Anwendung der Maschinellen Lerntechnologie im Handel
Schriftsteller:Lydia., Erstellt: 2022-12-30 10:53:07, Aktualisiert: 2023-09-20 09:30:09
Anwendung der Maschinellen Lerntechnologie im Handel
Die Inspiration für diesen Artikel stammt aus meiner Beobachtung einiger häufiger Warnungen und Fallen nach dem Versuch, Maschinelle Lerntechnologie auf Transaktionsprobleme während der Datenforschung auf der FMZ Quant-Plattform anzuwenden.
Wenn Sie meine vorherigen Artikel noch nicht gelesen haben, empfehlen wir Ihnen, den Leitfaden für die automatisierte Datenforschung und die systematische Methode zur Formulierung von Handelsstrategien zu lesen, die ich vor diesem Artikel auf der FMZ Quant-Plattform entwickelt habe.
Diese beiden Artikeladressen finden Sie hier:https://www.fmz.com/digest-topic/9862undhttps://www.fmz.com/digest-topic/9863.
Über die Einrichtung des Forschungsumfelds
Dieses Tutorial richtet sich an Enthusiasten, Ingenieure und Datenwissenschaftler aller Fähigkeitsstufen. Ob Sie ein Branchenführer oder ein Programmierbeginner sind, die einzigen Fähigkeiten, die Sie benötigen, sind ein grundlegendes Verständnis der Python-Programmiersprache und ausreichende Kenntnisse der Befehlszeilenoperationen (ein Datenwissenschaftsprojekt einzurichten ist ausreichend).
- Installieren Sie den FMZ Quant Docker und installieren Sie Anaconda
Die FMZ Quant-PlattformFMZ.COMDiese Anwendungen bieten nicht nur qualitativ hochwertige Datenquellen für die wichtigsten Mainstream-Börsen, sondern bieten auch eine Reihe von API-Schnittstellen, die uns helfen, automatische Transaktionen nach Abschluss der Datenanalyse durchzuführen.
Alle oben genannten Funktionen sind in einem Docker-ähnlichen System eingekapselt. Was wir tun müssen, ist, unsere eigenen Cloud-Computing-Dienste zu kaufen oder zu leasen und das Docker-System zu implementieren.
In der offiziellen Bezeichnung der FMZ Quant-Plattform wird das Docker-System das Docker-System genannt.
Bitte beachten Sie meinen vorherigen Artikel über die Bereitstellung eines Dockers und eines Roboters:https://www.fmz.com/bbs-topic/9864.
Leser, die ihren eigenen Cloud-Computing-Server kaufen möchten, um Dockers zu implementieren, können sich auf diesen Artikel beziehen:https://www.fmz.com/digest-topic/5711.
Nachdem wir den Cloud-Computing-Server und das Docker-System erfolgreich bereitgestellt haben, installieren wir als nächstes das derzeit größte Artefakt von Python: Anaconda.
Um alle relevanten Programmumgebungen (Abhängigkeitsbibliotheken, Versionsmanagement usw.) zu realisieren, die in diesem Artikel erforderlich sind, ist es am einfachsten, Anaconda zu verwenden.
Da wir Anaconda auf dem Cloud-Service installieren, empfehlen wir, dass der Cloud-Server das Linux-System und die Befehlszeilenversion von Anaconda installiert.
Für die Installationsmethode von Anaconda lesen Sie bitte den offiziellen Anleitungsbericht zu Anaconda:https://www.anaconda.com/distribution/.
Wenn Sie ein erfahrener Python-Programmierer sind und wenn Sie das Gefühl haben, dass Sie Anaconda nicht verwenden müssen, ist das überhaupt kein Problem. Ich nehme an, dass Sie keine Hilfe bei der Installation der notwendigen abhängigen Umgebung benötigen. Sie können diesen Abschnitt direkt überspringen.
Entwicklung einer Handelsstrategie
Die endgültige Ausgabe einer Handelsstrategie sollte folgende Fragen beantworten:
-
Richtungen: Feststellen, ob der Vermögenswert billig, teuer oder zum beizulegenden Zeitwert ist.
-
Eröffnungsbedingungen: Wenn der Vermögenswert billig oder teuer ist, sollten Sie Long oder Short gehen.
-
Schließungsposition Handel: Wenn der Vermögenswert einen angemessenen Preis hat und wir eine Position in dem Vermögenswert haben (vorheriger Kauf oder Verkauf), sollten Sie die Position schließen?
-
Preisbereich: der Preis (oder der Bereich), zu dem die Position eröffnet wurde.
-
Quantität: die Menge des gehandelten Geldes (z. B. die Menge der digitalen Währung oder die Anzahl der Lose von Rohstoff-Futures).
Maschinelles Lernen kann verwendet werden, um jede dieser Fragen zu beantworten, aber für den Rest dieses Artikels konzentrieren wir uns auf die erste Frage, die die Richtung des Handels ist.
Strategischer Ansatz
Es gibt zwei Arten von Ansätzen zur Konstruktion von Strategien: eine basiert auf Modellen; die andere basiert auf Data Mining.
Bei der modellbasierten Strategiekonstruktion beginnen wir mit dem Marktineffizienzmodell, bauen mathematische Ausdrücke (wie Preis und Gewinn) auf und testen ihre Wirksamkeit über einen langen Zeitraum. Dieses Modell ist in der Regel eine vereinfachte Version eines realen komplexen Modells und muss seine langfristige Bedeutung und Stabilität überprüfen.
Auf der anderen Seite suchen wir zuerst nach Preismustern und versuchen, Algorithmen in Datenmining-Methoden zu verwenden. Die Gründe für diese Muster sind nicht wichtig, da sich in Zukunft nur die identifizierten Muster wiederholen werden. Dies ist eine blinde Analysemethode und wir müssen streng überprüfen, um echte Muster aus zufälligen Mustern zu identifizieren.
Es ist offensichtlich, dass maschinelles Lernen sehr einfach auf Data-Mining-Methoden anzuwenden ist.
Das Codebeispiel verwendet ein Backtesting-Tool, das auf der FMZ Quant-Plattform und einer automatisierten Transaktions-API-Schnittstelle basiert. Nach dem Bereitstellen des Dockers und der Installation von Anaconda im obigen Abschnitt müssen Sie nur die benötigte Datenwissenschaftsanalysebibliothek und das berühmte Machine-Learning-Modell scikit-learn installieren.
