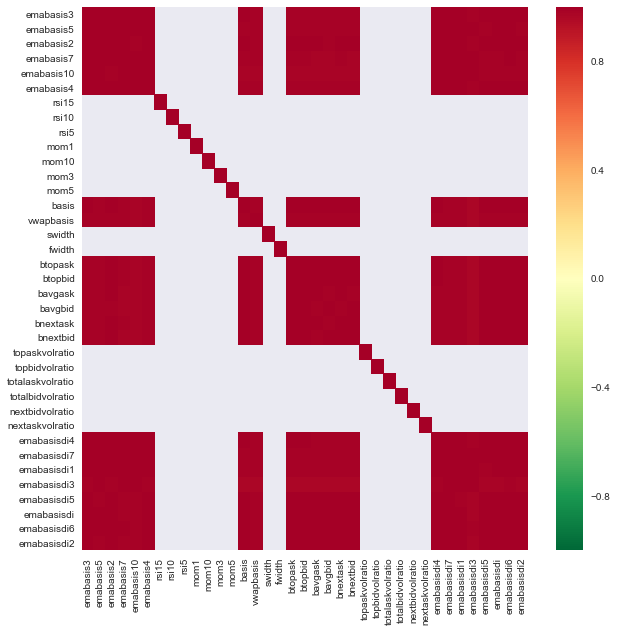
Korrelation zwischen Merkmalen
Dunkelrote Bereiche zeigen stark korrelierte Variablen an. Lassen Sie uns erneut einige Funktionen erstellen/ändern und versuchen, unser Modell zu verbessern.
Beispielsweise kann ich Features wie emabasisdi7, die lediglich lineare Kombinationen anderer Features sind, problemlos verwerfen.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
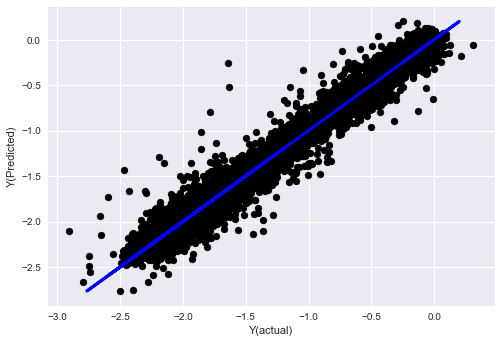
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Sie sehen, es gibt keine Veränderung in der Leistung unseres Modells, wir brauchen nur ein paar Merkmale, um unsere Zielvariable zu erklären. Ich schlage vor, dass Sie mehr der oben genannten Funktionen ausprobieren, neue Kombinationen usw. testen, um zu sehen, wie sich unser Modell verbessern lässt.
Wir können auch komplexere Modelle ausprobieren, um zu sehen, ob Änderungen am Modell die Leistung verbessern können.
- K-Nearest-Neighbor-Algorithmus (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Entscheidungsbaum
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Schritt 7: Backtest der Testdaten
Überprüfen Sie die Leistung anhand tatsächlicher Beispieldaten
Backtest-Leistung auf dem (unberührten) Testdatensatz
Dies ist ein kritischer Moment. Wir beginnen mit dem letzten Schritt, indem wir unser endgültiges optimiertes Modell auf den Testdaten ausführen, die wir zu Beginn beiseite gelegt und bisher nicht berührt haben.
Dadurch erhalten Sie realistische Erwartungen hinsichtlich der Leistung Ihres Modells anhand neuer und unbekannter Daten, wenn Sie mit dem Live-Handel beginnen. Daher müssen Sie sicherstellen, dass Sie über einen sauberen Datensatz verfügen, der nicht zum Trainieren oder Validieren des Modells verwendet wurde.
Wenn Sie mit den Backtest-Ergebnissen Ihrer Testdaten nicht zufrieden sind, verwerfen Sie das Modell und beginnen Sie von vorne. Gehen Sie niemals zurück und optimieren Sie Ihr Modell erneut, dies führt zu einer Überanpassung! (Es wird außerdem empfohlen, einen neuen Testdatensatz zu erstellen, da dieser Datensatz jetzt kontaminiert ist; wenn wir das Modell verwerfen, wissen wir implizit bereits etwas über den Datensatz.)
