8 मशीन लर्निंग एल्गोरिदम की तुलना
 0
6946
0
6946
8 मशीन लर्निंग एल्गोरिदम की तुलना
इस लेख में मुख्य रूप से निम्नलिखित कुछ सामान्य एल्गोरिदम के अनुकूलन परिदृश्य और उनके फायदे और नुकसान की समीक्षा की गई है।
मशीन लर्निंग एल्गोरिदम बहुत सारे हैं, वर्गीकरण, पुनरावृत्ति, समूह, अनुशंसा, छवि पहचान के क्षेत्र में और इतने पर, एक उपयुक्त एल्गोरिथ्म खोजने के लिए वास्तव में आसान नहीं है, इसलिए व्यावहारिक अनुप्रयोगों में, हम आम तौर पर प्रयोग करने के लिए प्रेरक सीखने के तरीके का उपयोग करते हैं।
आमतौर पर शुरुआत में हम एसवीएम, जीबीडीटी, एडाबॉस्ट जैसे आम तौर पर मान्यता प्राप्त एल्गोरिदम का चयन करते हैं, अब गहरी शिक्षा गर्म है, और न्यूरल नेटवर्क एक अच्छा विकल्प है।
यदि आप सटीकता के बारे में चिंतित हैं, तो सबसे अच्छा तरीका यह है कि आप प्रत्येक एल्गोरिथ्म को एक-एक करके क्रॉस-वैलिडेशन के माध्यम से परीक्षण करें, तुलना करें, फिर पैरामीटर को समायोजित करें ताकि यह सुनिश्चित हो सके कि प्रत्येक एल्गोरिथ्म इष्टतम समाधान तक पहुंचता है, और अंत में सबसे अच्छा चुनें।
लेकिन अगर आप सिर्फ एक ऐसा एल्गोरिथ्म ढूंढ रहे हैं जो आपके लिए काफी अच्छा हो, या यहां कुछ टिप्स दिए गए हैं, तो नीचे दिए गए एल्गोरिथ्म के फायदे और नुकसान का विश्लेषण करें, जिससे हमें इसे चुनना आसान हो सके।
- ## विचलन और अंतर
एक मॉडल का अच्छा या बुरा होना, सांख्यिकी में, एक विचलन और विचलन के आधार पर मापा जाता है, इसलिए हम विचलन और विचलन के बारे में सामान्यीकरण करते हैंः
विचलनः यह अनुमानित मूल्य (अनुमानित मूल्य) के अपेक्षित E और वास्तविक मूल्य Y के बीच के अंतर को दर्शाता है। विचलन जितना बड़ा है, उतना ही वास्तविक डेटा से दूर है।
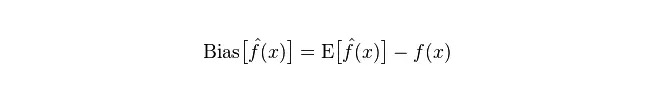
विभेद: विभेद का वर्णन एक अनुमानित मूल्य P के परिवर्तन की सीमा, विखंडन की डिग्री, जो अनुमानित मूल्य का विभेद है, जो कि इसके अपेक्षित मूल्य E से दूरी है। विभेद जितना बड़ा होगा, डेटा का वितरण उतना ही बिखरा हुआ होगा।
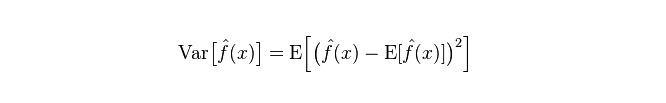
मॉडल की वास्तविक त्रुटि दोनों का योग है, जैसा कि नीचे दिखाया गया हैः
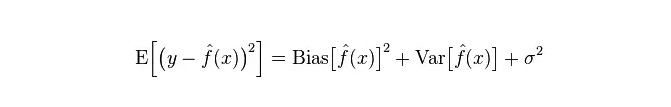
यदि यह एक छोटा प्रशिक्षण सेट है, तो उच्च विचलन / कम विचलन वर्गीकरण (उदाहरण के लिए, सरल बेयज़ एनबी) कम विचलन / उच्च विचलन के बड़े वर्गीकरण (उदाहरण के लिए, केएनएन) की तुलना में अधिक फायदेमंद है, क्योंकि बाद वाला ओवरफिट होगा।
लेकिन, जैसे-जैसे आपका प्रशिक्षण सेट बढ़ता है, मॉडल मूल डेटा के लिए बेहतर भविष्यवाणी करने की क्षमता रखता है, विचलन कम हो जाता है, इस समय कम विचलन/उच्च विचलन वर्गीकरण धीरे-धीरे अपने लाभ का प्रदर्शन करता है (क्योंकि उनके पास कम समीकरण त्रुटि है), इस समय उच्च विचलन वर्गीकरण अब सटीक मॉडल प्रदान करने के लिए पर्याप्त नहीं है।
बेशक, आप इसे जनरेशन मॉडल (NB) और निर्णय मॉडल (KNN) के बीच एक अंतर के रूप में देख सकते हैं।
- ## बेयज़ को उच्च विचलन या निम्न विचलन के रूप में क्यों जाना जाता है?