pip install -U scikit-learn
Verwenden Sie maschinelles Lernen, um Handelsstrategie-Signale zu erstellen
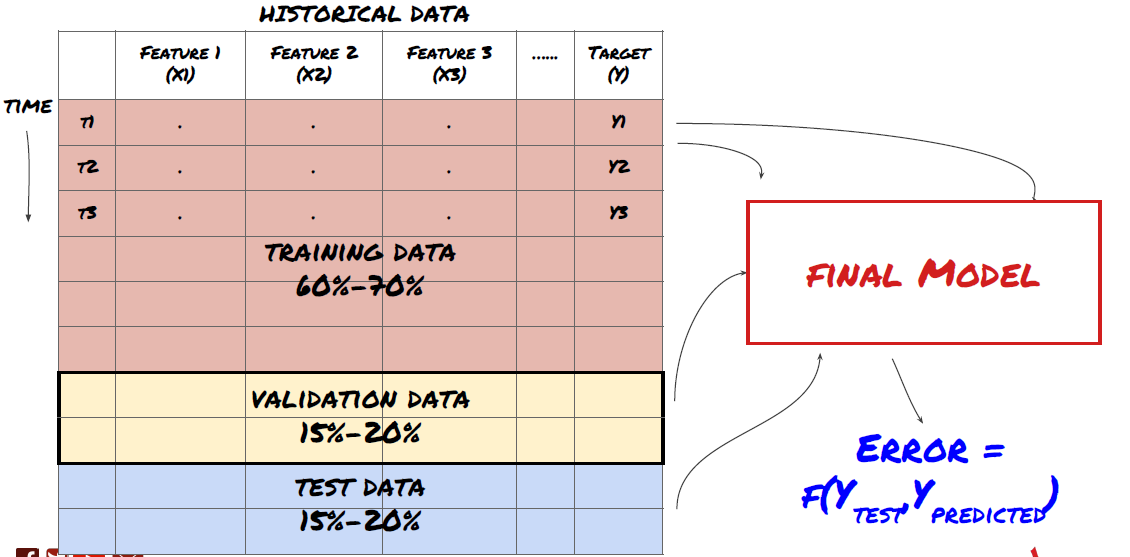
- Datenabbau Bevor wir beginnen, wird ein Standard-Maschinenlernproblemsystem in der folgenden Abbildung dargestellt:
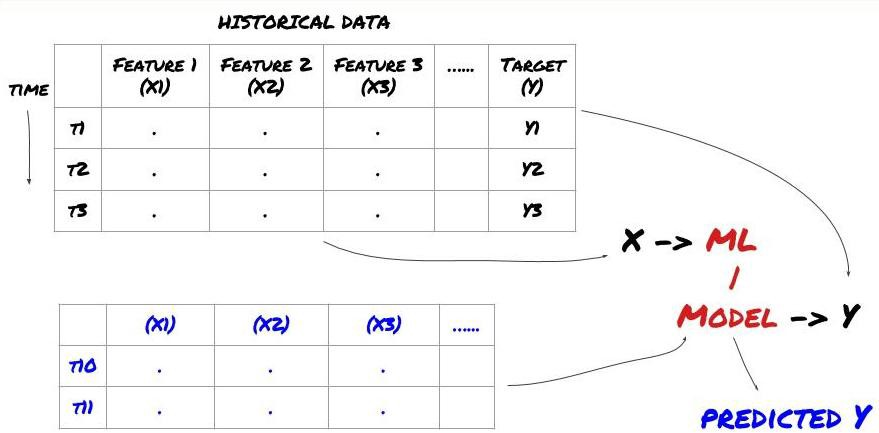
Maschinelles Lernproblemsystem
Die Funktion, die wir erstellen werden, muss eine gewisse Vorhersagekraft (X) haben. Wir wollen die Zielvariable (Y) vorhersagen und historische Daten verwenden, um das ML-Modell zu trainieren, das Y so nah wie möglich an den tatsächlichen Wert vorhersagen kann. Schließlich verwenden wir dieses Modell, um Vorhersagen zu machen, wenn Y unbekannt ist. Dies führt uns zum ersten Schritt:
Schritt 1: Stellen Sie Ihre Frage
- Was wollen Sie vorhersagen? Was ist eine gute Vorhersage? Wie bewerten Sie die Ergebnisse der Vorhersage?
Das heißt, in unserem obigen Rahmen, was ist Y?
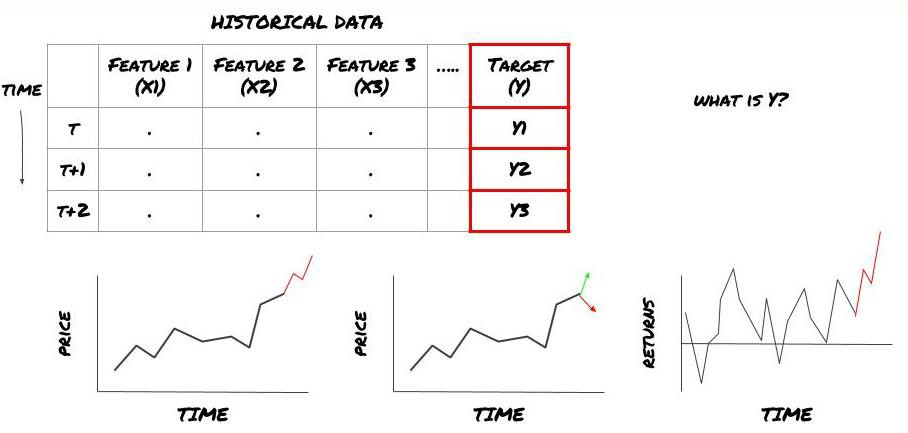
Was wollen Sie vorhersagen?
Möchten Sie zukünftige Preise, zukünftige Renditen/Pnl, Kauf-/Verkaufssignale vorhersagen, die Portfolioverteilung optimieren und versuchen, Transaktionen effizient auszuführen?
Nehmen wir an, wir versuchen, die Preise für den nächsten Zeitstempel vorherzusagen. In diesem Fall, Y (t) = Preis (t + 1). Jetzt können wir historische Daten verwenden, um unseren Rahmen zu vervollständigen.
Beachten Sie, dass Y (t) nur im Backtest bekannt ist, aber wenn wir unser Modell verwenden, werden wir den Preis (t + 1) der Zeit t nicht kennen. Wir verwenden unser Modell, um Y (vorhersagbar, t) vorherzusagen und vergleichen es mit dem tatsächlichen Wert nur zur Zeit t + 1. Dies bedeutet, dass Sie Y nicht als Merkmal im Vorhersagemodell verwenden können.
Sobald wir das Ziel Y kennen, können wir auch entscheiden, wie wir unsere Vorhersagen bewerten. Dies ist wichtig, um zwischen den verschiedenen Modellen der Daten zu unterscheiden, die wir ausprobieren werden. Wählen Sie einen Indikator aus, um die Effizienz unseres Modells entsprechend dem Problem, das wir lösen, zu messen. Zum Beispiel, wenn wir Preise vorhersagen, können wir den Quadratfehler des Mittelwertes als Indikator verwenden. Einige häufig verwendete Indikatoren (EMA, MACD, Varianzscore usw.) sind in der FMZ Quant-Toolbox vorkodiert. Sie können diese Indikatoren global über die API-Schnittstelle anrufen.
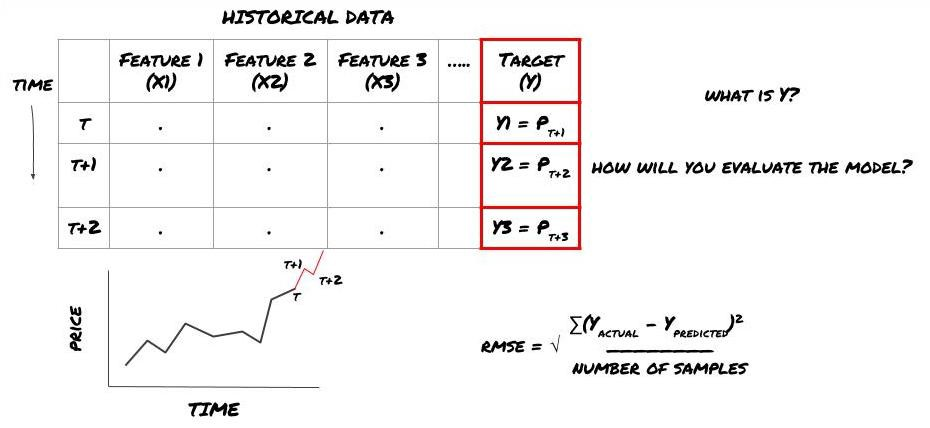
ML-Rahmen für die Vorhersage zukünftiger Preise
Zu Demonstrationszwecken erstellen wir ein Vorhersagemodell zur Vorhersage des erwarteten zukünftigen Benchmark- (Basis-) Wertes eines hypothetischen Anlageobjekts, wobei
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Da es sich um ein Regressionsproblem handelt, werden wir das Modell auf RMSE (Root mean square error) bewerten.
