
1. Introducción
El artículo anterior presentó el uso de la red LSTM para predecir los precios de Bitcoin https://www.fmz.com/digest-topic/4035. Como se menciona en el artículo, es solo un pequeño proyecto para practicar y familiarizarse con RNN y PyTorch. . Este artículo presentará el uso de métodos de aprendizaje de refuerzo para entrenar directamente estrategias comerciales. El modelo de aprendizaje de refuerzo es el PPO de código abierto de OpenAI, y el entorno se basa en el estilo de gimnasio. Para facilitar la comprensión y las pruebas, el modelo LSTM PPO y el entorno de backtesting gym se escriben directamente sin utilizar paquetes listos para usar.
PPO, el nombre completo de Optimización de Políticas Proximales, es una mejora de optimización de Policy Graident, es decir, gradiente de políticas. OpenAI también lanzó Gym. Puede interactuar con la red de políticas y brindar retroalimentación sobre el estado actual y la recompensa del entorno. Es como el ejercicio de aprendizaje de refuerzo que utiliza el modelo PPO de LSTM para realizar directamente la compra, venta o ninguna operación en función de la Información del mercado de Bitcoin. Las instrucciones las proporciona el entorno de backtesting y el modelo se optimiza continuamente mediante el entrenamiento para lograr el objetivo de rentabilidad de la estrategia.
Para leer este artículo es necesario tener ciertas bases en Python, PyTorch y aprendizaje de refuerzo profundo DRL. Pero no importa si no sabes cómo hacerlo. Es fácil aprender y empezar con el código que se proporciona en este artículo. Este artículo fue producido por FMZ, el inventor de la plataforma de comercio cuantitativo de divisas digitales (www.fmz.com). Bienvenido a unirse al grupo QQ: 863946592 para comunicarse.
2. Datos y referencias de aprendizaje
Los datos del precio de Bitcoin provienen de la plataforma de comercio cuantitativo del inventor FMZ: https://www.quantinfo.com/Tools/View/4.html
Un artículo sobre el uso de DRL+gym para entrenar estrategias comerciales: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
Algunos ejemplos de cómo empezar a utilizar PyTorch: https://github.com/yunjey/pytorch-tutorial
Este artículo utilizará directamente esta breve implementación del modelo LSTM-PPO: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
Artículos sobre PPO: https://zhuanlan.zhihu.com/p/38185553
Más artículos sobre DRL: https://www.zhihu.com/people/flood-sung/posts
En cuanto al gimnasio, este artículo no necesita instalarse, pero el aprendizaje de refuerzo es muy común: https://gym.openai.com/
3.LSTM-PPO
Para obtener una explicación más detallada de la PPO, puede estudiar las referencias anteriores. Aquí se ofrece solo una introducción al concepto simple. En la edición anterior, la red LSTM solo predijo un precio. La forma de comprar y vender transacciones en función de este precio previsto debe implementarse por separado. Naturalmente, se puede imaginar que sería más directo emitir directamente las acciones de compra y venta. , ¿bien? El gradiente de políticas es así: puede dar la probabilidad de varias acciones en función de la información ambiental de entrada. La pérdida de LSTM es la diferencia entre el precio previsto y el precio real, mientras que la pérdida de PG es -log(p)*Q, donde p es la probabilidad de que se produzca una acción y Q es el valor de la acción (como una puntuación de recompensa). La explicación intuitiva es que si el valor de una acción es mayor, la red debería producir una probabilidad mayor. para reducir la pérdida. Aunque el PPO es mucho más complicado, el principio es similar. La clave está en cómo evaluar mejor el valor de cada acción y cómo actualizar mejor los parámetros.
A continuación se muestra el código fuente de LSTM-PPO, que puede entenderse en combinación con la información anterior:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Entorno de backtesting de Bitcoin
Siguiendo el formato del gimnasio, hay un método de inicialización de reinicio, una acción de entrada de pasos y el resultado devuelto es (próximo estado, beneficio de la acción, si está terminada, información adicional). El entorno de backtest completo tiene solo 60 líneas, que se pueden Modificado por ti mismo. Versión compleja, código específico:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Varios detalles dignos de mención
¿Por qué la cuenta inicial tiene monedas?
La fórmula para calcular el rendimiento en el entorno de backtesting es: Rendimiento actual = Valor de la cuenta actual - Valor actual de la cuenta inicial. Esto significa que si el precio de Bitcoin cae y la estrategia vende las monedas, la estrategia debería ser recompensada incluso si el valor total de la cuenta disminuye. Si el período de backtesting es largo, es posible que la cuenta inicial no se vea muy afectada, pero aun así tendrá un gran impacto al principio. El cálculo de rendimientos relativos garantiza que cada operación correcta obtenga una recompensa positiva.
