
1 परिचय
पिछले लेख में बिटकॉइन की कीमतों का अनुमान लगाने के लिए LSTM नेटवर्क के उपयोग की जानकारी दी गई थी https://www.fmz.com/digest-topic/4035. जैसा कि लेख में बताया गया है, यह RNN और पाइटॉर्च से परिचित होने और अभ्यास करने के लिए एक छोटा सा प्रोजेक्ट है . यह आलेख ट्रेडिंग रणनीतियों को सीधे प्रशिक्षित करने के लिए सुदृढीकरण सीखने के तरीकों के उपयोग का परिचय देगा। सुदृढीकरण सीखने का मॉडल ओपनएआई द्वारा ओपन सोर्स किया गया पीपीओ है, और इसका वातावरण जिम की शैली पर आधारित है। समझने और परीक्षण को सुविधाजनक बनाने के लिए, एलएसटीएम पीपीओ मॉडल और बैकटेस्टिंग जिम वातावरण को तैयार पैकेजों का उपयोग किए बिना सीधे लिखा जाता है।
पीपीओ, प्रॉक्सिमल पॉलिसी ऑप्टिमाइज़ेशन का पूरा नाम है, जो पॉलिसी ग्रेडिएंट, यानी पॉलिसी ग्रेडिएंट का एक ऑप्टिमाइज़ेशन सुधार है। जिम को भी ओपनएआई द्वारा जारी किया गया है। यह नीति नेटवर्क के साथ बातचीत कर सकता है और पर्यावरण की वर्तमान स्थिति और इनाम का फीडबैक दे सकता है। यह सुदृढीकरण सीखने के अभ्यास की तरह है जो LSTM PPO मॉडल का उपयोग करके सीधे खरीद, बिक्री या कोई ऑपरेशन नहीं करता है। बिटकॉइन की बाजार जानकारी। बैकटेस्टिंग वातावरण द्वारा निर्देश दिए जाते हैं, और रणनीति लाभप्रदता के लक्ष्य को प्राप्त करने के लिए मॉडल को प्रशिक्षण के माध्यम से लगातार अनुकूलित किया जाता है।
इस लेख को पढ़ने के लिए पायथन, पाइटॉर्च और डीआरएल डीप रीइन्फोर्समेंट लर्निंग में एक निश्चित आधार की आवश्यकता है। लेकिन अगर आपको नहीं पता कि यह कैसे करना है तो कोई बात नहीं। इस लेख में दिए गए कोड से इसे सीखना और शुरू करना आसान है। यह लेख डिजिटल मुद्रा मात्रात्मक ट्रेडिंग प्लेटफॉर्म (www.fmz.com) के आविष्कारक FMZ द्वारा निर्मित है। QQ समूह में शामिल होने के लिए आपका स्वागत है: संचार के लिए 863946592।
2. डेटा और सीखने के संदर्भ
बिटकॉइन मूल्य डेटा FMZ इन्वेंटर क्वांटिटेटिव ट्रेडिंग प्लेटफॉर्म से आता है: https://www.quantinfo.com/Tools/View/4.html
ट्रेडिंग रणनीतियों को प्रशिक्षित करने के लिए DRL+gym का उपयोग करने पर एक लेख: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
पाइटोरच के साथ शुरुआत करने के कुछ उदाहरण: https://github.com/yunjey/pytorch-tutorial
यह लेख सीधे LSTM-PPO मॉडल के इस संक्षिप्त कार्यान्वयन का उपयोग करेगा: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
पीपीओ के बारे में लेख: https://zhuanlan.zhihu.com/p/38185553
डीआरएल के बारे में अधिक लेख: https://www.zhihu.com/people/flood-sung/posts
जिम के संबंध में, इस लेख को इसे स्थापित करने की आवश्यकता नहीं है, लेकिन सुदृढीकरण सीखना बहुत आम है: https://gym.openai.com/
3.LSTM-PPO
