

Tulisan ini terinspirasi oleh pengamatan saya terhadap beberapa peringatan dan jebakan umum setelah mencoba menerapkan teknik pembelajaran mesin pada masalah perdagangan selama penelitian data saya di platform Inventor Quant.
Jika Anda belum membaca artikel saya sebelumnya, kami sarankan Anda membaca panduan saya sebelumnya tentang lingkungan penelitian data otomatis yang dibangun pada Platform Kuantitatif Inventor dan pendekatan sistematis untuk mengembangkan strategi perdagangan sebelum artikel ini.
Alamatnya ada di sini: https://www.fmz.com/digest-topic/4187 dan https://www.fmz.com/digest-topic/4169.
Tentang Pembentukan Lingkungan Penelitian
Tutorial ini dirancang untuk para penggemar, teknisi, dan ilmuwan data dari semua tingkat keahlian. Baik Anda seorang pakar industri atau pemula pemrograman, satu-satunya keahlian yang Anda butuhkan adalah pemahaman dasar tentang bahasa pemrograman Python dan pengetahuan yang memadai tentang operasi baris perintah. (Kemampuan untuk menyiapkan proyek ilmu data sudah cukup)
- Menginstal Inventor Quant Hoster dan Menyiapkan Anaconda
Selain menyediakan sumber data berkualitas tinggi dari bursa utama, Inventor Quantitative Platform FMZ.COM juga menyediakan serangkaian antarmuka API yang lengkap untuk membantu kami melakukan transaksi otomatis setelah menyelesaikan analisis data. Seperangkat antarmuka ini mencakup alat-alat praktis seperti menanyakan informasi akun, menanyakan harga tinggi, harga pembukaan, harga terendah, harga penutupan, volume perdagangan, berbagai indikator analisis teknis yang umum digunakan oleh berbagai bursa utama, dll., terutama untuk menghubungkan ke bursa utama utama secara aktual. proses perdagangan. Antarmuka API publik menyediakan dukungan teknis yang kuat.
Semua fitur yang disebutkan di atas dirangkum dalam sistem yang mirip dengan Docker. Yang harus kita lakukan adalah membeli atau menyewa layanan komputasi awan kita sendiri dan kemudian menerapkan sistem Docker.
Dalam nama resmi Inventor Quantitative Platform, sistem Docker ini disebut sistem host.
Untuk informasi lebih lanjut tentang cara menyebarkan host dan robot, silakan lihat artikel saya sebelumnya: https://www.fmz.com/bbs-topic/4140
Pembaca yang ingin membeli host penyebaran server komputasi awan mereka sendiri dapat merujuk ke artikel ini: https://www.fmz.com/bbs-topic/2848
Setelah berhasil menerapkan layanan komputasi awan dan sistem host, kami akan menginstal alat Python paling kuat: Anaconda
Untuk mencapai semua lingkungan program relevan yang diperlukan untuk artikel ini (perpustakaan dependen, manajemen versi, dll.), cara termudah adalah menggunakan Anaconda. Ini adalah ekosistem ilmu data Python dan manajer ketergantungan yang dikemas.
Karena kami menginstal Anaconda pada layanan cloud, kami sarankan Anda menginstal sistem Linux plus versi baris perintah Anaconda pada server cloud.
Untuk metode instalasi Anaconda, silakan lihat panduan resmi Anaconda: https://www.anaconda.com/distribution/
Jika Anda seorang programmer Python berpengalaman dan tidak merasa perlu menggunakan Anaconda, itu tidak masalah. Saya berasumsi bahwa Anda tidak memerlukan bantuan dalam menginstal dependensi yang diperlukan dan Anda dapat melewati bagian ini.
Mengembangkan strategi perdagangan
Hasil akhir dari strategi perdagangan harus menjawab pertanyaan-pertanyaan berikut:
-
Petunjuk: Tentukan apakah suatu aset murah, mahal, atau dinilai wajar.
-
Kondisi pembukaan: Jika harga aset murah atau mahal, Anda harus mengambil posisi long atau short.
-
Tutup perdagangan: Jika harga aset wajar dan kami memiliki posisi pada aset tersebut (beli atau jual sebelumnya), haruskah Anda menutup posisi tersebut?
-
Kisaran Harga: Harga (atau kisaran) di mana perdagangan dibuka
-
Kuantitas: Jumlah dana yang diperdagangkan (misalnya jumlah mata uang digital atau jumlah lot komoditas berjangka)
Pembelajaran mesin dapat digunakan untuk menjawab setiap pertanyaan ini, tetapi untuk sisa artikel ini, kami akan fokus menjawab pertanyaan pertama, yaitu arah perdagangan.
Pendekatan Strategis
Ada dua jenis pendekatan untuk membangun strategi, satu berbasis model dan lainnya berbasis penambangan data. Kedua hal ini pada dasarnya adalah pendekatan yang berlawanan.
Dalam konstruksi strategi berbasis model, kita mulai dengan model inefisiensi pasar, membangun ekspresi matematika (misalnya, harga, pengembalian) dan menguji efektivitasnya dalam jangka waktu yang lebih lama. Model tersebut biasanya merupakan versi sederhana dari model kompleks yang nyata, dan signifikansi serta stabilitasnya dalam jangka panjang perlu diverifikasi. Strategi tren mengikuti, pengembalian rata-rata dan arbitrase yang umum termasuk dalam kategori ini.
Di sisi lain, pertama-tama kami mencari pola harga dan mencoba menggunakan algoritma dalam metode penambangan data. Apa yang menyebabkan pola ini tidaklah penting, karena yang pasti pola ini akan terus berulang di masa mendatang. Ini adalah metode analisis buta dan kita perlu pemeriksaan ketat untuk mengidentifikasi pola nyata dari pola acak. "Coba-coba", "Pola diagram batang", dan "Regresi massa fitur" termasuk dalam kategori ini.
Jelasnya, pembelajaran mesin cocok sekali untuk metode penambangan data. Mari kita lihat bagaimana pembelajaran mesin dapat digunakan untuk membuat sinyal perdagangan melalui penambangan data.
Contoh kode menggunakan alat pengujian ulang dan antarmuka API perdagangan otomatis berdasarkan Inventor Quantitative Platform. Setelah memasang hoster dan menginstal Anaconda di bagian di atas, Anda hanya perlu menginstal pustaka analisis ilmu data yang kami butuhkan dan model pembelajaran mesin terkenal scikit-learn. Kami tidak akan membahas detail tentang bagian ini.
