Comparación de 8 algoritmos de aprendizaje automático
 0
6946
0
6946
Comparación de 8 algoritmos de aprendizaje automático
Este artículo se centra en los siguientes escenarios de adaptación de algoritmos de uso común y sus ventajas y desventajas.
Hay demasiados algoritmos de aprendizaje automático, clasificación, regresión, agrupación, recomendación, reconocimiento de imágenes, etc., que no es fácil encontrar un algoritmo adecuado, por lo que en la práctica, generalmente experimentamos con el aprendizaje iluminado.
Por lo general, al principio elegimos los algoritmos con los que todos estamos de acuerdo, como SVM, GBDT, Adaboost, y ahora que el aprendizaje profundo está en auge, las redes neuronales también son una buena opción.
Si te preocupa la precisión, la mejor manera de hacerlo es mediante la validación cruzada, donde se prueba cada algoritmo uno por uno, se hacen comparaciones, se ajustan los parámetros para asegurar que cada algoritmo alcance la solución óptima y finalmente se selecciona el mejor.
Pero si solo buscas un algoritmo que sea lo suficientemente bueno para resolver tu problema, o si tienes algunos consejos que puedes usar, analizaremos los pros y los contras de cada uno de ellos para que sea más fácil para nosotros elegirlo.
- ## Divergencia y diferencia
En estadística, un modelo es bueno o malo, y se mide en base a la diferencia y la diferencia, así que vamos a generalizar la diferencia y la diferencia:
Desviación: Describe la diferencia entre el valor esperado de E y el valor real de Y de los valores de predicción (valor estimado). Cuanto mayor es la desviación, más se desvía de los datos reales.
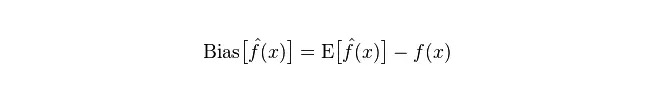
Diferencia: describe el rango de variación del valor de predicción P, el grado de dispersión, es la diferencia del valor de predicción, es decir, la distancia de su valor esperado E. Cuanto mayor es la diferencia, más dispersa es la distribución de los datos.
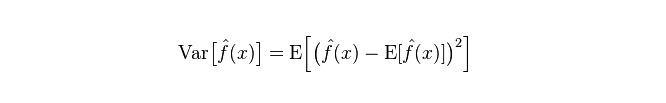
El error real del modelo es la suma de ambos, como se muestra a continuación:
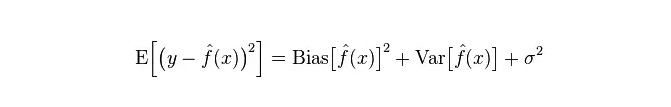
Si se trata de un conjunto de entrenamiento pequeño, el clasificador de alta desviación/baja diferencia (por ejemplo, el simple Bayesian NB) tiene una gran ventaja sobre la clasificación de baja desviación/alta diferencia (por ejemplo, KNN), ya que la última se adapta demasiado.
Sin embargo, a medida que tu conjunto de entrenamiento crece, los modelos son mejores para predecir los datos originales, y la desviación disminuye, y los clasificadores de baja desviación/alta desviación gradualmente muestran su ventaja (ya que tienen un menor error de aproximación), y los clasificadores de alta desviación ya no son suficientes para proporcionar un modelo preciso.
Por supuesto, también se puede considerar que es una diferencia entre el modelo de generación (NB) y el modelo de determinación (KNN).
- ## ¿Por qué la simplicidad de Bayes es alta y baja?
El siguiente es un extracto:
En primer lugar, supongamos que usted conoce la relación entre el conjunto de entrenamiento y el conjunto de prueba. En pocas palabras, vamos a aprender un modelo en el conjunto de entrenamiento, y luego obtener el conjunto de prueba para usarlo.