Hier verwenden wir weiterhin Auquans Toolbox
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
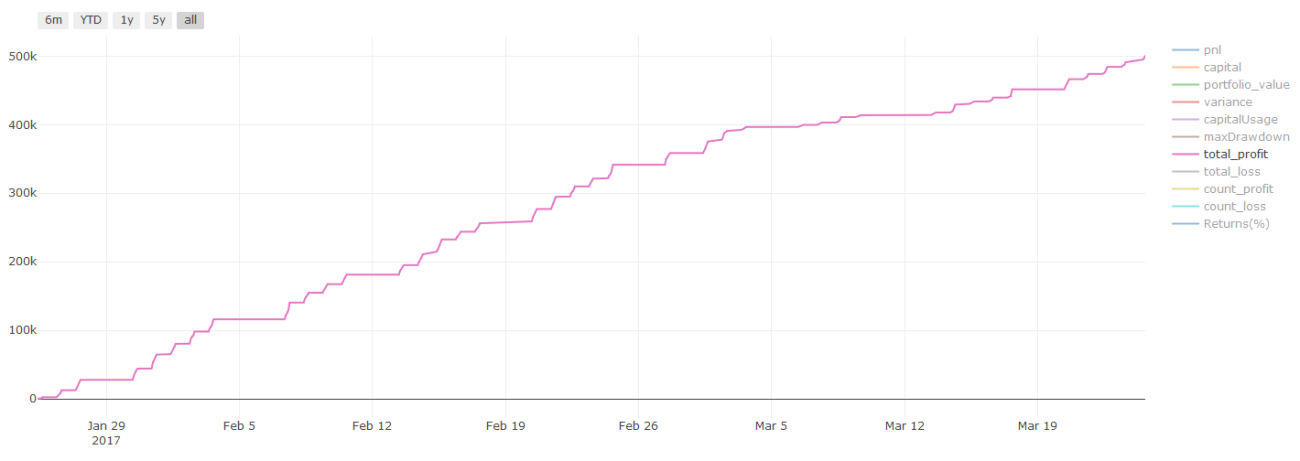
Backtest-Ergebnisse, PNL wird in US-Dollar berechnet (PNL beinhaltet keine Transaktionskosten und andere Gebühren)
Schritt 8: Weitere Möglichkeiten zur Verbesserung des Modells
Rollierende Validierung, Ensemble-Lernen, Bagging und Boosting
Neben dem Sammeln weiterer Daten, dem Erstellen besserer Funktionen oder dem Ausprobieren weiterer Modelle gibt es einige Dinge, die Sie versuchen können, zu verbessern.