Hinweis: Bitte lesen Sie die Baidu Enzyklopädie für relevante mathematische Kenntnisse über RMSE.
- Unser Ziel: ein Modell zu erstellen, das den vorhergesagten Wert so nahe wie möglich an Y anpasst.
Schritt 2: Zuverlässige Daten sammeln
Sammeln und klären Sie Daten, die Ihnen helfen können, das Problem zu lösen.
Welche Daten müssen Sie berücksichtigen, um die Zielvariable Y vorherzusagen? Wenn wir den Preis vorhersagen, können Sie die Preisdaten des Anlageobjekts, die Handelsmengendaten des Anlageobjekts, die ähnlichen Daten des zugehörigen Anlageobjekts, den Indexwert des Anlageobjekts und andere Gesamtmarktindikatoren sowie den Preis anderer zugehöriger Vermögenswerte verwenden.
Sie müssen die Datenzugriffsberechtigungen für diese Daten festlegen und sicherstellen, dass Ihre Daten korrekt sind und die verlorenen Daten lösen (ein sehr häufiges Problem). Gleichzeitig müssen Sie sicherstellen, dass Ihre Daten unparteiisch und vollständig repräsentativ für alle Marktbedingungen sind (z. B. die gleiche Anzahl von Gewinn- und Verlustszenarien), um Verzerrungen im Modell zu vermeiden. Sie müssen möglicherweise auch die Daten bereinigen, um Dividenden, geteilte Anlageziele, Fortsetzungen usw. zu erhalten.
Wenn Sie die FMZ Quant-Plattform (FMZ. COM) verwenden, können wir auf kostenlose globale Daten von Google, Yahoo, NSE und Quandl zugreifen; Tiefendaten von inländischen Rohstoff-Futures wie CTP und Esunny; Daten von Mainstream-digitalen Währungsaustauschs wie Binance, OKX, Huobi und BitMex. Die FMZ Quant-Plattform reinigt und filtert auch diese Daten, wie die Aufteilung von Anlagezielen und detaillierte Marktdaten, und präsentiert sie Strategieentwicklern in einem Format, das für quantitative Praktiker leicht verständlich ist.
Um die Demonstration dieses Artikels zu erleichtern, verwenden wir folgende Daten als
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Mit dem obigen Code hat Auquan
Schritt 3: Daten aufteilen
- Erstellen Sie Trainingssets, kreuzverprüfen und testen Sie diese Datensätze aus Daten.
Das ist ein sehr wichtiger Schritt!Bevor wir fortfahren, sollten wir die Daten in Trainingsdatensätze aufteilen, um Ihr Modell zu trainieren; Testdatensätze, um die Leistung des Modells zu bewerten. Es wird empfohlen, sie in 60-70% Trainingssätze und 30-40% Testsätze aufzuteilen.
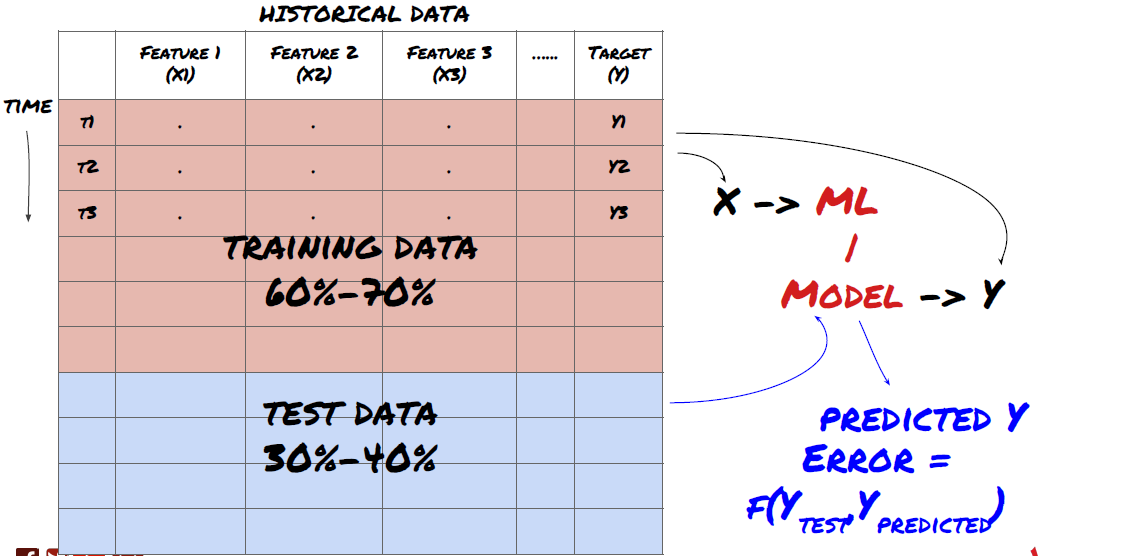
Aufteilung der Daten in Trainings- und Testsätze
Da Trainingsdaten zur Auswertung von Modellparametern verwendet werden, kann es sein, dass Ihr Modell diese Trainingsdaten übermäßig passt und die Trainingsdaten die Modellleistung irreführen können. Wenn Sie keine einzelnen Testdaten speichern und alle Daten für das Training verwenden, werden Sie nicht wissen, wie gut oder schlecht Ihr Modell auf den neuen unsichtbaren Daten funktioniert. Dies ist einer der Hauptgründe für das Scheitern des trainierten ML-Modells in Echtzeitdaten: Menschen trainieren alle verfügbaren Daten und sind von den Trainingsdatenindikatoren begeistert, aber das Modell kann keine sinnvolle Vorhersage über die nicht trainierten Echtzeitdaten machen.
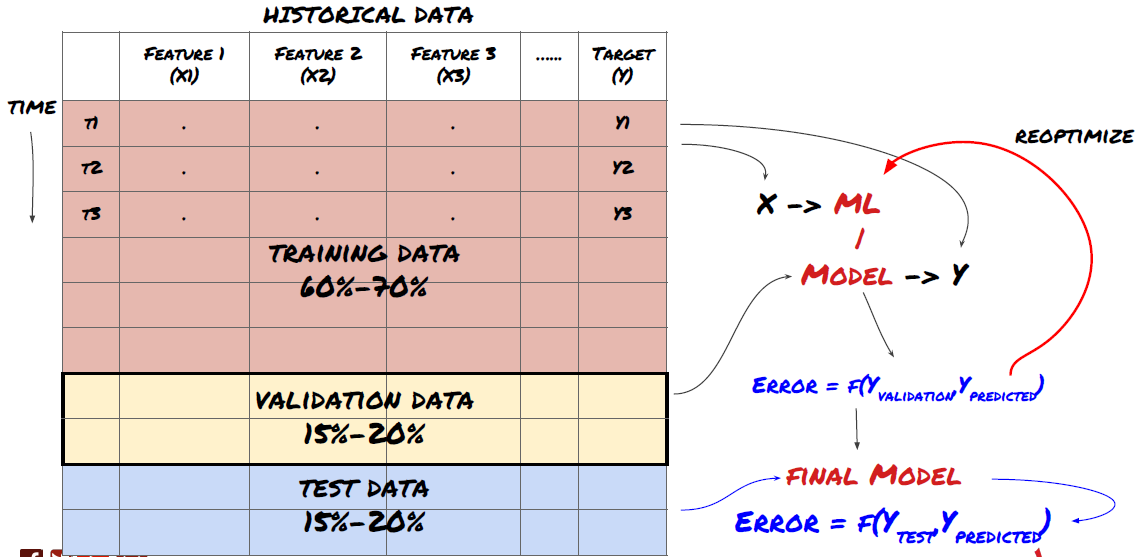
Aufteilung der Daten in Trainings-, Verifikations- und Testsätze
Es gibt Probleme mit dieser Methode. Wenn wir die Trainingsdaten wiederholt trainieren, die Leistung der Testdaten bewerten und unser Modell optimieren, bis wir mit der Leistung zufrieden sind, nehmen wir die Testdaten implizit als Teil der Trainingsdaten. Am Ende kann unser Modell auf diesem Satz von Trainings- und Testdaten gut funktionieren, aber es kann nicht garantieren, dass es neue Daten gut vorhersagen kann.