Pero muchas veces, solo podemos asumir que el conjunto de pruebas y el conjunto de entrenamiento coinciden con la misma distribución de datos, pero no obtenemos los datos de prueba reales. ¿Por qué medir el error de prueba con solo ver la tasa de error de entrenamiento?
Debido a que las muestras de entrenamiento son pocas (o al menos no son suficientes), el modelo obtenido a través de la recopilación de entrenamiento no siempre es realmente correcto. Incluso si la tasa de corrección en el conjunto de entrenamiento es del 100%, no se puede decir que traza una distribución de datos real. Nuestro objetivo es saber cómo trazar una distribución de datos real, y no solo trazar los puntos de datos limitados del conjunto de entrenamiento.
Además, en la práctica, las muestras de entrenamiento suelen tener cierta cantidad de error de ruido, por lo que si se busca demasiado la perfección en el conjunto de entrenamiento y se adopta un modelo muy complejo, el modelo tomará todos los errores dentro del conjunto de entrenamiento como características de distribución de datos reales, lo que dará una estimación de distribución de datos errónea.
En este caso, en el conjunto de pruebas reales, el error es muy confuso (este fenómeno se llama adecuación). Sin embargo, no se puede usar un modelo demasiado simple, de lo contrario, cuando la distribución de los datos es más compleja, el modelo no es suficiente para representar la distribución de los datos (que se traduce en una alta tasa de error incluso en el conjunto de entrenamiento, este fenómeno es menos adecuado).
El exceso de ajuste indica que el modelo adoptado es más complejo que la distribución de datos real, mientras que el defecto de ajuste indica que el modelo adoptado es más simple que la distribución de datos real.
En el marco del aprendizaje estadístico, cuando se traza la complejidad de un modelo, existe la idea de que Error = Bias + Variance. El Error aquí se puede entender como el error de predicción del modelo, y se compone de dos partes, una parte es la inexactitud de la estimación debido a que el modelo es demasiado simple (Bias), y la otra parte es el mayor espacio de variación e incertidumbre debido a que el modelo es demasiado complejo (Variance).
Por lo tanto, es fácil analizar un simple Bayes. Su simple hipótesis de que los datos son irrelevantes es un modelo muy simplificado. Por lo tanto, para un modelo tan simple, en la mayoría de los casos, la parte de Bias será mayor que la parte de Variance, es decir, con un alto desviación y una baja diferencia.
En la práctica, para minimizar el error, necesitamos equilibrar la proporción de Bias y Variance en la elección del modelo, es decir, equilibrar el sobre-ajuste y el bajo-ajuste.
La relación entre la desviación y la diferencia cuadrada y la complejidad del modelo es más clara en el siguiente gráfico:
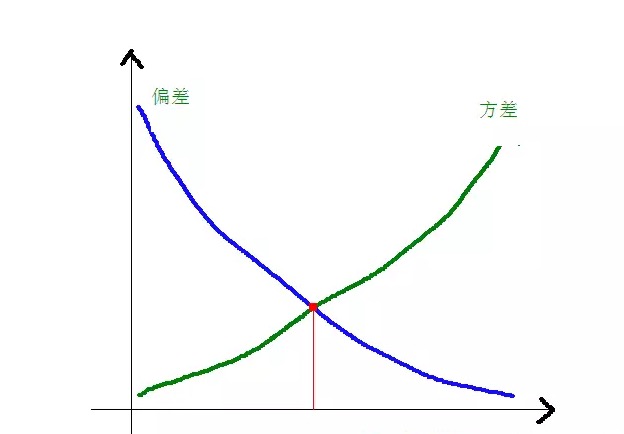
A medida que la complejidad del modelo aumenta, la desviación se reduce y la diferencia se agranda.
-
Ventajas y desventajas de los algoritmos comunes
- ### 1. La inocencia de Bayes
El simple Bayesianismo pertenece a los modelos generativos (sobre los modelos generativos y los modelos discriminativos, principalmente sobre si se requiere una distribución conjunta), es muy simple, simplemente haces un montón de cálculos.