यह भी पढ़ेंः
सबसे पहले, मान लीजिए कि आप जानते हैं कि प्रशिक्षण सेट और परीक्षण सेट के बीच क्या संबंध है। सरल शब्दों में, हम प्रशिक्षण सेट पर एक मॉडल सीखते हैं, और फिर परीक्षण सेट प्राप्त करते हैं। प्रभावशीलता को परीक्षण सेट की त्रुटि दर से मापा जाता है।
लेकिन कई बार, हम केवल यह मान सकते हैं कि परीक्षण सेट और प्रशिक्षण सेट एक ही डेटा वितरण के अनुरूप हैं, लेकिन वास्तविक परीक्षण डेटा प्राप्त नहीं करते हैं। तो हम केवल प्रशिक्षण त्रुटि दर को देखते हुए परीक्षण त्रुटि दर को कैसे माप सकते हैं?
चूंकि प्रशिक्षण नमूने बहुत कम हैं (कम से कम पर्याप्त नहीं हैं), इसलिए प्रशिक्षण सेट के माध्यम से प्राप्त मॉडल हमेशा सही नहीं होता है। (यहां तक कि यदि प्रशिक्षण सेट पर 100% सटीकता है, तो यह नहीं कह सकता कि यह वास्तविक डेटा वितरण को चित्रित करता है, यह जानना कि वास्तविक डेटा वितरण को चित्रित करना हमारा उद्देश्य है, न कि केवल प्रशिक्षण सेट के सीमित डेटा बिंदुओं को चित्रित करना) ।
इसके अलावा, वास्तव में, प्रशिक्षण नमूने में अक्सर कुछ शोर त्रुटि होती है, इसलिए यदि एक जटिल मॉडल को प्रशिक्षण सेट पर पूर्णता के लिए बहुत अधिक उपयोग किया जाता है, तो यह मॉडल को प्रशिक्षण सेट में सभी त्रुटियों को वास्तविक डेटा वितरण विशेषता के रूप में लेने का कारण बनता है, जिससे गलत डेटा वितरण अनुमान प्राप्त होता है।
इस तरह, वास्तविक परीक्षण सेट में एक त्रुटि है (इस घटना को संयोग कहा जाता है) । लेकिन बहुत सरल मॉडल का उपयोग नहीं किया जा सकता है, अन्यथा जब डेटा वितरण अधिक जटिल होता है, तो मॉडल डेटा वितरण को चित्रित करने के लिए पर्याप्त नहीं होता है (यहां तक कि प्रशिक्षण सेट में त्रुटि दर बहुत अधिक होती है, यह घटना कम उपयुक्त है) ।
अति-अनुरूपता से पता चलता है कि मॉडल वास्तविक डेटा वितरण की तुलना में अधिक जटिल है, जबकि अति-अनुरूपता से पता चलता है कि मॉडल वास्तविक डेटा वितरण की तुलना में सरल है।
सांख्यिकीय सीखने के ढांचे में, जब हम मॉडल की जटिलता को रेखांकित करते हैं, तो यह विचार है कि त्रुटि = पूर्वाग्रह + भिन्नता। यहाँ त्रुटि को शायद मॉडल की भविष्यवाणी त्रुटि के रूप में समझा जा सकता है, जो दो भागों से बना है, एक भाग मॉडल के बहुत सरल होने के कारण अनुमान की अशुद्धता है (पूर्वाग्रह), और दूसरा भाग मॉडल के बहुत जटिल होने के कारण अधिक परिवर्तन स्थान और अनिश्चितता है (भिन्नता) ।
इसलिए, यह सरल बेयस का विश्लेषण करने के लिए आसान है। यह एक बहुत ही सरल मॉडल है, जो डेटा के बीच असंबद्ध है। इसलिए, इस तरह के एक सरल मॉडल के लिए, ज्यादातर मामलों में, पूर्वाग्रह भाग वैरिएंस भाग से बड़ा होता है, यानी उच्च विचलन और कम विचलन।