pip install -U scikit-learn
Menggunakan pembelajaran mesin untuk membuat sinyal strategi perdagangan
- Penambangan Data
Sebelum kita mulai, struktur masalah pembelajaran mesin standar ditunjukkan di bawah ini:
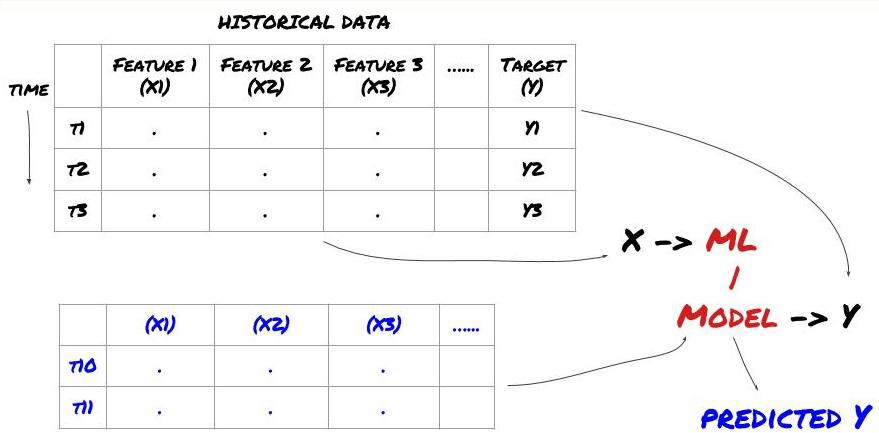
Kerangka Masalah Pembelajaran Mesin
Fitur yang akan kita buat harus memiliki beberapa kekuatan prediktif (X), kita ingin memprediksi variabel target (Y), dan menggunakan data historis untuk melatih model ML yang dapat memprediksi Y sedekat mungkin dengan nilai sebenarnya. Terakhir, kami menggunakan model ini untuk membuat prediksi pada data baru di mana Y tidak diketahui. Hal ini membawa kita ke langkah pertama:
Langkah 1: Siapkan masalah Anda
- Apa yang ingin Anda prediksi? Apa ramalan yang baik? Bagaimana Anda mengevaluasi hasil prediksi?
Artinya, dalam kerangka kerja kita di atas, apa itu Y?
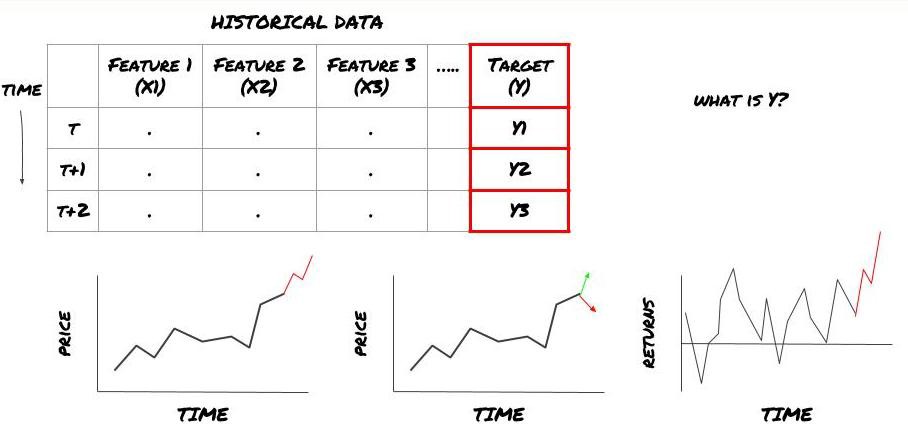
Apa yang ingin Anda prediksi?
Apakah Anda ingin memprediksi harga masa mendatang, laba/laba masa depan, sinyal beli/jual, mengoptimalkan alokasi portofolio, dan mencoba mengeksekusi perdagangan secara efisien, dsb.?
Misalkan kita mencoba memperkirakan harga pada cap waktu berikutnya. Dalam kasus ini, Y(t) = Harga(t+1). Sekarang kita bisa melengkapi kerangka kerja kita dengan data historis
Perhatikan bahwa Y(t) hanya diketahui dalam backtest, tetapi saat kita menggunakan model kita, kita tidak akan mengetahui harga pada waktu t (t+1). Kami menggunakan model kami untuk membuat prediksi Y(prediksi, t) dan membandingkannya dengan nilai aktual hanya pada waktu t+1. Ini berarti Anda tidak dapat menggunakan Y sebagai fitur dalam model prediktif.
Setelah kita mengetahui target Y kita, kita juga dapat memutuskan cara mengevaluasi prediksi kita. Hal ini penting untuk membedakan berbagai model yang akan kita coba pada data kita. Bergantung pada masalah yang kita pecahkan, pilih metrik untuk mengukur efisiensi model kita. Misalnya, jika kita hendak memperkirakan harga, kita dapat menggunakan kesalahan akar kuadrat rata-rata sebagai metrik. Beberapa indikator yang umum digunakan (rata-rata pergerakan, MACD dan skor varians, dll.) telah dikodekan sebelumnya dalam kotak peralatan Inventor Quant, dan Anda dapat memanggil indikator ini secara global melalui antarmuka API.
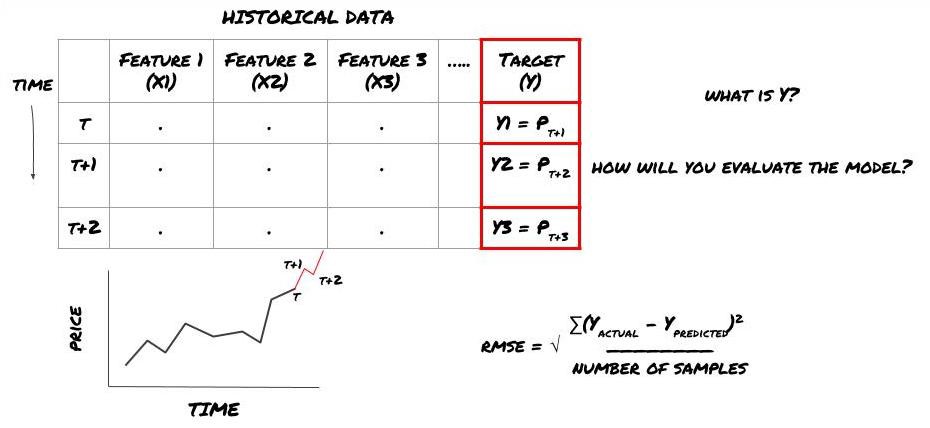
Kerangka kerja ML untuk memprediksi harga masa depan
Untuk mendemonstrasikannya, kami akan membuat model peramalan untuk memperkirakan nilai dasar yang diharapkan di masa depan dari target investasi hipotetis, di mana:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Karena ini adalah masalah regresi, kami akan mengevaluasi model pada RMSE (Root Mean Squared Error). Kami juga akan menggunakan Total Pnl sebagai kriteria evaluasi
Catatan: Untuk pengetahuan matematika yang relevan tentang RMSE, silakan merujuk ke konten yang relevan dari Ensiklopedia Baidu
- Sasaran kami: menciptakan model yang membuat nilai prediksi sedekat mungkin dengan Y.
Langkah 2: Kumpulkan data yang dapat diandalkan
Kumpulkan dan bersihkan data yang dapat membantu Anda memecahkan masalah yang dihadapi
Data apa yang perlu Anda pertimbangkan untuk memiliki daya prediksi untuk variabel target Y? Jika kita memprediksi harga, Anda dapat menggunakan data target harga, data target volume perdagangan, data serupa untuk target terkait, indikator pasar keseluruhan seperti tingkat indeks target, harga aset terkait lainnya, dll.
