Perbandingan 8 algoritma pembelajaran mesin
 0
6946
0
6946
Perbandingan 8 algoritma pembelajaran mesin
Dalam artikel ini, kami akan mengkaji semula beberapa senario penyesuaian algoritma yang biasa digunakan dan kelebihan dan kekurangan mereka.
Terdapat banyak algoritma pembelajaran mesin, seperti pengurutan, regresi, pengelompokan, cadangan, pengiktirafan imej, dan sebagainya. Ia tidak mudah untuk mencari algoritma yang sesuai, jadi dalam aplikasi sebenar, kita biasanya menggunakan pembelajaran inspiratif untuk bereksperimen.
Biasanya kita akan mulakan dengan algoritma yang diterima umum, seperti SVM, GBDT, Adaboost, pembelajaran mendalam sangat popular sekarang, dan rangkaian saraf adalah pilihan yang baik.
Jika anda mengambil berat tentang ketepatan, kaedah terbaik adalah untuk menguji algoritma secara berturut-turut melalui cross-validation, membandingkannya, kemudian menyesuaikan parameter untuk memastikan setiap algoritma mencapai penyelesaian terbaik, dan akhirnya memilih yang terbaik.
Tetapi jika anda hanya mencari algoritma yang cukup baik untuk menyelesaikan masalah anda, atau ada beberapa petua untuk rujukan, mari kita menganalisis kelebihan dan kekurangan setiap algoritma, dan berdasarkan kelebihan dan kekurangan algoritma, lebih mudah bagi kita untuk memilihnya.
- ## Kecacatan & Perbezaan
Dalam statistik, sebuah model yang baik atau buruk, diukur berdasarkan bias dan perbezaan, jadi mari kita umumkan bias dan perbezaan:
Penyimpangan: menggambarkan perbezaan antara nilai ramalan (nilai anggaran) yang diharapkan E dan nilai sebenar Y. Semakin besar penyimpangan, semakin jauh dari data sebenar.
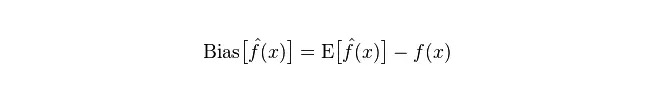
Divergensi: menggambarkan perubahan dalam jangkauan nilai ramalan P, tahap perpecahan, adalah divergensi nilai ramalan, iaitu jarak dari nilai yang diharapkan E. Semakin besar divergensi, semakin tersebarnya data.
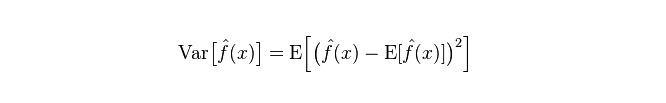
Kesalahan sebenar model adalah jumlah kedua-duanya, seperti yang ditunjukkan di bawah:
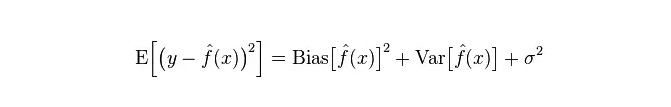
Jika ia adalah set latihan kecil, pengelasan yang tinggi deviasi / rendah perbezaan (contohnya, Bayesian NB yang polos) akan mempunyai kelebihan yang lebih besar daripada pengelasan yang rendah deviasi / tinggi perbezaan (contohnya, KNN), kerana yang terakhir akan terlalu sesuai.
Tetapi, apabila anda mempunyai set latihan yang lebih besar, semakin baik kemampuan model untuk meramalkan data asal, maka bias akan berkurangan, dan pada masa ini pengelasan bias rendah / tinggi akan menunjukkan keunggulan mereka (kerana mereka mempunyai kesalahan perbandingan yang lebih rendah), dan pengelasan bias tinggi tidak lagi cukup untuk menyediakan model yang tepat.
Sudah tentu, anda juga boleh menganggapnya sebagai perbezaan antara model penjanaan (NB) dan model penilaian (KNN).
- ## Kenapa Bayes yang polos adalah orang yang mempunyai bias tinggi dan rendah?
Di bawah ini adalah sebahagian daripada kenyataan:
Pertama, andaikan anda tahu hubungan antara set latihan dan set ujian. Secara ringkasnya, kita akan mempelajari model dalam set latihan, dan kemudian mendapatkan set ujian untuk digunakan.