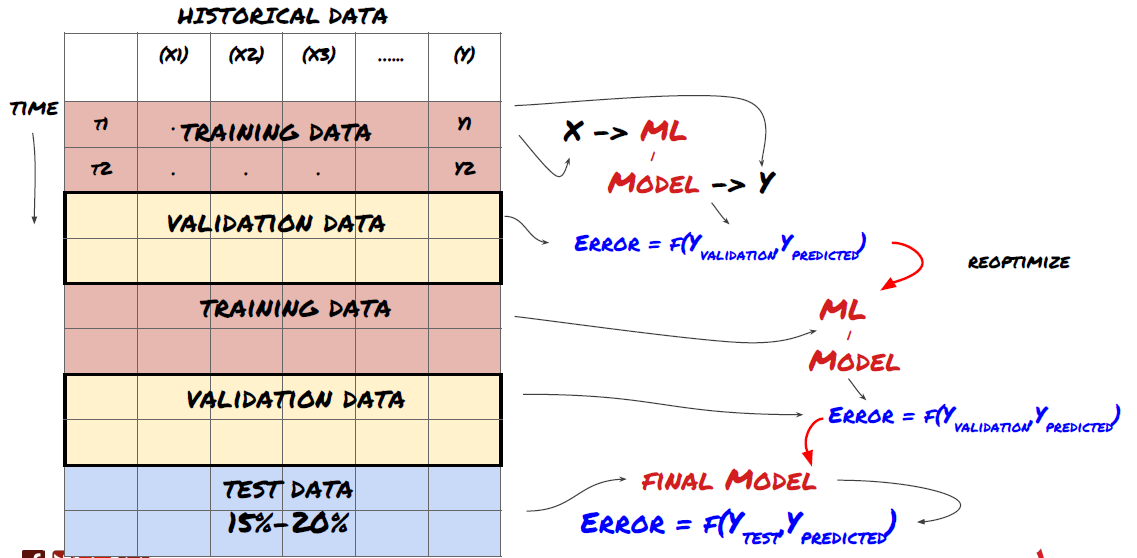
1. Fortlaufende Verifizierung
Fortlaufende Validierung
Die Marktbedingungen bleiben selten konstant. Angenommen, Sie verfügen über Daten für ein Jahr und verwenden Daten von Januar bis August zum Trainieren und Daten von September bis Dezember zum Testen Ihres Modells. Dann trainieren Sie möglicherweise für einen sehr spezifischen Satz von Marktbedingungen. Vielleicht gab es in der ersten Jahreshälfte keine Marktvolatilität und einige extreme Nachrichten haben im September einen starken Marktanstieg verursacht. Ihr Modell wird dieses Muster nicht lernen können und Ihnen Müllvorhersageergebnisse liefern.
Es wäre vielleicht besser, die Validierung fortlaufend zu verlängern, das Training im Januar/Februar durchzuführen, die Validierung im März durchzuführen, das erneute Training im April/Mai durchzuführen, die Validierung im Juni durchzuführen und so weiter.
2. Ensemble-Lernen
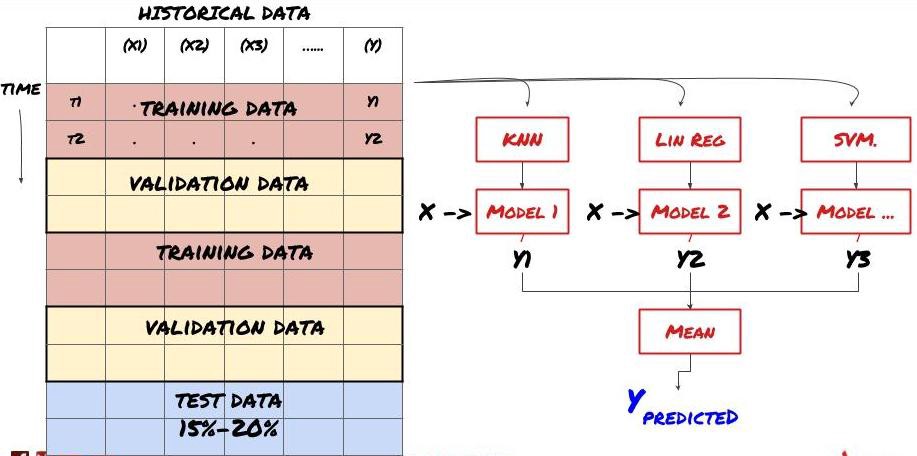
Ensemble-Lernen
Manche Modelle eignen sich möglicherweise gut für die Vorhersage bestimmter Szenarien, sind jedoch bei der Vorhersage anderer Szenarien oder in bestimmten Situationen möglicherweise deutlich überangepasst. Eine Möglichkeit, Fehler und Überanpassung zu reduzieren, besteht darin, ein Ensemble verschiedener Modelle zu verwenden. Ihre Vorhersage ist der Durchschnitt der Vorhersagen vieler Modelle und die Fehler verschiedener Modelle können ausgeglichen oder reduziert werden. Einige gängige Ensemblemethoden sind Bagging und Boosting.