Si se aplica la hipótesis de independencia condicional ((una condición más estricta), el clasificador Bayesiano sencillo tendrá una velocidad de convergencia más rápida que el modelo de discernimiento, como la regresión lógica, por lo que solo se necesitan menos datos de entrenamiento. Incluso si la hipótesis de independencia condicional de la NB no es válida, la clasificación NB sigue funcionando muy bien en la práctica.
Su principal desventaja es que no puede aprender la interacción entre los personajes, y el R en mRMR es la redundancia de los personajes. Para citar un ejemplo más clásico, por ejemplo, aunque te gusta la película de Brad Pitt y Tom Cruise, no puede aprender que no te gusta la película en la que están juntos.
Las ventajas:
El modelo simplista de Bayes surge de la teoría matemática clásica, tiene una base matemática sólida y una eficiencia de clasificación estable. El rendimiento es bueno para datos a pequeña escala, puede manejar tareas de varios tipos por separado y es adecuado para el entrenamiento incremental. El algoritmo es más sencillo y no es tan sensible a la falta de datos, por lo que suele usarse para clasificar textos. Desventajas:
Se necesita calcular la probabilidad previa. La tasa de error en las decisiones de clasificación; Es sensible a la forma de expresión de los datos de entrada.
- ### 2. Regresión lógica
En un modelo discriminativo, hay muchas formas de regular el modelo (L0, L1, L2, etc.) y no tienes que preocuparte por si tus características son relevantes como si estuvieras usando un simple Bayes.
También obtienes una buena interpretación de la probabilidad en comparación con el árbol de decisión y la máquina SVM, e incluso puedes actualizar el modelo fácilmente con los nuevos datos (con el algoritmo de descenso de gradiente en línea).
Si necesitas una estructura de probabilidad (por ejemplo, simplemente para ajustar los umbrales de clasificación, señalar incertidumbres o obtener intervalos de confianza) o si deseas integrar más datos de entrenamiento rápidamente en el modelo en el futuro, entonces úsalo.
La función sigmoide:
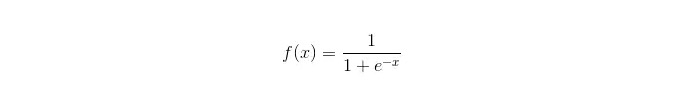
Las ventajas: La simplicidad y amplitud de su aplicación en cuestiones industriales; El proceso de clasificación es muy pequeño, rápido y con pocos recursos de almacenamiento. Los puntos de probabilidad de las muestras de observación facilitadas; Para la regresión lógica, la covalencia múltiple no es un problema, que se puede resolver en combinación con la regularización L2; Desventajas: La regresión lógica no funciona bien cuando el espacio de caracteres es grande. Falta de ajuste, suele tener poca precisión No puede manejar muy bien una gran cantidad de características o variables múltiples. solo puede tratar dos problemas de clasificación (softmax, derivado de esta base, puede usarse para múltiples clasificaciones) y debe ser linealmente separable; Para las características no lineales, se necesita una conversión.
- ### Regresión lineal
La regresión lineal se usa para la regresión, no como la regresión logística se usa para la clasificación, y su idea básica es optimizar las funciones de error en forma de menor bimetálica con la regresión de gradiente, y, por supuesto, también se puede obtener la solución de los parámetros directamente con la ecuación normal, resultando en:
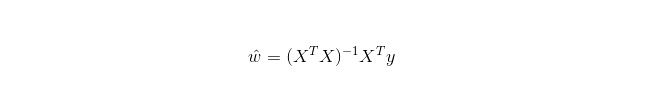
En LWLR, la expresión de cálculo de los parámetros es:
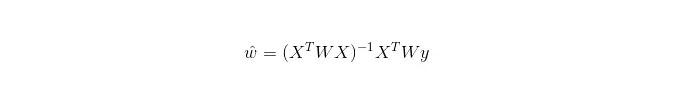
De esta manera, se puede ver que la LWLR es diferente a la LR, ya que es un modelo no paramétrico, ya que cada cálculo de regresión debe recorrer la muestra de entrenamiento al menos una vez.