Tetapi sering kali kita hanya boleh menganggap bahawa set ujian dan set latihan sesuai dengan sebaran data yang sama, tetapi tidak mendapat data ujian yang sebenar. Bagaimana untuk mengukur kadar kesilapan ujian dengan hanya melihat kadar kesilapan latihan?
Oleh kerana sampel latihan sangat sedikit (atau sekurang-kurangnya tidak cukup), model yang diperoleh melalui kumpulan latihan tidak selalu benar. Walaupun ia benar 100% pada kumpulan latihan, ia tidak menunjukkan bahawa ia mengukir sebaran data yang benar. Tujuan kita adalah untuk mengetahui bagaimana mengukir sebaran data yang benar, bukan hanya mengukir titik data terhad dalam kumpulan latihan.
Selain itu, dalam praktiknya, sampel latihan sering mempunyai kesilapan kebisingan, jadi jika terlalu berusaha untuk mencapai kesempurnaan dalam set latihan dan menggunakan model yang sangat rumit, ia akan menyebabkan model menganggap semua kesilapan dalam set latihan sebagai ciri-ciri pengedaran data yang benar, dan dengan itu mendapatkan anggaran pengedaran data yang salah.
Dalam kes ini, pada set ujian sebenar, ia akan menjadi salah (kejadian ini dipanggil pencocokan). Tetapi anda tidak boleh menggunakan model yang terlalu mudah, jika tidak, model tidak akan mencukupi untuk menggambarkan pengedaran data yang lebih rumit (termasuk dalam set latihan, kadar ralatnya sangat tinggi, fenomena ini kurang sesuai).
Overfitting menunjukkan model yang digunakan lebih rumit daripada sebaran data sebenar, dan underfitting menunjukkan model yang digunakan lebih mudah daripada sebaran data sebenar.
Dalam kerangka pembelajaran statistik, apabila kita menggambarkan kerumitan model, ada pendapat bahawa Error = Bias + Variance. Di sini, Error mungkin dapat difahami sebagai kadar kesilapan ramalan model, terdiri daripada dua bahagian, satu bahagian adalah perkiraan yang tidak tepat yang disebabkan oleh model yang terlalu mudah (Bias), dan bahagian lain adalah ruang perubahan dan ketidakpastian yang lebih besar yang disebabkan oleh model yang terlalu rumit (Variance).
Oleh itu, ia mudah untuk menganalisis Bayes yang sederhana. Ia hanya mengandaikan bahawa setiap data tidak berkaitan, dan ia adalah model yang sangat disederhanakan. Oleh itu, untuk model mudah seperti itu, bias akan lebih besar daripada varian dalam kebanyakan kes, iaitu bias yang tinggi dan varian yang rendah.
Dalam praktiknya, untuk mengurangkan kesilapan, kita perlu mengimbangi kadar bias dan varian dalam pemilihan model, iaitu mengimbangi over-fitting dan under-fitting.
Hubungan antara varian dan perbezaan kuasa dua dengan kerumitan model dapat dilihat dengan lebih jelas dalam rajah berikut:
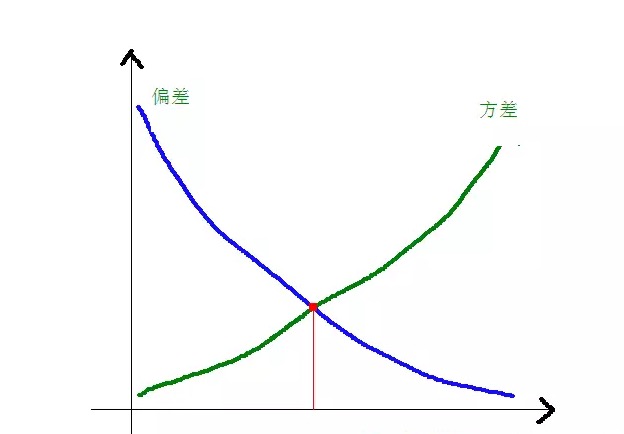
Apabila model semakin kompleks, bias akan menjadi lebih kecil, dan perbezaan akan menjadi lebih besar.
-
Kelemahan dan kelemahan algoritma biasa
- ### Bayes 1.
Bayesian sederhana adalah model generatif (terutamanya mengenai model generatif dan model penentuan, sama ada ia memerlukan sebaran bersama), sangat mudah, anda hanya melakukan banyak pengiraan.