PPO की गहन व्याख्या के लिए, आप पिछले संदर्भों का अध्ययन कर सकते हैं। यहाँ केवल सरल अवधारणा का परिचय दिया गया है। पिछले अंक में, LSTM नेटवर्क ने केवल कीमत का पूर्वानुमान लगाया था। इस पूर्वानुमानित कीमत के आधार पर लेन-देन कैसे खरीदें और बेचें, इसे अलग से लागू करने की आवश्यकता है। स्वाभाविक रूप से, यह कल्पना की जा सकती है कि खरीद और बिक्री क्रियाओं को सीधे आउटपुट करना अधिक प्रत्यक्ष होगा , सही? पॉलिसी ग्रेडिएंट भी ऐसा ही है। यह इनपुट पर्यावरण संबंधी जानकारी के आधार पर विभिन्न क्रियाओं की संभावना बता सकता है। एलएसटीएम की हानि पूर्वानुमानित मूल्य और वास्तविक मूल्य के बीच का अंतर है, जबकि पीजी की हानि -लॉग(पी) है*Q, जहाँ p किसी क्रिया के आउटपुट होने की संभावना है, और Q क्रिया का मान है (जैसे कि रिवॉर्ड स्कोर)। सहज व्याख्या यह है कि यदि किसी क्रिया का मान अधिक है, तो नेटवर्क को उच्च संभावना आउटपुट करनी चाहिए नुकसान को कम करने के लिए. हालाँकि PPO बहुत ज़्यादा जटिल है, लेकिन सिद्धांत समान है। मुख्य बात यह है कि प्रत्येक क्रिया के मूल्य का बेहतर मूल्यांकन कैसे किया जाए और मापदंडों को बेहतर तरीके से कैसे अपडेट किया जाए।
LSTM-PPO का स्रोत कोड नीचे दिया गया है, जिसे पिछली जानकारी के साथ मिलाकर समझा जा सकता है:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. बिटकॉइन बैकटेस्टिंग वातावरण
जिम के प्रारूप के अनुसार, रीसेट आरंभीकरण विधि, चरण इनपुट क्रिया है, और लौटाया गया परिणाम है (अगली स्थिति, क्रिया लाभ, क्या यह समाप्त हो गया है, अतिरिक्त जानकारी)। संपूर्ण बैकटेस्ट वातावरण केवल 60 पंक्तियों का है, जिसे अपने द्वारा संशोधित। जटिल संस्करण, विशिष्ट कोड:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. कई उल्लेखनीय विवरण
प्रारंभिक खाते में सिक्के क्यों होते हैं?
बैकटेस्टिंग वातावरण में रिटर्न की गणना करने का सूत्र है: चालू रिटर्न = चालू खाता मूल्य - प्रारंभिक खाता चालू मूल्य। इसका मतलब यह है कि यदि बिटकॉइन की कीमत गिरती है और रणनीति सिक्के बेचती है, तो रणनीति को वास्तव में पुरस्कृत किया जाना चाहिए, भले ही कुल खाता मूल्य कम हो जाए। यदि बैकटेस्टिंग अवधि लंबी है, तो प्रारंभिक खाते पर अधिक प्रभाव नहीं पड़ेगा, लेकिन फिर भी शुरुआत में इसका बड़ा प्रभाव पड़ेगा। सापेक्ष प्रतिफल की गणना यह सुनिश्चित करती है कि प्रत्येक सही संचालन से सकारात्मक प्रतिफल प्राप्त हो।
प्रशिक्षण के दौरान हम बाज़ार का नमूना क्यों लेते हैं?
डेटा की कुल मात्रा 10,000 K-लाइनों से ज़्यादा है। अगर हर बार पूरा चक्र चलाया जाए, तो इसमें काफ़ी समय लगेगा और रणनीति हर बार बिल्कुल एक जैसी स्थिति का सामना करेगी, जिससे ओवरफ़िटिंग हो सकती है। बैकटेस्ट डेटा के रूप में हर बार 500 बार खींचे जाते हैं। हालाँकि ओवरफिटिंग अभी भी संभव है, लेकिन रणनीति 10,000 से ज़्यादा अलग-अलग संभावित शुरुआतों का सामना करती है।
यदि आपके पास सिक्के या पैसे न हों तो क्या करें?
