機械学習技術の取引への応用
作者: リン・ハーンリディア, 作成日:2022-12-30 10:53:07, 更新日:2023-09-20 09:30:09
機械学習技術の取引への応用
この記事へのインスピレーションは FMZ Quant プラットフォームのデータ調査中にトランザクション問題に対して機械学習技術を適用しようとしたときに,ある一般的な警告や罠を観察した結果です.
この記事より前に FMZ Quantプラットフォームで確立した自動化データ調査環境ガイドと取引戦略の体系的な方法を読んでください.
この2つの記事の住所はこちらです.https://www.fmz.com/digest-topic/9862そしてhttps://www.fmz.com/digest-topic/9863.
研究環境の構築について
このチュートリアルは,すべてのスキルレベルのエキスパート,エンジニア,データサイエンティスト向けです.業界リーダーでもプログラミング初心者でも,必要な唯一のスキルは,Pythonプログラミング言語の基本的な理解とコマンドライン操作の十分な知識です (データサイエンスのプロジェクトを設定することが十分です).
- FMZ Quant ドッカーをインストールして Anaconda を設定します
FMZ 量子プラットフォームFMZ.COMこのインターフェースは,データ分析を完了した後,自動取引を行うのに役立つ豊富な API インターフェースのセットを提供します.このインターフェースのセットには,アカウント情報をクエリする,高,オープン,低,領収書価格,取引量,および様々な主流取引所の一般的に使用される技術分析指標などの実践的なツールが含まれています.特に,実際の取引プロセスで主要な主流取引所を接続する公開 API インターフェースに強力な技術的サポートを提供します.
上のすべての機能は Docker のようなシステムに収縮されています. 必要なのは,独自のクラウドコンピューティングサービスを購入またはリースし,Docker システムを展開することです.
FMZ Quantプラットフォームの公式名称では,Dockerシステムと呼ばれています.
ドッカーとロボットの展開について 私の前の記事を参照してください:https://www.fmz.com/bbs-topic/9864.
ドーカーを展開するために独自のクラウドコンピューティングサーバを購入したい読者は,この記事を参照してください:https://www.fmz.com/digest-topic/5711.
次に,Pythonの現在の最大のアーティファクトをインストールします. Anaconda.
この記事で要求されるすべての関連するプログラム環境 (依存ライブラリ,バージョン管理など) を実現するために,最も簡単な方法は Anaconda を使用することです.これはパッケージ化された Python データサイエンスエコシステムと依存ライブラリマネージャです.
Anacondaをクラウドサービスにインストールするので,クラウドサーバーに Linux システムと Anaconda のコマンドラインバージョンをインストールすることをお勧めします.
アナコンダのインストール方法については,アナコンダの公式ガイドを参照してください.https://www.anaconda.com/distribution/.
経験豊富な Python プログラマーで,Anaconda を使用する必要がないと感じている場合は,全く問題ありません.必要な依存環境をインストールする際に助けを必要としないと仮定します.このセクションを直接スキップできます.
取引戦略を策定する
取引戦略の最終的な成果は,次の質問に答えなければならない.
-
方向性:資産が安価,高価,またはフェアバリューであるかどうかを決定する.
-
オープンポジション条件:資産が安価か高価な場合は,ロングまたはショートに行くべきです.
-
閉じる ポジション 取引:資産の価格が合理的で,その資産にポジションがある場合 (前回の購入または販売) ポジションを閉じるべきですか?
-
価格範囲: ポジションが開かれた価格 (または範囲).
-
取引量:取引された貨幣の量 (例えば,デジタル通貨の量または商品先物取引先のロット数).
機械学習を使って これらの質問に答えることができますが この記事の残りの部分では 貿易の方向性という 最初の質問に焦点を当てます
戦略的アプローチ
戦略の構築には2種類のアプローチがあります.一つはモデルに基づいています.もう一つはデータマイニングに基づいています.この2つの方法は基本的に互いに反対です.
モデルベースの戦略構築では,市場非効率モデルからスタートし,数学的表現 (価格と利益など) を構築し,長期間にわたってその有効性をテストする.このモデルは通常,実際の複雑なモデルの簡略化されたバージョンであり,その長期的意義と安定性を検証する必要がある.一般的な傾向は,平均逆転と仲介戦略がこのカテゴリーに属します.
一方,私たちはまず価格パターンを探して,データマイニング方法でアルゴリズムを使用しようとします.これらのパターンの理由は重要ではありません.なぜなら,特定されたパターンだけが将来的に繰り返されるからです.これは盲目分析方法であり,ランダムなパターンから実際のパターンを識別するために厳格にチェックする必要があります.
明らかに,機械学習はデータマイニング方法に適用するのは非常に簡単です.データマイニングを通じてトランザクション信号を作成するために機械学習を使用する方法を見てみましょう.
コード例は,FMZ Quant プラットフォームと自動トランザクション API インターフェースをベースにしたバックテストツールを使用しています.ドッカーを展開し,上記のセクションで Anaconda をインストールした後,必要なデータサイエンス分析ライブラリと有名な機械学習モデル scikit-learn をインストールするだけです.このセクションを繰り返しません.
pip install -U scikit-learn
機械学習を使用して取引戦略の信号を作成します
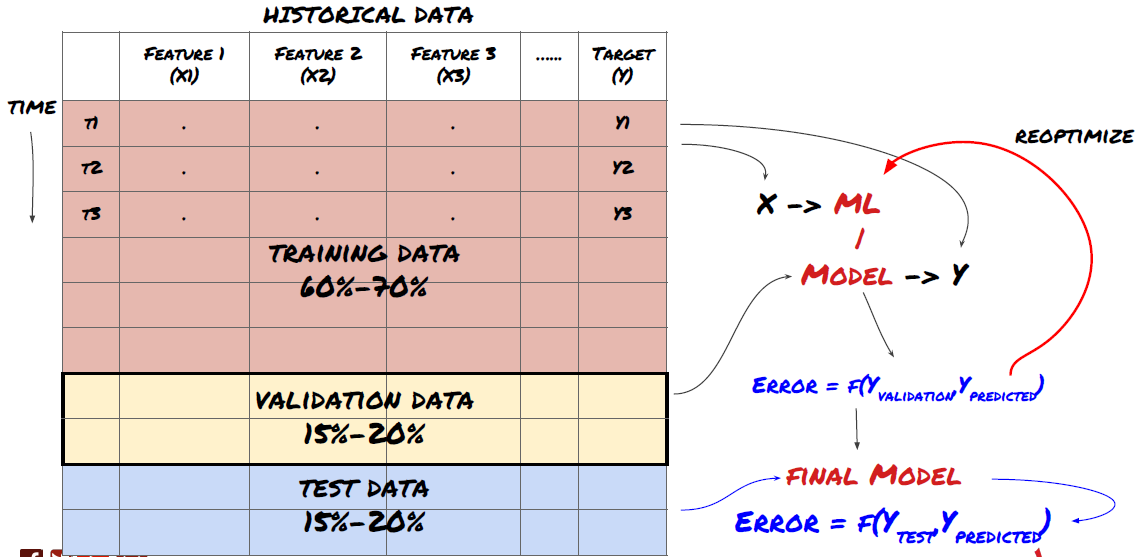
- データマイニング 機械学習の標準的な問題システムは次の図で示されています
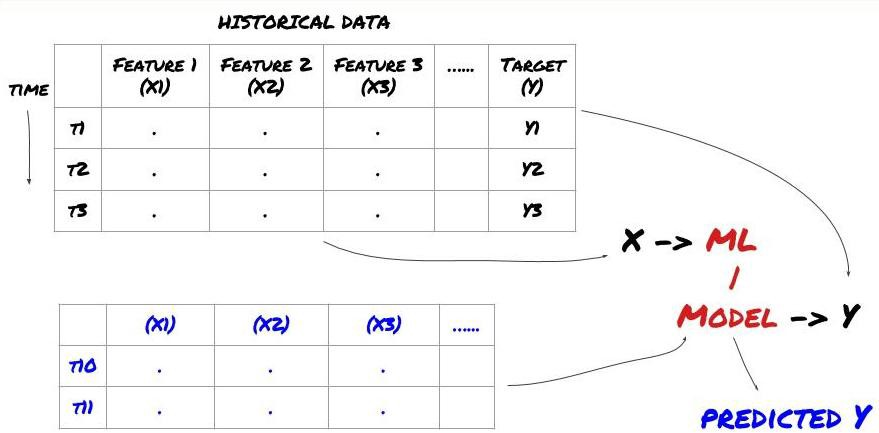
機械学習の問題システム
作成する機能は,予測能力 (X) が一定である必要があります. 目標変数 (Y) を予測し,実際の値にできるだけ近いYを予測できるMLモデルを訓練するために歴史的なデータを使用します. 最後に,このモデルを使用して,Yが未知の新しいデータで予測します. これは最初のステップに導きます:
ステップ 1: 質問 を 立て
- 予測結果はどう評価しますか? 予測結果はどうですか?
Y は何ですか? Y は何ですか?
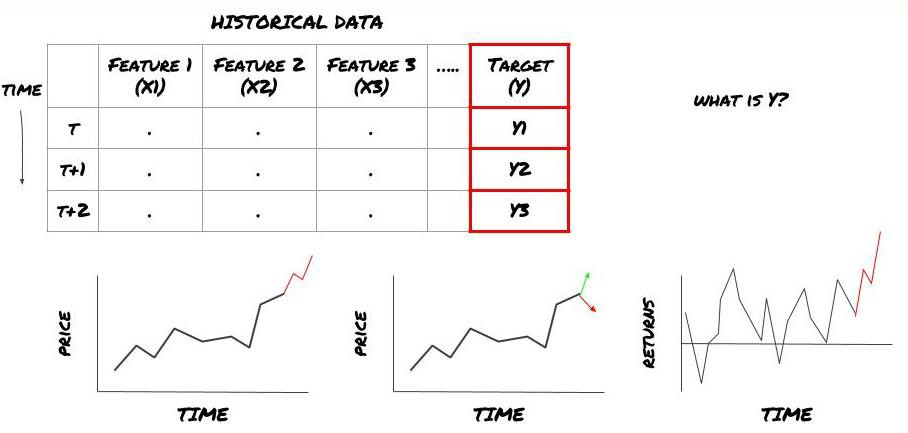
何を予測したいの?
将来の価格,将来の収益/Pnl,買い/売るシグナルを予測し ポートフォリオの配置を最適化し 取引を効率的に実行したいですか?
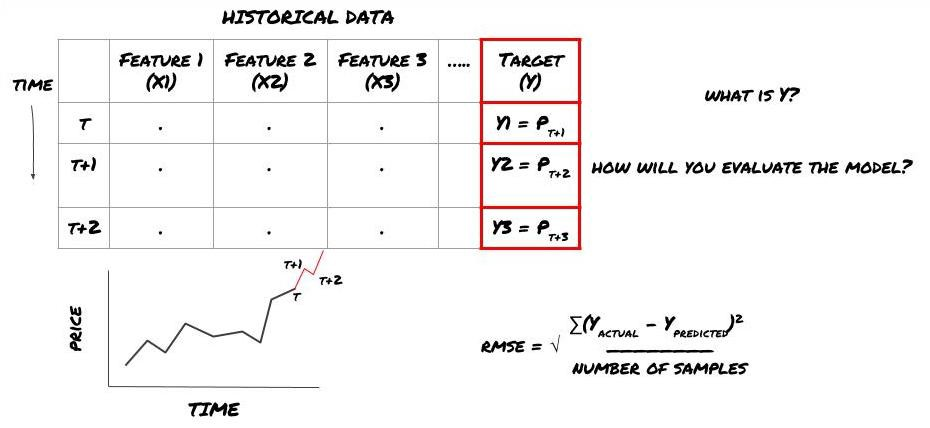
この例では,Y (t) =価格 (t+1) です. フレームワークを完了するために,歴史的なデータを使用できます.
Y (t) はバックテストでしか知られていないことに注意してください.しかし,モデルを使用すると,時間 t の価格 (t+1) を知りません.モデルを使用してY (予測,t) を予測し,それを時間 t+1 の実際の値とのみ比較します.これは,予測モデルの特徴としてY を使用することはできませんことを意味します.
目標Yを知った後,予測の評価方法も決定できます.これは,試すデータの異なるモデルを区別するために重要です. モデルの効率を測定するための指標を選択し,解決している問題に応じて測定します. 例えば,価格を予測する場合は,指数としてルーツ・ミッド・スクエア・エラーを使用できます. 一般的に使用される指標 (EMA,MACD,バリエンススコアなど) がFMZ Quantツールボックスにプリコードされています. これらの指標をAPIインターフェースを通じてグローバルに呼び出すことができます.
将来の価格を予測するためのMLフレームワーク
演示目的で,仮定投資対象物の予想される将来の基準値 (ベース値) を予測するための予測モデルを作成します.
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
これは回帰問題なので,モデルをRMSE (ルート・ミディアン・スクエア・エラー) で評価します.評価基準として総PNlも使用します.
注: RMSE に関する数学的な知識については,Baidu Encyclopedia を参照してください.
- 予測値が Yにできるだけ近いモデルを作ります
ステップ2 信頼性の高いデータ収集
問題を解くのに役立つデータを集め 整理してください
目標変数 Y を予測できるデータは何を考えなければならないか? 価格を予測する場合は,投資対象物の価格データ,投資対象物の取引量データ,関連投資対象物の類似データ,投資対象物のインデックスレベル,その他の全体的な市場指標,その他の関連資産の価格を使用できます.
このデータに対するデータアクセス権限を設定し,データが正確であることを確認し,失われたデータ (非常に一般的な問題) を解決する必要があります.同時に,モデルにおける偏見を避けるために,データが公正で,すべての市場状況 (例えば,同じ数の利益と損失シナリオ) を完全に代表していることを確認してください.また,配当,分割投資目標,継続等を得るためにデータをクリーンアップする必要があります.
FMZ Quantプラットフォーム (FMZ.COM) を使用すると,Google,Yahoo,NSE,Quandlからの無料グローバルデータ,CTPやEsunnyなどの国内商品先物深度データ,Binance,OKX,Huobi,BitMexなどの主流デジタル通貨取引所のデータにアクセスできます.FMZ Quantプラットフォームは,投資目標の分割や深層市場データなどのデータをプリクリーンしフィルタリングし,定量的な実践者が容易に理解できる形式で戦略開発者に提示します.
この記事の実証を容易にするために,仮想投資目標のMQKとして以下のデータを使用します.また, Auquan
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
上記のコードで,Auquan
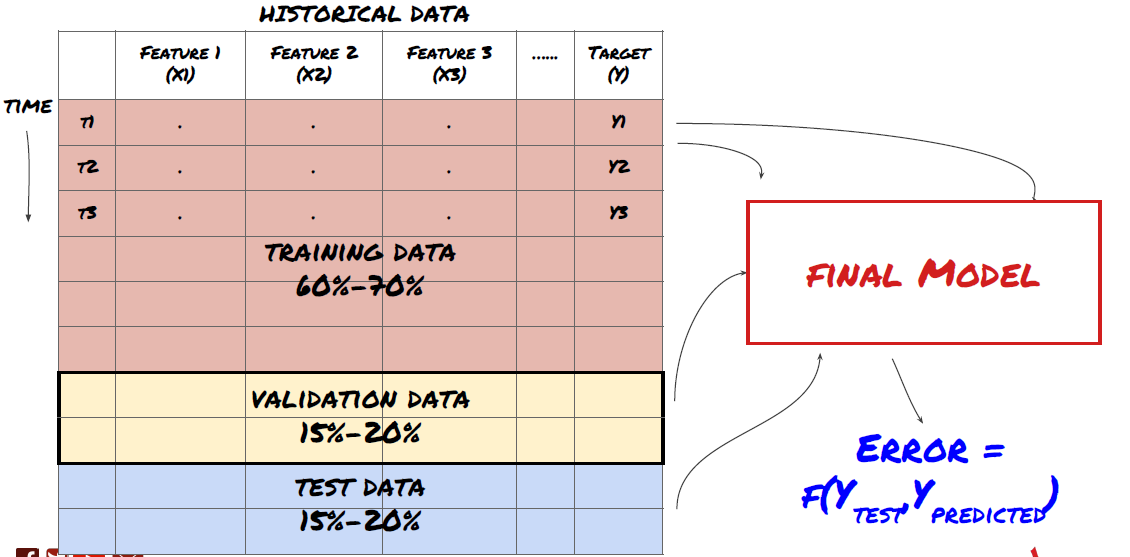
ステップ3:データを分割する
- 訓練セットを作成し,クロス検証を行い,データからこれらのデータセットをテストします
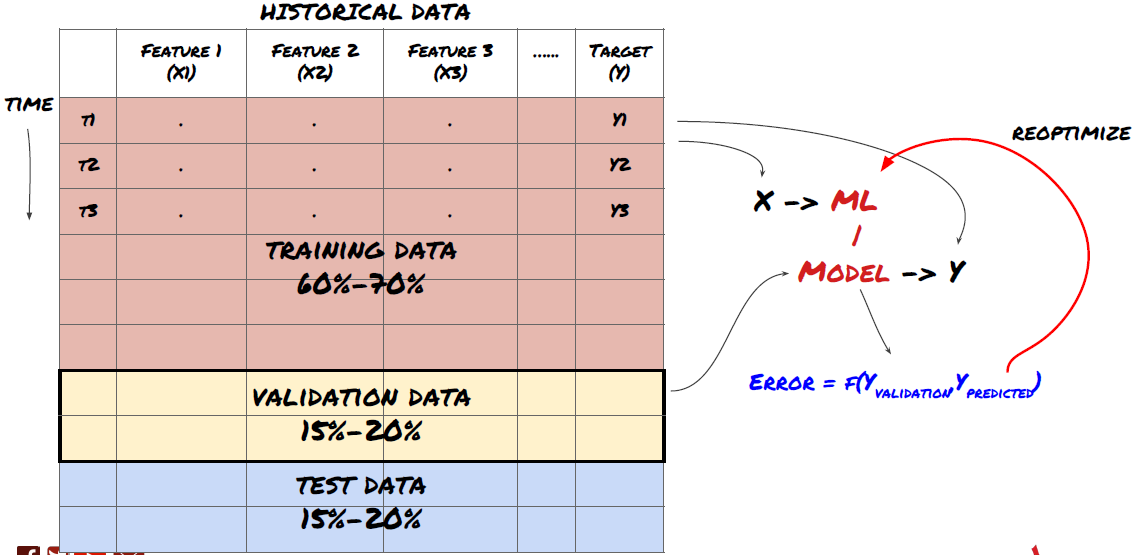
これはとても重要な一歩です!モデルを訓練するためのトレーニングデータセット,モデルパフォーマンスを評価するためのテストデータセットに分割します. 60-70%のトレーニングセットと30-40%のテストセットに分割することが推奨されます.
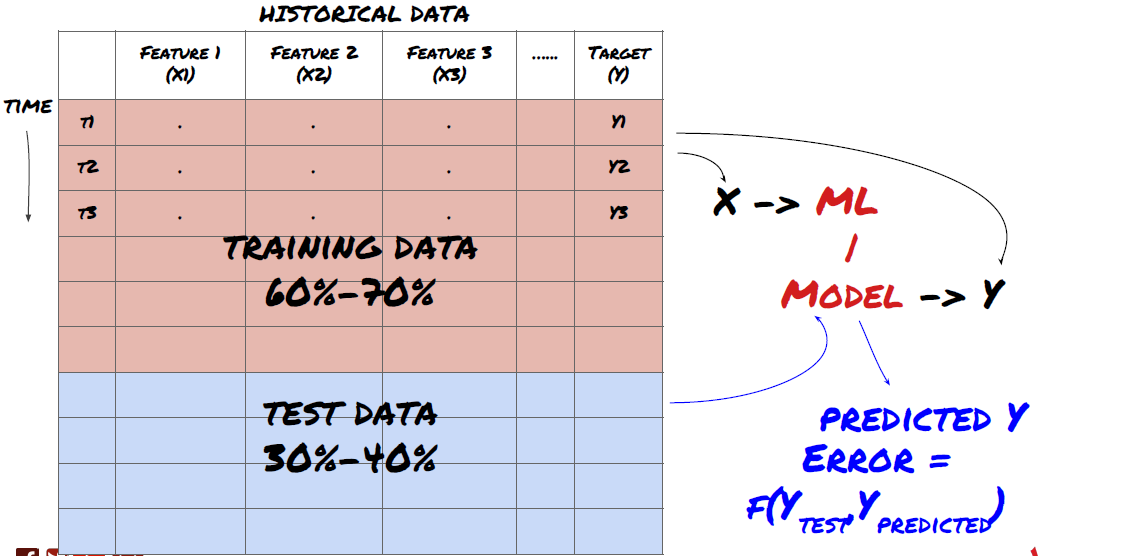
データをトレーニングセットとテストセットに分割する
訓練データはモデルパラメータを評価するために使用されるため,あなたのモデルはこれらのトレーニングデータに過剰に適合し,トレーニングデータはモデルのパフォーマンスを誤導する可能性があります.あなたが個々のテストデータを保持せず,トレーニングのためにすべてのデータを使用しない場合は,あなたのモデルは新しい目に見えないデータでどのようにうまくやっていいかわからないでしょう.これはリアルタイムデータにおける訓練されたMLモデルの失敗の主な理由の一つです.人々は利用可能なすべてのデータを訓練し,トレーニングデータ指標に興奮しますが,モデルは訓練されていないリアルタイムデータについて有意義な予測を行うことができません.
データをトレーニングセット,検証セット,テストセットに分割する.
この方法には問題があります.もしトレーニングデータを繰り返しトレーニングし,テストデータのパフォーマンスを評価し,パフォーマンスを満足するまでモデルを最適化した場合,テストデータをトレーニングデータの部分として暗黙に受け止めます.結局のところ,私たちのモデルはこのトレーニングとテストデータのセットでうまく機能するかもしれませんが,新しいデータをうまく予測できることを保証することはできません.
この問題を解くには,別々の検証データセットを作成できます. データをトレーニングし,検証データのパフォーマンスを評価し,パフォーマンスを満足するまで最適化し,最終的にテストデータをテストできます. この方法で,テストデータは汚染されることはありません. そして,テストデータの情報をモデルを改善するために使用しません.
テストデータのパフォーマンスを確認した後に,モデルをさらに最適化しようとしないでください.モデルが良い結果を出さないと判断した場合,モデルを完全に捨てて,再び開始してください.トレーニングデータの60%,検証データの20%,テストデータの20%を分割することが提案されています.
3つのデータセットがあります. 1つはトレーニングセット,2つ目は検証セット,3つ目はテストセットです.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
目標変数 Y を加算します この変数は次の5つの基本値の平均値として定義されます
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
ステップ4 機能工学
データの行動を分析し,予測機能を作成する
現在,実際のプロジェクト構築が開始されています. 機能選択の黄金ルールは,予測能力は主にモデルではなく機能から来ることです. 機能の選択がモデル選択よりもパフォーマンスにはるかに大きな影響を与えることを発見します. 機能選択のためのいくつかの考慮事項:
-
ターゲット変数との関係を調べずに ランダムに 大きい特徴を選択しないでください
-
目標変数との関係が少ないか全くない場合,過剰なフィットメントを引き起こす可能性があります.
-
選択した特徴は 相互に密接に関連している可能性があります この場合は 少数の特徴も ターゲットを説明できます
-
対象変数とこれらの特性との相関を確認し どちらを使うかを判断します 対象変数とこれらの特性との相関を調べます
-
また,主要な成分分析 (PCA) や他の方法を使って,最大情報係数 (MIC) に基づいて候補特性を分類することもできます.
特徴変換/正常化:
MLモデルは標準化に関して良好なパフォーマンスを発揮する傾向があります.しかし,将来のデータ範囲が不明であるため,時間系列データに対処するときに標準化は困難です.あなたのデータは標準化範囲外にあり,モデルエラーを引き起こす可能性があります.しかし,一定の安定性を強制しようとすることができます:
-
スケーリング: 標準偏差やクォーティルの範囲で特徴を分割する.
-
中心化: 過去の平均値を現在の値から引く.
-
標準化:上記の2回 (x=平均) /stdev
-
規則的な正規化: - 1 から +1 までの範囲にデータを標準化し,バックトラッキング期間 (x-min) / ((max min) 内に中心を再決定する.
追溯期を超えた歴史的連続平均値,標準偏差,最大値または最小値を使用しているため,特徴の標準化標準化値は異なる時点での異なる実際の値を表すことに注意してください.例えば,特徴の現在の値が5で,連続30期間の平均値は4.5である場合,中心化後に0.5に変換されます.その後,30期連続の平均値が3になると,値3.5は0.5になります.これは間違ったモデルの原因かもしれません.したがって,標準化は難しいので,モデルのパフォーマンスを改善するもの (実際に存在する場合) を解明する必要があります.
複合パラメータを使用して多くの特徴を作成しました. その後,特徴の数を減らすことができるか試してみます.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
ステップ 5: モデルの選択
選択された質問に応じて適切な統計/MLモデルを選択します.
モデルの選択は,問題の形成方法によって決まる.あなたは監督された (特徴マトリックス内の各点Xはターゲット変数Yにマッピングされる) 解決していますか?それとも監督されていない学習 (与えられたマッピングなしでは,モデルは未知のパターンを学習しようとします) ですか? あなたは回帰 (将来の時間の実際の価格を予測する) または分類 (将来の時間の価格の方向性 (増加/減少) を予測するのみ) を扱っていますか?

監督された学習や監督されていない学習

退行または分類
いくつかの一般的な監督学習アルゴリズムは 始められるように役立ちます:
-
線形回帰 (パラメータ,回帰)
-
ロジスティック回帰 (パラメータ,分類)
-
K-近隣人 (KNN) アルゴリズム (ケースベース,回帰)
-
SVM,SVR (パラメータ,分類,回帰)
-
決定樹
-
決定の森
線形または論理回帰のような単純なモデルから始め,必要に応じてより複雑なモデルを構築することを提案します.また,盲目的にブラックボックスとして使用するのではなく,モデルの背後にある数学を読むことをお勧めします.
ステップ 6:訓練,検証,最適化 (ステップ4〜6を繰り返す)
訓練と検証データセットを使用してモデルを訓練し最適化します
この段階では,モデルとモデルのパラメータを繰り返すだけです.トレーニングデータでモデルをトレーニングし,検証データでパフォーマンスを測定し,それから戻し,最適化,再訓練,評価します.モデルのパフォーマンスに満足していない場合は,別のモデルを試してみてください.最終的に満足したモデルを得るまで,この段階を何度も繰り返します.
好きなモデルを見つけたら 次のステップに移ります
簡単な線形回帰から始めましょう.
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
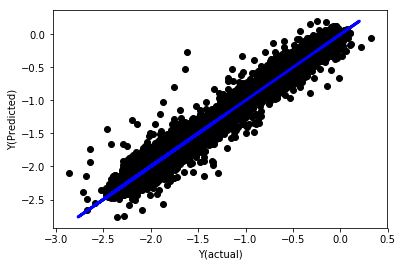
標準化なしの線形回帰
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
モデル係数を見てみましょう. どの係数が重要かを比較したり,判断したりできません. なぜなら,それらはすべて異なるスケールに属しているからです. 標準化して,同じ比例に適合させ,また,いくつかのスムーズさを強制してみましょう.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
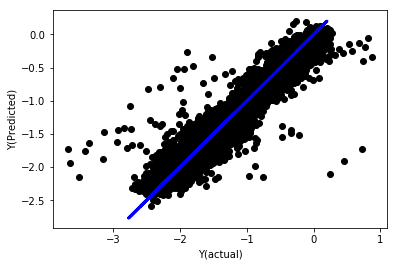
標準化による線形回帰
Mean squared error: 0.05
Variance score: 0.90
このモデルは前モデルを改善しませんが 劣化していません. 現在,係数を比較して どれが本当に重要かを見ることができます.
では,係数を見てみましょう.
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
結果は以下の通りです.
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
予測能力が強くなっていることもあります 予測能力が強くなっていることもあります 予測能力が強くなっていることもあります
異なる特徴との相関を見てみましょう.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
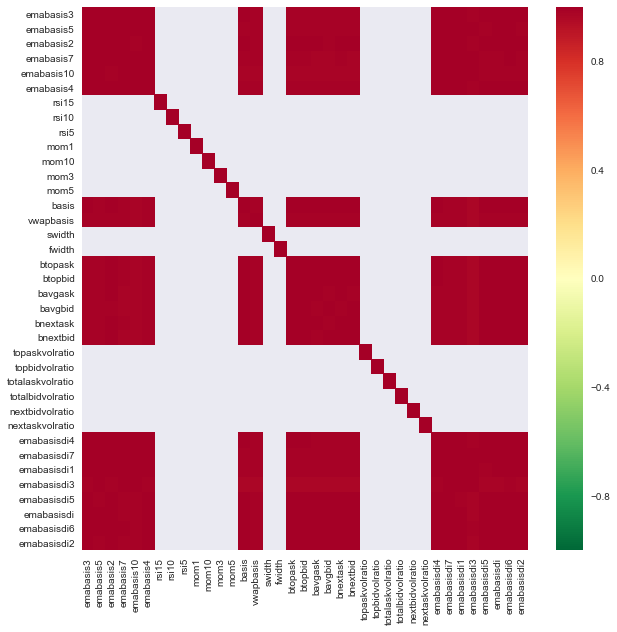
特徴間の相関
濃い赤色の領域は高度に相関する変数を表しています. いくつかの機能を再び作成/修正してモデルを改善してみましょう.
例えば,Emabasisdi7のような機能は 簡単に捨てることができます. 他の機能の線形組み合わせだけです.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
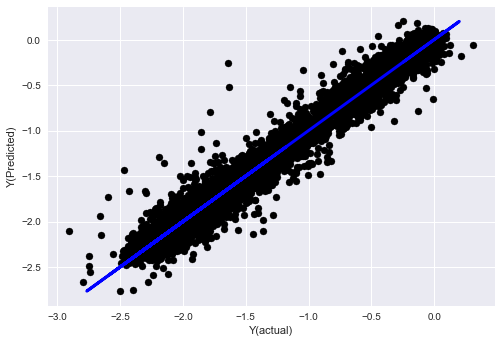
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
モデルの性能は変わっていません. 目標変数を説明するために,いくつかの特徴が必要です. 上記の機能をもっと試してみてください. 新しい組み合わせを試してみてください.
さらに複雑なモデルを試して モデルの変化が 性能を向上させるかどうかを調べます
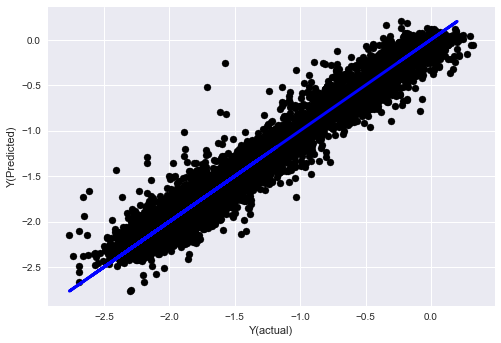
- K-近隣人 (KNN) アルゴリズム
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
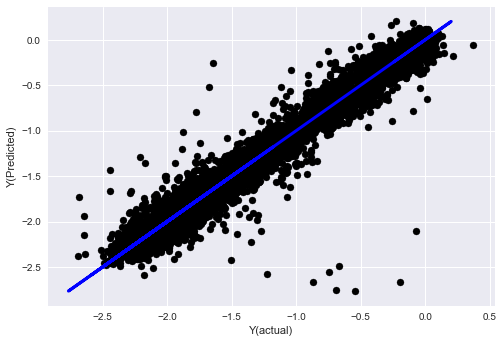
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- 決定樹
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
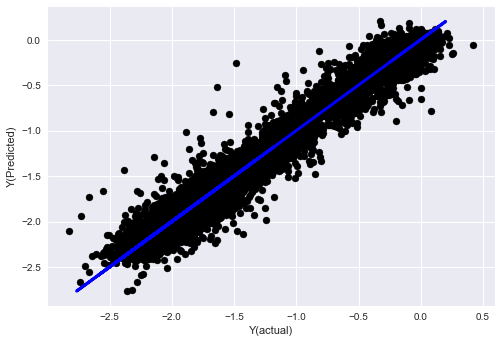
ステップ7 テストデータをバックテストする
実際のサンプルデータの性能をチェックする
(未使用) 試験データセットのバックテスト性能
テストデータの最後のステップから 最終的な最適化モデルを実行し 最初から脇に置いて 今のところデータには触っていません
これは,リアルタイム取引を開始するときに,モデルが新しい未知のデータでどのように実行されるかを現実的な期待を与えます.したがって,モデルを訓練または検証するために使用されないクリーンなデータセットを持っていることを確認する必要があります.
テストデータのバックテスト結果が気に入らない場合は,モデルを捨て,再起動してください. モデルを戻したり再最適化したりしないでください. これはオーバーフィッティングにつながります! (また,新しいテストデータセットを作成することもお勧めします.このデータセットが汚染されているため,モデルを捨てると,私たちは既にデータセットの内容を暗黙に知っています).
この場合は,まだ Auquan のツールボックスを使用します.
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
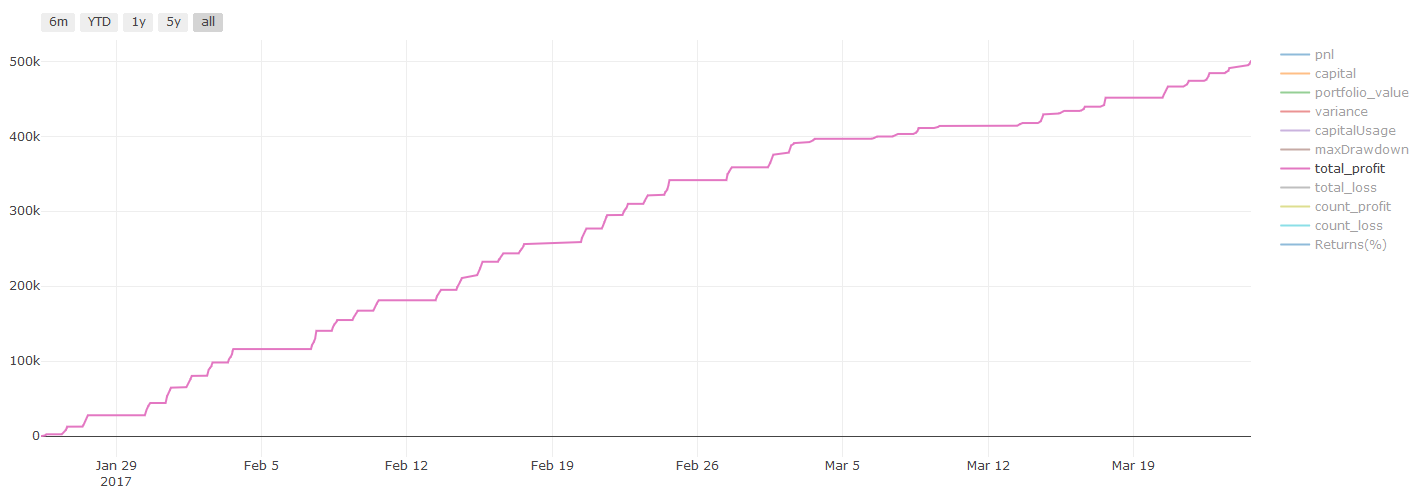
バックテストの結果,PnlはUSDで計算されます (Pnlは取引費用やその他の手数料に含まれていません)
ステップ8 モデルを改善するための他の方法
ローリング検証,セット学習,バッグリング,ブーシング
より多くのデータを収集したり より良い機能を作成したり より多くのモデルを試したりするだけでなく 改善しようと試みる点もあります
1. ローリング 検証
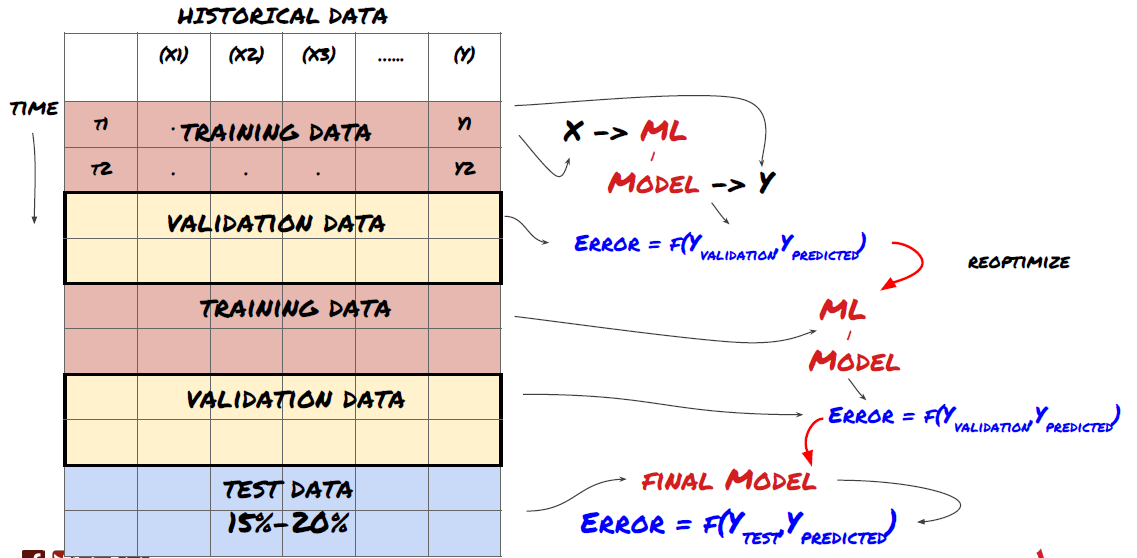
ローリング検証
市場情勢はめったに変わらない. 1年分のデータを持っていて,1月から8月のデータをトレーニングに使用し,9月から12月のデータをモデルをテストするために使用するとします. 最終的には非常に特定の市場情勢のためにトレーニングするかもしれません. 年の前半には市場の変動がなかったかもしれません. そして,いくつかの極端なニュースが9月に市場の急上昇につながりました. モデルはこのモデルを学習することができず,ゴミ予測結果をもたらします.
先行的な検証を試みる方が良いかもしれません.例えば1月から2月にかけて訓練,3月にかけて検証,4月から5月にかけて再訓練,6月にかけて検証などです.
2. セット 学習
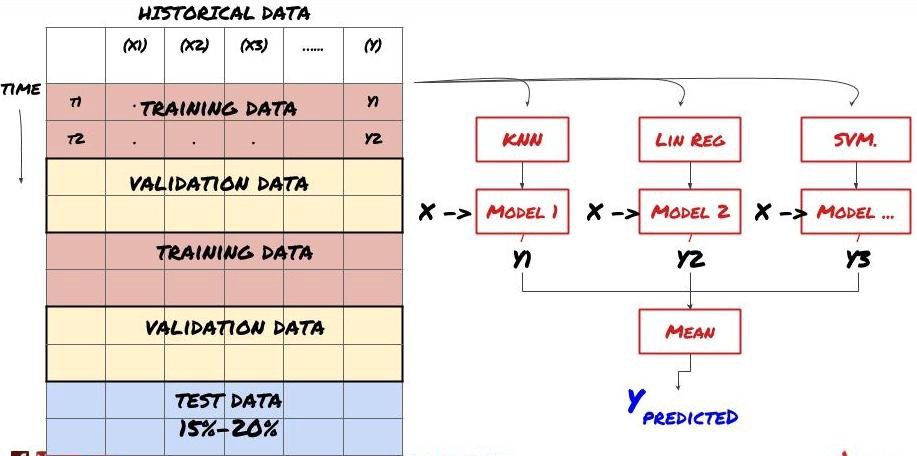
セット学習
あるモデルでは,特定のシナリオを予測するのに非常に効果的であり,他のシナリオを予測する際に,または特定の状況下でモデルが極端に過剰に適している可能性があります.エラーと過剰な適性を減らす方法の1つは,さまざまなモデルのセットを使用することです.あなたの予測は,多くのモデルの予測の平均であり,異なるモデルのエラーはオフセットまたは削減されることがあります.一般的なセット方法の中には,バッグとブースティングがあります.
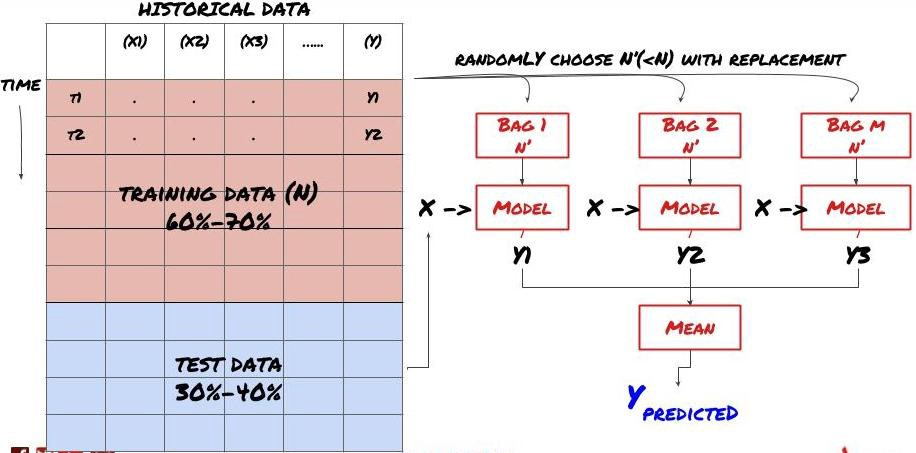
バッグ
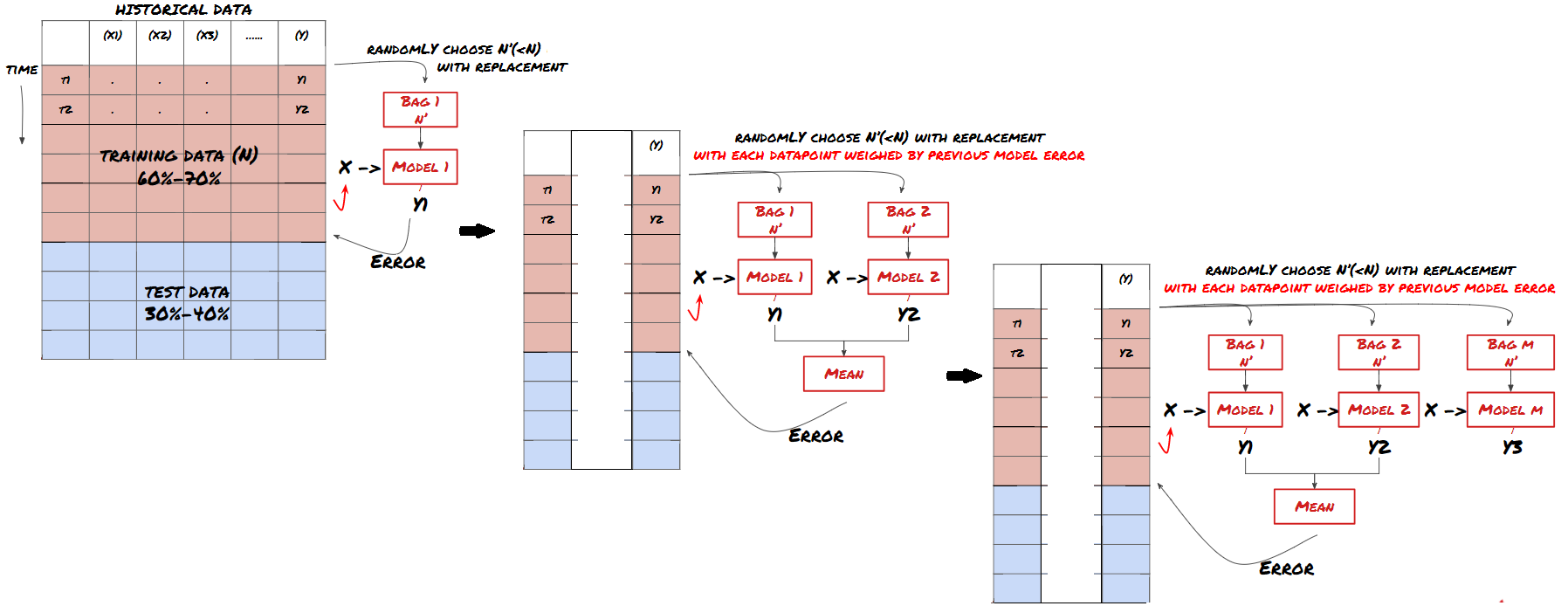
刺激する
簡潔さのために,これらの方法を省きますが,オンラインでより多くの情報を見つけることができます.
問題を解くためのセット方法を使ってみましょう.
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
今のところ,私たちは多くの知識と情報を蓄積しました.
-
問題を解決する
-
信頼性の高いデータを収集し,データを整理する.
-
訓練,検証,テストセットにデータを分割する.
-
特徴を作り,行動分析する.
-
行動に応じて適切な訓練モデルを選択する.
-
訓練データを使ってモデルを訓練し予測する
-
検証セットの性能をチェックし,再最適化する.
-
試験セットの最終性能を確認する.
信頼性の高い予測モデルしか持っていない. 戦略で本当に何を望んだか覚えてますか?
-
予測モデルに基づくシグナルを開発し,取引方向性を特定する.
-
オープン・閉鎖ポジションを特定するための具体的な戦略を策定する.
-
ポジションと価格を識別するシステムを実行する.
FMZ Quant プラットフォームを使用する (FMZ.COM) FMZ Quantプラットフォームには,高度にカプセル化され,完璧な API インターフェース,およびグローバルに呼び出すことができるオーダーおよび取引機能があります.あなたは異なる取引所の API インターフェースを一つずつ接続して追加する必要はありません. FMZ Quant プラットフォームの戦略スクエアには,この記事の機械学習方法に匹敵する多くの成熟した完璧な代替戦略があります.それはあなたの特定の戦略をより強力にします.戦略スクエアには,以下のように位置しています:https://www.fmz.com/square.
**トランザクションコストに関する重要な注意事項: **選択した資産がロングまたはショートになる時,あなたのモデルはあなたに知らせます.しかし,手数料/トランザクションコスト/利用可能な取引量/ストップ損失等を考慮していません.トランザクションコストは通常,収益性の高い取引を損失にします.例えば,予想価格上昇が0.05ドルである資産は購入です.しかし,この取引のために0.10ドルを払わなければならなければ,最終的には0.05ドルの純損失を得ます.ブローカーの佣金,為替手数料,ポイント差を考慮した後,上の大きな利益チャートは以下のように見えます.
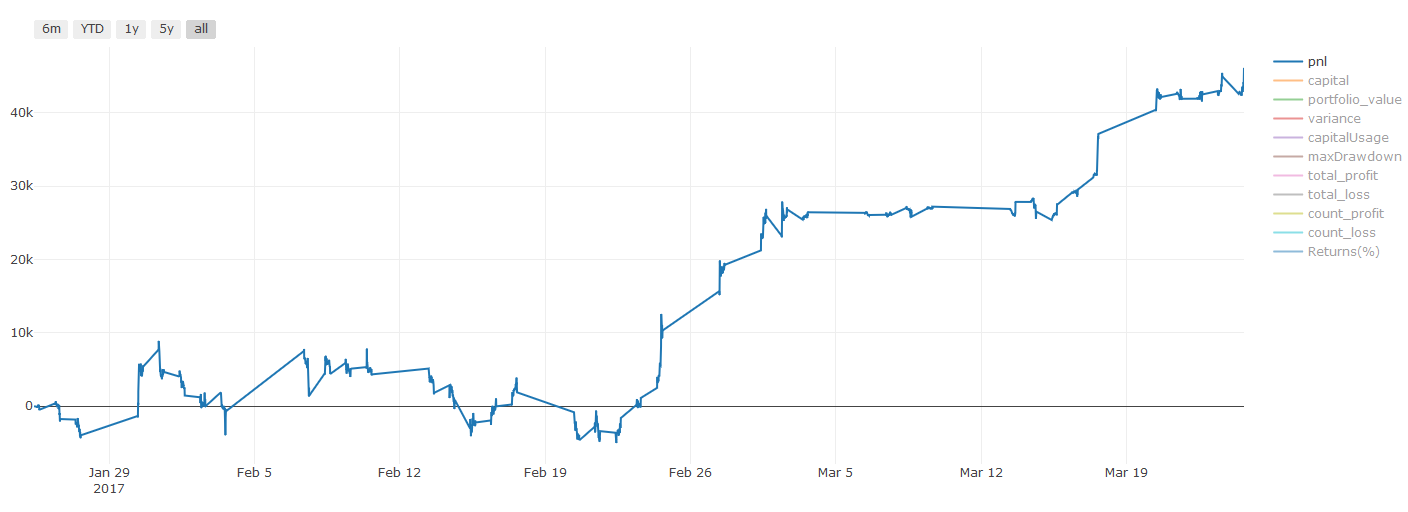
取引手数料とポイント差の後のバックテスト結果は Pnl で USD です.
取引手数料と価格差は,PNLの90%以上を占めています.
最後に,いくつかの一般的な罠を見てみましょう.
何をするべきか,何をするべきでないか
-
余計に身につかないで!
-
データポイントごとに再訓練しないでください:これは機械学習開発で人がする一般的な間違いです.モデルがデータポイントごとに再訓練する必要がある場合,それは非常に良いモデルではない可能性があります.つまり,定期的に再訓練する必要があります.そして,合理的な頻度でしか訓練する必要はありません (例えば,日中の予測を行う場合,毎週の終わりに再訓練する必要があります).
-
バイアス,特に前向きなバイアスを避ける: これはモデルが動作しないもう一つの理由であり,将来の情報を使用しないことを確認します.ほとんどの場合,これはターゲット変数Yがモデル内の機能として使用されないことを意味します.バックテスト中にそれを使用できますが,モデルを実行するときに実際に利用できなくなります. これによりモデルが使用不能になります.
-
データマイニングバイアスの注意:当社は,適切なかどうかを判断するためにデータに一連のモデリングを行おうとしているため,特別な理由がない場合は,発生する実際のモードからランダムモードを分離するために厳格なテストを実行することを確認してください.例えば,線形回帰は上昇傾向パターンをよく説明しますが,より大きなランダムさまよいことのほんの一部になる可能性があります!
オーバーフィッティングを避ける
これは非常に重要で,もう一度お話しする必要があると思います.
-
取引戦略の中で 最も危険な罠です
-
複雑なアルゴリズムはバックテストで非常にうまく機能するかもしれないが,新しい目に見えないデータでは惨めな失敗を起こす.このアルゴリズムはデータのトレンドを明らかにしたり,実際の予測能力をもたない.それは見るデータに非常に適している.
-
データを解釈するために複雑な機能が多く必要だと気づけば,過剰に適しているかもしれません.
-
利用可能なデータを訓練データとテストデータに分割し,リアルタイムトランザクションのモデルを使用する前に,実際のサンプルデータのパフォーマンスを常に検証します.
- 暗号通貨市場の基本分析を定量化する: データが自分で話せ!
- 通貨圏の基礎的な定量化研究 - 数字を客観的に話すために,あらゆる
教師を信頼しなくていい! - 量化取引の必須ツール - 発明者による量化データ探索モジュール
- すべてをマスターする - FMZの新バージョンの取引ターミナルへの紹介 (TRB仲裁ソースコード)
- FMZの新バージョンの取引端末のご紹介 (TRBの利息ソースコード追加)
- FMZ Quant: 仮想通貨市場における共通要件設計例の分析 (II)
- 80行のコードで高周波戦略で 脳のない販売ボットを利用する方法
- FMZ定量化:仮想通貨市場の常用需要設計事例解析 (II)
- 80行コードの高周波戦略で脳のないロボットを搾取して売る方法
- FMZ Quant: 仮想通貨市場における共通要件設計例の分析 (I)
- FMZ定量化:仮想通貨市場の常用需要設計事例解析 (1)