Um dieses Problem zu lösen, können wir einen separaten Validierungsdatensatz erstellen. Jetzt können Sie die Daten trainieren, die Leistung der Validierungsdaten bewerten, optimieren, bis Sie mit der Leistung zufrieden sind, und schließlich die Testdaten testen. Auf diese Weise werden die Testdaten nicht verschmutzt, und wir werden keine Informationen in den Testdaten verwenden, um unser Modell zu verbessern.
Denken Sie daran, sobald Sie die Leistung Ihrer Testdaten überprüft haben, gehen Sie nicht zurück und versuchen Sie, Ihr Modell weiter zu optimieren. Wenn Sie feststellen, dass Ihr Modell keine guten Ergebnisse liefert, werfen Sie das Modell vollständig weg und beginnen Sie noch einmal. Es wird vorgeschlagen, dass 60% der Trainingsdaten, 20% der Validierungsdaten und 20% der Testdaten aufgeteilt werden können.
Für unsere Frage haben wir drei verfügbare Datensätze. Wir verwenden einen als Trainings-Set, den zweiten als Verifizierungs-Set und den dritten als Test-Set.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Für jede dieser Werte addieren wir die Zielvariable Y, die als Durchschnitt der nächsten fünf Basiswerte definiert wird.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Schritt 4: Feature Engineering
Analysieren Sie das Datenverhalten und erstellen Sie prädiktive Funktionen
Nun hat der eigentliche Projektbau begonnen. Die goldene Regel der Feature-Auswahl ist, dass die Vorhersagekraft hauptsächlich von Features und nicht von Modellen kommt. Sie werden feststellen, dass die Auswahl von Features einen viel größeren Einfluss auf die Leistung hat als die Auswahl von Modellen. Einige Überlegungen zur Feature-Auswahl:
-
Wählen Sie nicht zufällig eine große Anzahl von Merkmalen aus, ohne die Beziehung zur Zielvariable zu untersuchen.
-
Eine geringe oder gar keine Beziehung zur Zielvariable kann zu einer Überanpassung führen.
-
Die von Ihnen ausgewählten Merkmale sind möglicherweise stark miteinander verwandt, wobei eine kleine Anzahl von Merkmalen auch das Ziel erklären kann.
-
Normalerweise erstelle ich einige intuitive Funktionen, überprüfe die Korrelation zwischen der Zielvariable und diesen Funktionen und die Korrelation zwischen ihnen, um zu entscheiden, welche zu verwenden ist.
-
Sie können auch versuchen, die Hauptkomponentenanalyse (PCA) und andere Methoden zur Sortierung der Kandidatenmerkmale nach dem maximalen Informationskoeffizienten (MIC) durchzuführen.
Merkmaltransformation/Normalisierung:
ML-Modelle sind in der Regel gut in Bezug auf die Normalisierung. Normalisierung ist jedoch schwierig, wenn es um Zeitreihendaten geht, da der zukünftige Datenbereich unbekannt ist. Ihre Daten können außerhalb des Normalisierungsbereichs liegen, was zu Modellfehlern führt. Aber Sie können immer noch versuchen, ein gewisses Maß an Stabilität zu erzwingen:
-
Skalierung: Teilen von Merkmalen nach Standardabweichung oder Quartilbereich.
-
Zentrierung: Der historische Durchschnittswert wird vom aktuellen Wert abgezogen.
-
Normalisierung: zwei rückwirkende Perioden der oben genannten (x-Mittelwert) /stdev.
-
Regelmäßige Normalisierung: Standardisierung der Daten in den Bereich von -1 bis +1 und Wiederbestimmung des Zentrums innerhalb der Rückverfolgungszeit (x-min) / ((max min).
Da wir historische kontinuierliche Durchschnittswerte, Standardabweichungen, Höchst- oder Mindestwerte über den Rückverfolgungszeitraum hinaus verwenden, stellt der normalisierte Standardisierungswert des Features zu verschiedenen Zeiten unterschiedliche tatsächliche Werte dar. Zum Beispiel, wenn der aktuelle Wert des Features 5 ist und der Durchschnittswert für 30 aufeinanderfolgende Perioden 4,5 ist, wird er nach der Zentrierung auf 0,5 umgewandelt. Danach, wenn der Durchschnittswert von 30 aufeinanderfolgende Perioden 3 wird, wird der Wert 3,5 0,5 werden. Dies kann die Ursache für das falsche Modell sein. Daher ist die Normalisierung schwierig und Sie müssen herausfinden, was die Leistung des Modells verbessert (wenn überhaupt).
Für die erste Iteration in unserem Problem haben wir eine große Anzahl von Features mit gemischten Parametern erstellt.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Schritt 5: Auswahl des Modells
Auswahl des geeigneten statistischen/ML-Modells nach den ausgewählten Fragen
Die Wahl des Modells hängt davon ab, wie das Problem gebildet wird. Lernen Sie überwacht (jeder Punkt X in der Merkmalmatrix wird an die Zielvariable Y abgegliedert) oder unbeaufsichtigt (ohne eine gegebene Abbildung versucht das Modell ein unbekanntes Muster zu erlernen)?

Unterricht unter Aufsicht oder ohne Aufsicht

Regression oder Klassifizierung
Einige gängige Algorithmen für überwachtes Lernen können Ihnen dabei helfen:
-
Lineare Regression (Parameter, Regression)
-
Logistische Regression (Parameter, Klassifizierung)
-
K-Nächster Nachbar (KNN) -Algorithmus (fallbasiert, Regression)
-
SVM, SVR (Parameter, Klassifizierung und Regression)
-
Entscheidungsbaum
-
Entscheidungswald
Ich schlage vor, mit einem einfachen Modell zu beginnen, wie z.B. einer linearen oder logistischen Regression, und von dort aus nach Bedarf komplexere Modelle zu erstellen.