Ventajas: Es fácil de implementar y de calcular.
Desventajas: No se puede ajustar a datos no lineales.
- ### 4. El algoritmo de vecindad más cercana KNN
KNN es el algoritmo de vecindad más cercana, cuyo proceso principal es:
Calcular la distancia de cada punto de muestra en la muestra de entrenamiento y la muestra de prueba (las medidas de distancia más comunes son la distancia europea, la distancia de Mares, etc.)
Sortar todos los valores de distancia de arriba;
Las muestras de k distancias mínimas antes de la selección;
La clasificación final se obtiene mediante una votación basada en las etiquetas de los k ejemplares;
Cómo elegir un valor de K óptimo depende de los datos. En general, un valor de K más grande en la clasificación puede reducir el impacto del ruido, pero puede hacer que los límites entre las categorías se vuelvan más difusos.
Un mejor valor de K se obtiene a través de diversas técnicas de iluminación, como la verificación cruzada. Además, la presencia de un vector de características de ruido y no correlación reduce la precisión de los algoritmos de vecindad cercana de K.
Los algoritmos de cercanía tienen resultados de gran consistencia. A medida que los datos se acercan al infinito, el algoritmo garantiza que la tasa de error no exceda el doble de la tasa de error del algoritmo de Bayes. Para algunos buenos valores de K, el algoritmo de cercanía garantiza que la tasa de error no exceda la tasa de error de Bayes.
Ventajas del algoritmo KNN
Las teorías son maduras, las ideas son simples, y pueden ser usadas tanto para clasificar como para regresar. Se puede usar para clasificar de manera no lineal. La complejidad del tiempo de entrenamiento es O (n); No hay suposiciones en los datos, tienen una alta precisión y no son sensibles a los outliers. defecto
Es una gran cantidad de cálculo. El problema del desequilibrio de muestras (es decir, hay muchas muestras en algunas categorías y pocas en otras). El problema es que la memoria es muy pesada.
- ### 5. Árboles de decisión
Es fácil de explicar. Puede tratar las interacciones entre las características sin estrés y es no parametrizado, por lo que no tiene que preocuparse por si los valores excepcionales o los datos son linealmente separables (por ejemplo, el árbol de decisión puede manejar fácilmente la categoría A en el extremo de una dimensión de la característica x, la categoría B en el medio, y luego la categoría A en el extremo anterior de la dimensión de la característica x).
Uno de sus inconvenientes es que no soporta el aprendizaje en línea, por lo que el árbol de decisión debe ser reconstruido completamente cuando llegan nuevos ejemplares.
Otra desventaja es la posibilidad de que se produzca una sobreadaptación, pero también es el punto de partida para métodos de integración como RF de bosques aleatorios (o elevar árboles impulsados).
Además, los bosques aleatorios a menudo son los ganadores de muchos problemas de clasificación (por lo general, un poco más que las máquinas de soporte de vectores), se entrenan rápidamente y son ajustables, y no tienes que preocuparte por ajustar una gran cantidad de parámetros como las máquinas de soporte de vectores, por lo que siempre han sido muy populares.
Un punto importante en el árbol de decisión es elegir un atributo para ramificar, por lo que es importante prestar atención a la fórmula de cálculo de la ganancia de información y entenderla en profundidad.
La fórmula de cálculo de la barra de información es la siguiente:
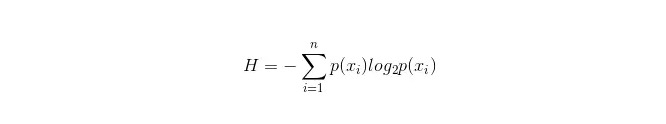
Donde n representa que hay n categorías de clasificación ((supongamos que se trata de una pregunta de clase 2, entonces n = 2). Calcule la probabilidad de que aparezcan estas dos clases de muestras en la muestra total, p1 y p2, respectivamente, para calcular la información anterior a la ramificación de las propiedades no seleccionadas.