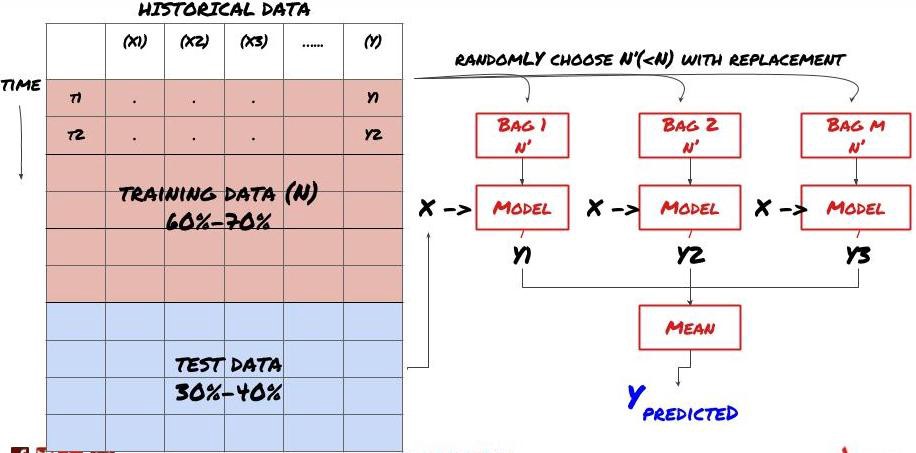
Bagging
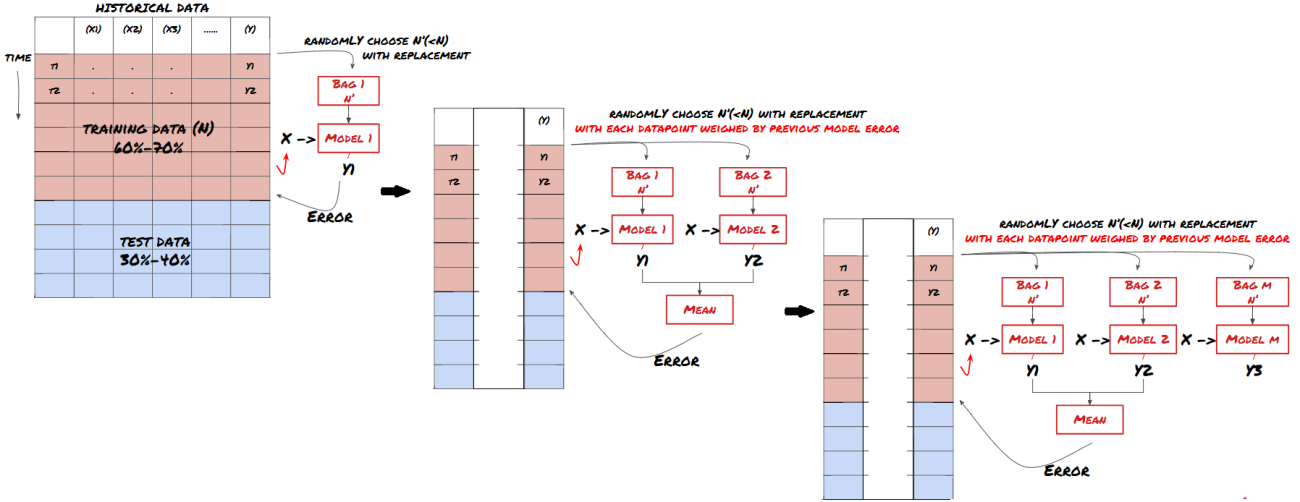
Boosting
Der Kürze halber werde ich diese Methoden überspringen, aber Sie können online weitere Informationen dazu finden.