Schritt 6: Schulung, Überprüfung und Optimierung (Schritte 4-6 wiederholen)
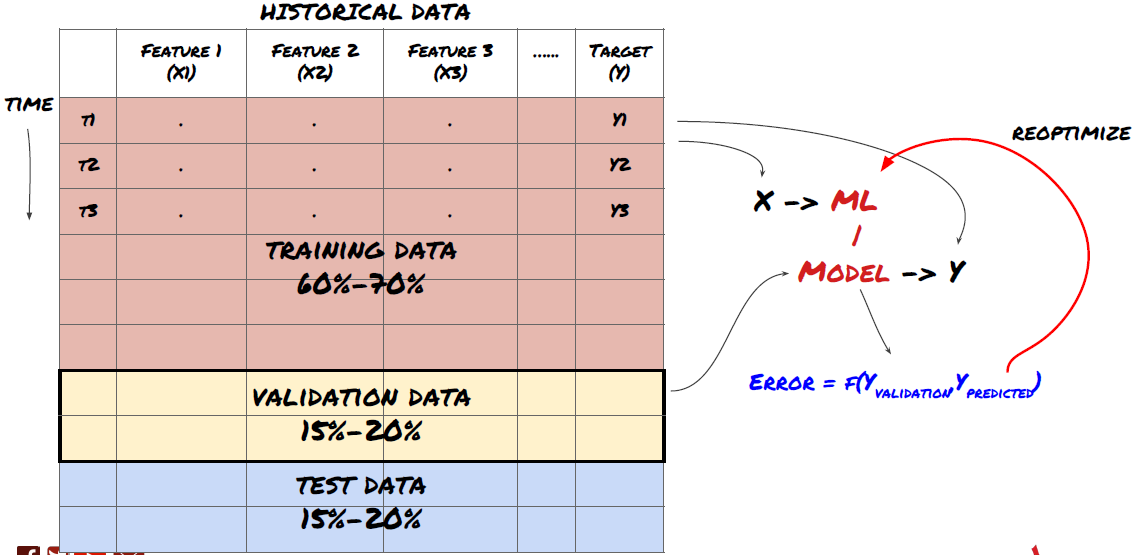
Verwenden Sie Trainings- und Verifizierungsdatenmengen, um Ihr Modell zu trainieren und zu optimieren
Jetzt sind Sie bereit, das Modell endgültig zu bauen. In dieser Phase wiederholen Sie einfach das Modell und die Modellparameter. Trainieren Sie Ihr Modell auf den Trainingsdaten, messen Sie seine Leistung auf den Verifizierungsdaten und geben Sie es dann zurück, optimieren, neu ausbilden und bewerten Sie es. Wenn Sie mit der Leistung des Modells nicht zufrieden sind, versuchen Sie bitte ein anderes Modell. Sie fahren viele Male durch diese Phase, bis Sie endlich ein Modell haben, mit dem Sie zufrieden sind.
Nur wenn Sie Ihr Lieblingsmodell haben, dann gehen Sie zum nächsten Schritt.
Für unser Demonstrationsproblem beginnen wir mit einer einfachen linearen Regression:
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
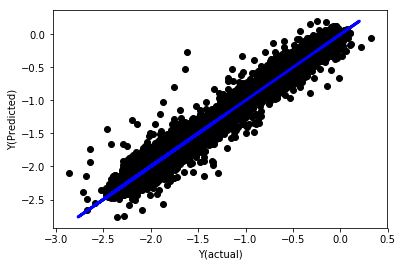
Lineare Regression ohne Normalisierung
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Schauen wir uns die Modellkoeffizienten an. Wir können sie nicht wirklich vergleichen oder sagen, welcher wichtig ist, weil sie alle zu verschiedenen Skalen gehören.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
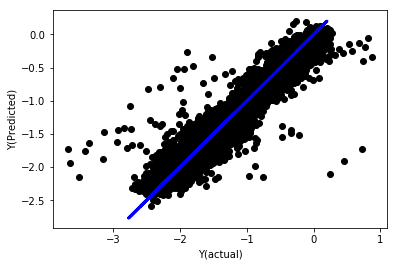
Lineare Regression mit Normalisierung
Mean squared error: 0.05
Variance score: 0.90
Das ist ein sehr schwieriges Problem, aber wir müssen uns darüber im klaren sein.
Schauen wir uns die Koeffizienten an:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Die Ergebnisse sind:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Wir können deutlich sehen, dass einige Merkmale höhere Koeffizienten haben als andere und sie können eine stärkere Vorhersagekraft haben.
Schauen wir uns die Korrelation zwischen den verschiedenen Merkmalen an.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
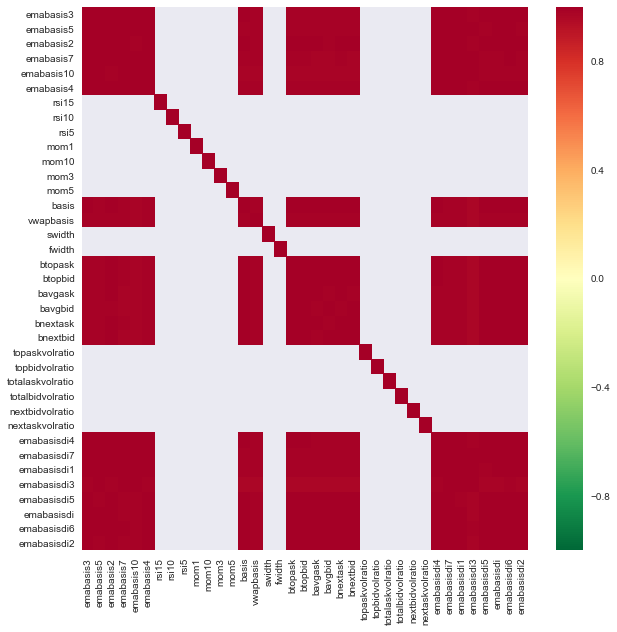
Korrelation zwischen Merkmalen
Die dunkelroten Bereiche repräsentieren stark korrelierte Variablen. Lassen Sie uns einige Merkmale neu erstellen/modifizieren und versuchen, unser Modell zu verbessern.
Zum Beispiel kann ich einfach Funktionen wie emabasisdi7 entsorgen, die nur lineare Kombinationen von anderen Funktionen sind.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
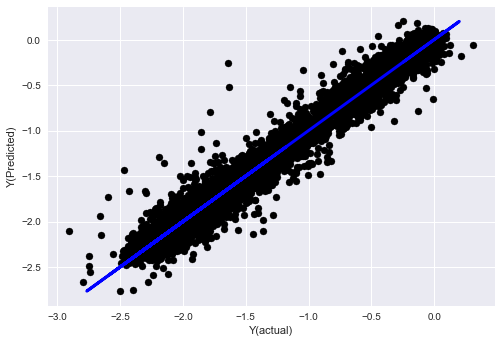
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Schauen Sie, die Leistung unseres Modells hat sich nicht geändert. Wir brauchen nur einige Eigenschaften, um unsere Zielvariablen zu erklären. Ich schlage vor, dass Sie mehr der oben genannten Funktionen ausprobieren, neue Kombinationen usw. ausprobieren, um zu sehen, was unser Modell verbessern kann.
Wir können auch komplexere Modelle ausprobieren, um zu sehen, ob Änderungen an Modellen die Leistung verbessern können.
- K-Nächster Nachbar (KNN) -Algorithmus
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Entscheidungsbaum
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
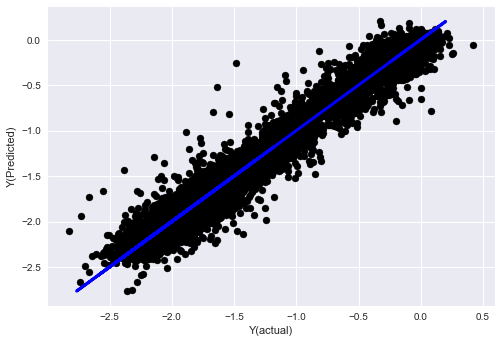
Schritt 7: Rückprüfung der Prüfdaten
Überprüfung der Leistung der tatsächlichen Probendaten
Backtestleistung auf (unberührten) Prüfdatenmengen
Wir führen unser endgültiges Optimierungsmodell aus dem letzten Schritt der Testdaten aus, wir legen es am Anfang beiseite und wir haben die Daten bisher nicht berührt.