वास्तव में, त्रुटि को कम से कम करने के लिए, हमें मॉडल चुनते समय पूर्वाग्रह और भिन्नता के अनुपात को संतुलित करने की आवश्यकता होती है, यानी ओवर-फिटिंग और अंडर-फिटिंग को संतुलित करना।
यह स्पष्ट है कि विचलन और वर्ग विचलन मॉडल की जटिलता के साथ कैसे संबंधित हैं, जैसा कि नीचे दिया गया हैः
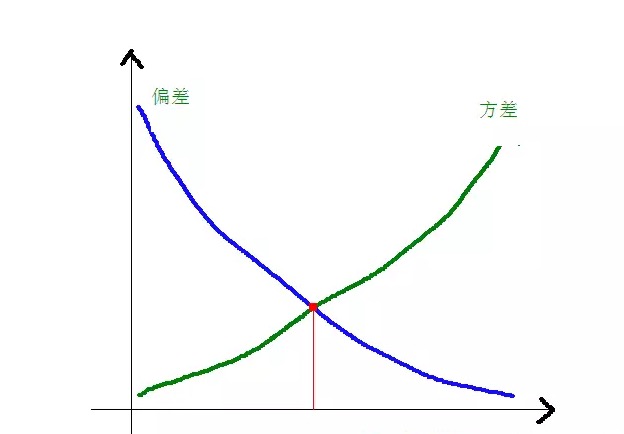
जैसे-जैसे मॉडल की जटिलता बढ़ती है, विचलन छोटा होता जाता है और अंतर बड़ा होता जाता है।
-
सामान्य एल्गोरिदम के फायदे और नुकसान
- ### १. प्राक्सन बेयज़
सरल बेयज़ जनरेटिव मॉडल के अंतर्गत आता है ((जन्म देने वाले मॉडल और निर्णायक मॉडल के बारे में, मुख्य रूप से यह है कि क्या यह संयुक्त वितरण की आवश्यकता है), बहुत सरल है, आप बस गणना का एक ढेर कर रहे हैं।
यदि आप सशर्त स्वतंत्रता परिकल्पना को लागू करते हैं (एक अधिक सख्त शर्त), तो एक सरल बेयज़ वर्गीकरणकर्ता तर्कसंगत वापसी जैसे निर्णय मॉडल की तुलना में अधिक तेज़ी से संकुचन करेगा, इसलिए आपको केवल कम प्रशिक्षण डेटा की आवश्यकता होगी। एनबी वर्गीकरणकर्ता अभ्यास में बहुत अच्छा प्रदर्शन करते हैं, भले ही एनबी सशर्त स्वतंत्रता परिकल्पना मान्य न हो।
इसका मुख्य दोष यह है कि यह सुविधाओं के बीच बातचीत नहीं सीख सकता है, mRMR में R के लिए, यह सुविधाओं की अनावश्यकता है। एक और अधिक क्लासिक उदाहरण को उद्धृत करने के लिए, उदाहरण के लिए, भले ही आपको ब्रैड पिट और टॉम क्रूज की फिल्म पसंद है, लेकिन यह यह नहीं सीख सकता है कि आपको उनके साथ फिल्म पसंद नहीं है।
लाभ:
सरल बेयज़ मॉडल शास्त्रीय गणितीय सिद्धांत से उत्पन्न होता है, जिसमें एक ठोस गणितीय आधार और स्थिर वर्गीकरण दक्षता होती है। छोटे पैमाने पर डेटा के लिए अच्छा प्रदर्शन, बहु-श्रेणी के कार्यों को एक-एक करके संभाल सकता है, जो वृद्धिशील प्रशिक्षण के लिए उपयुक्त है; गुम हुए डेटा के प्रति संवेदनशील नहीं है, और एल्गोरिदम सरल हैं, अक्सर पाठ वर्गीकरण के लिए उपयोग किया जाता है। दोष:
एक पूर्व-संभाव्यता की गणना की आवश्यकता; वर्गीकरण निर्णयों में त्रुटि दर; इनपुट डेटा के अभिव्यक्ति के लिए संवेदनशील।
- ### 2. तार्किक वापसी
एक विशिष्ट मॉडल में, कई तरीके हैं जो एक मॉडल को व्यवस्थित करते हैं (L0, L1, L2, आदि) और आपको चिंता करने की ज़रूरत नहीं है कि आपकी विशेषताएं प्रासंगिक हैं, जैसा कि बेयज़ के साथ होता है।
निर्णय पेड़ों और एसवीएम मशीनों की तुलना में, आपको एक अच्छी संभाव्यता व्याख्या भी मिलती है, और आप आसानी से नए डेटा का उपयोग करके मॉडल को अपडेट कर सकते हैं।
यदि आपको एक संभाव्यता संरचना की आवश्यकता है (उदाहरण के लिए, बस वर्गीकरण थ्रेशोल्ड को समायोजित करना, अनिश्चितता को इंगित करना, या विश्वास की सीमा प्राप्त करना), या आप बाद में मॉडल में अधिक प्रशिक्षण डेटा को जल्दी से एकीकृत करना चाहते हैं, तो इसका उपयोग करें।
सिग्मोइड फ़ंक्शन:
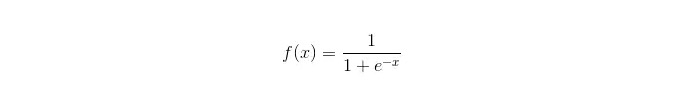
लाभ: यह सरल है और व्यापक रूप से औद्योगिक मुद्दों पर लागू होता है। वर्गीकरण के लिए बहुत कम गणना, बहुत तेज, और कम भंडारण संसाधन; एक सुविधाजनक अवलोकन नमूना संभावना स्कोर; लॉजिकल रिग्रेशन के लिए, बहु-सहसंयोज्यता कोई समस्या नहीं है और इसे L2 नियमितकरण के साथ हल किया जा सकता है; दोष: जब फीचर स्पेस बहुत बड़ा होता है, तो लॉजिकल रिग्रेशन का प्रदर्शन अच्छा नहीं होता है; गलत फ़िट करने की संभावना, सामान्यतः कम सटीकता बहुत सारे गुणों या चरों को अच्छी तरह से संभालने में असमर्थता; केवल दो वर्गीकरण प्रश्नों को संभाल सकता है (इस आधार पर व्युत्पन्न सॉफ्टमैक्स को बहु-वर्गीकरण के लिए उपयोग किया जा सकता है) और इसे रैखिक रूप से विभाजित किया जाना चाहिए; गैर-रैखिक विशेषताओं के लिए, रूपांतरण की आवश्यकता है;
- ### 3. रैखिक प्रतिगमन
रैखिक प्रतिगमन का उपयोग वर्गीकरण के लिए नहीं किया जाता है, जैसे कि लॉजिस्टिक प्रतिगमन के लिए किया जाता है, और इसका मूल विचार यह है कि त्रुटि फ़ंक्शंस को न्यूनतम द्विपद के रूप में ऑप्टिमाइज़ करने के लिए ग्रेडिएंट अवरोही विधि का उपयोग किया जाए, और निश्चित रूप से, सामान्य समीकरणों के साथ सीधे पैरामीटर के समाधान के लिए, परिणामः
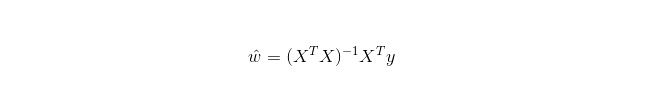
जबकि LWLR (स्थानीय भारित रैखिक प्रतिगमन) में, पैरामीटर की गणना अभिव्यक्ति हैः
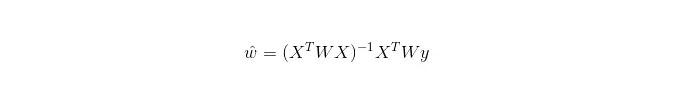
इस प्रकार यह देखा जा सकता है कि LWLR LR के विपरीत एक गैर-पैरामीटर मॉडल है, क्योंकि प्रत्येक पुनरावृत्ति गणना के लिए प्रशिक्षण नमूने को कम से कम एक बार पार करना पड़ता है।
लाभः सरलता से लागू किया जा सकता है, गणना करना आसान है;
दोष: गैर-रैखिक डेटा के लिए उपयुक्त नहीं है।
- ### 4. निकटतम पड़ोसी एल्गोरिदम केएनएन
KNN निकटतम-पड़ोसी एल्गोरिथ्म है, जिसकी मुख्य प्रक्रिया हैः
प्रशिक्षण नमूने और परीक्षण नमूने में प्रत्येक नमूना बिंदु की दूरी की गणना करें (सामान्य दूरी माप यूरोपीय दूरी, मार्स दूरी, आदि हैं);
ऊपर दिए गए सभी दूरी मानों को क्रमबद्ध करें;
k सबसे कम दूरी के नमूने का चयन करें;
इस तरह से, एक व्यक्ति के लिए, एक व्यक्ति के लिए, एक व्यक्ति के लिए, एक व्यक्ति के लिए, एक व्यक्ति के लिए, एक व्यक्ति के लिए, एक व्यक्ति के लिए, एक व्यक्ति के लिए।
एक इष्टतम के-वैल्यू कैसे चुनें, यह डेटा पर निर्भर करता है। सामान्य तौर पर, वर्गीकरण के दौरान एक बड़ा के-वैल्यू शोर के प्रभाव को कम करने में मदद करता है। लेकिन श्रेणियों के बीच की सीमाओं को धुंधला कर सकता है।
एक बेहतर K मान विभिन्न प्रकार के प्रवर्तक तकनीकों के माध्यम से प्राप्त किया जा सकता है, जैसे कि क्रॉस-सत्यापन। इसके अलावा, शोर और असंबद्धता विशेषता वैक्टर की उपस्थिति K निकट-पड़ोस के एल्गोरिदम की सटीकता को कम कर देती है।
समीपस्थ एल्गोरिदम के पास एक मजबूत सुसंगत परिणाम होता है। जैसे-जैसे डेटा अनंत होता है, एल्गोरिदम की त्रुटि दर बेयज़ एल्गोरिदम की त्रुटि दर से दोगुनी से अधिक नहीं होने का आश्वासन दिया जाता है। कुछ अच्छे K मानों के लिए, K के समीपस्थ की त्रुटि दर बेयज़ के सैद्धांतिक त्रुटि दर से अधिक नहीं होने का आश्वासन दिया जाता है।
KNN एल्गोरिथ्म के फायदे
सिद्धांत परिपक्व है, विचार सरल है, वर्गीकरण के लिए भी इस्तेमाल किया जा सकता है और वापसी के लिए भी इस्तेमाल किया जा सकता है; गैर-रैखिक वर्गीकरण के लिए; प्रशिक्षण समय जटिलता O (n) है; डेटा पर कोई धारणा नहीं, उच्च सटीकता, आउटलियर के प्रति संवेदनशील नहीं; कमी
बड़ी गणना; असंतुलित नमूने की समस्या (यानी, कुछ श्रेणियों में बहुत सारे नमूने हैं, जबकि अन्य में बहुत कम नमूने हैं); यह बहुत अधिक मेमोरी की आवश्यकता होती है।
- ### 5. निर्णय वृक्ष
व्याख्या करने में आसान। यह सुविधाओं के बीच बातचीत को तनाव मुक्त और गैर-पैरामीटर के साथ संभाल सकता है, इसलिए आपको चिंता करने की ज़रूरत नहीं है कि असामान्य मूल्य या डेटा रैखिक रूप से अलग हो सकता है (उदाहरण के लिए, निर्णय पेड़ आसानी से श्रेणी ए को किसी सुविधा आयाम x के अंत में संभाल सकता है, श्रेणी बी मध्य में, और फिर श्रेणी ए फिर से सुविधा आयाम x के सामने की ओर दिखाई देती है) ।
एक कमजोरी यह है कि यह ऑनलाइन सीखने का समर्थन नहीं करता है, इसलिए नए नमूनों के आने के बाद निर्णय के पेड़ को पूरी तरह से फिर से बनाना पड़ता है।
एक और दोष यह है कि यह अति-अनुरूपता के लिए आसान है, लेकिन यह एकीकरण के लिए एक प्रवेश बिंदु है जैसे कि यादृच्छिक वन आरएफ (या बूस्टेड ट्री) ।
इसके अलावा, यादृच्छिक वन अक्सर वर्गीकरण समस्याओं के कई विजेता होते हैं (आमतौर पर वेक्टर समर्थित मशीनों की तुलना में थोड़ा बेहतर), यह तेजी से प्रशिक्षित और समायोज्य होता है, और आपको वेक्टर समर्थित मशीनों की तरह कई मापदंडों को बदलने के बारे में चिंता करने की आवश्यकता नहीं होती है, इसलिए यह पहले से ही लोकप्रिय रहा है।
निर्णय के पेड़ में एक महत्वपूर्ण बात यह है कि एक विशेषता का चयन करने के लिए शाखाएं हैं, इसलिए सूचना वृद्धि के लिए गणना सूत्र पर ध्यान दें और इसे गहराई से समझें।
जानकारी तालिका के लिए सूत्र इस प्रकार है:
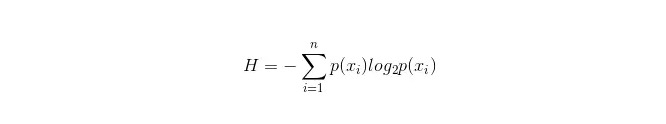
इनमें से n का प्रतिनिधित्व करता है n वर्गीकरण श्रेणियाँ ((उदाहरण के लिए, मान लें कि यह 2 प्रकार का प्रश्न है, तो n = 2) । कुल नमूने में इन 2 प्रकार के नमूनों की संभावना p1 और p2 को अलग-अलग गणना करें, ताकि अनचेक किए गए गुणों की शाखाओं से पहले की जानकारी की गणना की जा सके।
अब एक विशेषता xxi का चयन करें जिसे शाखाओं के लिए उपयोग किया जाए, और इस समय शाखा नियम यह हैः यदि x = vxi = v, तो नमूने को पेड़ की एक शाखा में विभाजित करें; यदि यह समान नहीं है, तो दूसरी शाखा में जाएं।
यह स्पष्ट है कि शाखाओं में नमूने में दो श्रेणियां शामिल होने की संभावना है, क्रमशः H1 और H2 की गणना की जाती है, और शाखाओं के बाद कुल जानकारी की गणना की जाती है। H = p1 H1 + p2 H2, तो इस समय सूचना वृद्धि ΔH = H - H। सूचना वृद्धि के सिद्धांत के रूप में, सभी गुणों को एक साथ परीक्षण करें, और इस बार शाखाओं के गुण के रूप में सबसे अधिक वृद्धि वाले गुण को चुनें।
निर्णय वृक्ष के फायदे
यह एक सरल, समझने में आसान और व्याख्या करने योग्य गणना है। अनुपलब्ध गुणों के साथ काम करने के लिए उपयुक्त नमूने की तुलना करना; यह एक ऐसा विषय है, जिसके बारे में हम बात कर रहे हैं। एक अपेक्षाकृत कम समय में बड़े डेटा स्रोतों के लिए व्यवहार्य और प्रभावी परिणाम प्राप्त करने में सक्षम होना। कमी
अति-अनुकूलन के लिए अति-संवेदनशील (यादृच्छिक वनों में अति-अनुकूलन को काफी हद तक कम किया जा सकता है); यह डेटा के बीच संबंध को नजरअंदाज कर रहा है। उन सभी श्रेणियों के लिए, जहां डेटा की संख्या में असमानता है, निर्णय पेड़ों में, सूचना वृद्धि के परिणाम उन लोगों के लिए अधिक मूल्यवान विशेषताओं के साथ पक्षपाती हैं (यह नुकसान तब होता है जब सूचना वृद्धि का उपयोग किया जाता है, जैसे कि आरएफ) ।
- ### 5.1 Adaboosting
Adaboost एक जोड़ने का मॉडल है, प्रत्येक मॉडल पिछले मॉडल की त्रुटि दर के आधार पर बनाया गया है, गलत वर्गीकृत नमूनों पर बहुत अधिक ध्यान केंद्रित करना, और सही वर्गीकृत नमूनों पर कम ध्यान देना, एक अपेक्षाकृत अच्छा मॉडल प्राप्त करने के लिए, एक बार में पुनरावृत्ति के बाद। यह एक विशिष्ट बूस्टिंग एल्गोरिथ्म है। नीचे इसके फायदे और नुकसान का सारांश है।
फ़ायदा
adaboost एक उच्च परिशुद्धता वर्गीकरण है। विभिन्न विधियों का उपयोग करके एक उप-वर्गीकरण का निर्माण किया जा सकता है। Adaboost एल्गोरिदम एक ढांचा प्रदान करता है। जब सरल वर्गीकरण का उपयोग किया जाता है, तो गणना के परिणामों को समझा जा सकता है, और कमजोर वर्गीकरण की संरचना बेहद सरल है। सरल, कोई विशेषता फ़िल्टरिंग की आवश्यकता नहीं। ओवरफिटिंग की संभावना नहीं यादृच्छिक वन और GBDT जैसे संयोजन एल्गोरिदम के बारे में, इस लेख को देखेंः मशीन लर्निंग - संयोजन एल्गोरिदम सारांश
दोष: आउटलीयर के प्रति संवेदनशील
- ### 6. एसवीएम समर्थित वेक्टर मशीन
उच्च सटीकता, ओवरफिटिंग से बचने के लिए एक अच्छा सैद्धांतिक आश्वासन प्रदान करता है, और यह अच्छी तरह से काम करता है, भले ही डेटा मूल विशेषता अंतरिक्ष में रैखिक रूप से अविभाज्य हो, बस एक उपयुक्त कोर फ़ंक्शन दिया जाए।
यह विशेष रूप से उच्च आयाम के पाठ वर्गीकरण के लिए लोकप्रिय है। यह स्मृति की खपत, व्याख्या करने में कठिनाई, और संरेखण और संरेखण के साथ परेशानी का कारण बनता है, जबकि यादृच्छिक वन इन कमियों से बचने के लिए व्यावहारिक है।
फ़ायदा यह एक उच्च आयामी समस्या को हल करने में सक्षम है, जो कि एक विशाल विशेषता स्थान है। गैर-रैखिक विशेषताओं के साथ बातचीत करने में सक्षम; और यह पूरी तरह से डेटा पर निर्भर नहीं करता है। और यह भी कि यह कैसे हो सकता है?
कमी जब बहुत सारे नमूने देखे जाते हैं, तो यह बहुत प्रभावी नहीं होता है। गैर-रैखिक समस्याओं के लिए कोई सार्वभौमिक समाधान नहीं है, और कभी-कभी एक उपयुक्त कोर फ़ंक्शन ढूंढना मुश्किल होता है; इस तरह के डेटा के लिए संवेदनशीलता कोर के चयन के लिए भी कौशल है (libsvm में चार प्रकार के कोर फ़ंक्शन हैंः रैखिक कोर, बहुपद कोर, RBF और सिग्मोइड कोर):
पहला, यदि नमूने की संख्या विशेषताओं की संख्या से कम है, तो गैर-रैखिक कोर का चयन करने की आवश्यकता नहीं है, बस रैखिक कोर का उपयोग करें;
दूसरा, यदि नमूनों की संख्या विशेषताओं की संख्या से अधिक है, तो एक गैर-रैखिक कोर का उपयोग करके नमूनों को उच्च आयामों में मैप किया जा सकता है, जो आम तौर पर बेहतर परिणाम देता है।
तीसरा, यदि नमूनों की संख्या और विशेषताओं की संख्या समान है, तो एक गैर-रैखिक कोर का उपयोग किया जा सकता है, सिद्धांत दूसरे के समान है।
पहले मामले के लिए, डेटा को पहले आयाम में घटाया जा सकता है और फिर एक गैर-रैखिक कोर का उपयोग किया जा सकता है, यह भी एक तरीका है।
- ### 7. कृत्रिम तंत्रिका नेटवर्क के फायदे और नुकसान
एएनएन के फायदे: वर्गीकरण की उच्च सटीकता; यह भी कहा गया है कि यह एक “प्रबल” और “प्रबल” प्रणाली है। शोर तंत्रिका के लिए मजबूत कठोरता और त्रुटि सहनशीलता, जो जटिल गैर-रैखिक संबंधों के लिए पर्याप्त रूप से करीब है; याद करने की क्षमता के साथ
एएनएन के नुकसानः तंत्रिका नेटवर्क को बहुत सारे मापदंडों की आवश्यकता होती है, जैसे कि नेटवर्क टोपोलॉजी, प्रारंभिक मान और थ्रेशोल्ड; एक गैर-निरीक्षणात्मक सीखने की प्रक्रिया, जिसके परिणामों की व्याख्या करना मुश्किल है, परिणामों की विश्वसनीयता और स्वीकार्यता को प्रभावित करता है; अध्ययन के लिए समय बहुत लंबा है, और आप शायद अपने उद्देश्य तक नहीं पहुंच पाएंगे।
- ### 8 के-मीन्स समूह
K-Means clustering के बारे में पहले एक लेख लिखा गया था, जिसमें बहुत मजबूत EM विचार थे।