बैकटेस्ट वातावरण में इस स्थिति पर विचार नहीं किया जाता है। यदि सिक्का बिक चुका है या न्यूनतम लेनदेन मात्रा तक नहीं पहुंचा है, तो इस समय बिक्री ऑपरेशन को निष्पादित करना वास्तव में कोई ऑपरेशन निष्पादित करने के बराबर है। यदि कीमत गिरती है, तो सापेक्ष के अनुसार रिटर्न गणना पद्धति, यह अभी भी रणनीति के सकारात्मक इनाम पर आधारित है। इस स्थिति का प्रभाव यह है कि जब रणनीति यह निर्धारित करती है कि बाजार गिर रहा है और खाते में शेष सिक्के बेचे नहीं जा सकते हैं, तो बिक्री कार्यों और कोई संचालन नहीं करने के बीच अंतर करना असंभव है, लेकिन इसका रणनीति के अपने निर्णय पर कोई प्रभाव नहीं पड़ता है। बाजार.
खाता जानकारी को स्थिति के रूप में क्यों लौटाया जाए?
पीपीओ मॉडल में एक वैल्यू नेटवर्क होता है जिसका उपयोग वर्तमान स्थिति के मूल्य का मूल्यांकन करने के लिए किया जाता है। जाहिर है, अगर रणनीति यह निर्धारित करती है कि कीमत बढ़ने वाली है, तो पूरी स्थिति का मूल्य केवल तभी सकारात्मक होगा जब चालू खाते में बिटकॉइन हो, और इसके विपरीत। इसलिए, मूल्य नेटवर्क का आकलन करने के लिए खाता जानकारी एक महत्वपूर्ण आधार है। ध्यान दें कि पिछली कार्रवाई की जानकारी स्थिति के रूप में नहीं लौटाई जाती है, जो कि मैं व्यक्तिगत रूप से मानता हूं कि मूल्य निर्धारण के लिए बेकार है।
किन परिस्थितियों में यह कोई ऑपरेशन नहीं करेगा?
जब रणनीति यह निर्धारित कर ले कि क्रय-विक्रय से प्राप्त लाभ, लेन-देन शुल्क को कवर नहीं कर सकता, तो उसे कोई कार्रवाई नहीं करनी चाहिए। हालाँकि पिछले विवरण में मूल्य प्रवृत्तियों को निर्धारित करने के लिए बार-बार रणनीतियों का उपयोग किया गया था, यह केवल समझने में आसानी के लिए था। वास्तव में, यह पीपीओ मॉडल बाजार के बारे में कोई भविष्यवाणी नहीं करता है, बल्कि केवल तीन क्रियाओं की संभावनाओं को आउटपुट करता है।