Sekiranya anda membuat andaian kebebasan bersyarat ((satu syarat yang lebih ketat), klasifier Bayes yang sederhana akan bertepatan lebih cepat daripada model penilaian seperti logik regresi, jadi anda hanya memerlukan sedikit data latihan. Walaupun andaian kebebasan bersyarat NB tidak berlaku, klasifier NB masih berfungsi dengan baik dalam praktiknya.
Kelemahan utamanya ialah ia tidak dapat mempelajari interaksi antara ciri-ciri, dan R dalam mRMR adalah kelebihan ciri-ciri. Untuk memberi contoh yang lebih klasik, misalnya, walaupun anda menyukai filem Brad Pitt dan Tom Cruise, ia tidak dapat mempelajari filem yang anda tidak suka bersama mereka.
Kelebihan:
Model Bayes yang sederhana berasal dari teori matematik klasik, mempunyai asas matematik yang kukuh, dan kecekapan klasifikasi yang stabil. Ia mempunyai prestasi yang baik untuk skala kecil data, boleh menangani pelbagai tugas, dan sesuai untuk latihan tambahan; Algoritma yang kurang sensitif terhadap data yang hilang adalah lebih mudah dan sering digunakan untuk mengelaskan teks. Kelemahan:
Ia memerlukan pengiraan kebarangkalian awal. Kesilapan dalam membuat keputusan klasifikasi; Ia sensitif kepada bentuk data input.
- ### 2. Kembali logik
Terdapat banyak kaedah untuk memodelkan model yang bersifat diskriminatif (L0, L1, L2, dan lain-lain) dan anda tidak perlu bimbang tentang apakah ciri anda relevan seperti yang anda lakukan dengan Bayes yang sederhana.
Anda juga akan mendapat interpretasi kebarangkalian yang baik berbanding dengan pokok keputusan dan mesin SVM, dan anda juga boleh menggunakan data baru untuk mengemas kini model dengan mudah (menggunakan algoritma penurunan gradien dalam talian, gradien descent dalam talian).
Jika anda memerlukan struktur kebarangkalian (contohnya, hanya untuk menyesuaikan had klasifikasi, menunjukkan ketidakpastian, atau untuk mendapatkan ruang keyakinan), atau anda ingin mengintegrasikan lebih banyak data latihan ke dalam model dengan cepat, gunakanlah.
Fungsi Sigmoid:
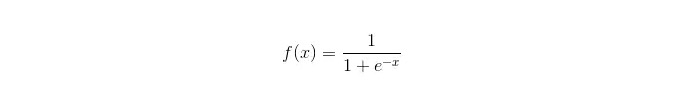
Kelebihan: Ia mudah dan boleh digunakan secara meluas untuk masalah industri; Perangkaan yang sangat kecil, kelajuan yang cepat, dan sumber penyimpanan yang rendah; Skor kebarangkalian sampel untuk kemudahan pengamatan; Bagi regresi logik, komuniti berganda bukanlah masalah, dan ia boleh diselesaikan dengan penyesuaian L2; Kelemahan: Logik regresi tidak berfungsi dengan baik apabila ruang ciri yang besar; Kemungkinan kurang sesuai, biasanya kurang tepat Tidak dapat menangani pelbagai jenis ciri atau pembolehubah dengan baik; hanya boleh menangani dua soalan klasifikasi (softmax yang dihasilkan dari asas ini boleh digunakan untuk pelbagai klasifikasi) dan mesti linear; Untuk ciri-ciri bukan linear, ia memerlukan penukaran.
- ### 3. Regresen Linear
Regresi linear digunakan untuk regresi, tidak seperti Regresi Logistik yang digunakan untuk klasifikasi, dan idea asasnya adalah untuk mengoptimumkan fungsi kesalahan dalam bentuk penggandaan binomial terkecil dengan menggunakan pengurangan gradien, dan tentu saja untuk mendapatkan penyelesaian parameter secara langsung dengan persamaan normal, yang menghasilkan:
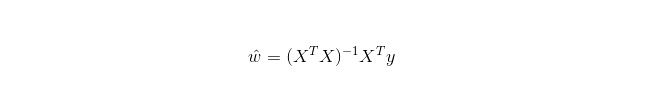
Dalam LWLR (Local Weighted Linear Regression), ungkapan pengiraan parameter adalah:
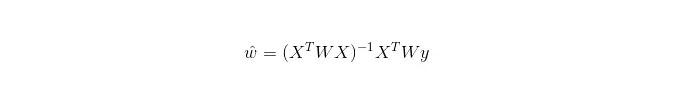
Dari sini dapat dilihat bahawa LWLR berbeza dengan LR, LWLR adalah model tanpa parameter, kerana setiap pengiraan regresi perlu melalui sampel latihan sekurang-kurangnya sekali.
Kelebihan: Mudah dilaksanakan, mudah dikira;
Kelemahan: Tidak sesuai dengan data bukan linear.
- ### 4. Algoritma berdekatan terdekat
KNN ialah algoritma berjiran terdekat, yang proses utamanya adalah:
Mengira jarak setiap titik sampel dalam sampel latihan dan sampel ujian (metrik jarak yang biasa digunakan ialah jarak dalam bentuk euro, jarak dalam bentuk marz, dan sebagainya);
Sort semua nilai jarak di atas;
K sampel jarak minimum dipilih;
Di bawah label k sampel ini, undi akan dibuat untuk mendapatkan kategori pengelompokan terakhir;
Cara memilih nilai K yang optimum bergantung kepada data. Secara amnya, nilai K yang lebih besar dapat mengurangkan kesan bunyi apabila diklasifikasikan. Tetapi ia dapat mengaburkan sempadan antara kategori.
Nilai K yang lebih baik boleh diperoleh melalui pelbagai teknik ilusi, seperti, cross-validation. Selain itu, kehadiran bunyi bising dan vektor ciri yang tidak berkaitan akan mengurangkan ketepatan algoritma berdekatan K.
Algoritma berdekatan mempunyai hasil konsistensi yang kuat. Dengan data yang tidak terhingga, algoritma menjamin bahawa kadar ralatnya tidak akan melebihi dua kali ganda daripada ralat algoritma Bayesian. Untuk beberapa nilai K yang baik, K berdekatan menjamin bahawa ralatnya tidak akan melebihi ralat teori Bayesian.
Kelebihan algoritma KNN
Teori yang matang, pemikiran yang mudah, boleh digunakan untuk membuat klasifikasi dan boleh digunakan untuk melakukan pengunduran; Ia boleh digunakan untuk klasifikasi bukan linear; Kompleksiti masa latihan adalah O (n); Tidak ada hipotesis mengenai data, sangat tepat dan tidak sensitif terhadap outlier; kekurangan
Pengiraan yang besar; Masalah ketidakseimbangan sampel ((iaitu, terdapat banyak sampel dalam beberapa kategori dan sedikit sampel dalam kategori lain); Ia memerlukan banyak memori.
- ### 5. Pokok keputusan
Ia boleh menangani interaksi antara ciri-ciri tanpa tekanan dan tidak parameter, jadi anda tidak perlu bimbang tentang nilai luar biasa atau data yang linear (contohnya, pokok keputusan dapat dengan mudah menangani kategori A di hujung dimensi ciri x, kategori B di tengah, dan kemudian kategori A muncul di hujung dimensi ciri x).
Salah satu kelemahan adalah bahawa ia tidak menyokong pembelajaran dalam talian, jadi pokok keputusan perlu dibina semula apabila sampel baru tiba.
Kelemahan lain ialah mudahnya overfit, tetapi ini adalah titik masuk untuk kaedah integrasi seperti RF hutan rawak (atau meningkatkan pokok yang dibangkitkan).
Selain itu, hutan rawak sering menjadi pemenang dalam banyak masalah klasifikasi (biasanya sedikit lebih baik daripada mesin penyokong vektor), ia dilatih dengan cepat dan boleh disesuaikan, dan anda tidak perlu bimbang untuk mengubah banyak parameter seperti mesin penyokong vektor, jadi ia selalu popular di masa lalu.
Satu perkara yang penting dalam pokok keputusan ialah memilih satu sifat untuk bercabang, jadi perhatikan formula pengiraan peningkatan maklumat dan pahami ia.
Formula pengiraan untuk bilik maklumat adalah seperti berikut:
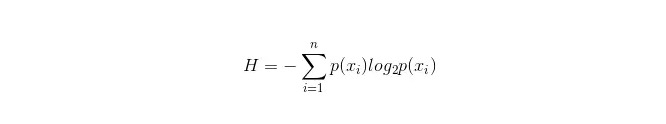
Di mana n mewakili mempunyai n kategori klasifikasi ((misalnya, jika ia adalah soalan kelas 2, maka n = 2) . Mengira kebarangkalian p1 dan p2 untuk kedua-dua jenis sampel ini dalam sampel keseluruhan, sehingga anda dapat mengira jumlah maklumat sebelum cabang sifat yang tidak dipilih .