Versuchen wir eine Ensemble-Methode für unser Problem
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Bisher haben wir viel Wissen und Informationen gesammelt. Lassen Sie uns kurz zusammenfassen:
-
Lösen Sie Ihr Problem
-
Zuverlässige Daten sammeln und Daten bereinigen
-
Teilen Sie die Daten in Trainings-, Validierungs- und Testsätze auf
-
Erstellen Sie Features und analysieren Sie ihr Verhalten
-
Wählen Sie das geeignete Trainingsmodell basierend auf dem Verhalten
-
Verwenden Sie die Trainingsdaten, um Ihr Modell zu trainieren und Vorhersagen zu treffen
-
Überprüfen Sie die Leistung des Validierungssatzes und optimieren Sie erneut
-
Überprüfen Sie die endgültige Leistung auf dem Testset
Ziemlich aufregend, oder? Aber es ist noch nicht vorbei. Sie haben jetzt nur noch ein zuverlässiges Vorhersagemodell. Erinnern Sie sich, was wir mit unserer Strategie wirklich wollten? Du brauchst also noch nicht:
-
Entwickeln Sie prädiktive, modellbasierte Signale zur Erkennung von Handelsrichtungen
-
Entwickeln Sie spezifische Strategien zur Identifizierung von Eröffnungs- und Schlusspositionen
-
Ausführungssystem zur Identifizierung von Positionen und Preisen
Für alle oben genannten Funktionen ist die Verwendung der Inventor Quantitative Platform (FMZ.COM) erforderlich. Die Inventor Quantitative Platform verfügt über eine hochgradig gekapselte und vollständige API-Schnittstelle sowie global aufrufbare Bestell- und Transaktionsfunktionen, sodass Sie nicht um sie nacheinander zu verbinden und hinzuzufügen. API-Schnittstellen verschiedener Börsen, im Strategy Square der Inventor Quantitative Platform gibt es viele ausgereifte und vollständige alternative Strategien. Mit der maschinellen Lernmethode dieses Artikels wird Ihre spezifische Strategie leistungsfähiger Den Strategy Square finden Sie unter: https://www.fmz.com/square
Ein wichtiger Hinweis zu den Transaktionskosten: Ihr Modell sagt Ihnen, wann Sie bei Ihrem ausgewählten Vermögenswert Long- oder Short-Positionen eingehen sollten. Gebühren/Transaktionskosten/verfügbares Volumen/Stop-Losses usw. werden dabei jedoch nicht berücksichtigt. Transaktionskosten können einen profitablen Handel oft in einen Verlust verwandeln. Beispielsweise ist ein Vermögenswert, dessen Preis voraussichtlich um 0,05 \( steigen wird, ein Kauf. Wenn Sie für diesen Handel jedoch 0,10 \) zahlen müssen, entsteht Ihnen am Ende ein Nettoverlust von 0,05 $. Unser beeindruckendes Gewinndiagramm oben sieht tatsächlich so aus, wenn Sie Maklerprovisionen, Börsengebühren und Spreads berücksichtigen:
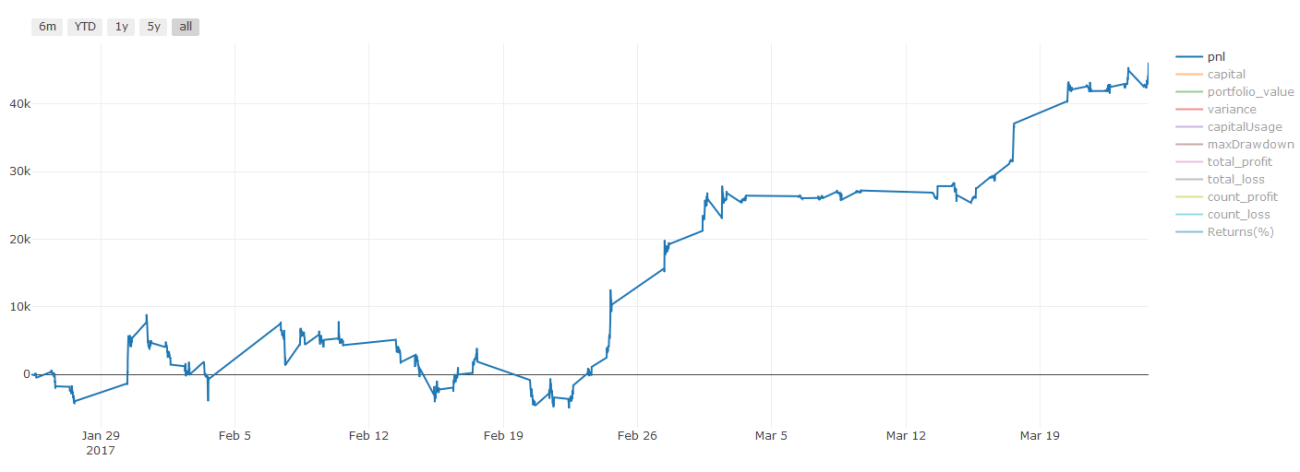
Backtest-Ergebnisse nach Transaktionsgebühren und Spreads, Pnl ist USD
Transaktionsgebühren und Spreads machen mehr als 90 % unseres Gewinns aus! Wir werden diese in den nachfolgenden Artikeln ausführlich besprechen.