Ahora se selecciona un atributo xixi para la ramificación, en este momento la regla de ramificación es: si xi = vxi = v, divide la muestra en una rama del árbol; si no es igual, entre en la otra rama.
Es evidente que la muestra de ramificaciones puede incluir dos categorías, calcular las subdivisiones H1 y H2 de las dos ramificaciones, calcular la suma de las subdivisiones H = p1 H1 + p2 H2 y el aumento de información ΔH = H - H. Tener el aumento de información como principio, probar todas las propiedades a un lado y elegir una de las propiedades con el mayor aumento como la propiedad de la ramificación.
Las ventajas de los árboles de decisión
Las estadísticas son simples, fáciles de entender y de interpretar. comparar las muestras más adecuadas para el tratamiento de los atributos perdidos; La capacidad de procesar características irrelevantes; La capacidad de obtener resultados viables y eficaces en fuentes de datos grandes en un tiempo relativamente corto. defecto
La adaptación es más fácil (los bosques aleatorios pueden reducir la adaptación en gran medida). La correlación entre los datos es ignorada. Para aquellos datos en los que el número de muestras de las diferentes categorías no es consistente, en los árboles de decisión, los resultados del aumento de la información se prefieren a los que tienen características de mayor valor (siempre que se utilice el aumento de la información, hay esta desventaja, como RF).
- ### 5.1 Adaboosting
Adaboost es un modelo de suma, cada modelo se basa en la tasa de error del modelo anterior, centrándose demasiado en las muestras que se equivocan, y menos en las muestras clasificadas correctamente, y después de una serie de repeticiones, se obtiene un modelo relativamente mejor. Es un algoritmo de boosting típico.
ventaja
Adaboost es un clasificador de alta precisión. Se puede construir un subclasificador usando varios métodos, el algoritmo de Adaboost proporciona el marco. Cuando se usa un clasificador simple, los resultados calculados son comprensibles, y la construcción de un clasificador débil es extremadamente simple. Es fácil, no hay que hacer un filtro de características. No es fácil que ocurra el overfitting. En cuanto a los algoritmos combinados como los bosques aleatorios y GBDT, consulte este artículo: Aprendizaje automático - Resumen de los algoritmos combinados
Desventajas: Sensibilidad al outlier
- ### 6. Máquinas vectoriales compatibles con el SVM
La alta precisión proporciona una buena garantía teórica para evitar la sobreadaptación, y funciona muy bien incluso si los datos son linealmente indivisibles en el espacio de las características originales, siempre y cuando se le dé una función nuclear adecuada.
Es especialmente popular en los problemas de clasificación de texto de alta dimensión. Desafortunadamente, consume mucha memoria, es difícil de interpretar, y el funcionamiento y la citación son molestos, mientras que el bosque aleatorio evita estos inconvenientes y es más práctico.
ventaja En la actualidad, el uso de la tecnología de la computación en la informática es muy popular en los Estados Unidos. La interacción de las características no lineales; No hay que depender de todos los datos. El objetivo de este proyecto es mejorar la generalización.
defecto La eficiencia no es muy alta cuando se observan muchas muestras. No hay una solución universal para el problema de la no linealidad, y a veces es difícil encontrar una función nuclear adecuada. Sensibilidad por la falta de datos. La selección de núcleos también es hábil (libsvm tiene cuatro funciones de núcleo propias: núcleo lineal, núcleo polifuncional, RBF y núcleo sigmoide):
En primer lugar, si el número de muestras es menor que el número de características, no hay necesidad de elegir un núcleo no lineal, simplemente se puede usar un núcleo lineal.
En segundo lugar, si el número de muestras es mayor que el número de características, se puede usar un núcleo no lineal para mapear las muestras a dimensiones más altas, lo que generalmente da mejores resultados.
