ट्रेडिंग में मशीन लर्निंग प्रौद्योगिकी का अनुप्रयोग
लेखक:लिडिया, बनाया गयाः 2022-12-30 10:53:07, अद्यतन किया गयाः 2023-09-20 09:30:09
ट्रेडिंग में मशीन लर्निंग प्रौद्योगिकी का अनुप्रयोग
इस लेख की प्रेरणा कुछ आम चेतावनी और जाल के मेरे अवलोकन से आती है जब मैंने एफएमजेड क्वांट प्लेटफॉर्म पर डेटा अनुसंधान के दौरान लेनदेन की समस्याओं पर मशीन लर्निंग तकनीक को लागू करने की कोशिश की।
यदि आपने मेरे पिछले लेख नहीं पढ़े हैं, तो हम आपको स्वचालित डेटा अनुसंधान वातावरण गाइड और ट्रेडिंग रणनीतियों को तैयार करने के लिए व्यवस्थित विधि पढ़ने का सुझाव देते हैं जो मैंने इस लेख से पहले एफएमजेड क्वांट प्लेटफॉर्म पर स्थापित किया था।
इन दो लेखों के पते यहाँ दिए गए हैंःhttps://www.fmz.com/digest-topic/9862औरhttps://www.fmz.com/digest-topic/9863.
अनुसंधान वातावरण की स्थापना के बारे में
यह ट्यूटोरियल सभी कौशल स्तरों के उत्साही, इंजीनियरों और डेटा वैज्ञानिकों के लिए है। चाहे आप एक उद्योग के नेता हों या प्रोग्रामिंग नौसिखिया, आपको केवल पायथन प्रोग्रामिंग भाषा की बुनियादी समझ और कमांड लाइन संचालन के पर्याप्त ज्ञान की आवश्यकता है (डेटा साइंस परियोजना स्थापित करने में सक्षम होना पर्याप्त है) ।
- एफएमजेड क्वांट डॉकर स्थापित करें और एनाकोंडा सेट करें
एफएमजेड क्वांट प्लेटफार्मFMZ.COMयह न केवल प्रमुख मुख्यधारा के एक्सचेंजों के लिए उच्च गुणवत्ता वाले डेटा स्रोत प्रदान करता है, बल्कि डेटा विश्लेषण पूरा करने के बाद स्वचालित लेनदेन करने में हमारी सहायता करने के लिए समृद्ध एपीआई इंटरफेस का एक सेट भी प्रदान करता है। इंटरफेस के इस सेट में व्यावहारिक उपकरण शामिल हैं, जैसे कि खाता जानकारी पूछना, उच्च, खुला, कम, प्राप्ति मूल्य, व्यापार मात्रा, और विभिन्न मुख्यधारा के एक्सचेंजों के विभिन्न सामान्य रूप से उपयोग किए जाने वाले तकनीकी विश्लेषण संकेतक। विशेष रूप से, यह वास्तविक व्यापार प्रक्रिया में प्रमुख मुख्यधारा के एक्सचेंजों को जोड़ने वाले सार्वजनिक एपीआई इंटरफेस के लिए मजबूत तकनीकी समर्थन प्रदान करता है।
उपरोक्त सभी सुविधाओं को डॉकर जैसी प्रणाली में शामिल किया गया है। हमें अपनी क्लाउड कंप्यूटिंग सेवाओं को खरीदने या पट्टे पर लेने और डॉकर प्रणाली को तैनात करने की आवश्यकता है।
एफएमजेड क्वांट प्लेटफॉर्म के आधिकारिक नाम में, डॉकर सिस्टम को डॉकर सिस्टम कहा जाता है।
कृपया एक डॉकर और रोबोट तैनात करने के लिए मेरे पिछले लेख देखेंःhttps://www.fmz.com/bbs-topic/9864.
जो पाठक डॉकरों को तैनात करने के लिए अपना स्वयं का क्लाउड कंप्यूटिंग सर्वर खरीदना चाहते हैं, वे इस लेख का संदर्भ ले सकते हैंःhttps://www.fmz.com/digest-topic/5711.
बाद में क्लाउड कंप्यूटिंग सर्वर और डॉकर प्रणाली को सफलतापूर्वक तैनात करने के बाद, अगला हम पाइथन के वर्तमान सबसे बड़े कलाकृतियों को स्थापित करेंगेः एनाकोंडा
इस लेख में आवश्यक सभी प्रासंगिक प्रोग्राम वातावरण (निर्भरता पुस्तकालय, संस्करण प्रबंधन, आदि) को महसूस करने के लिए, सबसे सरल तरीका एनाकोंडा का उपयोग करना है। यह एक पैक किया गया पायथन डेटा विज्ञान पारिस्थितिकी तंत्र और निर्भरता पुस्तकालय प्रबंधक है।
चूंकि हम Anaconda को क्लाउड सेवा पर स्थापित करते हैं, इसलिए हम अनुशंसा करते हैं कि क्लाउड सर्वर ने Anaconda के कमांड लाइन संस्करण के साथ लिनक्स सिस्टम को स्थापित किया हो।
Anaconda की स्थापना विधि के लिए, कृपया Anaconda की आधिकारिक गाइड देखेंःhttps://www.anaconda.com/distribution/.
यदि आप एक अनुभवी पायथन प्रोग्रामर हैं और यदि आपको लगता है कि आपको एनाकोंडा का उपयोग करने की आवश्यकता नहीं है, तो यह कोई समस्या नहीं है। मैं मानूंगा कि आपको आवश्यक निर्भर वातावरण स्थापित करने में मदद की आवश्यकता नहीं है। आप इस अनुभाग को सीधे छोड़ सकते हैं।
एक व्यापारिक रणनीति विकसित करें
व्यापारिक रणनीति के अंतिम परिणाम में निम्नलिखित प्रश्नों का उत्तर देना चाहिए:
-
दिशाः यह निर्धारित करें कि संपत्ति सस्ती, महंगी या उचित मूल्य है या नहीं।
-
शुरुआती स्थिति की शर्तेंः यदि संपत्ति सस्ती या महंगी है, तो आपको लंबी या छोटी स्थिति में जाना चाहिए।
-
बंद करने की स्थिति व्यापारः यदि परिसंपत्ति का उचित मूल्य है और हमारे पास परिसंपत्ति में एक स्थिति है (पिछली खरीद या बिक्री), तो क्या आपको स्थिति बंद करनी चाहिए?