6. डेटा अधिग्रहण और प्रशिक्षण
पिछले लेख की तरह, डेटा निम्न प्रारूप में प्राप्त किया गया है: 2018/5/7 से 2019/6/27 तक बिटफ़ाइनक्स एक्सचेंज पर BTC_USD ट्रेडिंग जोड़ी की एक घंटे की K-लाइन:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
चूंकि LSTM नेटवर्क का उपयोग किया गया था, इसलिए प्रशिक्षण का समय बहुत लंबा था, इसलिए मैंने GPU संस्करण में बदलाव किया, जो लगभग 3 गुना तेज था।
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. प्रशिक्षण परिणाम और विश्लेषण
लम्बे इंतजार के बाद:

सबसे पहले, आइए प्रशिक्षण डेटा के बाजार के रुझान पर एक नज़र डालें। आम तौर पर, पहली छमाही में एक लंबी गिरावट थी, और दूसरी छमाही में एक मजबूत पलटाव था।
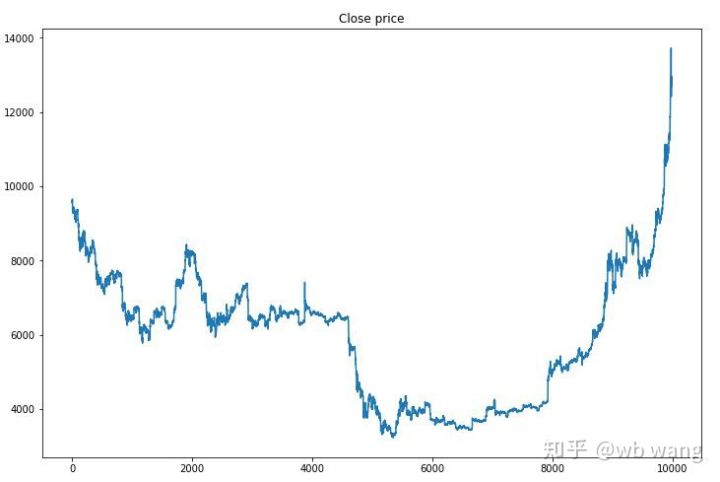
प्रशिक्षण के प्रारंभिक चरण में बहुत सारी खरीदारी होती है, तथा मूलतः कोई लाभदायक दौर नहीं होता। प्रशिक्षण अवधि के मध्य तक, खरीद कार्यों की संख्या धीरे-धीरे कम हो गई, और लाभ की संभावना अधिक से अधिक हो गई, लेकिन नुकसान की संभावना अभी भी अधिक थी।
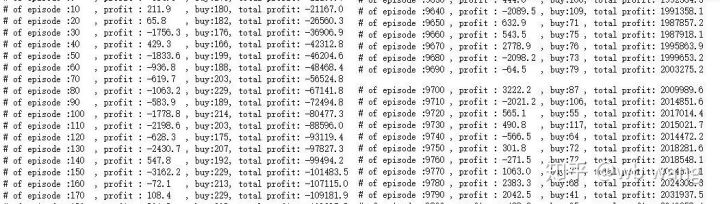
प्रति राउंड राजस्व का आकलन करने पर परिणाम इस प्रकार हैं:
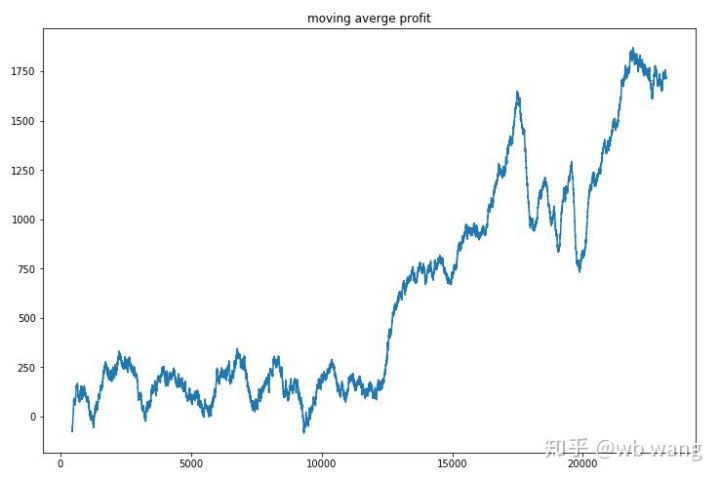
इस रणनीति ने शुरुआती चरणों में नकारात्मक रिटर्न से जल्दी छुटकारा पा लिया, लेकिन उतार-चढ़ाव बड़े थे। 10,000 राउंड तक रिटर्न तेजी से बढ़ने नहीं लगा। सामान्य तौर पर, मॉडल प्रशिक्षण मुश्किल था।
अंतिम प्रशिक्षण पूरा होने के बाद, मॉडल को सभी डेटा को फिर से चलाने दें ताकि यह देखा जा सके कि यह कैसा प्रदर्शन करता है। इस अवधि के दौरान, खाते का कुल बाजार मूल्य, रखे गए बिटकॉइन की संख्या, बिटकॉइन मूल्य का अनुपात और कुल आय रिकॉर्ड करें .