En tercer lugar, si el número de muestras y el número de características son iguales, se puede usar un núcleo no lineal, el principio es el mismo que en el segundo caso.
Para el primer caso, también se puede reducir la dimensión de los datos y luego usar el núcleo no lineal, que también es un método.
- ### 7. Las ventajas y desventajas de las redes neuronales artificiales
Las ventajas de las redes neuronales artificiales: La clasificación es muy precisa. La tecnología de procesamiento distribuido en paralelo, el almacenamiento distribuido y el aprendizaje son muy potentes. Tiene una gran robustez y capacidad de tolerancia a los nervios del ruido, lo que le permite aproximarse a las relaciones no lineales complejas. Tiene la función de recordar.
Las redes neuronales artificiales tienen sus desventajas: Las redes neuronales requieren una gran cantidad de parámetros, como la estructura de la topografía de la red, los valores de ponderación y los valores iniciales de los umbrales. La imposibilidad de observar los procesos de aprendizaje entre sí y la dificultad para interpretar los resultados de la salida, lo que afecta la credibilidad y aceptabilidad de los resultados; El tiempo de estudio es demasiado largo y puede no alcanzar el objetivo de estudio.
- ### 8 K-Means agrupación
En un artículo anterior sobre la agrupación de K-Means, el algoritmo de aprendizaje automático K-means agrupación.
ventaja El algoritmo es simple y fácil de implementar. Para el tratamiento de grandes conjuntos de datos, el algoritmo es relativamente escalable y eficiente, ya que su complejidad es de aproximadamente O{\displaystyle O} nkt, donde n es el número de todos los objetos, k es el número de columnas, y t es el número de repeticiones. Por lo general, k<]]. El algoritmo suele ser localmente convergente. El algoritmo trata de encontrar la división k que permita el menor valor de la función de error cuadrado. La agrupación es mejor cuando el aluminio es denso, esférico o globular, y la diferencia entre aluminio y aluminio es evidente.
defecto Requisitos de tipo de datos más altos para datos de tipo numérico; Es posible que haya una convergencia mínima local, pero es más lenta en datos a gran escala. Los valores de K son más difíciles de obtener. Es sensible a los valores de foco iniciales, y puede dar lugar a resultados de agrupación diferentes para diferentes valores iniciales; No es adecuado para el descubrimiento de la forma no convexa de la cara, o de gran diferencia de tamaño. Para los datos sensibles a las vallas de ruido y los puntos aislados, una pequeña cantidad de estos datos puede tener un gran impacto en el promedio.
Selección de referencias por algoritmo
En un artículo que ya había traducido desde el extranjero, se ofreció una sencilla guía para elegir un algoritmo:
En primer lugar, se debe elegir la regresión lógica, y si su eficacia no es buena, se puede usar su resultado como referencia para compararlo con otros algoritmos en la base;
Luego prueba con árboles de decisión (bosques aleatorios) para ver si puedes mejorar considerablemente el rendimiento de tu modelo. Incluso si no lo consideras como el modelo final, puedes usar los bosques aleatorios para eliminar variables de ruido y hacer una selección de características.
Si el número de características y las muestras observadas son especialmente numerosas, entonces cuando los recursos y el tiempo son suficientes (esto es importante), el uso de SVM es una opción.
Por lo general: GBDT>=SVM>=RF>=Adaboost>=Other… bueno, ahora el aprendizaje profundo es muy popular, se utiliza en muchos campos, se basa en redes neuronales, y yo mismo estoy aprendiendo, pero el conocimiento teórico no es muy sólido, no es lo suficientemente profundo para entenderlo, no lo presento aquí.
Los algoritmos son importantes, pero los buenos datos son mejores que los buenos algoritmos, y los buenos rasgos de diseño son muy útiles. Si tienes un conjunto de datos muy grande, entonces el algoritmo que utilices puede no tener mucho impacto en el rendimiento de la clasificación (en este caso, puedes elegir entre velocidad y facilidad de uso).
-
Referencias