फ़ायदा एल्गोरिदम सरल और लागू करने में आसान है। बड़े डेटासेट को संभालने के लिए, यह एल्गोरिथ्म अपेक्षाकृत स्केलेबल और उच्च दक्षता वाला है, क्योंकि इसकी जटिलता लगभग O{\displaystyle \O{\mathrm {n}}} nkt है, जिसमें n सभी वस्तुओं की संख्या है, k पिंडों की संख्या है, और t पुनरावृत्ति की संख्या है। आमतौर पर k<}} होता है। यह एल्गोरिथ्म आमतौर पर स्थानीय रूप से संकुचित होता है। एल्गोरिथ्म का प्रयास वर्ग त्रुटि फ़ंक्शन के मूल्य को कम करने के लिए k विभाजनों को खोजने के लिए किया जाता है। जब स्टेरॉयड घने, गोलाकार या समूह के रूप में होते हैं, और स्टेरॉयड और स्टेरॉयड के बीच स्पष्ट अंतर होता है, तो समूह प्रभाव बेहतर होता है।
कमी डेटा प्रकार के लिए उच्च आवश्यकताएं, संख्यात्मक डेटा के लिए उपयुक्त; स्थानीय न्यूनतम के लिए संरेखित किया जा सकता है, बड़े पैमाने पर डेटा पर संरेखित करने के लिए धीमा K मान को चुनना मुश्किल है; प्रारंभिक मानों के लिए केंद्र के लिए संवेदनशील, अलग-अलग प्रारंभिक मानों के लिए, अलग-अलग क्लस्टर परिणामों का कारण बन सकता है; गैर-उभरा आकार के तारे या बड़े आकार के तारे खोजने के लिए उपयुक्त नहीं है। एक छोटी मात्रा में इस प्रकार के डेटा से औसत पर बहुत अधिक प्रभाव पड़ सकता है।
एल्गोरिथ्म चयन संदर्भ
एक लेख जो पहले से ही कुछ विदेशी लेखों का अनुवाद कर चुका है, एक सरल एल्गोरिथ्म चयन युक्तियाँ प्रदान करता हैः
पहली बात यह है कि तर्कसंगत रिटर्न को चुना जाना चाहिए, यदि यह बहुत अच्छा नहीं है, तो इसके परिणामों को एक आधार के रूप में संदर्भित किया जा सकता है, और अन्य एल्गोरिदम के साथ तुलना की जा सकती है;
फिर निर्णय पेड़ों (या यादृच्छिक जंगलों) का परीक्षण करें और देखें कि क्या आप अपने मॉडल की प्रदर्शन में काफी सुधार कर सकते हैं। यहां तक कि अगर आप इसे अंतिम मॉडल के रूप में नहीं लेते हैं, तो आप विशेषताओं के चयन के लिए शोर चर को हटाने के लिए यादृच्छिक जंगलों का उपयोग कर सकते हैं।
यदि विशेषताओं की संख्या और अवलोकन के नमूने विशेष रूप से अधिक हैं, तो एसवीएम का उपयोग करना एक विकल्प है जब संसाधन और समय पर्याप्त है (यह महत्वपूर्ण है) ।
सामान्य तौर परः GBDT>=SVM>=RF>=Adaboost>=Other… , अब गहरी सीखना बहुत लोकप्रिय है, कई क्षेत्रों में उपयोग किया जाता है, यह तंत्रिका नेटवर्क पर आधारित है, वर्तमान में मैं खुद भी सीख रहा हूं, केवल सैद्धांतिक ज्ञान बहुत ठोस नहीं है, समझने के लिए पर्याप्त गहरा नहीं है, यहां परिचय नहीं दिया गया है।
एल्गोरिदम महत्वपूर्ण हैं, लेकिन अच्छे डेटा अच्छे एल्गोरिदम से बेहतर हैं, और अच्छे डिज़ाइन की विशेषताएं बहुत फायदेमंद हैं। यदि आपके पास एक विशाल डेटासेट है, तो आप जो भी एल्गोरिदम का उपयोग करते हैं, वह वर्गीकरण प्रदर्शन पर बहुत अधिक प्रभाव नहीं डाल सकता है। (इस समय, गति और उपयोग में आसानी के आधार पर निर्णय लिया जा सकता है) ।
-
संदर्भ