Dies gibt Ihnen eine realistische Erwartung, wie Ihr Modell auf neuen und unsichtbaren Daten ausführt, wenn Sie mit dem Echtzeithandel beginnen. Daher ist es notwendig, sicherzustellen, dass Sie einen sauberen Datensatz haben, der nicht zum Trainieren oder Verifizieren des Modells verwendet wird.
Wenn Ihnen die Backtest-Ergebnisse der Testdaten nicht gefallen, entsorgen Sie das Modell und starten Sie erneut. Gehen Sie nie zurück oder optimieren Sie Ihr Modell erneut, was zu einer Überanpassung führen wird! (Es wird auch empfohlen, einen neuen Testdatensatz zu erstellen, da dieser Datensatz jetzt verschmutzt ist; wenn wir das Modell entsorgen, kennen wir bereits den Inhalt des Datensatzes implizit).
Hier werden wir weiterhin Auquan's Toolbox verwenden:
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
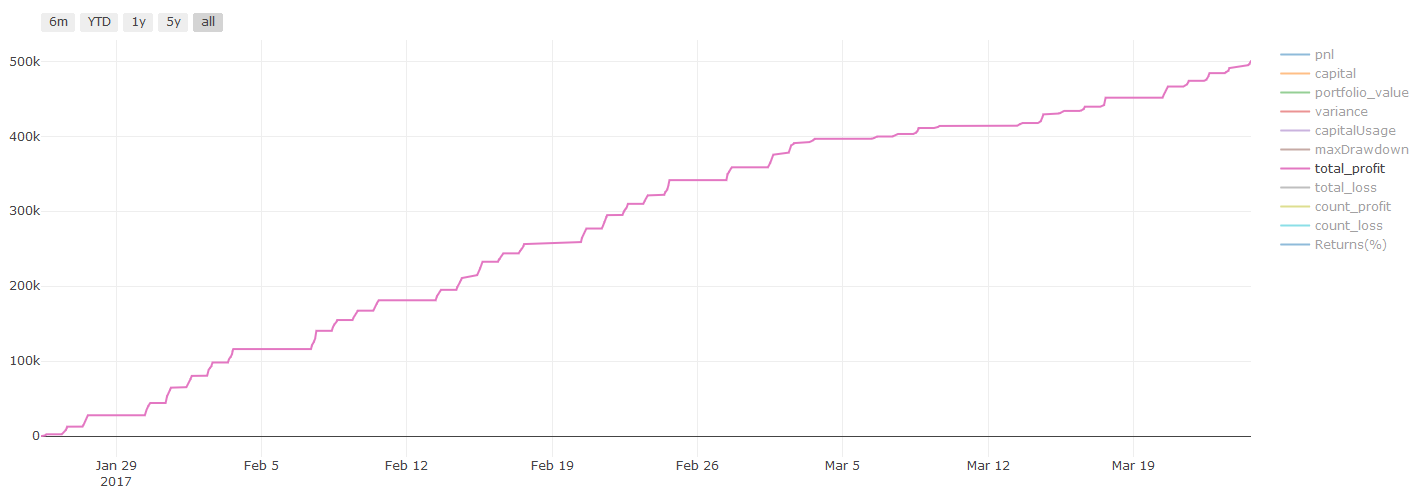
Ergebnisse des Backtests, Pnl wird in USD berechnet (Pnl ist nicht in Transaktionskosten und sonstigen Gebühren enthalten)
Schritt 8: Andere Methoden zur Verbesserung des Modells
Überprüfung des Rollens, Lernen der Satzungen, Verpackung und Steigerung
Zusätzlich zum Sammeln von mehr Daten, zur Erstellung besserer Funktionen oder zum Ausprobieren von mehr Modellen gibt es noch ein paar weitere Punkte, die Sie verbessern können.
1. Rolling-Überprüfung
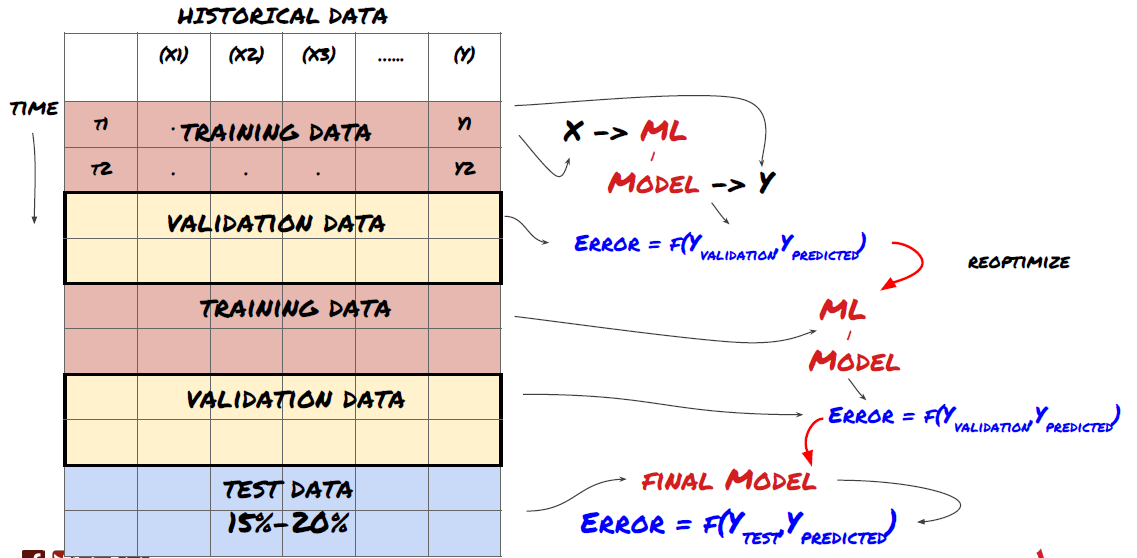
Rollprüfung
Die Marktbedingungen bleiben selten gleich. Angenommen, Sie haben Daten für ein Jahr und verwenden die Daten von Januar bis August für das Training und verwenden die Daten von September bis Dezember, um Ihr Modell zu testen. Sie können schließlich für eine sehr spezifische Reihe von Marktbedingungen trainieren. Vielleicht gab es keine Marktschwankungen in der ersten Jahreshälfte und einige extreme Nachrichten führten zu einem starken Anstieg des Marktes im September. Ihr Modell wird dieses Modell nicht lernen können und es wird Ihnen Müllprognosergebnisse bringen.
Es könnte besser sein, eine vorläufige Überprüfung zu versuchen, wie z. B. eine Ausbildung von Januar bis Februar, eine Überprüfung im März, eine Umschulung von April bis Mai, eine Überprüfung im Juni usw.