-
मूल्य सीमाः वह मूल्य (या सीमा) जिस पर स्थिति खोली गई थी।
-
मात्राः कारोबार की जाने वाली धनराशि की मात्रा (उदाहरण के लिए, डिजिटल मुद्रा की राशि या कमोडिटी वायदा के बहुतों की संख्या) ।
मशीन लर्निंग का उपयोग इन सवालों के हर एक का जवाब देने के लिए किया जा सकता है, लेकिन इस लेख के बाकी के लिए, हम पहले प्रश्न पर ध्यान केंद्रित करेंगे, जो व्यापार की दिशा है।
रणनीतिक दृष्टिकोण
रणनीतियों के निर्माण के लिए दो प्रकार के दृष्टिकोण हैंः एक मॉडल-आधारित है; दूसरा डेटा खनन पर आधारित है। ये दोनों तरीके मूल रूप से एक दूसरे के विपरीत हैं।
मॉडल आधारित रणनीति निर्माण में, हम बाजार अक्षमता मॉडल से शुरू करते हैं, गणितीय अभिव्यक्तियों (जैसे मूल्य और लाभ) का निर्माण करते हैं और लंबी अवधि में उनकी प्रभावशीलता का परीक्षण करते हैं। यह मॉडल आमतौर पर एक वास्तविक जटिल मॉडल का एक सरलीकृत संस्करण होता है, और इसके दीर्घकालिक महत्व और स्थिरता की पुष्टि करने की आवश्यकता होती है। निम्नलिखित सामान्य प्रवृत्ति, औसत प्रतिगमन और मध्यस्थता रणनीतियां इस श्रेणी में आती हैं।
दूसरी ओर, हम पहले मूल्य पैटर्न की तलाश करते हैं और डेटा खनन विधियों में एल्गोरिदम का उपयोग करने का प्रयास करते हैं। इन पैटर्न के कारण महत्वपूर्ण नहीं हैं, क्योंकि केवल पहचाने गए पैटर्न भविष्य में दोहराए जाएंगे। यह एक अंधा विश्लेषण विधि है, और हमें यादृच्छिक पैटर्न से वास्तविक पैटर्न की पहचान करने के लिए सख्ती से जांच करने की आवश्यकता है।
स्पष्ट रूप से, मशीन लर्निंग को डेटा खनन विधियों पर लागू करना बहुत आसान है। आइए देखें कि डेटा खनन के माध्यम से लेनदेन संकेत बनाने के लिए मशीन लर्निंग का उपयोग कैसे करें।
कोड उदाहरण एफएमजेड क्वांट प्लेटफॉर्म और एक स्वचालित लेनदेन एपीआई इंटरफ़ेस पर आधारित बैकटेस्टिंग टूल का उपयोग करता है। डॉकर को तैनात करने और उपरोक्त अनुभाग में एनाकोंडा स्थापित करने के बाद, आपको केवल डेटा विज्ञान विश्लेषण पुस्तकालय को स्थापित करने की आवश्यकता है और प्रसिद्ध मशीन लर्निंग मॉडल scikit-learn। हम इस अनुभाग पर फिर से नहीं जाएंगे।
pip install -U scikit-learn
ट्रेडिंग रणनीति संकेत बनाने के लिए मशीन लर्निंग का उपयोग करें
-डेटा खनन शुरू करने से पहले, एक मानक मशीन लर्निंग समस्या प्रणाली निम्नलिखित चित्र में दिखाई गई हैः
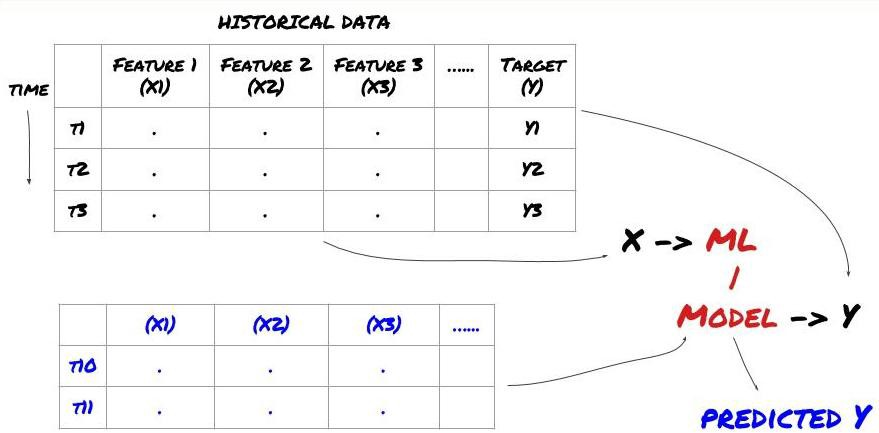
मशीन लर्निंग समस्या प्रणाली
हम जो सुविधा बनाने जा रहे हैं उसके पास कुछ पूर्वानुमान क्षमता (X) होनी चाहिए। हम लक्ष्य चर (Y) की भविष्यवाणी करना चाहते हैं और ऐतिहासिक डेटा का उपयोग एमएल मॉडल को प्रशिक्षित करने के लिए करते हैं जो वास्तविक मूल्य के जितना संभव हो उतना Y की भविष्यवाणी कर सकता है। अंत में, हम इस मॉडल का उपयोग नए डेटा पर भविष्यवाणियां करने के लिए करते हैं जहां Y अज्ञात है। यह हमें पहले चरण की ओर ले जाता हैः
चरण 1: अपना प्रश्न पूछें
- आप क्या भविष्यवाणी करना चाहते हैं? एक अच्छी भविष्यवाणी क्या है? आप भविष्यवाणी के परिणामों का मूल्यांकन कैसे करते हैं?
यही है, ऊपर हमारे ढांचे में, क्या है Y?
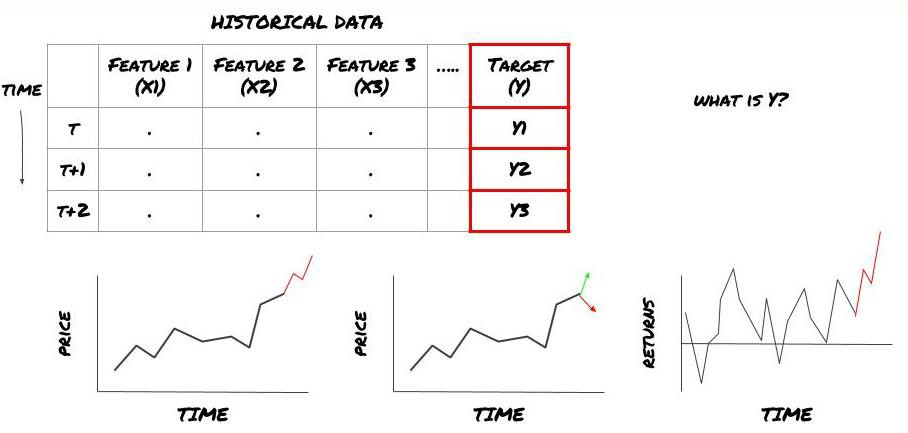
आप क्या भविष्यवाणी करना चाहते हैं?
क्या आप भविष्य की कीमतों, भविष्य के रिटर्न/पीएनएल, खरीद/बिक्री संकेतों का पूर्वानुमान लगाना चाहते हैं, पोर्टफोलियो आवंटन को अनुकूलित करना चाहते हैं और लेनदेन को कुशलतापूर्वक निष्पादित करने का प्रयास करना चाहते हैं?
मान लीजिए कि हम अगले टाइमस्टैम्प पर कीमतों का अनुमान लगाने की कोशिश करते हैं। इस मामले में, Y (t) = कीमत (t + 1) अब हम अपने ढांचे को पूरा करने के लिए ऐतिहासिक डेटा का उपयोग कर सकते हैं।
ध्यान दें कि Y (t) केवल बैकटेस्ट में ज्ञात है, लेकिन जब हम अपने मॉडल का उपयोग करते हैं, तो हम समय t की कीमत (t + 1) नहीं जानते हैं। हम Y (पूर्वानुमानित, t) की भविष्यवाणी करने के लिए अपने मॉडल का उपयोग करते हैं और इसकी तुलना केवल समय t + 1 पर वास्तविक मूल्य के साथ करते हैं। इसका मतलब है कि आप Y का उपयोग भविष्यवाणी मॉडल में एक विशेषता के रूप में नहीं कर सकते।
एक बार जब हम लक्ष्य Y को जानते हैं, तो हम यह भी तय कर सकते हैं कि हम अपनी भविष्यवाणियों का मूल्यांकन कैसे करते हैं। यह उन डेटा के विभिन्न मॉडलों के बीच अंतर करने के लिए महत्वपूर्ण है जिन्हें हम कोशिश करेंगे। हम जिस समस्या को हल कर रहे हैं उसके अनुसार हमारे मॉडल की दक्षता को मापने के लिए एक संकेतक का चयन करें। उदाहरण के लिए, यदि हम कीमतों की भविष्यवाणी करते हैं, तो हम एक संकेतक के रूप में रूट मीड स्क्वायर त्रुटि का उपयोग कर सकते हैं। कुछ आमतौर पर उपयोग किए जाने वाले संकेतक (ईएमए, एमएसीडी, विचलन स्कोर, आदि) को एफएमजेड क्वांट टूलबॉक्स में पूर्व-कोड किया गया है। आप इन संकेतकों को एपीआई इंटरफ़ेस के माध्यम से वैश्विक रूप से कॉल कर सकते हैं।
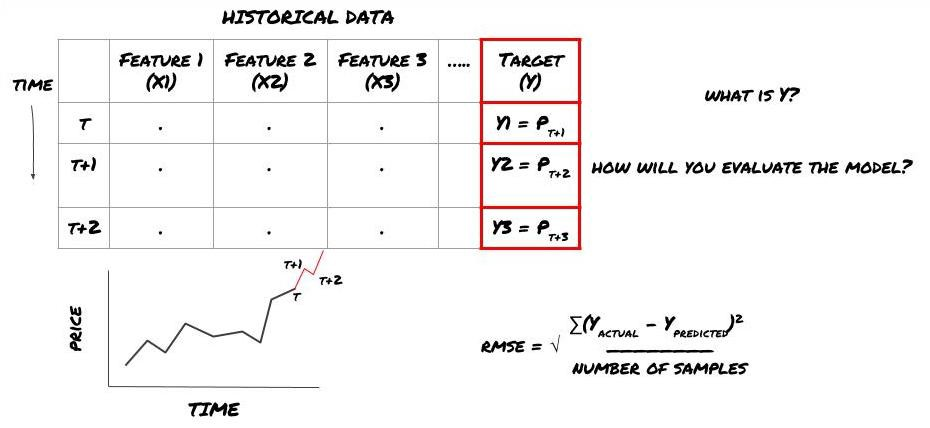
भविष्य की कीमतों की भविष्यवाणी के लिए एमएल ढांचा