सबसे पहले कुल बाजार मूल्य है। कुल राजस्व भी लगभग इतना ही है, इसलिए मैं इसे यहाँ पोस्ट नहीं करूँगा:
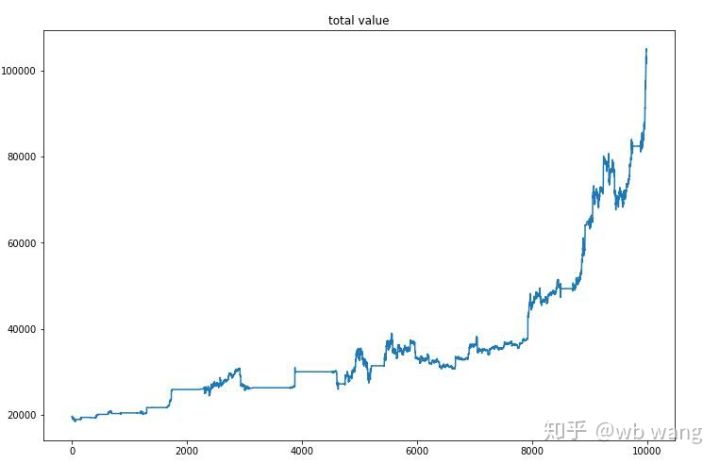
शुरुआती मंदी के दौरान कुल बाजार मूल्य में धीरे-धीरे वृद्धि हुई और बाद के तेजी के बाजार के दौरान भी इसमें वृद्धि जारी रही, लेकिन फिर भी समय-समय पर नुकसान होता रहा।
अंत में, आइए पदों के अनुपात पर एक नज़र डालें। ग्राफ का बायाँ अक्ष पदों का अनुपात है, और दायाँ अक्ष बाज़ार की स्थिति है। यह प्रारंभिक रूप से निर्धारित किया जा सकता है कि मॉडल ओवरफ़िट हो गया है। पदों की आवृत्ति थी शुरुआती मंदी के बाजार में स्थिति बहुत कम थी, और बाजार के निचले स्तर पर स्थिति की आवृत्ति बहुत अधिक थी। हम यह भी देख सकते हैं कि मॉडल ने लंबे समय तक पोजीशन को होल्ड करना नहीं सीखा है और हमेशा जल्दी ही बेच देता है।
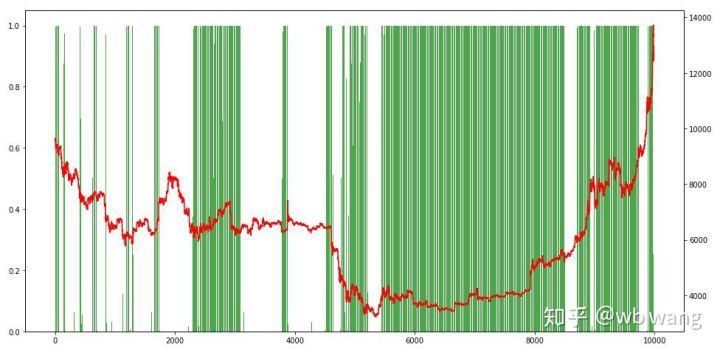
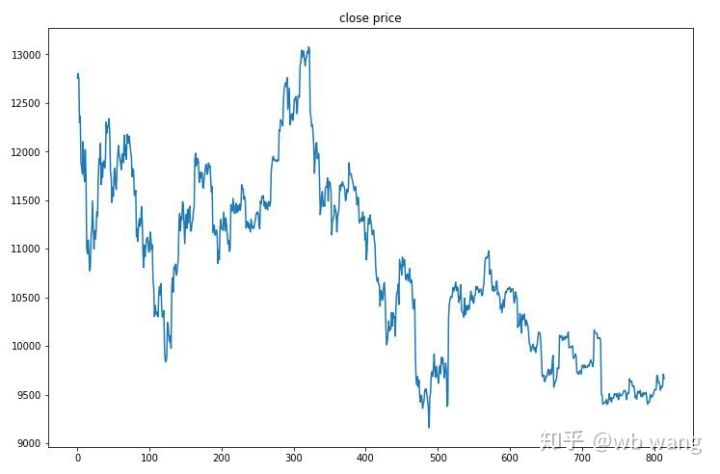
8. परीक्षण डेटा विश्लेषण
परीक्षण डेटा 2019/6/27 से वर्तमान तक एक घंटे के बिटकॉइन बाजार से प्राप्त किया गया था। जैसा कि आंकड़े से देखा जा सकता है, कीमत शुरुआत में $13,000 से गिरकर आज $9,000 से अधिक हो गई है, जो मॉडल के लिए एक बड़ी परीक्षा है।
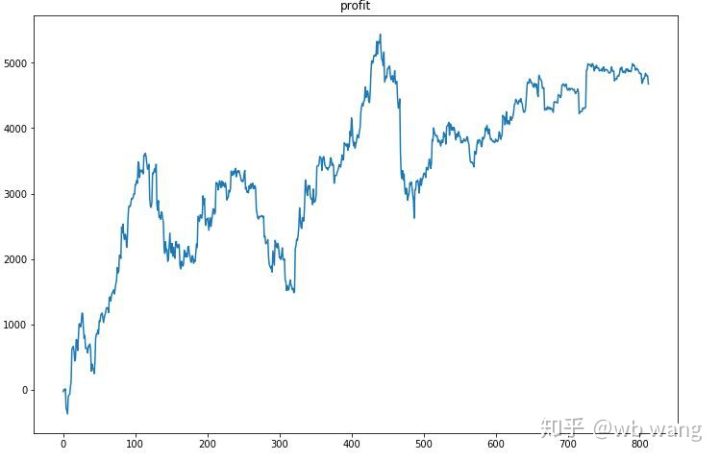
सबसे पहले तो अंतिम सापेक्ष लाभ संतोषजनक नहीं था, लेकिन कोई हानि भी नहीं हुई।
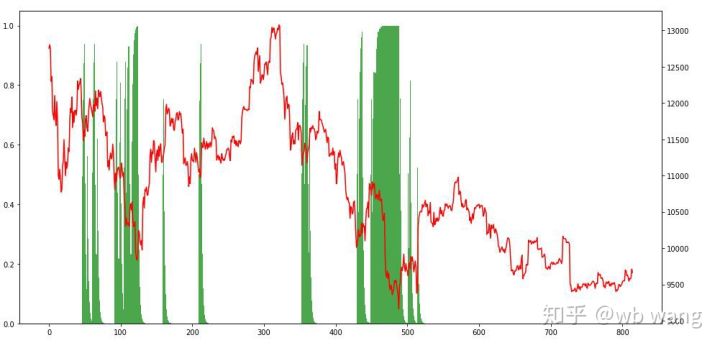