¿Por qué tomamos muestras del mercado durante la capacitación?
La cantidad total de datos es más de 10 000 líneas K. Si se ejecuta un ciclo completo cada vez, llevará mucho tiempo y la estrategia enfrentará exactamente la misma situación cada vez, lo que puede provocar un sobreajuste. Cada vez se dibujan 500 barras como datos de backtest. Aunque todavía es posible el sobreajuste, la estrategia se enfrenta a más de 10.000 posibles inicios diferentes.
¿Qué hacer si no tienes monedas o dinero?
Esta situación no se considera en el entorno de backtest. Si la moneda se ha vendido o no se alcanza el volumen mínimo de transacción, ejecutar la operación de venta en este momento es en realidad equivalente a no ejecutar ninguna operación. Si el precio cae, según el volumen relativo El método de cálculo de retorno todavía se basa en la recompensa positiva de la estrategia. El impacto de esta situación es que cuando la estrategia determina que el mercado está cayendo y las monedas restantes en la cuenta no se pueden vender, es imposible distinguir entre acciones de venta y ninguna operación, pero no tiene impacto en el propio juicio de la estrategia. el mercado.
¿Por qué devolver la información de la cuenta como estado?
El modelo PPO tiene una red de valor que se utiliza para evaluar el valor del estado actual. Obviamente, si la estrategia determina que el precio va a subir, todo el estado solo tendrá valor positivo si la cuenta actual contiene Bitcoin, y viceversa. Por lo tanto, la información de la cuenta es una base importante para juzgar el valor de la red. Tenga en cuenta que la información de acciones pasadas no se devuelve como estado, lo que personalmente creo que es inútil para juzgar el valor.
¿En qué circunstancias no devolverá ninguna operación?
Cuando la estrategia determina que las ganancias provenientes de la compra y la venta no pueden cubrir la tarifa de transacción, debe volver a no realizar ninguna acción. Aunque en la descripción anterior se utilizaron repetidamente estrategias para determinar las tendencias de precios, esto se hizo únicamente para facilitar la comprensión. De hecho, este modelo PPO no realiza ninguna predicción sobre el mercado, sino que solo genera las probabilidades de tres acciones.
6. Adquisición de datos y entrenamiento
Al igual que en el artículo anterior, los datos se obtienen en el siguiente formato: la línea K de una hora del par comercial BTC_USD en el intercambio Bitfinex del 7/5/2018 al 27/6/2019:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Como se utilizó la red LSTM, el tiempo de entrenamiento fue muy largo, así que cambié a una versión GPU, que era aproximadamente 3 veces más rápida.
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
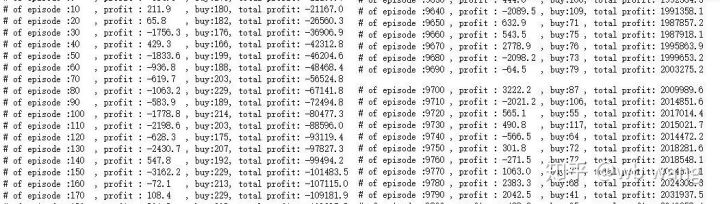
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Resultados y análisis del entrenamiento
Después de una larga espera:

En primer lugar, echemos un vistazo a las tendencias del mercado de los datos de entrenamiento. En términos generales, la primera mitad fue una caída prolongada y la segunda mitad fue una fuerte recuperación.
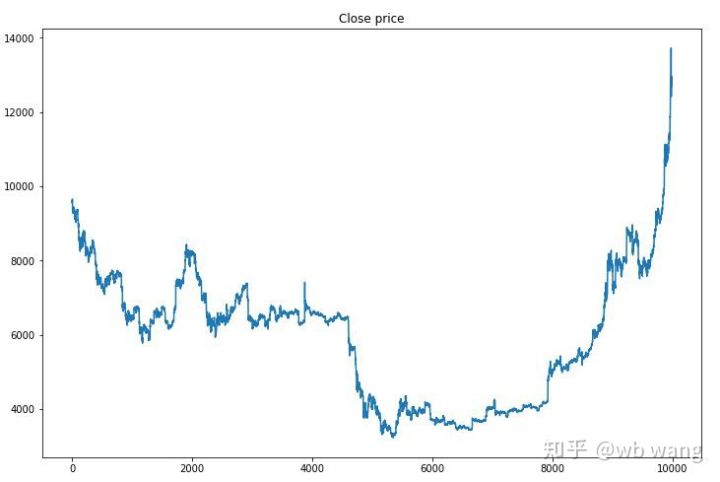
Hay muchas operaciones de compra en las primeras etapas del entrenamiento y básicamente no hay rondas rentables. A mitad del periodo de entrenamiento, el número de operaciones de compra disminuyó gradualmente y la probabilidad de ganancia se hizo cada vez mayor, pero todavía existía una alta probabilidad de pérdida.