Anda perlu menyiapkan izin akses data untuk data ini dan memastikan data Anda akurat serta mengatasi data yang hilang (masalah yang sangat umum). Pastikan juga data Anda tidak bias dan cukup mewakili semua kondisi pasar (misalnya, jumlah skenario untung dan rugi yang sama) untuk menghindari bias dalam model Anda. Anda mungkin juga perlu membersihkan data untuk dividen, pembagian portofolio, kelanjutan, dan lain-lain.
Jika Anda menggunakan Inventor Quantitative Platform (FMZ.COM), kami dapat mengakses data global gratis dari Google, Yahoo, NSE dan Quandl; data mendalam dari komoditas berjangka domestik seperti CTP dan Yisheng; Binance, OKEX, Huobi dan BitMex Platform Kuantitatif Inventor juga membersihkan dan menyaring data ini terlebih dahulu, seperti pembagian target investasi dan data pasar yang mendalam, dan menyajikannya kepada pengembang strategi dalam format yang mudah dipahami oleh pekerja kuantitatif.
Demi kenyamanan artikel ini, kami menggunakan data berikut sebagai target investasi virtual 'MQK'. Kami juga menggunakan alat kuantitatif yang sangat praktis yang disebut Auquan's Toolbox. Untuk informasi lebih lanjut, silakan lihat: https://github.com/Auquan / kotak peralatan auquan-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Dengan kode di atas, Auquan’s Toolbox telah mengunduh dan memuat data ke dalam kamus bingkai data. Sekarang kita perlu menyiapkan data dalam format yang kita inginkan. Fungsi ds.getBookDataByFeature() mengembalikan kamus bingkai data, satu bingkai data per fitur. Kami membuat kerangka data baru untuk saham dengan semua fitur.
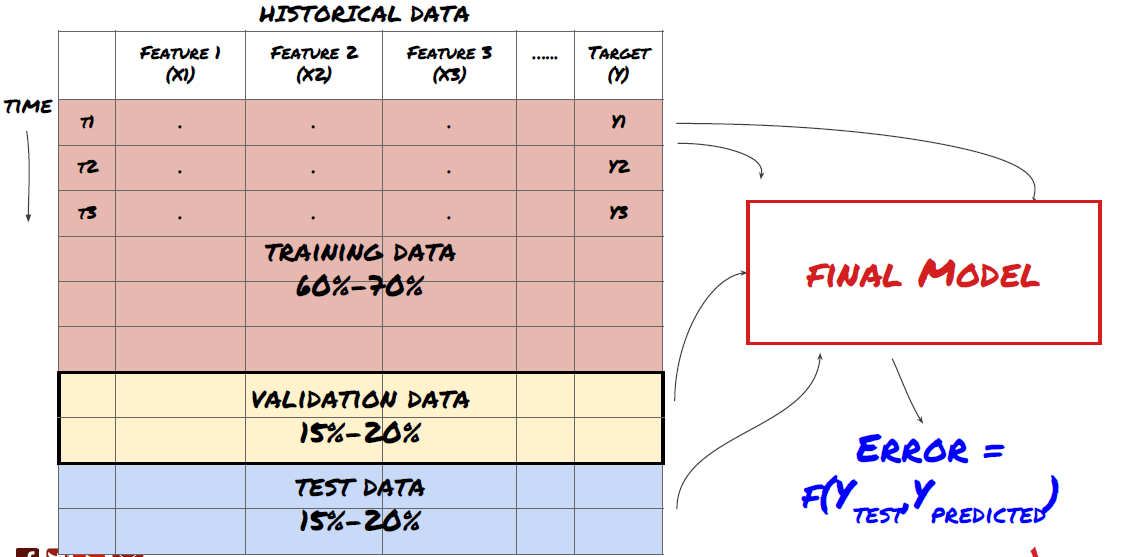
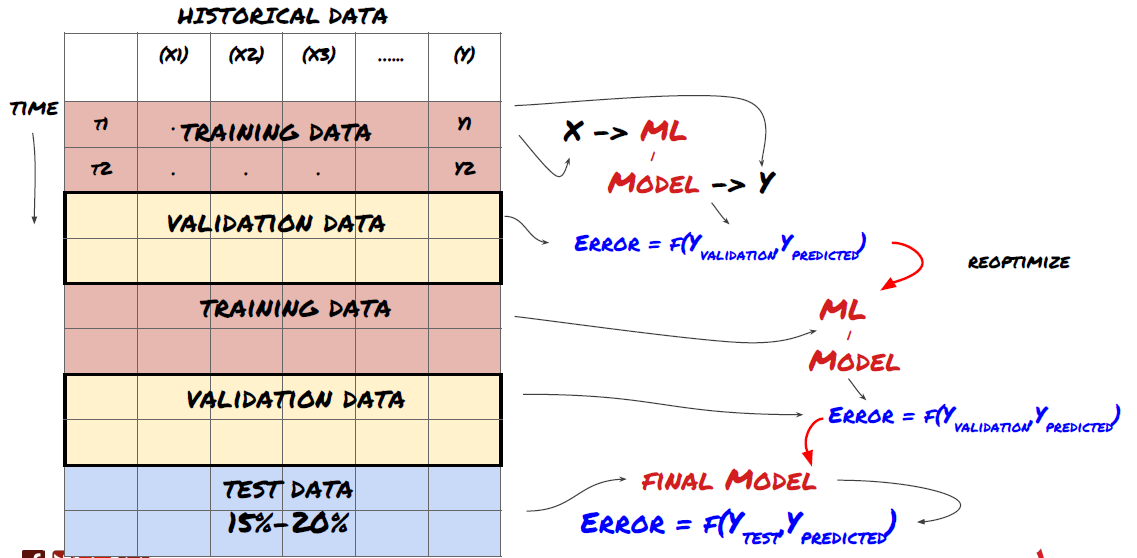
Langkah 3: Memisahkan data
- Buat set pelatihan dari data, validasi silang, dan uji set ini
Ini adalah langkah yang sangat penting! Sebelum melanjutkan, kita harus membagi data menjadi kumpulan data pelatihan, untuk melatih model Anda, dan kumpulan data uji, untuk mengevaluasi kinerja model. Pembagian yang disarankan adalah: 60-70% set pelatihan dan 30-40% set pengujian
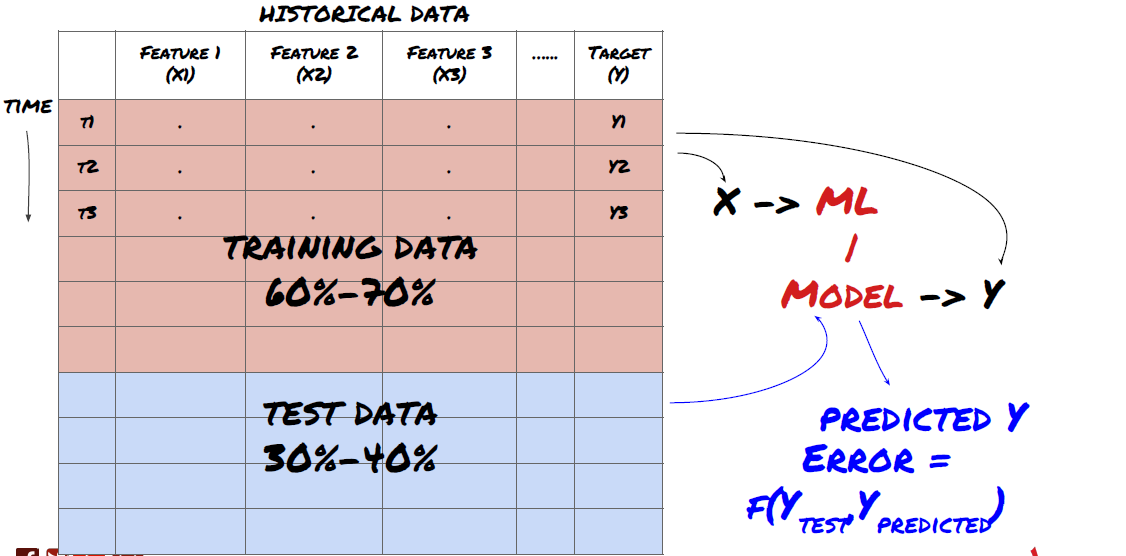
Memisahkan data menjadi set pelatihan dan pengujian
Karena data pelatihan digunakan untuk mengevaluasi parameter model, model Anda mungkin terlalu disesuaikan dengan data pelatihan ini dan data pelatihan dapat menyesatkan kinerja model. Jika Anda tidak menyimpan data pengujian terpisah dan menggunakan semua data untuk pelatihan, Anda tidak akan tahu seberapa baik atau buruk kinerja model Anda pada data baru yang belum pernah dilihat sebelumnya. Ini adalah salah satu alasan utama mengapa model ML yang terlatih gagal pada data langsung: orang berlatih pada semua data yang tersedia dan tertarik dengan metrik data pelatihan, tetapi model tersebut gagal membuat prediksi berarti pada data langsung yang bukan menjadi bahan pelatihannya. .