Schauen wir uns abschließend einige häufige Fehler an.
Was man tun und lassen sollte
-
Vermeiden Sie mit aller Kraft ein Overfitting!
-
Führen Sie kein erneutes Training nach jedem Datenpunkt durch: Dies ist ein häufiger Fehler bei der Entwicklung von maschinellem Lernen. Wenn Ihr Modell nach jedem Datenpunkt neu trainiert werden muss, ist es wahrscheinlich kein sehr gutes Modell. Das heißt, es muss regelmäßig neu trainiert werden, und zwar so oft es sinnvoll ist (z. B. am Ende jeder Woche bei Intraday-Prognosen).
-
Vermeiden Sie Verzerrungen, insbesondere Vorausschauverzerrungen: Dies ist ein weiterer Grund, warum Modelle nicht funktionieren. Stellen Sie sicher, dass Sie keine Informationen aus der Zukunft verwenden. Meistens bedeutet dies, dass Sie die Zielvariable Y nicht als Feature in Ihrem Modell verwenden. Sie können es beim Backtesting verwenden, es ist jedoch beim tatsächlichen Ausführen Ihres Modells nicht verfügbar, was Ihr Modell unbrauchbar macht.
-
Vorsicht vor Data-Mining-Verzerrungen: Da wir versuchen, eine Reihe von Modellierungen an unseren Daten durchzuführen, um zu ermitteln, ob sie passen, sollten Sie, wenn es dafür keinen besonderen Grund gibt, strenge Tests durchführen, um zufällige Muster von realen Mustern zu unterscheiden, die auftreten könnten . Beispielsweise lässt sich ein Aufwärtstrendmuster gut durch eine lineare Regression erklären, aber es handelt sich wahrscheinlich nur um einen kleinen Teil eines größeren Zufallsverlaufs.
Vermeiden Sie Überanpassung
Das ist so wichtig, dass ich es noch einmal erwähnen möchte.
-
Overfitting ist die gefährlichste Falle bei Handelsstrategien
-
Ein komplexer Algorithmus kann beim Backtesting sehr gute Ergebnisse erzielen, bei neuen, noch nicht bekannten Daten jedoch kläglich versagen. Der Algorithmus erkennt keine wirklichen Trends in den Daten und verfügt über keine echte Vorhersagekraft. Es ist sehr gut auf die Daten abgestimmt, die es sieht
-
Halten Sie Ihr System so einfach wie möglich. Wenn Sie feststellen, dass Sie viele komplexe Funktionen benötigen, um Ihre Daten zu erklären, kann es sein, dass Sie überangepasst haben.
-
Teilen Sie Ihre verfügbaren Daten in Trainings- und Testdaten auf und überprüfen Sie die Leistung immer anhand echter Beispieldaten, bevor Sie das Modell für den Live-Handel verwenden.



- 1