Suavizando los ingresos por ronda, los resultados son los siguientes:
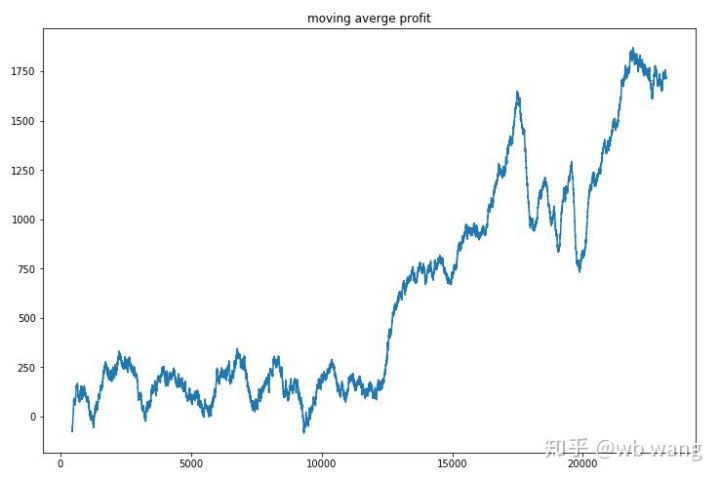
La estrategia eliminó rápidamente los rendimientos negativos en las primeras etapas, pero las fluctuaciones fueron grandes. No fue hasta 10.000 rondas que los rendimientos comenzaron a crecer rápidamente. En general, el entrenamiento del modelo fue difícil.
Una vez finalizado el entrenamiento final, deje que el modelo ejecute todos los datos nuevamente para ver cómo funciona. Durante este período, registre el valor total de mercado de la cuenta, la cantidad de bitcoins que posee, la proporción del valor de bitcoins y los ingresos totales. .
En primer lugar, está el valor total del mercado. Los ingresos totales son similares, por lo que no los publicaré aquí:
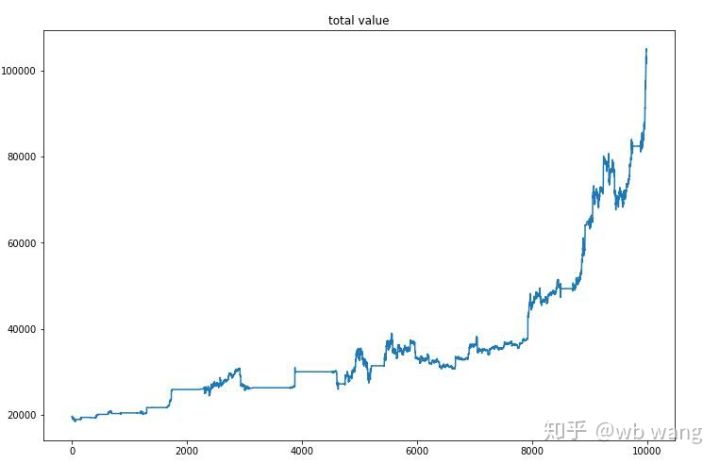
El valor total del mercado aumentó lentamente durante el mercado bajista inicial y también mantuvo el ritmo del aumento durante el mercado alcista posterior, pero todavía hubo pérdidas periódicas.
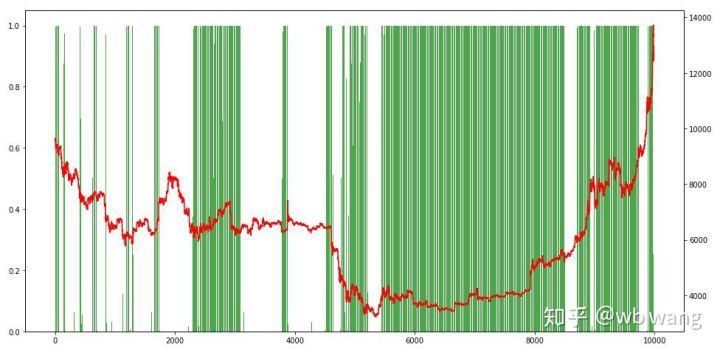
Por último, echemos un vistazo a la proporción de posiciones. El eje izquierdo del gráfico es la proporción de posiciones y el eje derecho es la situación del mercado. Se puede determinar preliminarmente que el modelo ha sido sobreajustado. La frecuencia de las posiciones fue bajo en el mercado bajista inicial, y la frecuencia de las posiciones fue muy alta en la parte inferior del mercado. También podemos ver que el modelo no ha aprendido a mantener posiciones durante mucho tiempo y siempre vende rápidamente.
8. Análisis de datos de prueba
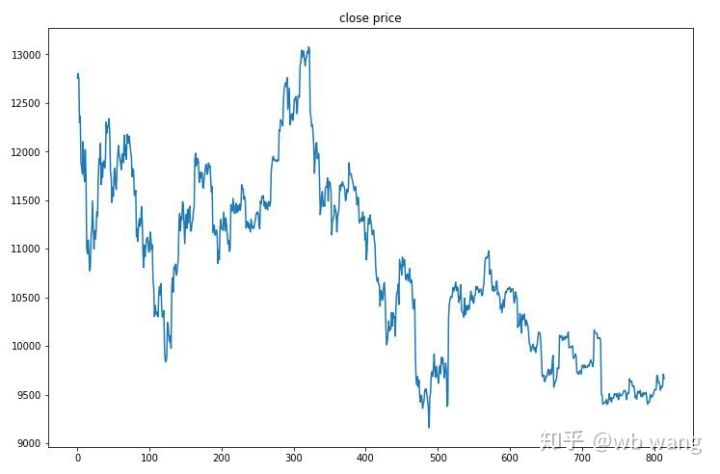
Los datos de prueba se obtuvieron del mercado de Bitcoin de una hora desde el 27/6/2019 hasta el presente. Como se puede ver en la figura, el precio ha bajado de 13.000 dólares al principio a más de 9.000 dólares en la actualidad, lo que supone una gran prueba para el modelo.
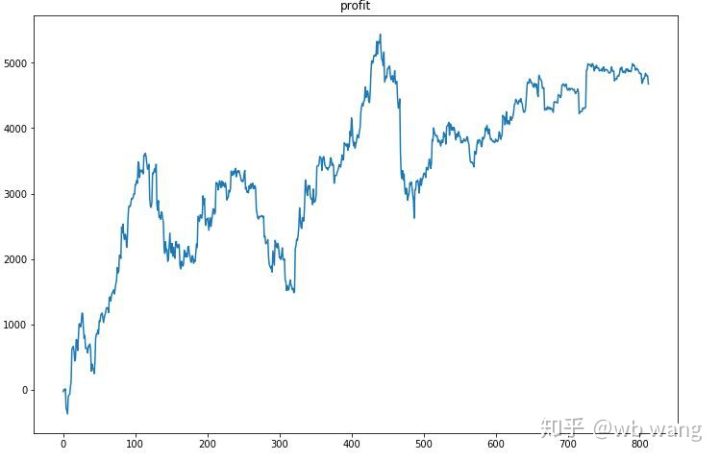
En primer lugar, el rendimiento relativo final no fue satisfactorio, pero tampoco hubo pérdidas.
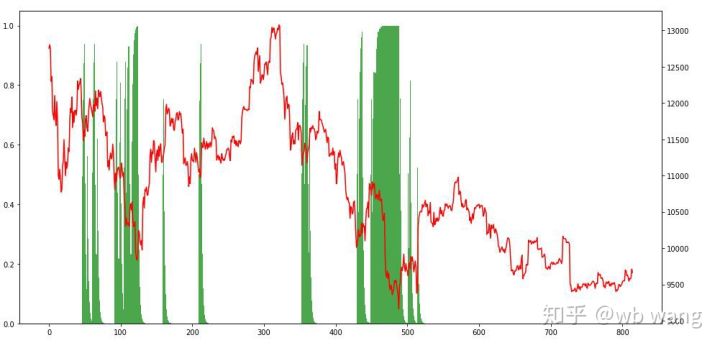
Observando las posiciones, podemos intuir que el modelo tiende a comprar tras una caída brusca y a vender tras un repunte. En los últimos tiempos, el mercado de Bitcoin ha fluctuado muy poco y el modelo ha estado en una posición corta.
9. Resumen
Este artículo utiliza el método de aprendizaje de refuerzo profundo PPO para entrenar un robot de comercio automático de Bitcoin y obtiene algunas conclusiones. Debido al tiempo limitado, todavía hay algunas áreas que se pueden mejorar en el modelo. Todos están invitados a debatir. La lección más importante es que la estandarización de los datos es el método correcto. No utilice métodos como el escalamiento, de lo contrario, el modelo recordará rápidamente la relación entre el precio y las condiciones del mercado y caerá en un sobreajuste. Después de la normalización, la tasa de cambio se convierte en un dato relativo, lo que dificulta que el modelo recuerde su relación con el mercado y lo obliga a encontrar la conexión entre la tasa de cambio y el aumento y la caída.
Artículos anteriores:
Algunas estrategias públicas compartidas en la plataforma cuantitativa FMZ Inventor: https://zhuanlan.zhihu.com/p/64961672
Curso de comercio cuantitativo de moneda digital de NetEase Cloud Classroom, solo 20 yuanes: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
He hecho pública una estrategia de alta frecuencia que en su día fue muy rentable: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1