2. Lernen
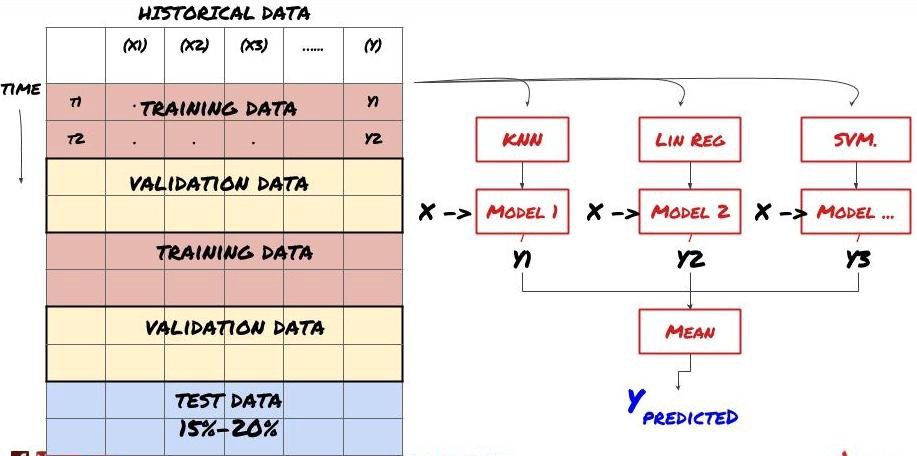
Set-Lernen
Einige Modelle können bei der Vorhersage bestimmter Szenarien sehr effektiv sein, während Modelle bei der Vorhersage anderer Szenarien oder unter bestimmten Umständen extrem übermäßig geeignet sein können. Eine Möglichkeit, Fehler und Überfitting zu reduzieren, besteht darin, eine Reihe von verschiedenen Modellen zu verwenden. Ihre Vorhersage wird der Durchschnitt der Vorhersagen sein, die von vielen Modellen gemacht wurden, und die Fehler verschiedener Modelle können kompensiert oder reduziert werden. Einige gängige Satzmethoden sind Bagging und Boosting.
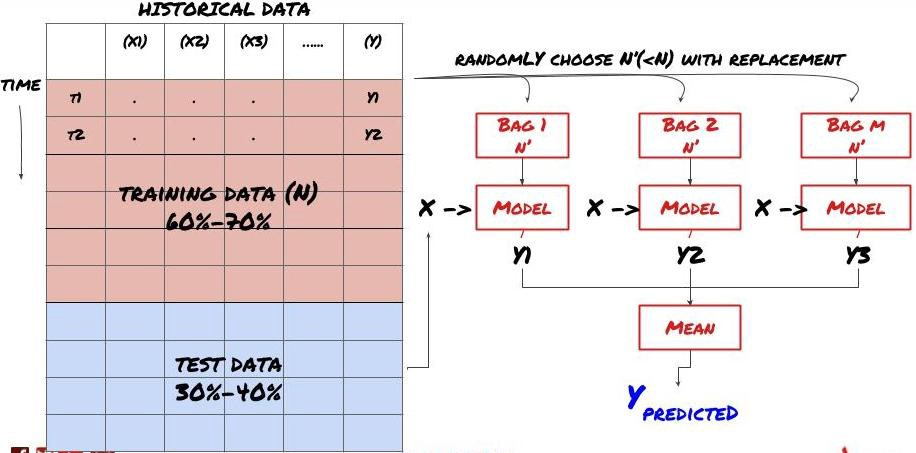
Verpackung
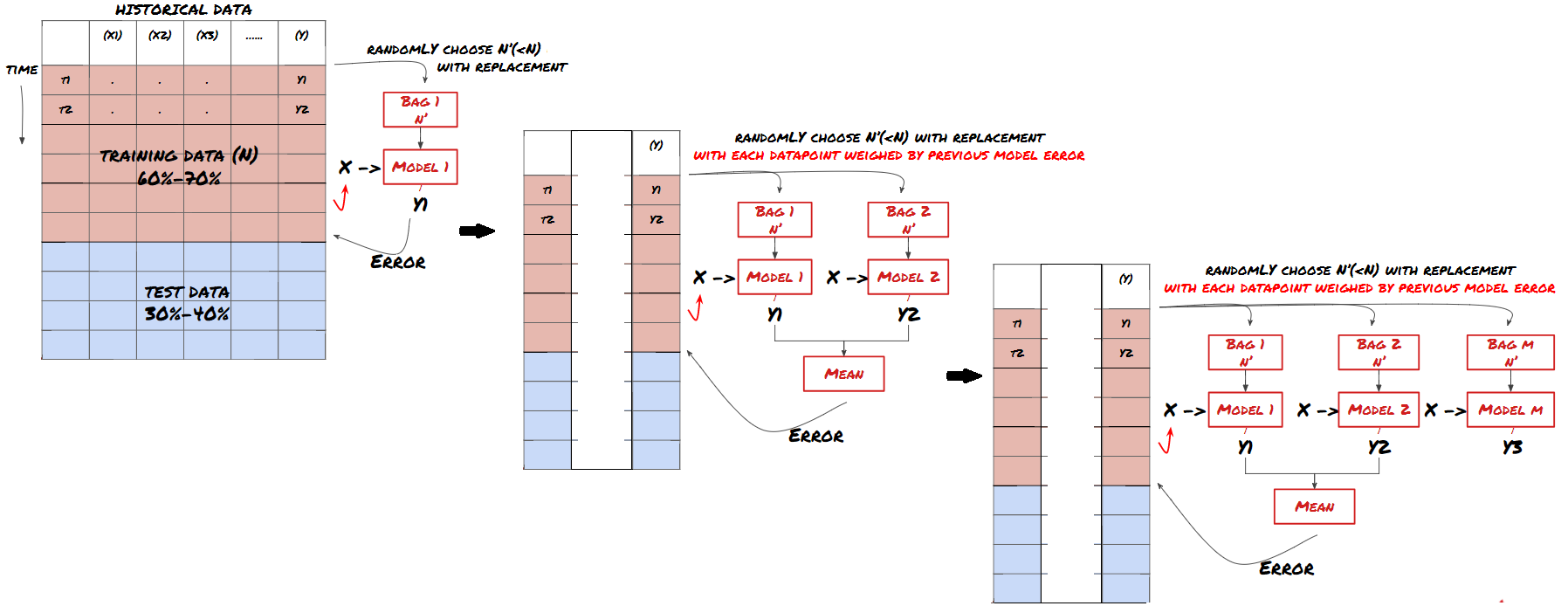
Erhöhung
Aus Gründen der Kürze werde ich diese Methoden überspringen, aber Sie können weitere Informationen online finden.
Versuchen wir eine Satzmethode für unser Problem:
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Wir haben bislang eine Menge Wissen und Informationen gesammelt.
-
Lösen Sie Ihr Problem.
-
Zuverlässige Daten sammeln und Daten bereinigen;
-
Aufteilung der Daten in Trainings-, Verifizierungs- und Testsätze;
-
Erstellen Sie Merkmale und analysieren Sie ihr Verhalten;
-
Auswahl eines geeigneten Trainingsmodells entsprechend dem Verhalten;
-
Nutzen Sie Trainingsdaten, um Ihr Modell zu trainieren und Vorhersagen zu treffen;
-
Überprüfung der Leistung des Verifizierungssatzes und erneute Optimierung;
-
Überprüfen Sie die endgültige Leistung des Prüfsatzes.
Aber es ist noch nicht vorbei. Sie haben nur ein zuverlässiges Vorhersagemodell.
-
Entwicklung von Signalen auf der Grundlage von Vorhersagemodellen zur Ermittlung von Handelsrichtungen;
-
Entwicklung spezifischer Strategien zur Ermittlung offener und geschlossener Positionen;
-
Ausführen des Systems zur Identifizierung von Positionen und Preisen.
