

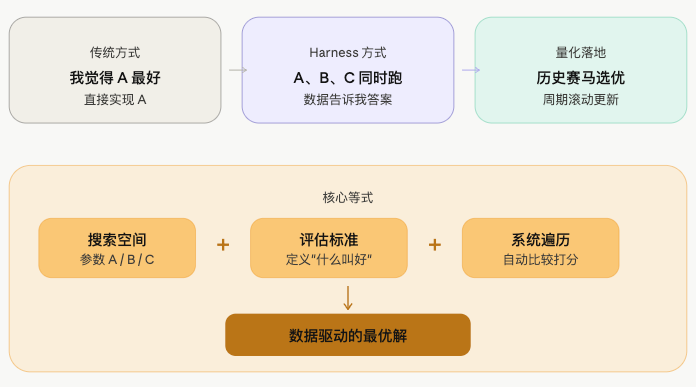
はじめに:Harness Engineer の考え方
最近、AI/MLエンジニアリングコミュニティで、Harness Engineer という考え方がますます広く議論されています。
その核心理念はシンプルです:
自分で頭をひねって答えを出すのではなく、フレームワークを構築し、データと実験に答えを見つけさせるのです。
従来のエンジニアの方法は:パラメータAが良いと判断し、Aを実装するコードを書く。Harness Engineerの方法は:A、B、Cのどれが良いか分からないので、フレームワークを構築し、A、B、Cを同時に実行させ、データが答えを教えてくれる。
エンジニアは探索空間と評価基準を定義し、システムが空間内で自動最適化を行います。この考え方はMLではwalk-forward optimization、AutoMLに対応し、量的取引においても自然に応用できる場面があります。
妖币:最もトレンドが顕著な戦場
暗号通貨の先物市場には、特に注目すべき種類のコインがあります——取引量が極めて大きい「妖币(ヨウビ)」です。
これらのコインには共通する特徴があります:
- 資金が高度に集中しており、大口の行動が顕著
- トレンドの持続性が比較的強い。一度動き出すと長期間続くことが多い
- ボラティリティが高い。一部の高取引量コインは特定の期間に強いトレンド性を示し、移動平均戦略はこのような銘柄に対する過去のバックテストで比較的良好な結果を示している
そのため、これらのコインに古典的なダブル移動平均クロス戦略を適用することは、素朴で合理的な入り口です。短期線が長期線を上抜ければトレンド開始としてフォローし、下抜ければトレンド反転として離脱します。ロジックはシンプルですが、トレンドが明確な銘柄では、過去のパフォーマンスが悪くないことが多いのです。
問題はただ一つ:どのコインが妖币か?どのMAパラメータを使うか?
この二つの問題を人手で判断しようとすると、主観性が強すぎます。人によって全く異なる答えが出る可能性があります。また市場は動的であり、今日の妖币が明日も妖币とは限らず、今日有効なパラメータの組み合わせが明日には無効になる可能性もあります。
ここに Harness Engineer 思想の出番があります。
人手でコインを選びパラメータを調整する代わりに、これら二つの問題をすべてフレームワークに任せます——評価基準を定義し、過去のデータを候補空間の中で自動的に答えを出させるのです。人間がすべきことは何を基準に良し悪しを測るかを決めることであり、残りはシステムに任せます。
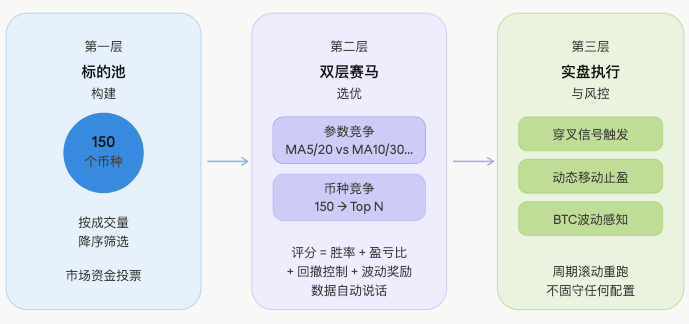
この考えに基づき、戦略全体はローリングフィルタリングフレームワークとして設計され、3層で動作します。
戦略アーキテクチャ:二段階の競馬メカニズム
第一層:銘柄プールの構築
全市場の先物銘柄から、米ドル建て取引量の降順で上位150のコインを候補プールとします。
なぜ取引量か?取引量が多いところに資金が最も集中し、トレンドが形成されやすく、妖币も密集しているからです。このステップでは主観的判断を一切行わず、純粋に市場の資金に投票させ、取引量の多いものがプールに入ります。
javascript
const filtered = tickers
.filter(t => t.Symbol.endsWith('USDT.swap'))
.map(t => ({ symbol: t.Symbol, quoteVolume: t.Last * t.Volume }))
.sort((a, b) => b.quoteVolume - a.quoteVolume)
.slice(0, topN)
.map(t => t.symbol);
ロジックは非常に直接的:USDT先物銘柄をフィルタリングし、米ドル建て取引量を計算、降順に並べ、上位N個を取得します。主観的判断は一切なく、市場の資金が自ら投票します。
第二層:二段階競馬による選別
これは戦略全体で最も核心的な部分であり、Harness思想が最も顕著に表れているところです。
正しい実行順序は次の通りです:
⚠️ 注意:最適パラメータのスコアをそのコインの能力の代表とすることには、ある程度の過学習リスクが内在しています——過去に最も良いパフォーマンスを示したパラメータが、将来も同様に有効であるとは限りません。この限界については後半でさらに議論します。
バックテストプロセス
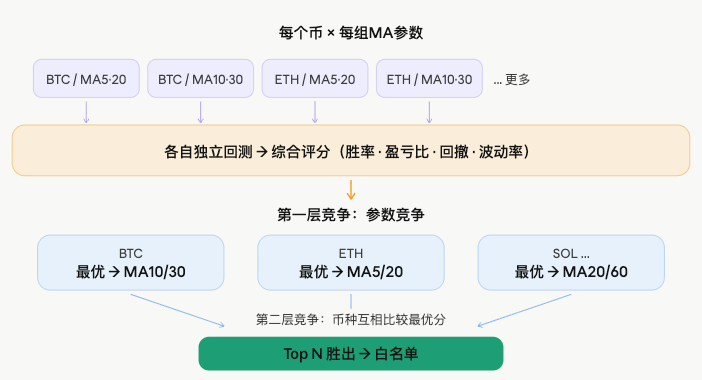
候補プール内の各コインに対して、複数のMAパラメータ組み合わせを同時に実行します。各パラメータ組み合わせは過去のK線で独立して動作し、実際のクロスによるロング・ショートのロジックをシミュレートします:
javascript
// 各コイン × 各パラメータ組み合わせをループ
for (const params of maParamsList) {
const bt = backtest_MA(records, params.fast, params.slow);
// 各バックテストは独立して:勝率、プロフィットファクター、最大ドローダウン、シグナル回数を算出
}
各バックテストの核心ロジックは標準的なダブル移動平均クロスです:
javascript
const crossUp = fastMA[i-1] <= slowMA[i-1] && fastMA[i] > slowMA[i];
const crossDown = fastMA[i-1] >= slowMA[i-1] && fastMA[i] < slowMA[i];
if (crossUp) position = { side: 'long', entryPrice: records[i].Close };
if (crossDown) position = { side: 'short', entryPrice: records[i].Close };
総合スコアリング
バックテスト完了後、各パラメータ組み合わせの結果に対して総合スコアを算出します。スコアは二つの要素で構成されます:
標準化加重スコア(合計係数 0.80):
javascript
const score =
Math.min(bt.winRate * 100, 100) * 0.30 // 勝率、上限100
+ Math.min(bt.profitFactor * 20, 60) * 0.30 // プロフィットファクター、上限60
+ Math.max(0, 1 - bt.maxDrawdown / maxMDD) * 100 * 0.20 // 最大ドローダウン制御
+ volPct * volPctBonus // ボラティリティ分位ボーナス加点項目
ボラティリティ分位ボーナス加点項目:最後の volPct × volPctBonus(デフォルト係数は10)は、加重体系から独立したボーナス項目であり、同じスコア条件下では現在のボラティリティが過去の高い分位にあるコインを優先的に選択するために用います——なぜなら、そのようなコインはトレンドがより活発である傾向があるためです。
ただし、この加重とボーナス係数は経験則に基づく設定であり、最適化によって導き出されたものではありません。実際の使用では市場環境に応じてさらに調整することが可能です。
第一段階の競争:パラメータ競争
同じコインの複数パラメータ組み合わせはそれぞれスコアを算出し、最高スコアのものをそのコインの代表スコアおよび最適パラメータとします:
javascript
if (score > bestScore) {
bestScore = score;
bestResult = bt;
bestParams = params; // 当該歴史期間で最良のパフォーマンスを示したパラメータ組み合わせを記録
}
第二段階の競争:コイン競争
すべてのコインがそれぞれの最適スコアを持ち寄り、並べ替えて上位N個をホワイトリストに投入します:
javascript
results.sort((a, b) => b.score - a.score);
const whitelist = results.slice(0, topCoins).map(r => r.coin);
最終的に出力されるのは、各ホワイトリストコインに対応する専用の最適移動平均パラメータであり、単一のパラメータセットをすべてに使うわけではありません。
第三層:実取引実行とリスク管理
選別された設定を用いて実取引を行い、同時に複数層のリスク管理機構を重ねます:
シグナルトリガー:リアルタイムでホワイトリストコインの移動平均クロス状態を検出し、ゴールデンクロスならロング、デッドクロスならショート:
javascript
const crossUp = fastPrev <= slowPrev && fastCur > slowCur;
const crossDown = fastPrev >= slowPrev && fastCur < slowCur;
if (crossUp) longList.push(sym);
if (crossDown && allowShort) shortList.push(sym);
移動利食い:含み益がトリガーしきい値に達した後に起動し、しきい値は含み益に応じて動的に引き締まります。三つの段階のしきい値は経験設定であり、核心理念は含み益が高くなるほどドローダウン許容度を小さくし、既得利益を確定させることです:
javascript
function getDynamicTrailDrawdown(maxPnl) {
if (maxPnl >= 7) return 3; // 含み益が高い、ドローダウン許容を引き締め
if (maxPnl >= 4) return 2;
return 1.5; // 含み益が低い、相場に余裕を持たせる
}
市場状態認識:BTCのボラティリティ分位を検出し、高ボラティリティ環境では自動的にポジション係数を低減し、極端な相場ではショートを直接禁止します:
javascript
if (marketState === 'volatile') positionScaleDown = 0.5;
else if (marketState === 'high_vol') positionScaleDown = 0.8;
else if (marketState === 'low_vol') positionScaleDown = 0.7;
選別プロセス全体は周期的にローリング再実行され、単一の設定に固執せず、市場に応じてホワイトリストとパラメータを動的に更新します。
基盤となる仮定:トレンドの持続性
このフレームワークが成立するためには、ある核心的な仮定に依存しています:
直近の歴史において良好なパフォーマンスを示したコインとパラメータは、その後の短期間においてもある程度の持続性を持つ。
これはオカルトではなく、背後には一定の市場ロジックがあります——資金の慣性、市場心理の継続、主力の行動の一貫性が、トレンドを一定の時間枠内で有効に保ちます。
しかし正直に言う必要があります:この仮説は厳密な統計的検証を経ていません。それはどちらかと言えば経験的な判断です。フレームワークが実運用で持続的に有効かどうかは、最終的には実際の取引データによって検証される必要があります。
本物のHarness Engineerとの違い
この点は明確にしておく必要があります。
この戦略にはHarnessの形がありますが、本物のHarness Engineerの体系と比較すると、まだ明らかなギャップがあります。
| 次元 | 本物のHarness | この戦略 |
|---|---|---|
| サンプル分割 | トレーニングセット + 検証セット + holdoutテストセット | 全履歴データでバックテスト、サンプル外検証なし |
| オーバーフィッティング対策 | 明確な汎化性テストあり | パラメータの多様性による部分的なヘッジに依存、不完全 |
| 実験の分離 | 各バリアントが独立して実行され相互影響なし | 同一のローソク足を共有、暗黙の結合あり |
| リリース基準 | validationを通過してからデプロイ | スコアが最も高いものが直接リリース、二次検証層なし |
| 誤差の累積 | 各層の評価は独立 | 2層の競馬はともに過去の最適値に基づく、誤差が累積する |
核心的な差は、本物のHarnessは「この結果はサンプル外でも成立するのか」と問いかけますが、この戦略の2層競馬で選ばれた「最適」は本質的に過去最適です——パラメータレベルでのオーバーフィッティングに、通貨レベルでのオーバーフィッティングが重なっており、将来にわたって有効かどうかは永遠に未解決の問題です。
結語:刻舟求剣、それとも試す価値があるか?
量的世界では、予測は常に極めて難しいことです。
多くの人は、過去のデータでパラメータを選んで実運用するのは、本質的に刻舟求剣(川で剣を落とした後、船べりに印を刻んでも剣を見つけられない)だと言うでしょう——剣はもう水中に落ちたのに、船に刻んだ目印では見つけられない。市場は変わり、有効なパラメータは無効になり、今日の怪しい通貨は明日には平凡になり、昨日の最適移動平均線は今日ではノイズになるかもしれません。
この批判には一理あります。
しかし、話を戻すと、やるべき試みは、やるべきです。
定量化の本質は、永遠に正しい答えを見つけることではなく、不確実性の中で系統的に勝率を高めることです。たとえ刻舟求剣であっても、まず船を手に入れ、印を刻む必要があります——戦略(舟)を位置づけること自体が、定量化の始まりです。
もちろん、フレームワーク自体は利益を保証しません。フレームワークがあるのは単なる出発点であり、真の価値は継続的な実行と反復にあります:ホワイトリストを調整でき、スコアの重みを変更でき、パラメータ空間を拡張でき、利確・損切りを最適化できます。調整のたびに新しい実験となり、このフレームワークを本物のHarnessに近づけていきます。
道は歩いて作るものであって、考えて作るものではありません。
戦略ソースコード:Harness Engineer 移動平均線選別定量化戦略
- 1