प्रदर्शन के प्रयोजनों के लिए, हम एक काल्पनिक निवेश वस्तु के भविष्य के अपेक्षित बेंचमार्क (आधार) मूल्य की भविष्यवाणी करने के लिए एक पूर्वानुमान मॉडल बनाएंगे, जहांः
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
चूंकि यह एक प्रतिगमन समस्या है, हम RMSE (मूल औसत वर्ग त्रुटि) पर मॉडल का मूल्यांकन करेंगे। हम मूल्यांकन मानदंड के रूप में कुल Pnl का भी उपयोग करेंगे।
नोटः RMSE के प्रासंगिक गणितीय ज्ञान के लिए कृपया Baidu विश्वकोश देखें।
- हमारा लक्ष्य: एक मॉडल बनाने के लिए Y के निकट संभव के रूप में भविष्यवाणी मूल्य बनाने के लिए।
चरण 2: विश्वसनीय डेटा एकत्र करें
उस समस्या को हल करने में मदद करने के लिए डेटा एकत्र करें और साफ करें।
आपको किन आंकड़ों पर विचार करने की आवश्यकता है जो लक्ष्य चर Y की भविष्यवाणी कर सकें? यदि हम कीमत की भविष्यवाणी करते हैं, तो आप निवेश वस्तु के मूल्य डेटा, निवेश वस्तु के व्यापार मात्रा डेटा, संबंधित निवेश वस्तु के समान डेटा, निवेश वस्तु के सूचकांक स्तर और अन्य समग्र बाजार संकेतकों का उपयोग कर सकते हैं, और अन्य संबंधित परिसंपत्तियों की कीमत।
आपको इन डेटा के लिए डेटा एक्सेस अनुमतियों को सेट करने और यह सुनिश्चित करने की आवश्यकता है कि आपके डेटा सटीक हैं, और खोए हुए डेटा को हल करें (एक बहुत ही आम समस्या) । साथ ही, यह सुनिश्चित करें कि आपके डेटा निष्पक्ष हैं और सभी बाजार की स्थितियों का पूरी तरह से प्रतिनिधित्व करते हैं (उदाहरण के लिए, लाभ और हानि परिदृश्यों की समान संख्या) मॉडल में पूर्वाग्रह से बचने के लिए। आपको लाभांश, विभाजित निवेश लक्ष्य, निरंतरता आदि प्राप्त करने के लिए डेटा को साफ करने की भी आवश्यकता हो सकती है।
यदि आप FMZ क्वांट प्लेटफॉर्म (FMZ.COM) का उपयोग करते हैं, तो हम Google, Yahoo, NSE और Quandl से मुफ्त वैश्विक डेटा एक्सेस कर सकते हैं; सीटीपी और एसुनी जैसे घरेलू कमोडिटी वायदा के गहराई के डेटा; बिनेंस, ओकेएक्स, हुओबी और बिटकॉइन जैसे मुख्यधारा के डिजिटल मुद्रा एक्सचेंजों के डेटा। FMZ क्वांट प्लेटफॉर्म इन डेटा को भी पूर्व-साफ करता है और फ़िल्टर करता है, जैसे कि निवेश लक्ष्यों के विभाजन और गहन बाजार डेटा, और उन्हें रणनीति डेवलपर्स को एक प्रारूप में प्रस्तुत करता है जो मात्रात्मक चिकित्सकों के लिए समझ में आसान है।
इस लेख के प्रदर्शन की सुविधा के लिए, हम आभासी निवेश लक्ष्य के
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
उपरोक्त कोड के साथ, Auquan
चरण 3: डेटा को विभाजित करें
- प्रशिक्षण सेट बनाएँ, क्रॉस सत्यापन करें और इन डेटा सेटों का डेटा से परीक्षण करें।
यह एक बहुत ही महत्वपूर्ण कदम है!आगे बढ़ने से पहले, हमें अपने मॉडल को प्रशिक्षित करने के लिए डेटा को प्रशिक्षण डेटा सेट में विभाजित करना चाहिए; मॉडल प्रदर्शन का मूल्यांकन करने के लिए परीक्षण डेटा सेट। उन्हें 60-70% प्रशिक्षण सेट और 30-40% परीक्षण सेट में विभाजित करने की सिफारिश की जाती है।
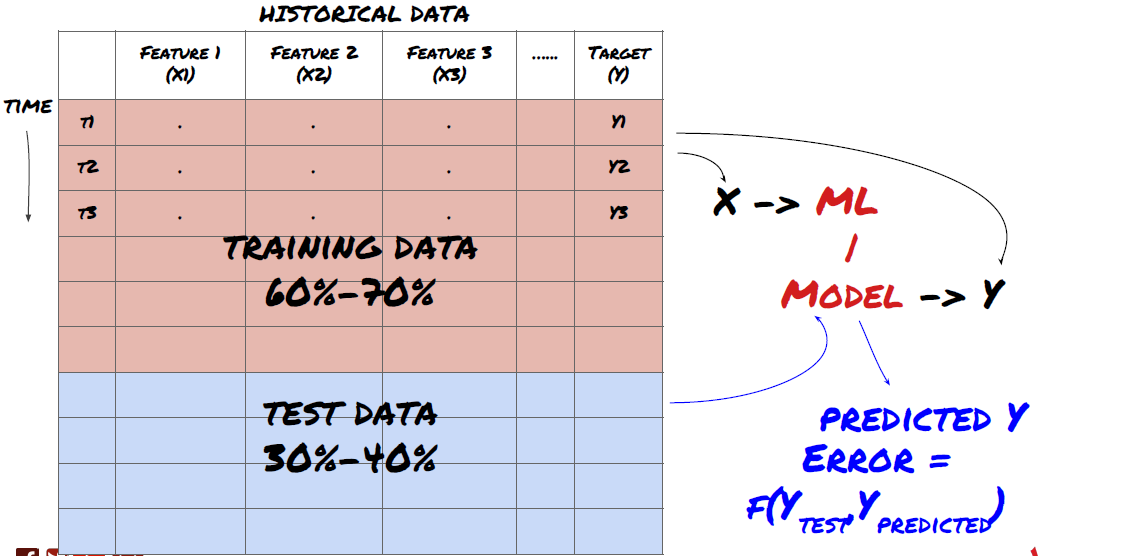
डेटा को प्रशिक्षण सेट और परीक्षण सेट में विभाजित करें
चूंकि प्रशिक्षण डेटा का उपयोग मॉडल मापदंडों का मूल्यांकन करने के लिए किया जाता है, इसलिए आपका मॉडल इन प्रशिक्षण डेटा में अधिक फिट हो सकता है, और प्रशिक्षण डेटा मॉडल के प्रदर्शन को भ्रामक बना सकता है। यदि आप कोई व्यक्तिगत परीक्षण डेटा नहीं रखते हैं और प्रशिक्षण के लिए सभी डेटा का उपयोग करते हैं, तो आपको नहीं पता होगा कि आपका मॉडल नए अदृश्य डेटा पर कितना अच्छा या बुरा प्रदर्शन करता है। यह वास्तविक समय डेटा में प्रशिक्षित एमएल मॉडल की विफलता के मुख्य कारणों में से एक हैः लोग सभी उपलब्ध डेटा को प्रशिक्षित करते हैं और प्रशिक्षण डेटा संकेतकों से उत्साहित होते हैं, लेकिन मॉडल अप्रशिक्षित वास्तविक समय डेटा पर कोई सार्थक भविष्यवाणी नहीं कर सकता है।
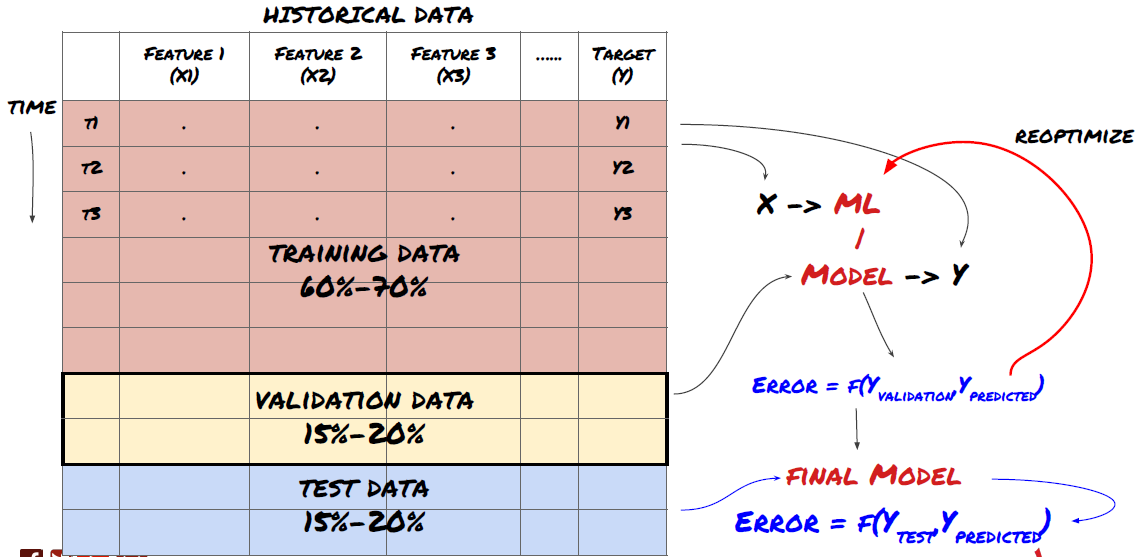
डेटा को प्रशिक्षण सेट, सत्यापन सेट और परीक्षण सेट में विभाजित करें
इस पद्धति के साथ समस्याएं हैं। यदि हम प्रशिक्षण डेटा को बार-बार प्रशिक्षित करते हैं, परीक्षण डेटा के प्रदर्शन का मूल्यांकन करते हैं और हमारे मॉडल को अनुकूलित करते हैं जब तक कि हम प्रदर्शन से संतुष्ट नहीं होते हैं, तो हम परीक्षण डेटा को प्रशिक्षण डेटा के हिस्से के रूप में निहित रूप से लेते हैं। अंत में, हमारा मॉडल प्रशिक्षण और परीक्षण डेटा के इस सेट पर अच्छा प्रदर्शन कर सकता है, लेकिन यह गारंटी नहीं दे सकता है कि यह नए डेटा की अच्छी तरह से भविष्यवाणी कर सकता है।
इस समस्या को हल करने के लिए, हम एक अलग सत्यापन डेटासेट बना सकते हैं. अब, आप डेटा को प्रशिक्षित कर सकते हैं, सत्यापन डेटा के प्रदर्शन का मूल्यांकन कर सकते हैं, जब तक आप प्रदर्शन से संतुष्ट नहीं हो जाते, तब तक अनुकूलित कर सकते हैं, और अंत में परीक्षण डेटा का परीक्षण कर सकते हैं. इस तरह, परीक्षण डेटा प्रदूषित नहीं होगा, और हम अपने मॉडल को बेहतर बनाने के लिए परीक्षण डेटा में किसी भी जानकारी का उपयोग नहीं करेंगे.
याद रखें, एक बार जब आप अपने परीक्षण डेटा के प्रदर्शन की जांच कर लेते हैं, तो वापस न जाएं और अपने मॉडल को और अनुकूलित करने का प्रयास न करें। यदि आप पाते हैं कि आपका मॉडल अच्छे परिणाम नहीं देता है, तो मॉडल को पूरी तरह से त्याग दें और फिर से शुरू करें। यह सुझाव दिया जाता है कि 60% प्रशिक्षण डेटा, 20% सत्यापन डेटा और 20% परीक्षण डेटा को विभाजित किया जा सकता है।
हमारे प्रश्न के लिए, हमारे पास तीन उपलब्ध डेटा सेट हैं। हम एक को प्रशिक्षण सेट के रूप में उपयोग करेंगे, दूसरा सत्यापन सेट के रूप में, और तीसरा हमारे परीक्षण सेट के रूप में।
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
इनमें से प्रत्येक के लिए, हम लक्ष्य चर Y जोड़ते हैं, जिसे अगले पांच आधार मानों के औसत के रूप में परिभाषित किया गया है।
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
चरण 4: फीचर इंजीनियरिंग
डेटा व्यवहार का विश्लेषण करें और पूर्वानुमानात्मक विशेषताएं बनाएं
अब वास्तविक परियोजना निर्माण शुरू हो गया है। सुविधा चयन का स्वर्ण नियम यह है कि भविष्यवाणी क्षमता मुख्य रूप से सुविधाओं से आती है, न कि मॉडल से। आप पाएंगे कि सुविधाओं के चयन का मॉडल चयन की तुलना में प्रदर्शन पर बहुत अधिक प्रभाव पड़ता है। सुविधा चयन के लिए कुछ विचारः
-
लक्ष्य चर के साथ संबंध का पता लगाने के बिना यादृच्छिक रूप से विशेषताओं के एक बड़े सेट का चयन न करें।
-
लक्ष्य चर के साथ बहुत कम या कोई संबंध नहीं होने से ओवरफिटिंग हो सकती है।
-
आपके द्वारा चयनित विशेषताएं एक दूसरे से बहुत संबंधित हो सकती हैं, इस मामले में एक छोटी संख्या में विशेषताएं लक्ष्य को भी समझा सकती हैं।
-
मैं आमतौर पर कुछ सहज सुविधाएँ बनाता हूँ, लक्ष्य चर और इन सुविधाओं के बीच संबंध की जाँच करता हूँ, और उन दोनों के बीच संबंध यह तय करने के लिए कि कौन सा उपयोग करना है।
-
आप अधिकतम सूचना गुणांक (एमआईसी) के अनुसार उम्मीदवार विशेषताओं को क्रमबद्ध करने के लिए मुख्य घटक विश्लेषण (पीसीए) और अन्य तरीकों का भी प्रयास कर सकते हैं।
विशेषता परिवर्तन/सामान्यीकरण:
एमएल मॉडल सामान्यीकरण के संदर्भ में अच्छा प्रदर्शन करते हैं। हालांकि, समय श्रृंखला डेटा से निपटने पर सामान्यीकरण मुश्किल है, क्योंकि भविष्य के डेटा रेंज अज्ञात हैं। आपके डेटा सामान्यीकरण रेंज से बाहर हो सकते हैं, जिससे मॉडल त्रुटियां हो सकती हैं। लेकिन आप अभी भी कुछ स्तर की स्थिरता को मजबूर करने का प्रयास कर सकते हैंः
-
स्केलिंगः मानक विचलन या क्वार्टिल रेंज द्वारा विशेषताओं को विभाजित करना।
-
केन्द्रित करनाः वर्तमान मूल्य से ऐतिहासिक औसत मूल्य घटाएं।
-
सामान्यीकरणः उपरोक्त (x - औसत) /stdev की दो प्रतिगामी अवधि।
-
नियमित सामान्यीकरणः डेटा को -1 से +1 की सीमा में मानकीकृत करें और बैकट्रैकिंग अवधि (x-min) / ((max min) के भीतर केंद्र को पुनः निर्धारित करें।
ध्यान दें कि चूंकि हम ऐतिहासिक निरंतर औसत मूल्य, मानक विचलन, अधिकतम या न्यूनतम मानों का उपयोग बैकट्रैक अवधि से परे करते हैं, इसलिए सुविधा का सामान्यीकृत मानकीकरण मूल्य विभिन्न समय पर विभिन्न वास्तविक मूल्यों का प्रतिनिधित्व करेगा। उदाहरण के लिए, यदि सुविधा का वर्तमान मूल्य 5 है और लगातार 30 अवधि के लिए औसत मूल्य 4.5 है, तो इसे केंद्र के बाद 0.5 में परिवर्तित कर दिया जाएगा। उसके बाद, यदि लगातार 30 अवधि का औसत मूल्य 3 हो जाता है, तो मूल्य 3.5 0.5 हो जाएगा। यह गलत मॉडल का कारण हो सकता है। इसलिए, सामान्यीकरण मुश्किल है, और आपको यह पता लगाना होगा कि मॉडल के प्रदर्शन में सुधार क्या होता है (यदि वास्तव में कोई है) ।
हमारी समस्या में पहले पुनरावृत्ति के लिए, हमने मिश्रित मापदंडों का उपयोग करके बड़ी संख्या में विशेषताएं बनाई हैं। बाद में हम यह देखने की कोशिश करेंगे कि क्या हम विशेषताओं की संख्या को कम कर सकते हैं।
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
चरण 5: मॉडल का चयन
चयनित प्रश्नों के अनुसार उपयुक्त सांख्यिकीय/एमएल मॉडल का चयन करें
मॉडल की पसंद इस बात पर निर्भर करती है कि समस्या कैसे बनती है। क्या आप पर्यवेक्षित हल करते हैं (विशेषताओं के मैट्रिक्स में प्रत्येक बिंदु X को लक्ष्य चर Y में मैप किया जाता है) या अनसुनिरीटेड लर्निंग (एक दिए गए मैपिंग के बिना, मॉडल एक अज्ञात पैटर्न सीखने की कोशिश करता है)? क्या आप प्रतिगमन (भविष्य में वास्तविक मूल्य का पूर्वानुमान) या वर्गीकरण (भविष्य में केवल मूल्य दिशा का पूर्वानुमान) से निपट रहे हैं?

पर्यवेक्षित या गैर पर्यवेक्षित शिक्षा

प्रतिगमन या वर्गीकरण
कुछ सामान्य पर्यवेक्षित सीखने के एल्गोरिदम आपको आरंभ करने में मदद कर सकते हैंः
-
रैखिक प्रतिगमन (पैरामीटर, प्रतिगमन)
-
लॉजिस्टिक प्रतिगमन (पैरामीटर, वर्गीकरण)
-
के-निकटतम पड़ोसी (केएनएन) एल्गोरिथ्म (केस आधारित, प्रतिगमन)
-
एसवीएम, एसवीआर (पैरामीटर, वर्गीकरण और प्रतिगमन)
-
निर्णय वृक्ष
-
निर्णय वन
मेरा सुझाव है कि एक सरल मॉडल से शुरू करें, जैसे कि रैखिक या लॉजिस्टिक प्रतिगमन, और जरूरत के अनुसार वहां से अधिक जटिल मॉडल का निर्माण करें। यह भी अनुशंसा की जाती है कि आप मॉडल के पीछे के गणित को पढ़ें, बजाय इसके कि इसे अंधाधुंध रूप से ब्लैक बॉक्स के रूप में उपयोग करें।
चरण 6: प्रशिक्षण, सत्यापन और अनुकूलन (चरण 4-6 दोहराएं)
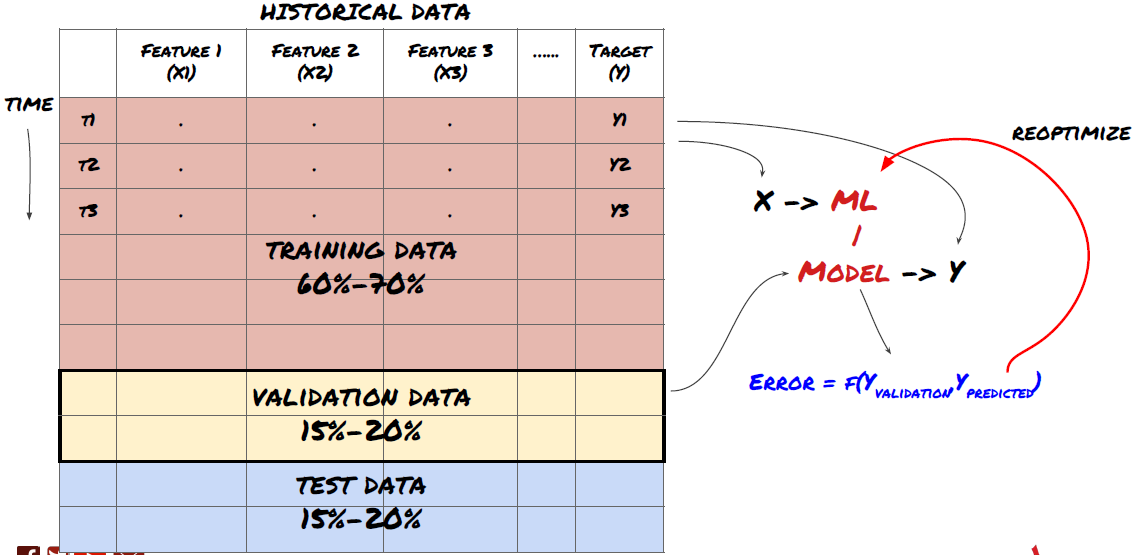
अपने मॉडल को प्रशिक्षित और अनुकूलित करने के लिए प्रशिक्षण और सत्यापन डेटा सेट का उपयोग करें
अब आप अंततः मॉडल बनाने के लिए तैयार हैं। इस चरण में, आप वास्तव में मॉडल और मॉडल मापदंडों को पुनरावृत्ति करते हैं। प्रशिक्षण डेटा पर अपने मॉडल को प्रशिक्षित करें, सत्यापन डेटा पर इसके प्रदर्शन को मापें, और फिर इसे वापस करें, अनुकूलित करें, पुनः प्रशिक्षित करें और मूल्यांकन करें। यदि आप मॉडल के प्रदर्शन से संतुष्ट नहीं हैं, तो कृपया एक और मॉडल का प्रयास करें। आप इस चरण के माध्यम से कई बार चक्र करते हैं जब तक कि आपके पास अंततः एक मॉडल न हो जिसके साथ आप संतुष्ट हैं।
केवल जब आपके पास अपना पसंदीदा मॉडल हो, तो अगले चरण पर आगे बढ़ें।
हमारे प्रदर्शन समस्या के लिए, चलो एक सरल रैखिक प्रतिगमन के साथ शुरू करते हैंः
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
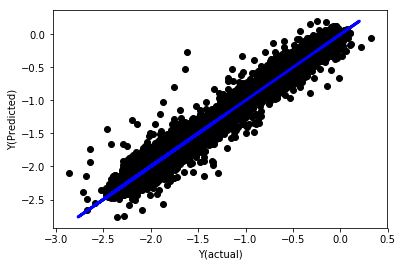
सामान्यीकरण के बिना रैखिक प्रतिगमन
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
मॉडल गुणांक को देखो. हम वास्तव में उनकी तुलना नहीं कर सकते हैं या यह नहीं कह सकते कि कौन सा महत्वपूर्ण है, क्योंकि वे सभी अलग-अलग पैमाने से संबंधित हैं. चलो उन्हें समान अनुपात के अनुरूप बनाने के लिए सामान्यीकरण का प्रयास करें और कुछ चिकनी भी लागू करें.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
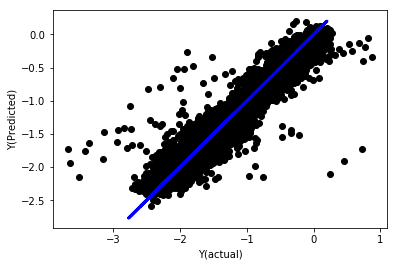
सामान्यीकरण के साथ रैखिक प्रतिगमन
Mean squared error: 0.05
Variance score: 0.90
यह मॉडल पिछले मॉडल में सुधार नहीं करता है, लेकिन यह बदतर नहीं है. अब हम गुणांक की तुलना कर सकते हैं यह देखने के लिए कि वास्तव में कौन से महत्वपूर्ण हैं।
आइए गुणांक पर एक नज़र डालें:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
परिणाम इस प्रकार हैं:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
हम स्पष्ट रूप से देख सकते हैं कि कुछ विशेषताओं में दूसरों की तुलना में उच्च गुणांक होते हैं, और उनके पास अधिक भविष्यवाणी करने की क्षमता हो सकती है।
आइए विभिन्न विशेषताओं के बीच संबंध देखें।
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
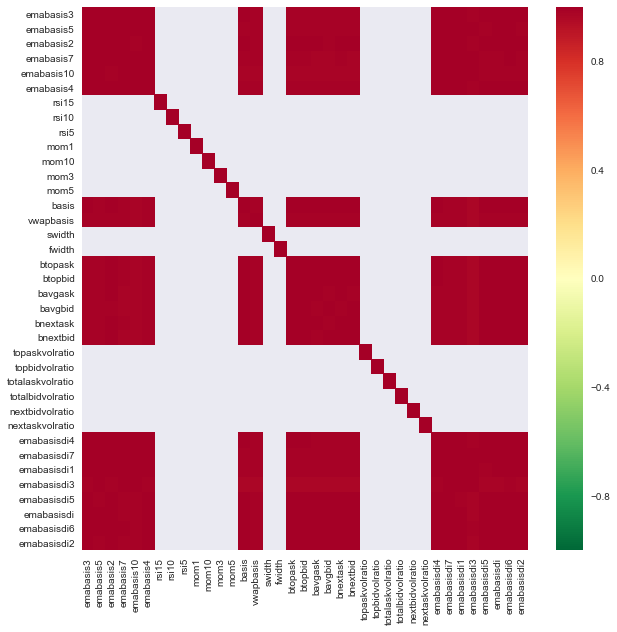
विशेषताओं के बीच संबंध
गहरे लाल क्षेत्र अत्यधिक सहसंबंधित चर का प्रतिनिधित्व करते हैं. चलो कुछ सुविधाओं को फिर से बनाने / संशोधित करें और हमारे मॉडल को बेहतर बनाने का प्रयास करें।
उदाहरण के लिए, मैं आसानी से emabasisdi7 जैसी सुविधाओं को त्याग सकता हूं, जो अन्य सुविधाओं के केवल रैखिक संयोजन हैं।
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
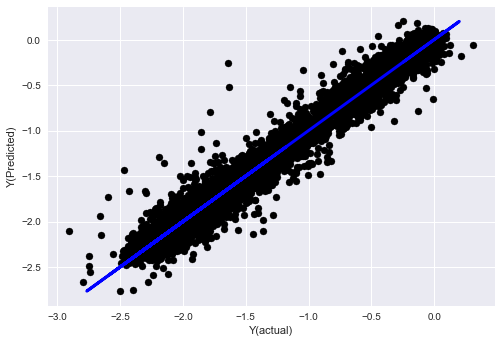
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
देखो, हमारे मॉडल का प्रदर्शन नहीं बदला है. हम केवल हमारे लक्ष्य चर को समझाने के लिए कुछ विशेषताओं की जरूरत है. मैं आप ऊपर सुविधाओं में से अधिक की कोशिश करने का सुझाव, नए संयोजन, आदि की कोशिश, हमारे मॉडल में सुधार कर सकते हैं क्या देखने के लिए.
हम अधिक जटिल मॉडल भी आज़मा सकते हैं यह देखने के लिए कि क्या मॉडल में परिवर्तन प्रदर्शन में सुधार कर सकते हैं।
- के-निकटतम पड़ोसी (केएनएन) एल्गोरिथ्म
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
- एसवीआर
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- निर्णय वृक्ष
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
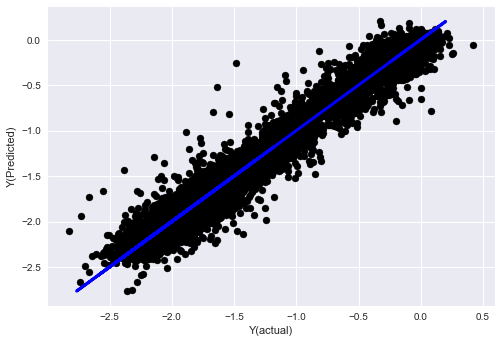
चरण 7: परीक्षण डेटा का बैकटेस्ट करें
वास्तविक नमूना डेटा के प्रदर्शन की जाँच करें
(अछूता) परीक्षण डेटा सेट पर बैकटेस्टिंग प्रदर्शन
यह एक महत्वपूर्ण क्षण है. हम परीक्षण डेटा के अंतिम चरण से हमारे अंतिम अनुकूलन मॉडल चलाते हैं, हम इसे शुरुआत में एक तरफ रख देते हैं और हमने अभी तक डेटा को नहीं छुआ है।
यह आपको वास्तविक समय में ट्रेडिंग शुरू करने पर आपके मॉडल के नए और अनदेखे डेटा पर निष्पादित होने की यथार्थवादी उम्मीद देता है। इसलिए, यह सुनिश्चित करना आवश्यक है कि आपके पास एक स्वच्छ डेटा सेट है जिसका उपयोग मॉडल को प्रशिक्षित या सत्यापित करने के लिए नहीं किया जाता है।
यदि आप परीक्षण डेटा के बैकटेस्ट परिणामों को पसंद नहीं करते हैं, तो कृपया मॉडल को त्याग दें और फिर से शुरू करें। कभी भी वापस न जाएं या अपने मॉडल को फिर से अनुकूलित न करें, जिससे ओवर-फिटिंग होगा! (एक नया परीक्षण डेटा सेट बनाने की भी अनुशंसा की जाती है, क्योंकि यह डेटा सेट अब प्रदूषित है; मॉडल को त्यागते समय, हम पहले से ही डेटा सेट की सामग्री को निहित रूप से जानते हैं) ।
यहाँ हम अभी भी Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
बैकटेस्टिंग के परिणाम, पीएनएल की गणना अमरीकी डालर में की जाती है (पीएनएल लेनदेन लागत और अन्य शुल्क में शामिल नहीं है)
चरण 8: मॉडल में सुधार के लिए अन्य तरीके
रोलिंग सत्यापन, सेट सीखने, बैगिंग और बूस्टिंग
अधिक डेटा एकत्र करने, बेहतर सुविधाएँ बनाने या अधिक मॉडल का परीक्षण करने के अलावा, कुछ और बिंदु हैं जिन्हें आप सुधारने का प्रयास कर सकते हैं।
1. रोलिंग सत्यापन
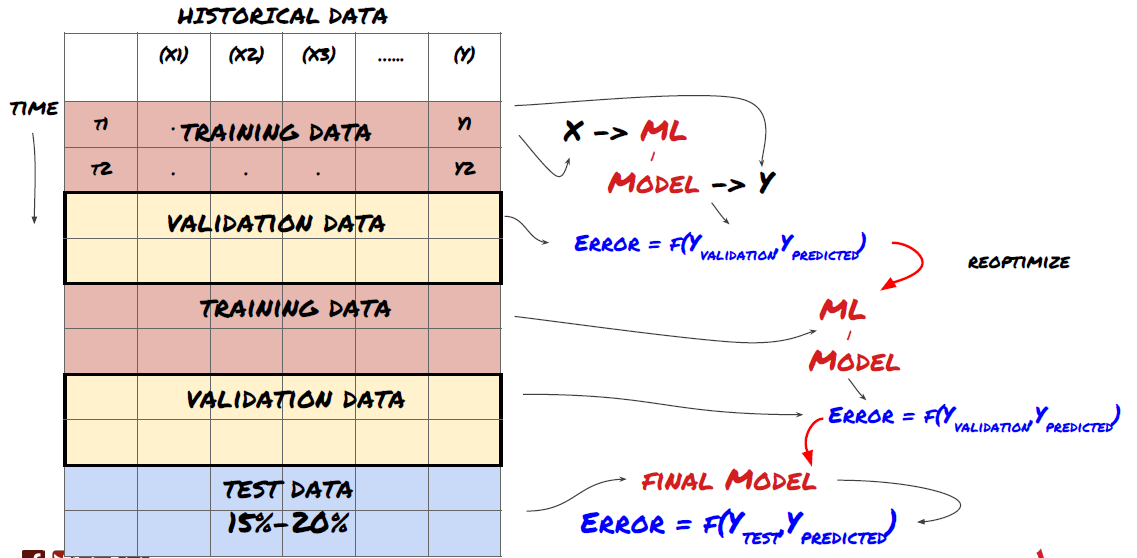
रोलिंग सत्यापन
बाजार की स्थिति शायद ही कभी समान रहती है. मान लीजिए आपके पास एक वर्ष का डेटा है, और आप जनवरी से अगस्त तक के डेटा का उपयोग प्रशिक्षण के लिए करते हैं, और सितंबर से दिसंबर तक के डेटा का उपयोग अपने मॉडल का परीक्षण करने के लिए करते हैं. आप अंततः बाजार की स्थितियों के एक बहुत ही विशिष्ट सेट के लिए प्रशिक्षित हो सकते हैं। शायद वर्ष की पहली छमाही में बाजार में कोई उतार-चढ़ाव नहीं था, और कुछ चरम समाचारों के कारण सितंबर में बाजार में तेज वृद्धि हुई। आपका मॉडल इस मॉडल को सीखने में सक्षम नहीं होगा, और यह आपको कचरा भविष्यवाणी परिणाम लाएगा।
जनवरी से फरवरी तक प्रशिक्षण, मार्च में सत्यापन, अप्रैल से मई तक पुनः प्रशिक्षण, जून में सत्यापन आदि के रूप में अग्रिम रोलिंग सत्यापन का प्रयास करना बेहतर हो सकता है।
2. सेट सीखना
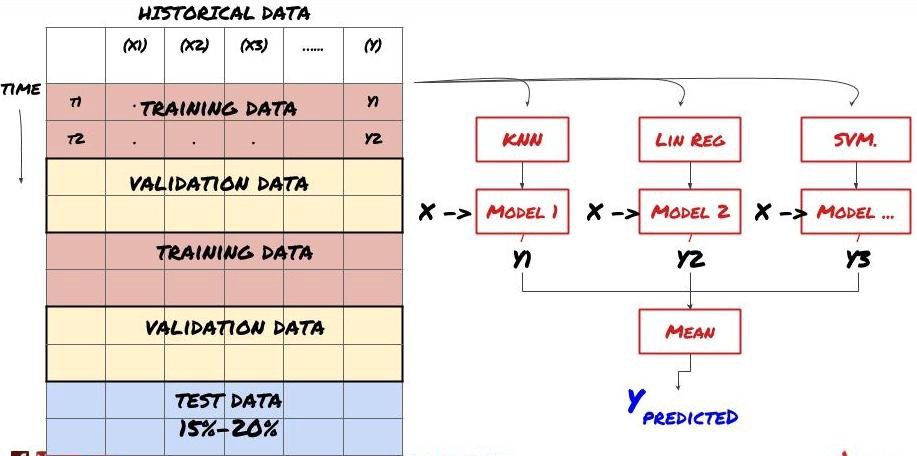
सेट सीखना
कुछ मॉडल कुछ परिदृश्यों की भविष्यवाणी करने में बहुत प्रभावी हो सकते हैं, जबकि मॉडल अन्य परिदृश्यों की भविष्यवाणी करने में या कुछ परिस्थितियों में बेहद ओवरफिट हो सकते हैं। त्रुटियों और ओवरफिट को कम करने का एक तरीका विभिन्न मॉडल के एक सेट का उपयोग करना है। आपकी भविष्यवाणी कई मॉडल द्वारा की गई भविष्यवाणियों का औसत होगी, और विभिन्न मॉडल की त्रुटियों को ऑफसेट या कम किया जा सकता है। कुछ सामान्य सेट विधियां बैगिंग और बूस्टिंग हैं।
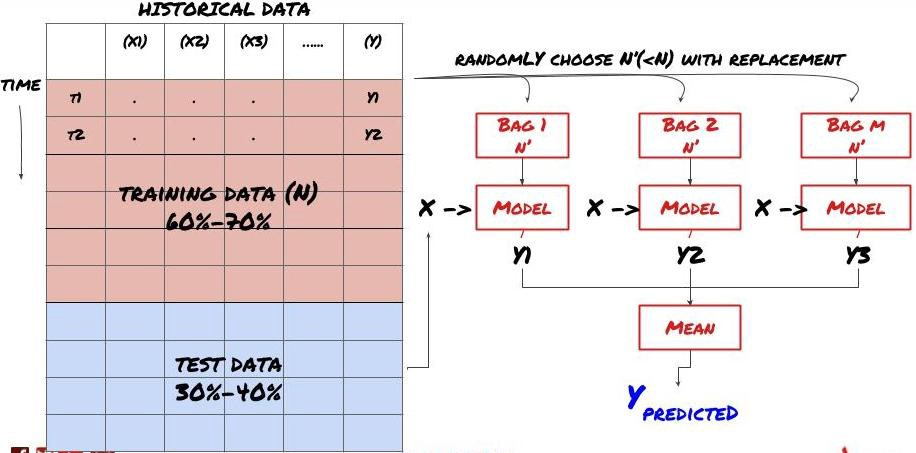
बैगिंग
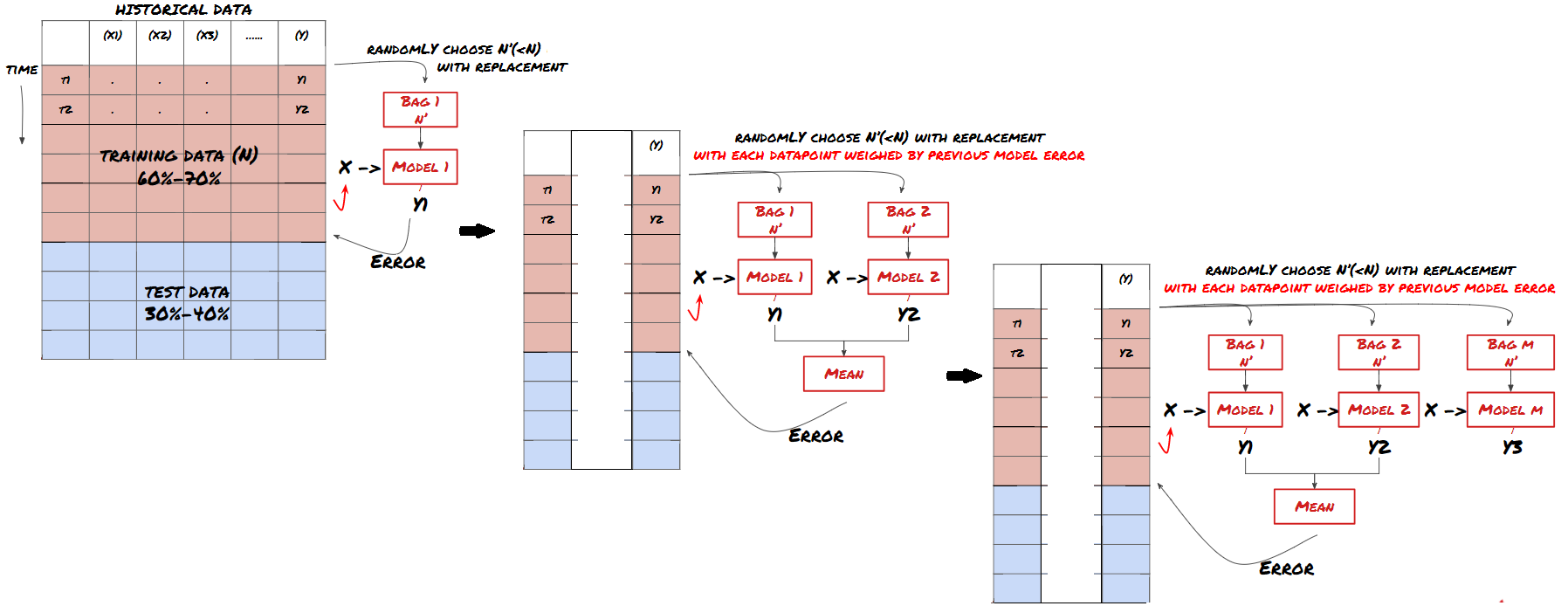
उत्तेजना
संक्षिप्तता के लिए, मैं इन तरीकों को छोड़ दूंगा, लेकिन आप अधिक जानकारी ऑनलाइन पा सकते हैं।
चलो हमारी समस्या के लिए एक सेट विधि का प्रयास करते हैंः
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
अब तक, हमने बहुत सारे ज्ञान और जानकारी एकत्र की है। आइए एक त्वरित समीक्षा करेंः
-
अपनी समस्या का समाधान करें;
-
विश्वसनीय डेटा एकत्र करना और डेटा को साफ करना;
-
डेटा को प्रशिक्षण, सत्यापन और परीक्षण सेटों में विभाजित करना;
-
विशेषताओं का निर्माण और उनके व्यवहार का विश्लेषण;
-
व्यवहार के अनुसार उपयुक्त प्रशिक्षण मॉडल का चयन करें;
-
अपने मॉडल को प्रशिक्षित करने और भविष्यवाणियां करने के लिए प्रशिक्षण डेटा का उपयोग करें;
-
सत्यापन सेट पर प्रदर्शन की जाँच करें और पुनः अनुकूलित करें;
-
परीक्षण सेट का अंतिम प्रदर्शन सत्यापित करें।
क्या यह आपके सिर में नहीं गया? लेकिन यह अभी तक खत्म नहीं हुआ है. आपके पास केवल एक विश्वसनीय भविष्यवाणी मॉडल है. याद रखें कि हम वास्तव में हमारी रणनीति में क्या चाहते थे? तो आपको इसकी आवश्यकता नहीं हैः
-
व्यापारिक दिशाओं की पहचान के लिए भविष्यवाणी मॉडल पर आधारित संकेत विकसित करना;
-
खुले और बंद पदों की पहचान के लिए विशिष्ट रणनीतियाँ विकसित करना;
-
पदों और कीमतों की पहचान करने के लिए प्रणाली को निष्पादित करें।
उपरोक्त FMZ क्वांट प्लेटफॉर्म का उपयोग करेगा (FMZ.COM) एफएमजेड क्वांट प्लेटफॉर्म पर, अत्यधिक कैप्सुलेट और सही एपीआई इंटरफेस हैं, साथ ही ऑर्डर और ट्रेडिंग फ़ंक्शन हैं जिन्हें वैश्विक रूप से बुलाया जा सकता है। आपको एक-एक करके विभिन्न एक्सचेंजों के एपीआई इंटरफेस को जोड़ने और जोड़ने की आवश्यकता नहीं है। एफएमजेड क्वांट प्लेटफॉर्म के रणनीति वर्ग में, कई परिपक्व और सही वैकल्पिक रणनीतियाँ हैं जो इस लेख में मशीन लर्निंग विधि से मेल खाती हैं, यह आपकी विशिष्ट रणनीति को अधिक शक्तिशाली बना देगी। रणनीति वर्ग पर स्थित हैःhttps://www.fmz.com/square.
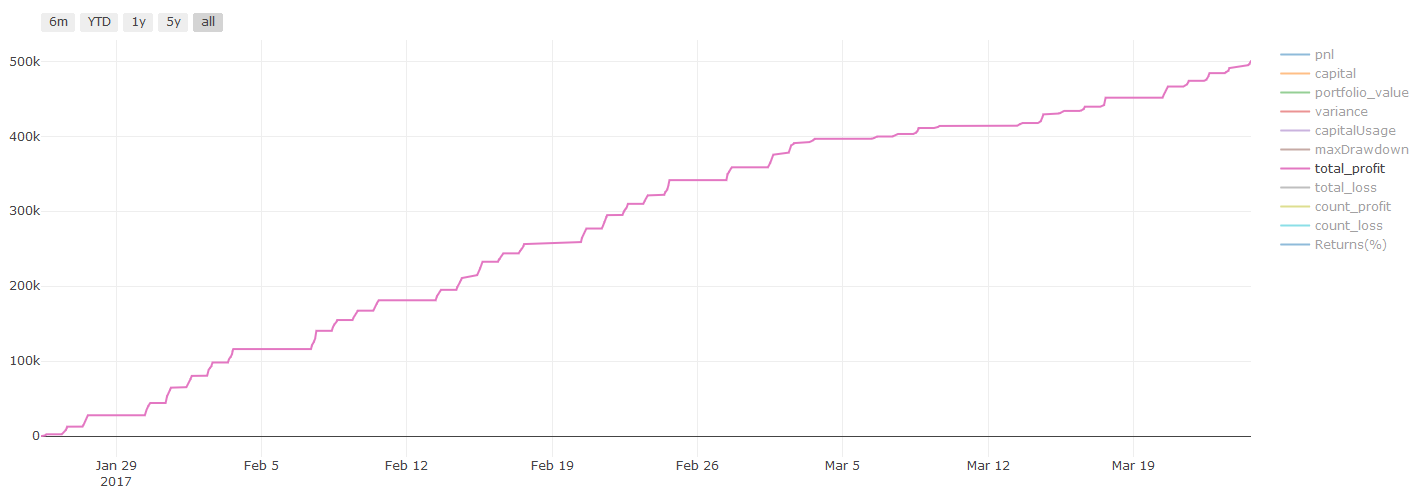
** लेन-देन की लागत पर महत्वपूर्ण नोटः ** आपका मॉडल आपको बताएगा कि चयनित परिसंपत्ति कब लंबी या छोटी हो रही है। हालांकि, इसमें शुल्क/लेन-देन की लागत/उपलब्ध ट्रेडिंग मात्रा/स्टॉप लॉस आदि पर विचार नहीं किया जाता है। लेन-देन की लागत आमतौर पर लाभदायक लेनदेन को नुकसान में बदल देती है। उदाहरण के लिए, $0.05 की अपेक्षित मूल्य वृद्धि के साथ एक परिसंपत्ति एक खरीद है, लेकिन यदि आपको इस लेनदेन के लिए $0.10 का भुगतान करना है, तो आपको अंततः $0.05 का शुद्ध नुकसान मिलेगा। ब्रोकर के कमीशन, विनिमय शुल्क और बिंदु अंतर को ध्यान में रखने के बाद, हमारा बड़ा लाभ चार्ट इस तरह दिखता हैः
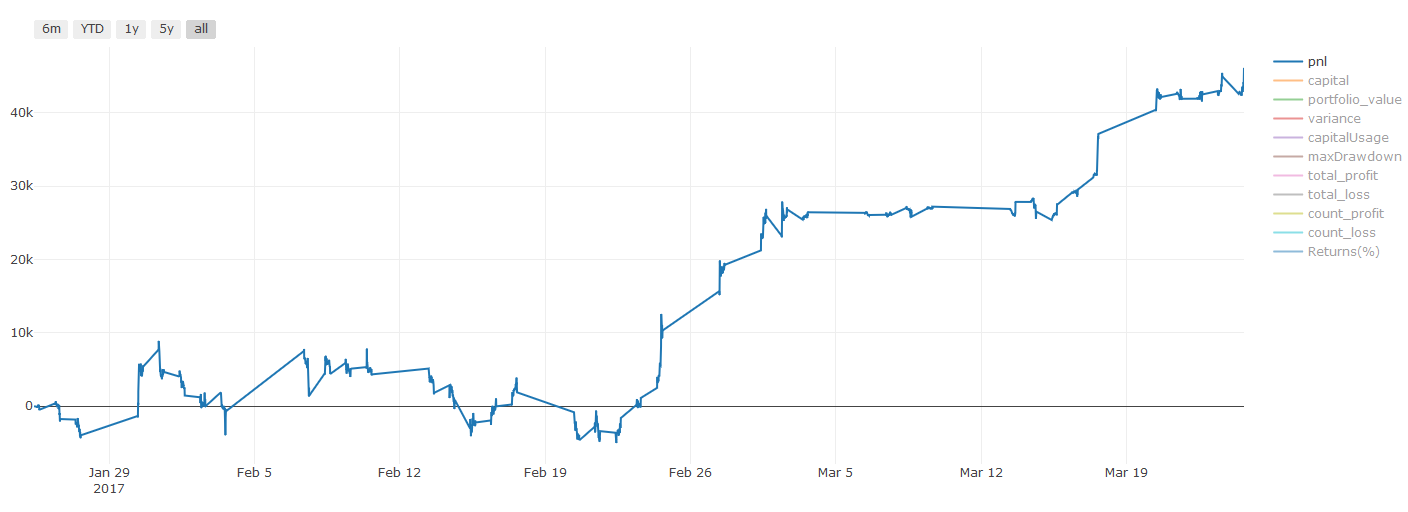
ट्रेडिंग शुल्क और बिंदु अंतर के बाद बैकटेस्ट परिणाम, पीएनएल यूएसडी है।
लेन-देन शुल्क और मूल्य अंतर हमारे पीएनएल का 90% से अधिक हिस्सा हैं! हम बाद के लेख में इन पर विस्तार से चर्चा करेंगे।
अंत में, आइए कुछ सामान्य फसलों पर एक नज़र डालें।
क्या करें और क्या न करें
-
अपनी पूरी ताकत से ज्यादा फिट होने से बचें!
-
प्रत्येक डेटा बिंदु के बाद पुनः प्रशिक्षित न करेंः यह एक आम गलती है जो लोग मशीन लर्निंग विकास में करते हैं। यदि आपके मॉडल को प्रत्येक डेटा बिंदु के बाद पुनः प्रशिक्षित करने की आवश्यकता है, तो यह बहुत अच्छा मॉडल नहीं हो सकता है। यानी, इसे नियमित रूप से पुनः प्रशिक्षित करने की आवश्यकता है, और केवल उचित आवृत्ति पर प्रशिक्षित करने की आवश्यकता है (उदाहरण के लिए, यदि इंट्रा-डे भविष्यवाणी की जाती है, तो इसे प्रत्येक सप्ताह के अंत में पुनः प्रशिक्षित करने की आवश्यकता होती है) ।
-
पूर्वाग्रह से बचें, विशेष रूप से आगे देखने वाले पूर्वाग्रहः यह एक और कारण है कि मॉडल काम नहीं करता है, और सुनिश्चित करें कि आप किसी भी भविष्य की जानकारी का उपयोग नहीं करते हैं। ज्यादातर मामलों में, इसका मतलब है कि लक्ष्य चर Y का उपयोग मॉडल में एक विशेषता के रूप में नहीं किया जाता है। आप इसका उपयोग बैकटेस्टिंग के दौरान कर सकते हैं, लेकिन यह उपलब्ध नहीं होगा जब आप वास्तव में मॉडल चलाते हैं, जिससे आपका मॉडल अनुपयोगी हो जाएगा।
-
डेटा खनन पूर्वाग्रह से सावधान रहें: जैसा कि हम यह निर्धारित करने के लिए अपने डेटा पर मॉडलिंग की एक श्रृंखला करने की कोशिश कर रहे हैं कि क्या यह उपयुक्त है, यदि कोई विशेष कारण नहीं है, तो कृपया सुनिश्चित करें कि आप रैंडम मोड को वास्तविक मोड से अलग करने के लिए सख्त परीक्षण चलाते हैं जो हो सकता है। उदाहरण के लिए, रैखिक प्रतिगमन ऊपर की ओर प्रवृत्ति पैटर्न को अच्छी तरह से समझाता है, लेकिन यह बड़े यादृच्छिक भटकने का एक अंश बनने की संभावना है!
अति-फिटिंग से बचें
यह बहुत महत्वपूर्ण है। मुझे लगता है कि इसे फिर से उल्लेख करना आवश्यक है।
-
व्यापारिक रणनीतियों में अतिसंयोजन सबसे खतरनाक जाल है।
-
एक जटिल एल्गोरिथ्म बैकटेस्ट में बहुत अच्छा प्रदर्शन कर सकता है, लेकिन यह नए अदृश्य डेटा पर बुरी तरह से विफल हो जाता है। यह एल्गोरिथ्म वास्तव में डेटा का कोई रुझान प्रकट नहीं करता है, न ही इसकी वास्तविक भविष्यवाणी क्षमता है। यह देखे जाने वाले डेटा के लिए बहुत उपयुक्त है;
-
अपने सिस्टम को यथासंभव सरल रखें. यदि आप पाते हैं कि आपको डेटा की व्याख्या करने के लिए बहुत सारे जटिल कार्यों की आवश्यकता है, तो आप ओवरफिट हो सकते हैं;
-
अपने उपलब्ध डेटा को प्रशिक्षण और परीक्षण डेटा में विभाजित करें, और वास्तविक समय लेनदेन के लिए मॉडल का उपयोग करने से पहले हमेशा वास्तविक नमूना डेटा के प्रदर्शन को सत्यापित करें।
- क्रिप्टोक्यूरेंसी बाजार में मौलिक विश्लेषण की मात्राः डेटा को खुद के लिए बोलने दें!
- मौद्रिक सर्कल के मूलभूत मात्रात्मक अनुसंधान - अब हर तरह के जादूगरों पर भरोसा न करें, डेटा निष्पक्ष रूप से बोलते हैं!
- क्वांटिफाइड ट्रेडिंग के लिए आवश्यक उपकरण - आविष्कारक क्वांटिफाइड डेटा एक्सप्लोरर मॉड्यूल
- सब कुछ में महारत हासिल करना - एफएमजेड ट्रेडिंग टर्मिनल का नया संस्करण (टीआरबी आर्बिट्रेज स्रोत कोड के साथ)
- सब कुछ जानने के लिए FMZ के नए संस्करण के लिए ट्रेडिंग टर्मिनल का परिचय (अनुदानित TRB सूट स्रोत कोड)
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (II)
- 80 पंक्तियों के कोड में उच्च आवृत्ति रणनीति के साथ मस्तिष्क रहित बिक्री बॉट्स का शोषण कैसे करें
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण
- 80 लाइनों के कोड के साथ उच्च आवृत्ति रणनीतियों का उपयोग करके बेचने के लिए मस्तिष्क रहित रोबोट का शोषण कैसे करें
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (I)
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण (1)