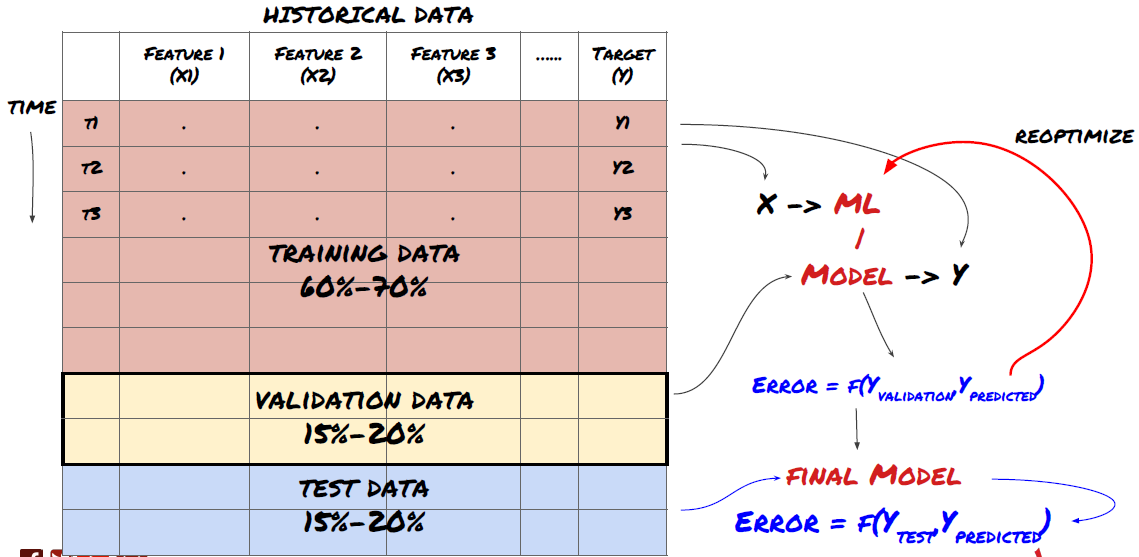
Membagi data menjadi set pelatihan, validasi, dan pengujian
Ada masalah dengan pendekatan ini. Jika kita berlatih berulang kali menggunakan data pelatihan, mengevaluasi performa pada data uji, dan mengoptimalkan model kita hingga merasa puas dengan performanya, secara implisit kita menyertakan data uji sebagai bagian dari data pelatihan. Pada akhirnya, model kita mungkin berkinerja baik pada rangkaian data pelatihan dan pengujian ini, tetapi tidak ada jaminan bahwa model tersebut akan mampu memprediksi data baru dengan baik.
Untuk mengatasi masalah ini, kita dapat membuat kumpulan data validasi terpisah. Sekarang Anda dapat berlatih pada data, mengevaluasi performa pada data validasi, mengoptimalkan hingga Anda puas dengan performanya, dan akhirnya menguji pada data uji. Dengan cara ini, data uji tidak akan terkontaminasi dan kami tidak akan menggunakan informasi apa pun dari data uji untuk meningkatkan model kami.
Ingat, setelah Anda memeriksa kinerja pada data uji, jangan kembali dan mencoba mengoptimalkan model lebih lanjut. Jika Anda menemukan bahwa model Anda tidak memberikan hasil yang baik, buang model tersebut sepenuhnya dan mulai dari awal lagi. Pembagian yang disarankan dapat berupa 60% data pelatihan, 20% data validasi, dan 20% data uji.
Untuk permasalahan kita, kita memiliki tiga set data yang tersedia dan kita akan menggunakan satu sebagai set pelatihan, yang kedua sebagai set validasi, dan yang ketiga sebagai set pengujian.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Pada masing-masing variabel tersebut, kita tambahkan variabel target Y, yang didefinisikan sebagai rata-rata dari lima nilai basis berikutnya
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Langkah 4: Rekayasa Fitur
Menganalisis perilaku data dan membuat fitur dengan kekuatan prediktif
Sekarang pembangunan proyek yang sesungguhnya dimulai. Aturan emas pemilihan fitur adalah bahwa kekuatan prediktif terutama berasal dari fitur, bukan dari model. Anda akan menemukan bahwa pilihan fitur memiliki dampak yang jauh lebih besar pada kinerja daripada pilihan model. Beberapa catatan tentang pemilihan fitur:
-
Jangan memilih sekumpulan fitur secara sembarangan tanpa menyelidiki hubungannya dengan variabel target.
-
Hubungan yang kecil atau tidak ada dengan variabel target dapat menyebabkan overfitting
-
Fitur-fitur yang Anda pilih mungkin sangat berkorelasi satu sama lain, dalam hal ini jumlah fitur yang lebih sedikit juga dapat menjelaskan target
-
Saya biasanya membuat beberapa fitur yang masuk akal secara intuitif dan melihat bagaimana variabel target dihubungkan dengan fitur-fitur tersebut, serta bagaimana fitur-fitur tersebut dihubungkan satu sama lain untuk memutuskan fitur mana yang akan digunakan.
-
Anda juga dapat mencoba memberi peringkat fitur kandidat berdasarkan Koefisien Informasi Maksimum (MIC), melakukan Analisis Komponen Utama (PCA), dan metode lainnya.
Transformasi/Normalisasi Fitur:
Model ML cenderung berkinerja baik dengan normalisasi. Namun, normalisasi sulit dilakukan jika berurusan dengan data deret waktu karena rentang data di masa mendatang tidak diketahui. Data Anda mungkin berada di luar rentang yang dinormalisasi, yang menyebabkan modelnya salah. Namun Anda masih dapat mencoba memaksakan beberapa derajat stasioneritas:
-
Skala: Membagi fitur berdasarkan deviasi standar atau rentang interkuartil
-
Pemusatan: Kurangi rata-rata historis dari nilai saat ini
-
Normalisasi: Dua periode tinjauan balik dari (x - mean) / stdev di atas
-
Normalisasi Konvensional: Menormalkan data ke rentang -1 hingga +1 dan memusatkan kembali dalam periode lookback (x-min)/(maks-min)
Perhatikan bahwa karena kami menggunakan rata-rata berjalan historis, deviasi standar, nilai maksimum atau minimum selama periode tinjauan ke belakang, nilai fitur yang dinormalisasi akan mewakili nilai aktual yang berbeda pada waktu yang berbeda. Misalnya, jika nilai fitur saat ini adalah 5 dan rata-rata 30 periode yang berjalan adalah 4,5, nilai tersebut akan diubah menjadi 0,5 setelah pemusatan. Nantinya, jika rata-rata berjalan 30 periode menjadi 3, maka nilai 3,5 akan menjadi 0,5. Ini bisa jadi alasan mengapa modelnya salah. Jadi, regularisasi itu rumit dan Anda harus mencari tahu apa yang sebenarnya meningkatkan kinerja model (jika ada).
Untuk iterasi pertama dalam masalah kita, kita membuat sejumlah besar fitur menggunakan parameter pencampuran. Nanti kita coba lihat apakah kita bisa mengurangi jumlah fiturnya
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Langkah 5: Pemilihan model
Pilih model statistik/ML yang sesuai untuk masalah yang dipilih
Pemilihan model bergantung pada bagaimana masalah dirumuskan. Apakah Anda memecahkan masalah pembelajaran terbimbing (setiap titik X dalam matriks fitur dipetakan ke variabel target Y) atau masalah pembelajaran tak terbimbing (tidak ada pemetaan yang diberikan dan model mencoba mempelajari pola yang tidak diketahui)? Apakah Anda memecahkan regresi (memprediksi harga aktual di masa mendatang) atau masalah klasifikasi (hanya memprediksi arah (kenaikan/penurunan) harga di masa mendatang).

Pembelajaran dengan pengawasan atau tanpa pengawasan

Regresi atau Klasifikasi
Beberapa algoritma pembelajaran terbimbing yang umum dapat membantu Anda memulai:
-
Regresi Linier(parameter, regresi)
-
Regresi logistik (parameter, klasifikasi)
-
Algoritma K-nearest neighbor (KNN) (berbasis instance, regresi)
-
SVM, SVR (parameter, klasifikasi dan regresi)
-
Pohon Keputusan
-
Hutan Keputusan
Saya sarankan memulai dengan model sederhana, seperti regresi linier atau logistik, dan membangun model yang lebih kompleks dari sana sesuai kebutuhan. Disarankan pula agar Anda membaca matematika di balik model tersebut daripada menggunakannya secara membabi buta sebagai kotak hitam.
Langkah 6: Pelatihan, validasi, dan pengoptimalan (ulangi langkah 4-6)
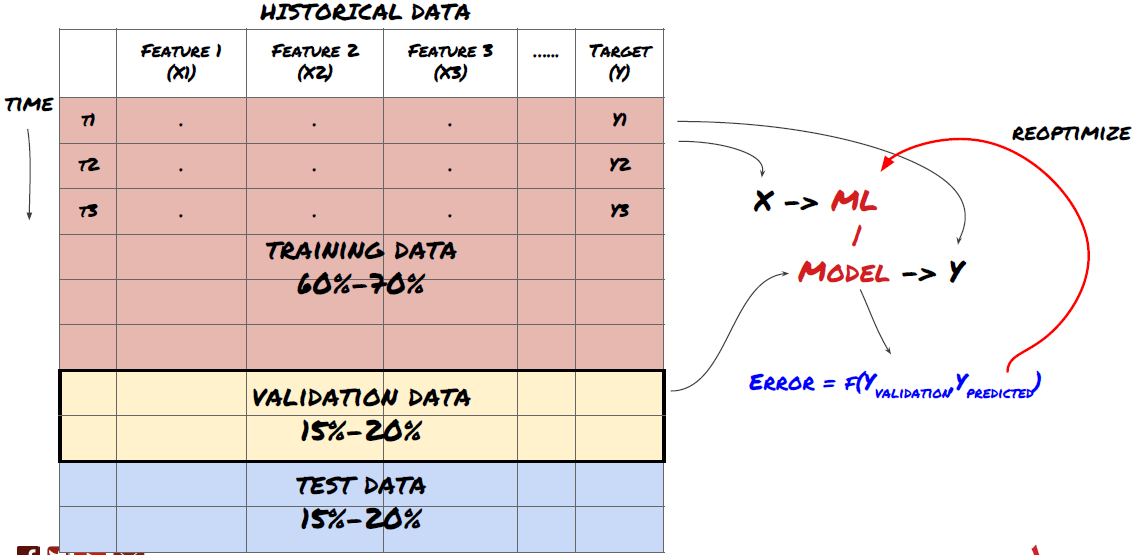
Latih dan optimalkan model Anda menggunakan kumpulan data pelatihan dan validasi
Sekarang Anda akhirnya siap untuk membangun model Anda. Pada tahap ini, Anda benar-benar hanya mengulangi model dan parameter model. Latih model Anda pada data pelatihan, ukur kinerjanya pada data validasi, lalu kembali, optimalkan, latih ulang, dan evaluasi. Jika Anda tidak puas dengan kinerja suatu model, coba gunakan model lain. Anda melewati fase ini beberapa kali hingga akhirnya memiliki model yang Anda sukai.
Hanya setelah Anda memiliki model yang Anda sukai, lanjutkan ke langkah berikutnya.
Untuk masalah demonstrasi kita, mari kita mulai dengan regresi linier sederhana
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
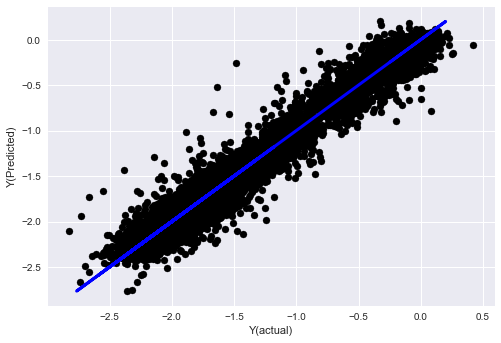
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
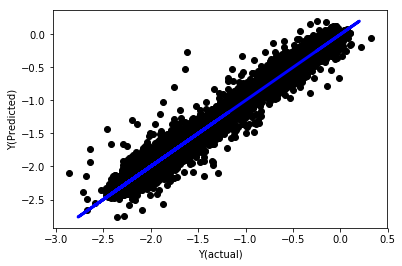
Regresi linier tanpa normalisasi
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Lihatlah koefisien modelnya. Kita tidak bisa benar-benar membandingkannya atau menentukan mana yang penting karena semuanya memiliki skala yang berbeda. Mari kita coba menormalkannya untuk membawanya ke skala yang sama dan juga menerapkan beberapa stasioneritas.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
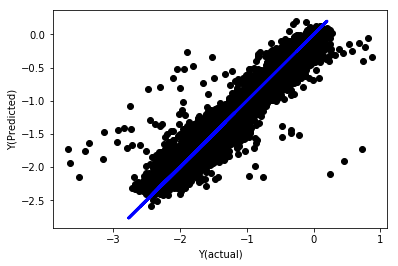
Regresi Linier yang Dinormalkan
Mean squared error: 0.05
Variance score: 0.90
Model ini tidak lebih baik dari model sebelumnya, tetapi juga tidak lebih buruk. Sekarang kita benar-benar dapat membandingkan koefisien dan melihat mana yang sebenarnya signifikan.
Mari kita lihat koefisiennya
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Hasilnya adalah:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Kita dapat melihat dengan jelas bahwa beberapa fitur memiliki koefisien yang lebih tinggi dibandingkan dengan fitur lainnya dan cenderung memiliki daya prediksi yang lebih kuat.
Mari kita lihat korelasi antara fitur-fitur yang berbeda.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
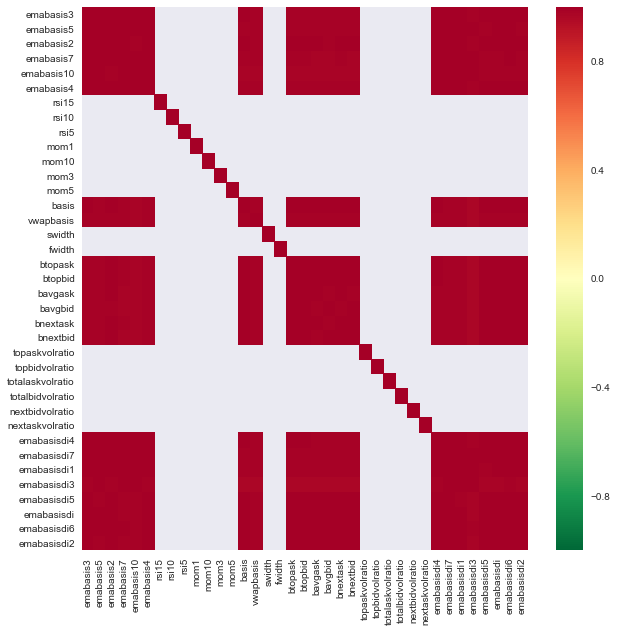
Korelasi antar fitur
Area merah tua menunjukkan variabel yang berkorelasi tinggi. Mari membuat/memodifikasi beberapa fitur lagi dan mencoba meningkatkan model kita.
Misalnya, saya dapat dengan mudah membuang fitur seperti emabasisdi7 yang hanya merupakan kombinasi linear dari fitur lainnya.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
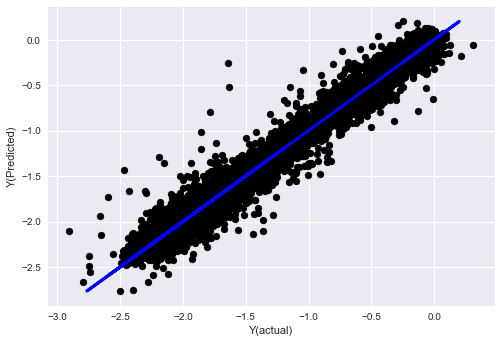
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Lihat, tidak ada perubahan dalam kinerja model kita, kita hanya butuh beberapa fitur untuk menjelaskan variabel target kita. Saya sarankan Anda mencoba lebih banyak fitur di atas, mencoba kombinasi baru, dll. untuk melihat apa yang dapat meningkatkan model kita.
Kita juga dapat mencoba model yang lebih kompleks untuk melihat apakah perubahan pada model dapat meningkatkan kinerja.
- Algoritma K-tetangga terdekat (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Pohon Keputusan
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Langkah 7: Uji ulang data pengujian
Periksa kinerja pada data sampel aktual
Performa backtest pada dataset pengujian (yang belum tersentuh)
Ini adalah momen yang kritis. Kita mulai dari langkah terakhir dengan menjalankan model akhir yang telah dioptimalkan pada data uji yang kita sisihkan di awal dan belum kita sentuh sejauh ini.
Hal ini memberi Anda ekspektasi realistis tentang kinerja model Anda pada data baru dan belum terlihat saat Anda mulai berdagang secara langsung. Oleh karena itu, penting untuk memastikan bahwa Anda memiliki kumpulan data bersih yang belum digunakan untuk melatih atau memvalidasi model.
Jika Anda tidak menyukai hasil backtest pada data pengujian Anda, buang model tersebut dan mulai lagi. Jangan pernah kembali dan mengoptimalkan ulang model Anda, ini akan menyebabkan overfitting! (Disarankan juga untuk membuat kumpulan data pengujian baru, karena kumpulan data ini sekarang terkontaminasi; saat membuang model, secara implisit kita sudah mengetahui sesuatu tentang kumpulan data tersebut).
Di sini kita masih akan menggunakan Toolbox Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
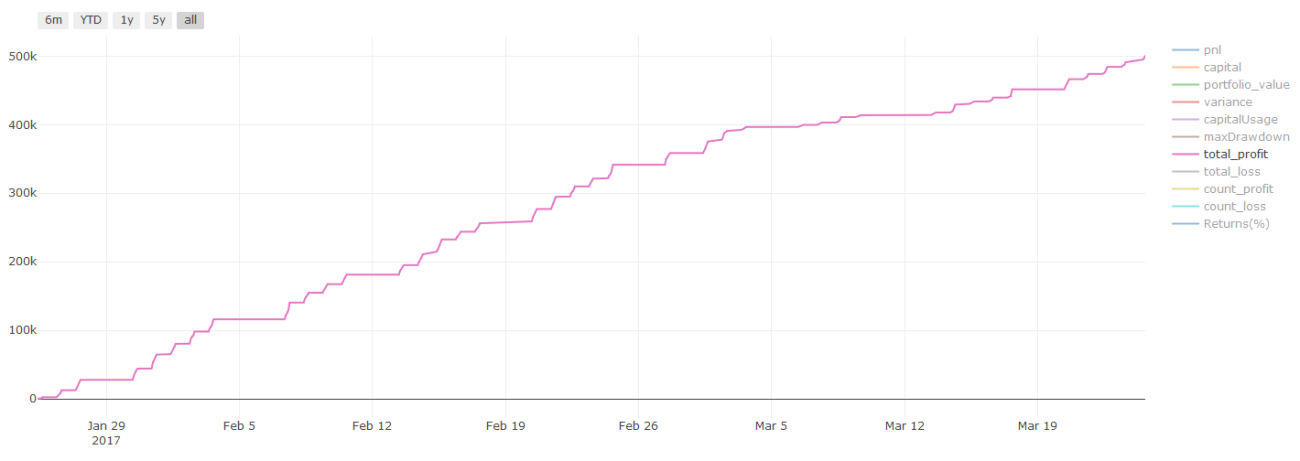
Hasil backtest, Pnl dihitung dalam dolar AS (Pnl tidak termasuk biaya transaksi dan biaya lainnya)
Langkah 8: Cara lain untuk meningkatkan model
Validasi Bergulir, Pembelajaran Ensemble, Bagging dan Boosting
Selain mengumpulkan lebih banyak data, membuat fitur yang lebih baik, atau mencoba lebih banyak model, berikut adalah beberapa hal yang dapat Anda coba tingkatkan.
1. Verifikasi bergulir
Validasi Bergulir
Kondisi pasar jarang tetap konstan. Katakanlah Anda memiliki data selama satu tahun, dan Anda menggunakan data dari Januari hingga Agustus untuk pelatihan, dan data dari September hingga Desember untuk menguji model Anda, Anda mungkin akan melakukan pelatihan untuk serangkaian kondisi pasar yang sangat spesifik. Mungkin tidak ada volatilitas pasar pada paruh pertama tahun ini, dan beberapa berita ekstrem menyebabkan pasar naik tajam pada bulan September. Model Anda tidak akan dapat mempelajari pola ini dan akan memberikan hasil prediksi yang buruk.
Mungkin lebih baik untuk mencoba menggulirkan validasi ke depan, melatih pada bulan Januari-Februari, memvalidasi pada bulan Maret, melatih ulang pada bulan April-Mei, memvalidasi pada bulan Juni, dan seterusnya.
2. Pembelajaran Berkelompok
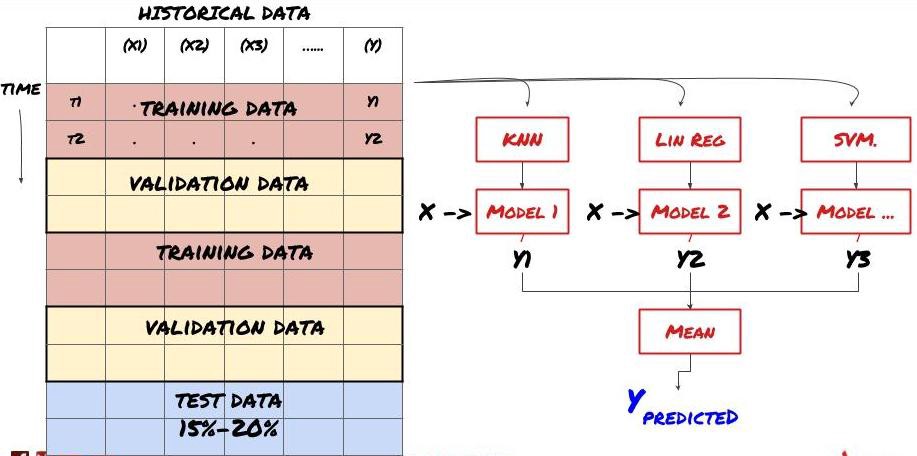
Pembelajaran Berkelompok
Beberapa model mungkin berfungsi baik dalam memprediksi skenario tertentu, tetapi mungkin terlalu akurat dalam memprediksi skenario lain atau situasi tertentu. Salah satu cara untuk mengurangi kesalahan dan overfitting adalah dengan menggunakan kumpulan model yang berbeda. Prediksi Anda akan menjadi rata-rata prediksi yang dibuat oleh banyak model, dan kesalahan dari model yang berbeda dapat diimbangi atau dikurangi. Beberapa metode ensemble yang umum adalah Bagging dan Boosting.
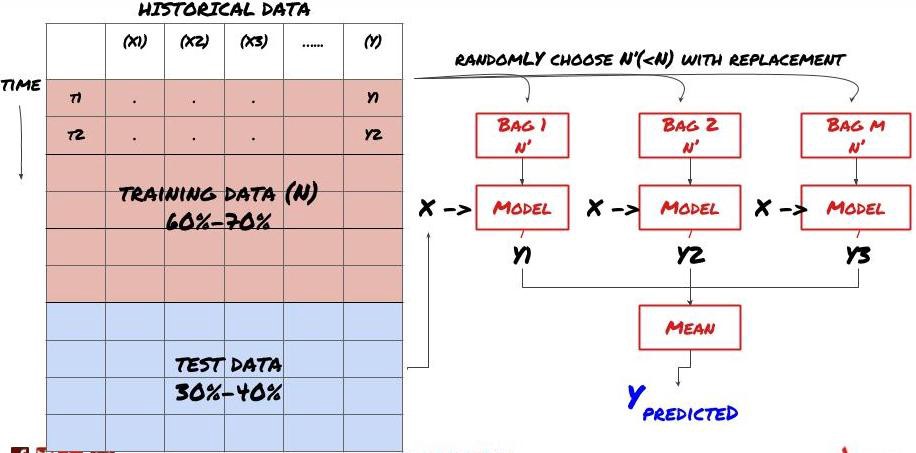
Bagging
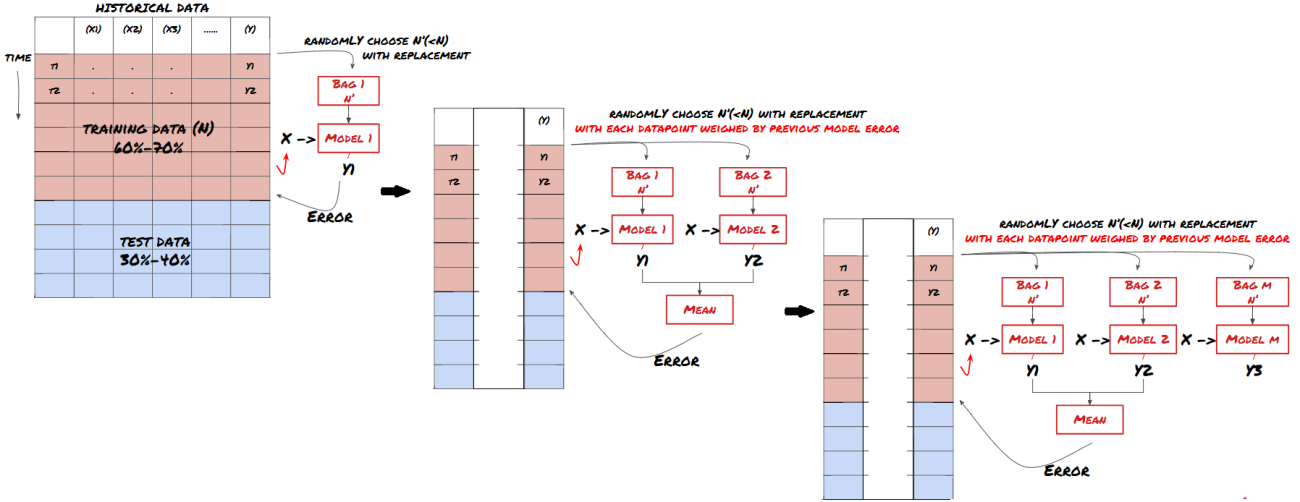
Boosting
Demi singkatnya, saya akan melewatkan metode ini, tetapi Anda dapat menemukan informasi lebih lanjut tentangnya secara daring.
Mari kita coba metode ensemble untuk masalah kita
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Banyak sekali pengetahuan dan informasi yang telah kita peroleh sejauh ini. Mari kita tinjau kembali:
-
Selesaikan masalah Anda
-
Mengumpulkan data yang dapat diandalkan dan membersihkan data
-
Membagi data menjadi set pelatihan, validasi, dan pengujian
-
Membuat fitur dan menganalisis perilakunya
-
Pilih model pelatihan yang tepat berdasarkan perilaku
-
Gunakan data pelatihan untuk melatih model Anda dan membuat prediksi
-
Periksa kinerja pada set validasi dan optimalkan kembali
-
Validasi kinerja akhir pada set pengujian
Cukup menarik, bukan? Namun, ini belum berakhir. Kini Anda hanya memiliki model prediksi yang andal. Ingat apa yang sebenarnya kita inginkan dalam strategi kita? Jadi Anda belum membutuhkan:
-
Mengembangkan sinyal berbasis model prediktif untuk mengidentifikasi arah perdagangan
-
Mengembangkan strategi khusus untuk mengidentifikasi posisi pembukaan dan penutupan
-
Sistem eksekusi untuk mengidentifikasi posisi dan harga
Semua hal di atas memerlukan penggunaan Inventor Quantitative Platform (FMZ.COM). Di Inventor Quantitative Platform, terdapat antarmuka API yang sangat terenkapsulasi dan lengkap, serta fungsi pesanan dan transaksi yang dapat dipanggil secara global, jadi Anda tidak memerlukan untuk menghubungkan dan menambahkannya satu per satu. Antarmuka API dari berbagai bursa, di Strategy Square dari Inventor Quantitative Platform, terdapat banyak strategi alternatif yang matang dan lengkap. Dengan metode pembelajaran mesin dari artikel ini, strategi spesifik Anda akan lebih kuat Strategy Square terletak di: https://www.fmz.com/square
Catatan penting tentang biaya transaksi:Model Anda akan memberi tahu Anda kapan harus mengambil posisi long atau short pada aset pilihan Anda. Akan tetapi, hal itu tidak memperhitungkan biaya/biaya transaksi/volume yang tersedia/stop loss, dll. Biaya transaksi sering kali dapat mengubah perdagangan yang menguntungkan menjadi kerugian. Misalnya, suatu aset diperkirakan harganya naik sebesar $0,05 merupakan pembelian, tetapi jika Anda harus membayar $0,10 untuk melakukan perdagangan ini, Anda akan berakhir dengan kerugian bersih sebesar $0,05. Grafik keuntungan kami yang tampak mengagumkan di atas sebenarnya terlihat seperti ini setelah Anda memperhitungkan komisi broker, biaya pertukaran, dan spread:
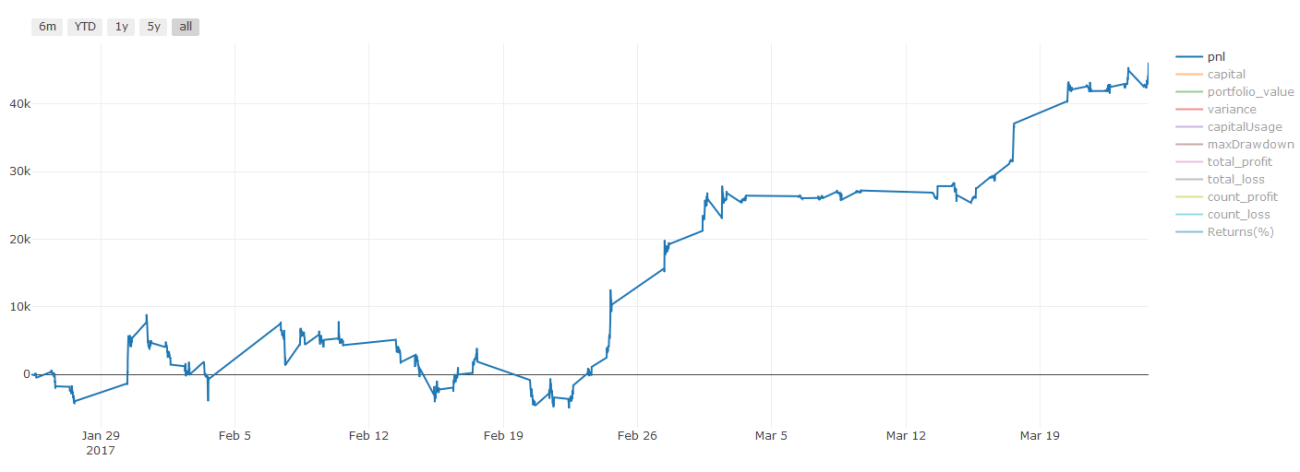
Hasil backtest setelah biaya transaksi dan spread, Pnl adalah USD
Biaya transaksi dan spread mencakup lebih dari 90% Pnl kami! Kami akan membahasnya secara rinci dalam artikel berikutnya.
Terakhir, mari kita lihat beberapa jebakan umum.
Hal yang boleh dan tidak boleh dilakukan
-
Hindari melakukan overfitting dengan sekuat tenaga!
-
Jangan melakukan pelatihan ulang setelah setiap titik data: Ini adalah kesalahan umum yang dilakukan orang dalam pengembangan pembelajaran mesin. Jika model Anda perlu dilatih ulang setelah setiap titik data, maka kemungkinan besar model tersebut bukanlah model yang baik. Artinya, pelatihan ulang perlu dilakukan secara berkala, sesuai kebutuhan (misalnya, pada akhir setiap minggu jika melakukan prakiraan intraday).
-
Hindari bias, terutama bias melihat ke depan: Ini adalah alasan lain mengapa model tidak berfungsi. Pastikan Anda tidak menggunakan informasi apa pun dari masa depan. Sering kali, ini berarti tidak menggunakan variabel target Y sebagai fitur dalam model Anda. Anda dapat menggunakannya selama pengujian ulang, tetapi tidak akan tersedia saat benar-benar menjalankan model Anda, yang akan membuat model Anda tidak berguna.
-
Waspadalah terhadap bias penambangan data: Karena kita mencoba melakukan serangkaian pemodelan pada data kita untuk menentukan apakah data tersebut cocok, jika tidak ada alasan khusus untuk itu, pastikan Anda menjalankan pengujian yang ketat untuk memisahkan pola acak dari pola nyata yang mungkin terjadi . Misalnya, pola tren naik dapat dijelaskan dengan baik melalui regresi linier, tetapi kemungkinan besar merupakan bagian kecil dari pergerakan acak yang lebih besar!
Hindari overfitting
Ini sangat penting sehingga saya rasa perlu disebutkan lagi.
-
Overfitting adalah perangkap paling berbahaya dalam strategi perdagangan
-
Algoritme yang rumit mungkin bekerja sangat baik dalam pengujian ulang tetapi gagal total pada data baru yang tidak terlihat. Algoritme tersebut tidak benar-benar mengungkap tren apa pun dalam data dan tidak memiliki daya prediksi yang nyata. Sangat cocok dengan data yang dilihatnya
-
Jaga sistem Anda sesederhana mungkin. Jika Anda merasa membutuhkan banyak fitur kompleks untuk menjelaskan data Anda, Anda mungkin melakukan overfitting
-
Bagilah data yang tersedia menjadi data pelatihan dan pengujian, dan selalu verifikasi kinerja pada data sampel nyata sebelum menggunakan model untuk perdagangan langsung.



- 1