Die oben genannten Unternehmen werden die FMZ Quant-Plattform verwenden (FMZ.COM) Auf der FMZ Quant Plattform gibt es hochkapselte und perfekte API-Schnittstellen sowie Bestell- und Handelsfunktionen, die global aufgerufen werden können. Sie müssen keine API-Schnittstellen verschiedener Börsen nacheinander verbinden und hinzufügen. Im Strategie-Feld der FMZ Quant-Plattform gibt es viele ausgereifte und perfekte alternative Strategien, die mit der Maschinellen Lernmethode in diesem Artikel übereinstimmen, es wird Ihre spezifische Strategie leistungsfähiger machen. Das Strategie-Feld befindet sich unter:https://www.fmz.com/square.
** Wichtige Anmerkung zu den Transaktionskosten: ** Ihr Modell wird Ihnen mitteilen, wann der ausgewählte Vermögenswert lang oder kurz geht. Es berücksichtigt jedoch keine Gebühren/Transaktionskosten/verfügbare Handelsmenge/Stop-Loss usw. Transaktionskosten verwandeln gewöhnlich profitable Transaktionen in Verluste. Zum Beispiel ist ein Vermögenswert mit einem erwarteten Preisanstieg von 0,05 USD ein Kauf, aber wenn Sie für diese Transaktion 0,10 USD zahlen müssen, erhalten Sie schließlich einen Nettoverlust von 0,05 USD. Nachdem Sie die Provision, die Wechselgebühr und die Punktdifferenz des Brokers berücksichtigt haben, sieht unser großes Gewinndiagramm oben so aus:
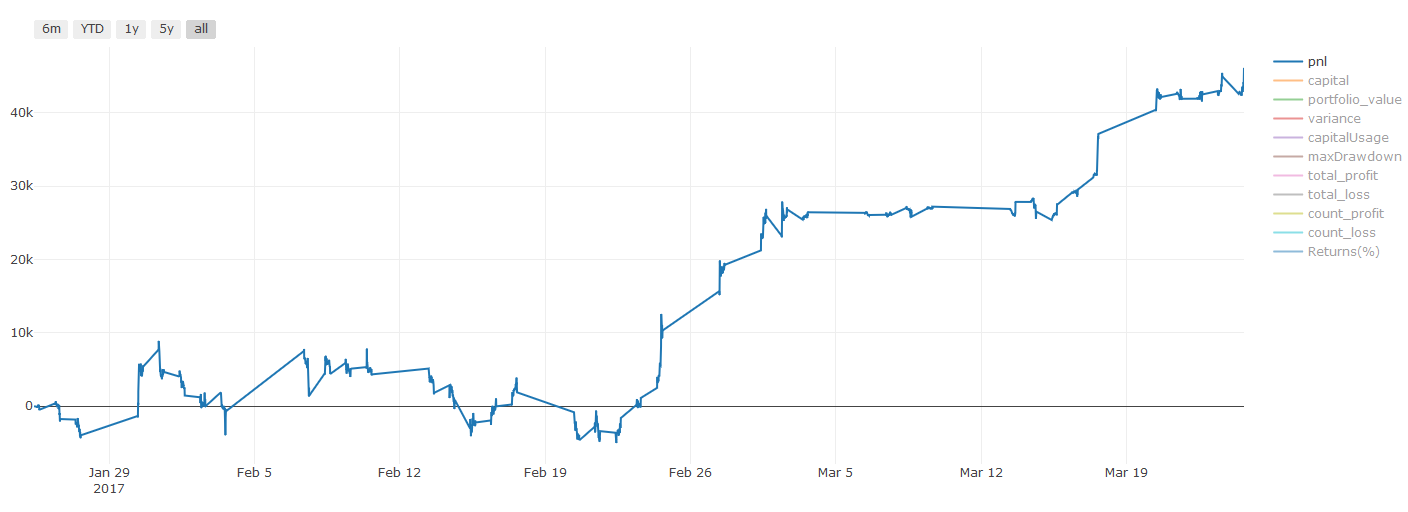
Das Backtestresultat nach Handelsgebühren und Punktdifferenz, Pnl, ist USD.
Transaktionsgebühren und Preisunterschiede machen mehr als 90% unseres PNL aus!
Schließlich wollen wir uns einige häufige Fallstricke ansehen.
Was tun und was nicht tun
-
Vermeide es, dich mit aller Kraft zu überanpassen!
-
Nicht nach jedem Datenpunkt neu trainieren: Dies ist ein häufiger Fehler, den Menschen bei der Entwicklung von maschinellem Lernen machen. Wenn Ihr Modell nach jedem Datenpunkt neu trainiert werden muss, ist es möglicherweise kein sehr gutes Modell. Das heißt, es muss regelmäßig neu trainiert werden und muss nur mit einer angemessenen Häufigkeit trainiert werden (z. B. wenn eine Vorhersage innerhalb eines Tages gemacht wird, muss es am Ende jeder Woche neu trainiert werden).
-
Vermeiden Sie Verzerrungen, insbesondere zukunftsgerichtete Verzerrungen: Dies ist ein weiterer Grund, warum das Modell nicht funktioniert, und stellen Sie sicher, dass Sie keine zukünftigen Informationen verwenden. In den meisten Fällen bedeutet dies, dass die Zielvariable Y nicht als Feature im Modell verwendet wird. Sie können sie während des Backtests verwenden, aber sie wird nicht verfügbar sein, wenn Sie das Modell tatsächlich ausführen, was Ihr Modell unbrauchbar macht.
-
Achten Sie auf Datenmining-Vorurteile: Da wir versuchen, eine Reihe von Modellierungen auf unseren Daten durchzuführen, um festzustellen, ob dies angemessen ist, stellen Sie bitte sicher, dass Sie strenge Tests durchführen, um den zufälligen Modus von dem tatsächlichen Modus zu trennen, der auftreten kann.
Vermeiden Sie eine Überanpassung.
Das ist sehr wichtig, und ich halte es für notwendig, es noch einmal zu erwähnen.
-
Überanpassung ist die gefährlichste Falle in Handelsstrategien;
-
Ein komplexer Algorithmus kann im Backtest sehr gut abschneiden, aber er versagt mißbräuchlich bei den neuen unsichtbaren Daten. Dieser Algorithmus enthüllt nicht wirklich einen Trend der Daten, noch hat er echte Vorhersagekraft. Er eignet sich sehr gut für die Daten, die er sieht;
-
Wenn Sie feststellen, dass Sie viele komplexe Funktionen benötigen, um Daten zu interpretieren, können Sie überanpassen;
-
Teilen Sie Ihre verfügbaren Daten in Schulungs- und Testdaten auf und überprüfen Sie immer die Leistung realer Probendaten, bevor Sie das Modell für Echtzeittransaktionen verwenden.
- Quantifizierung der Fundamentalanalyse auf dem Kryptowährungsmarkt: Die Daten sprechen für sich!
- Die Quantifizierung der Kernforschung der Münzkreise - nicht mehr auf alle Arten von Lehrern zu vertrauen, die überzeugt sind, dass die Daten objektiv sind!
- Ein wichtiges Werkzeug im Bereich der Quantitative Transaktionen - der Erfinder der Quantitative Data Exploration Module
- Mastering Everything - Einführung in FMZ Neue Version des Handelsterminals (mit TRB Arbitrage Source Code)
- Die neue Version des FMZ-Trading-Terminals ist verfügbar.
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (II)
- Wie man Hirnlose Verkaufs-Bots mit einer Hochfrequenz-Strategie in 80 Codezeilen ausnutzt
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt (II)
- Wie man Hirnlose Roboter ausbeuten und verkaufen kann mit einer 80-Zeilen-code-Hochfrequenz-Strategie
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (I)
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt