
1. 서론
이전 기사에서는 LSTM 네트워크를 사용하여 비트코인 가격을 예측하는 방법을 소개했습니다. https://www.fmz.com/digest-topic/4035. 기사에서 언급했듯이, RNN과 pytorch를 연습하고 익숙해지는 것은 작은 프로젝트일 뿐입니다. . 이 글에서는 강화 학습 방법을 사용하여 거래 전략을 직접적으로 훈련하는 방법을 소개합니다. 강화 학습 모델은 OpenAI가 오픈 소스로 공개한 PPO이며, 환경은 gym 스타일을 기반으로 합니다. 이해와 테스트를 용이하게 하기 위해 LSTM PPO 모델과 백테스팅 체육관 환경은 기성 패키지를 사용하지 않고 직접 작성되었습니다.
PPO는 Proximal Policy Optimization의 약자로, Policy Graident, 즉 정책 그래디언트의 최적화 개선안입니다. Gym도 OpenAI에서 출시했습니다. 정책 네트워크와 상호 작용하여 환경의 현재 상태와 보상을 피드백할 수 있습니다. LSTM PPO 모델을 사용하여 직접 매수, 매도 또는 아무 작업도 하지 않는 강화 학습 연습과 같습니다. 비트코인의 시장 정보. 지침은 백테스팅 환경에서 제공되며, 모델은 전략적 수익성의 목표를 달성하기 위해 지속적으로 훈련을 통해 최적화됩니다.
이 기사를 읽으려면 Python, PyTorch, DRL 심층 강화 학습에 대한 특정 기초가 필요합니다. 하지만 방법을 모르더라도 상관없습니다. 이 글에서 제공하는 코드를 배우고 시작하는 것은 쉽습니다. 이 기사는 디지털 통화 양적 거래 플랫폼(www.fmz.com)의 발명가인 FMZ가 제작했습니다. QQ 그룹에 가입해 주셔서 감사합니다: 863946592로 연락해 주세요.
2. 데이터 및 학습 참고 자료
비트코인 가격 데이터는 FMZ 발명가 양적 거래 플랫폼에서 제공됩니다: https://www.quantinfo.com/Tools/View/4.html
DRL+gym을 사용하여 거래 전략을 훈련하는 방법에 대한 기사: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
Pytorch를 시작하는 방법에 대한 몇 가지 예: https://github.com/yunjey/pytorch-tutorial
이 문서에서는 LSTM-PPO 모델의 간단한 구현을 직접 사용합니다: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
PPO 관련 기사: https://zhuanlan.zhihu.com/p/38185553
DRL에 대한 더 많은 기사: https://www.zhihu.com/people/flood-sung/posts
헬스장과 관련해서 이 문서에서는 헬스장을 설치할 필요는 없지만 강화 학습은 매우 흔합니다: https://gym.openai.com/
3.LSTM-PPO
PPO에 대한 심층적인 설명을 위해 이전 참고문헌을 공부할 수 있습니다. 여기서는 간단한 개념에 대한 소개만 있습니다. 이전 호에서 LSTM 네트워크는 가격만 예측했습니다. 이 예측 가격을 기반으로 매수 및 매도 거래를 하는 방법은 별도로 구현해야 합니다. 자연스럽게 매수 및 매도 동작을 직접 출력하는 것이 더 직접적일 것이라고 생각할 수 있습니다. , 오른쪽? Policy Graident는 이와 같습니다. 입력 환경 정보에 따라 다양한 행동의 확률을 제공할 수 있습니다. LSTM의 손실은 예측 가격과 실제 가격의 차이이고, PG의 손실은 -log(p)입니다.*Q, 여기서 p는 동작이 출력될 확률이고 Q는 동작의 값(예: 보상 점수)입니다. 직관적인 설명은 동작의 값이 더 높을 경우 네트워크가 더 높은 확률을 출력해야 한다는 것입니다. 손실을 줄이기 위해. PPO는 훨씬 더 복잡하지만 원리는 비슷합니다. 핵심은 각 액션의 가치를 더 잘 평가하는 방법과 매개변수를 더 잘 업데이트하는 방법에 있습니다.
LSTM-PPO의 소스 코드는 아래와 같습니다. 이전 정보와 결합하여 이해할 수 있습니다.
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. 비트코인 백테스팅 환경
헬스장 포맷에 따라 초기화 초기화 방법, 스텝 입력 액션이 있고, 반환되는 결과는 (다음 상태, 액션 혜택, 완료 여부, 추가 정보)입니다. 전체 백테스트 환경은 60줄에 불과하며, 본인이 수정했습니다. 복잡한 버전, 특정 코드:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. 주목할만한 몇 가지 세부 사항
초기 계좌에 코인이 있는 이유는 무엇인가요?
백테스팅 환경에서 수익률을 계산하는 공식은 다음과 같습니다. 현재 수익률 = 현재 계좌 가치 - 초기 계좌 현재 가치. 즉, 비트코인 가격이 하락하고 해당 전략에서 코인을 매도하면 총 계좌 가치가 감소하더라도 해당 전략은 실제로 보상을 받아야 합니다. 백테스팅 기간이 길면 초기 계좌에는 큰 영향을 미치지 않을 수 있지만, 처음에는 여전히 큰 영향을 미칠 것입니다. 상대적 수익률을 계산하면 모든 올바른 작업이 긍정적인 보상을 얻는 것이 보장됩니다.
훈련 중에 왜 시장을 샘플링하는가?
총 데이터 양은 10,000개 이상의 K-lines입니다. 매번 전체 사이클을 실행하면 시간이 오래 걸리고 전략은 매번 정확히 동일한 상황에 직면하게 되어 과적합이 발생할 수 있습니다. 백테스트 데이터로 매번 500개의 막대가 추출됩니다. 오버피팅이 여전히 가능하지만, 이 전략은 10,000개 이상의 가능한 시작에 직면합니다.
동전이나 돈이 없으면 어떻게 해야 하나요?
이 상황은 백테스트 환경에서 고려되지 않습니다. 코인이 매도되었거나 최소 거래량에 도달하지 못한 경우 이때 매도 작업을 실행하는 것은 실제로 작업을 실행하지 않는 것과 같습니다. 가격이 하락하면 상대적인 수익 계산 방법은 여전히 전략의 긍정적인 보상에 기반을 둡니다. 이러한 상황의 영향은 전략이 시장이 하락하고 계정에 남아 있는 코인을 매도할 수 없다고 판단할 때 매도 행동과 무행동을 구별하는 것은 불가능하지만 전략 자체의 판단에는 영향을 미치지 않는다는 것입니다. 시장.
왜 계정 정보를 상태로 반환하나요?
PPO 모델은 현재 상태의 가치를 평가하는 데 사용되는 가치 네트워크를 가지고 있습니다. 분명히, 전략이 가격이 상승할 것이라고 판단하면, 현재 계좌가 비트코인을 보유하고 있는 경우에만 전체 상태가 양의 가치를 갖게 되고, 그 반대의 경우도 마찬가지입니다. 따라서 계정 정보는 가치 네트워크를 판단하는 중요한 기준이 됩니다. 과거 작업 정보는 상태로 반환되지 않습니다. 개인적으로는 이것이 가치를 판단하는 데 쓸모없다고 생각합니다.
어떤 상황에서는 아무 작업도 수행하지 않게 됩니까?
전략에서 매수 및 매도에서 얻은 수익이 거래 수수료를 충당할 수 없다고 판단되면 더 이상 행동하지 않아야 합니다. 이전 설명에서 가격 추세를 결정하기 위해 전략을 반복적으로 사용했지만, 그것은 단지 이해의 편의를 위한 것이었습니다. 사실, 이 PPO 모델은 시장에 대한 예측을 하지 않고, 단지 세 가지 행동의 확률만을 출력합니다.
6. 데이터 수집 및 교육
이전 기사와 마찬가지로 데이터는 다음 형식으로 수집되었습니다. 2018/5/7부터 2019/6/27까지 Bitfinex 거래소의 BTC_USD 거래 쌍의 1시간 K-라인:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
LSTM 네트워크를 사용했기 때문에 학습 시간이 매우 길어서 GPU 버전으로 바꾸었는데, 약 3배 정도 더 빨랐습니다.
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. 훈련 결과 및 분석
오랜 기다림 끝에:

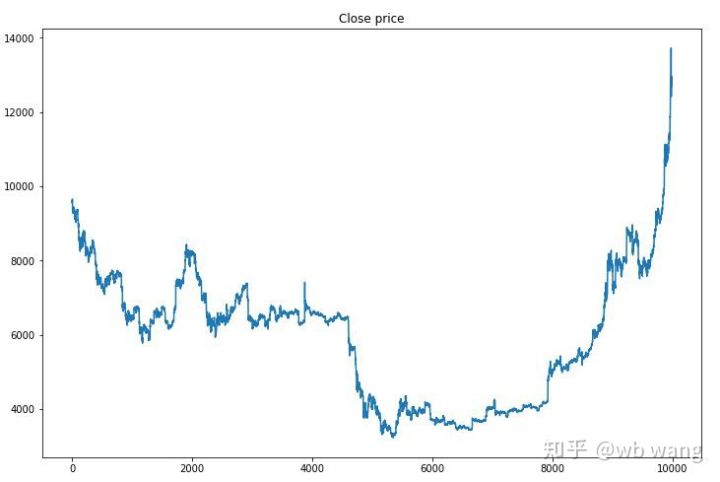
먼저, 훈련 데이터의 시장 동향을 살펴보겠습니다. 전반적으로 상반기는 긴 하락이었고, 하반기는 강력한 반등이었습니다.
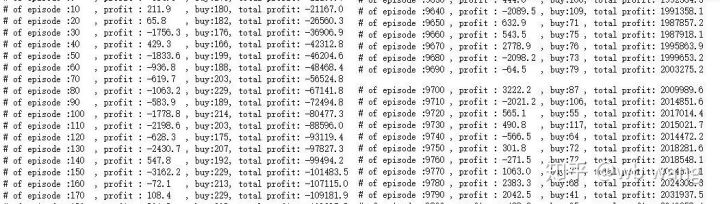
훈련 초기 단계에는 매수 작업이 많고, 수익을 내는 라운드는 사실상 없습니다. 훈련 기간 중반쯤 되자 매수 작업의 횟수는 점점 줄어들었고, 수익 가능성은 점점 더 커졌지만 손실 가능성은 여전히 높았습니다.
라운드별 수익을 평활화하면 결과는 다음과 같습니다.
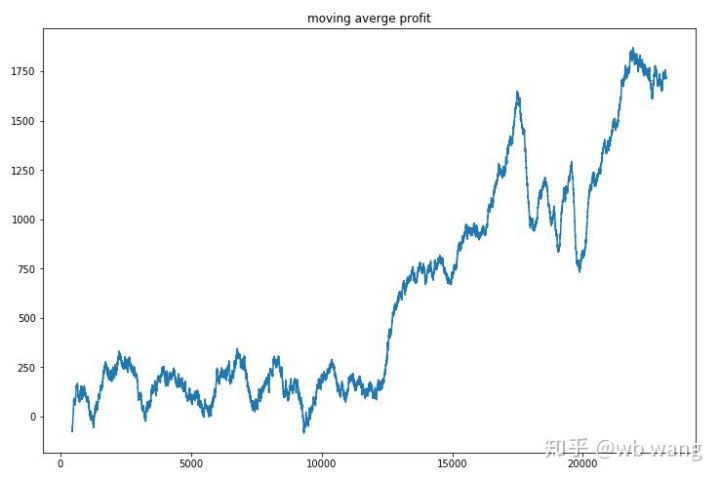
이 전략은 초기 단계에서 부정적인 수익률을 빠르게 제거했지만 변동이 컸습니다. 수익률이 빠르게 증가하기 시작한 것은 10,000라운드가 되어서였습니다. 전반적으로 모델 훈련은 어려웠습니다.
최종 훈련이 완료된 후, 모델이 모든 데이터를 다시 실행하여 어떻게 수행되는지 확인합니다. 이 기간 동안 계정의 총 시장 가치, 보유한 비트코인 수, 비트코인 가치의 비율, 총 수입을 기록합니다. .
첫 번째는 총 시장 가치입니다. 총 수익은 비슷하므로 여기에 게시하지 않겠습니다.
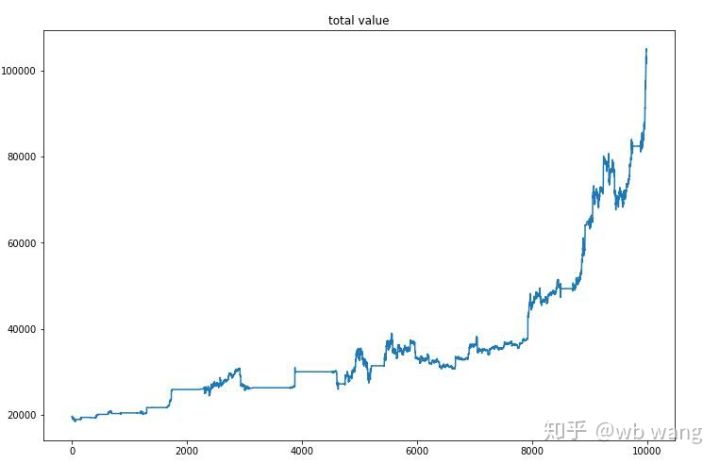
전체 시장 가치는 초기 하락장 동안 느리게 증가하였고, 이후 상승장 동안에도 상승세를 유지하였지만, 주기적인 손실은 여전히 있었습니다.
마지막으로 포지션의 비율을 살펴보겠습니다. 그래프의 왼쪽 축은 포지션의 비율이고 오른쪽 축은 시장 상황입니다. 모델이 과대적합되었다는 것을 예비적으로 판단할 수 있습니다. 포지션의 빈도는 초기 하락장에서는 낮은 수준이었고, 시장이 바닥을 쳤을 때는 포지션 빈도가 매우 높았습니다. 또한 이 모델은 오랫동안 포지션을 유지하는 법을 배우지 못했고 항상 빠르게 매도하는 모습을 볼 수 있습니다.
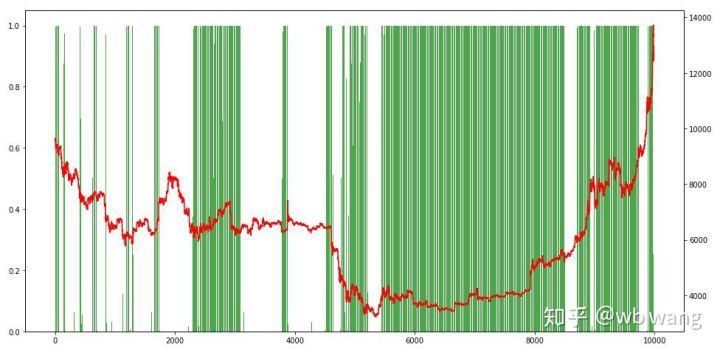
8. 테스트 데이터 분석
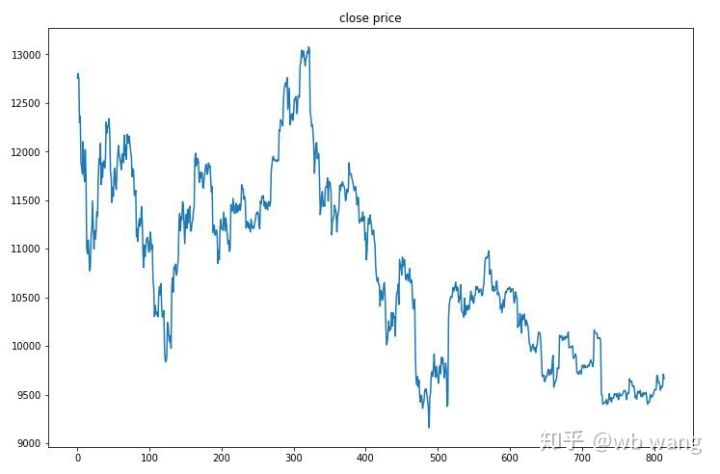
테스트 데이터는 2019년 6월 27일부터 현재까지의 1시간 비트코인 시장에서 얻었습니다. 그림에서 볼 수 있듯이, 시작 시 13,000달러였던 가격이 현재는 9,000달러 이상으로 떨어졌는데, 이는 모델에 대한 좋은 테스트가 될 수 있습니다.
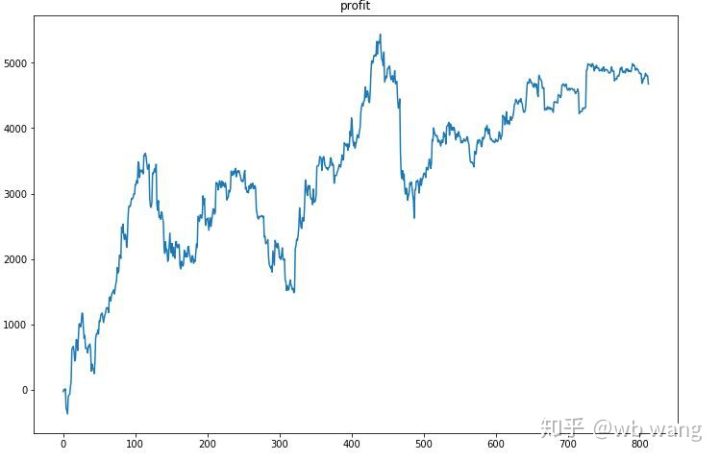
우선 최종 상대수익률은 만족스럽지 않았지만 손실도 없었습니다.
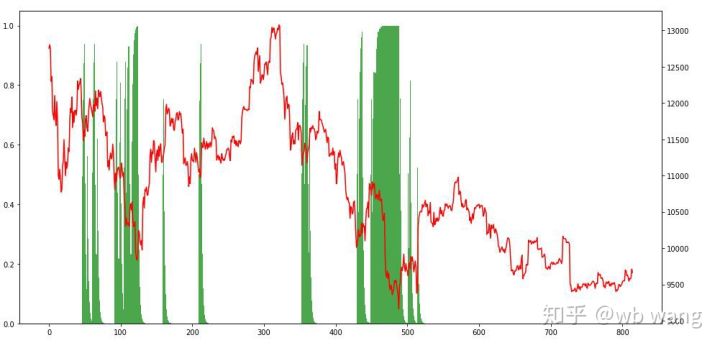
포지션을 살펴보면, 이 모델은 급락 후 매수하고 반등 후 매도하는 경향이 있다고 추측할 수 있습니다. 비트코인 시장은 최근 몇 년간 변동이 거의 없었고, 이 모델은 숏 포지션을 유지해 왔습니다.
9. 요약
본 논문에서는 심층 강화 학습 방식인 PPO를 사용하여 비트코인 자동 거래 로봇을 훈련시키고 몇 가지 결론을 얻었습니다. 제한된 시간으로 인해 모델에서 개선할 수 있는 부분이 아직 몇 가지 있습니다. 누구나 토론할 수 있습니다. 가장 큰 교훈은 데이터 표준화가 올바른 방법이라는 것입니다. 스케일링과 같은 방법을 사용하지 마십시오. 그렇지 않으면 모델이 가격과 시장 상황 간의 관계를 빠르게 기억하고 과적합에 빠지게 됩니다. 정규화 후 변화율은 상대적 데이터가 되므로 모델이 시장과의 관계를 기억하기 어렵고 변화율과 상승 및 하락 간의 연관성을 찾아야 합니다.
이전 기사:
FMZ Inventor Quantitative Platform에서 일부 공개 전략 공유: https://zhuanlan.zhihu.com/p/64961672
넷이즈 클라우드 클래스룸 디지털 화폐 양적 거래 과정, 단 20위안: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
저는 한때 매우 수익성이 높았던 고빈도 전략을 공개했습니다: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1