पोजीशन को देखते हुए, हम अनुमान लगा सकते हैं कि मॉडल तेज गिरावट के बाद खरीदने और पलटाव के बाद बेचने की प्रवृत्ति रखता है। हाल के दिनों में, बिटकॉइन बाजार में बहुत कम उतार-चढ़ाव आया है और मॉडल शॉर्ट पोजीशन में रहा है।
9. सारांश
यह लेख बिटकॉइन स्वचालित ट्रेडिंग रोबोट को प्रशिक्षित करने के लिए गहन सुदृढीकरण सीखने की विधि पीपीओ का उपयोग करता है और कुछ निष्कर्ष प्राप्त करता है। सीमित समय के कारण, मॉडल में अभी भी कुछ ऐसे क्षेत्र हैं जिनमें सुधार किया जा सकता है। चर्चा के लिए सभी का स्वागत है। सबसे बड़ी सीख यह है कि डेटा मानकीकरण ही सही तरीका है। स्केलिंग जैसे तरीकों का इस्तेमाल न करें, वरना मॉडल जल्दी ही कीमत और बाजार की स्थितियों के बीच के रिश्ते को याद कर लेगा और ओवरफिटिंग में पड़ जाएगा। सामान्यीकरण के बाद, परिवर्तन की दर सापेक्ष डेटा बन जाती है, जिससे मॉडल के लिए बाजार के साथ अपने संबंध को याद रखना मुश्किल हो जाता है और उसे परिवर्तन की दर और वृद्धि और गिरावट के बीच संबंध खोजने के लिए मजबूर होना पड़ता है।
पिछले लेख:
FMZ इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म पर कुछ सार्वजनिक रणनीति साझा करना: https://zhuanlan.zhihu.com/p/64961672
नेटएज़ क्लाउड क्लासरूम का डिजिटल मुद्रा मात्रात्मक ट्रेडिंग कोर्स, केवल 20 युआन: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
मैंने एक उच्च आवृत्ति रणनीति सार्वजनिक की है जो कभी बहुत लाभदायक थी: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1