Sekarang pilih satu sifat xixi yang digunakan untuk melakukan percabangan, pada masa ini peraturan percabangan adalah: jika xi = vxi = v, membahagikan sampel ke satu cabang pokok; jika tidak sama, masuk ke cabang lain.
Jelas sekali, sampel dalam cabang kemungkinan besar terdiri daripada 2 kategori, masing-masing mengira nilai H1 dan H2 dari kedua-dua cabang, mengira nilai maklumat keseluruhan selepas cabang H = p1 H1 + p2 H2, maka keuntungan maklumat pada masa ini ΔH = H - H. Dengan keuntungan maklumat sebagai prinsip, menguji semua sifat, pilih salah satu sifat yang mendapat keuntungan terbesar sebagai sifat cabang kali ini.
Kelebihan pokok keputusan sendiri
Pengiraan mudah, mudah difahami, dan mudah difahami; Sampel yang lebih sesuai untuk rawatan dengan sifat yang hilang; Ia juga boleh digunakan untuk mengesan ciri-ciri yang tidak berkaitan. Hasil yang boleh dilaksanakan dan berkesan dari sumber data besar dalam masa yang agak singkat. kekurangan
Terlalu mudah beradaptasi (hutan rawak boleh mengurangkan terlalu banyak adaptasi); Tidak ada hubungan antara data; Bagi data yang mempunyai jumlah sampel yang tidak konsisten dalam pelbagai kategori, hasil peningkatan maklumat di dalam pokok keputusan memihak kepada ciri-ciri yang mempunyai nilai yang lebih banyak ((sehingga peningkatan maklumat digunakan, terdapat kelemahan ini, seperti RF)).
- ### 5.1 Adaboosting
Adaboost adalah model penjumlahan, setiap model dibina berdasarkan kadar kesilapan model sebelumnya, memberi perhatian berlebihan kepada sampel yang salah, dan kurang perhatian kepada sampel yang diklasifikasikan dengan betul, dan setelah berulang kali, model yang lebih baik dapat diperoleh.
kelebihan
Adaboost adalah pengelompokan yang sangat tepat. Pelbagai kaedah boleh digunakan untuk membina sub-klasifikator. Adaboost menyediakan kerangka kerja. Hasil yang dikira dapat difahami apabila menggunakan klasifikasi mudah, dan klasifikasi lemah sangat mudah dibina. Mudah, tidak perlu menyaring ciri. Tidak mudah berlaku overfitting. Mengenai algoritma gabungan seperti hutan rawak dan GBDT, lihat artikel ini: Pembelajaran mesin - Ringkasan algoritma gabungan
Kelemahan: Sensitif terhadap outlier
- ### 6. SVM menyokong mesin vektor
Ketepatan yang tinggi, memberikan jaminan teori yang baik untuk mengelakkan overfit, dan walaupun data tidak dapat dibahagikan secara linear dalam ruang ciri asal, ia akan berfungsi dengan baik dengan hanya memberi fungsi teras yang sesuai.
Ia sangat popular dalam masalah pengelompokan teks berdimensi tinggi. Ia memerlukan banyak memori, sukar untuk menterjemahkan, dan ia agak mengganggu untuk beroperasi dan memaparkan, tetapi hutan rawak mengelakkan kekurangan ini dan lebih praktikal.
kelebihan Ia boleh menyelesaikan masalah dimensi tinggi, iaitu ruang ciri yang besar. Mampu menangani interaksi ciri-ciri bukan linear; Tidak perlu bergantung pada keseluruhan data; Ia boleh meningkatkan keupayaan generalisasi.
kekurangan Ia juga boleh menyebabkan masalah dalam kes-kes yang berkaitan dengan penglihatan, dan ia juga boleh menyebabkan masalah dalam penglihatan. Tidak ada penyelesaian umum untuk masalah bukan linear, dan kadang-kadang sukar untuk mencari fungsi teras yang sesuai; Sensitiviti terhadap data yang hilang; Terdapat juga keahlian untuk memilih kernel (libsvm mempunyai empat fungsi kernel: kernel linear, kernel polynomial, kernel RBF, dan kernel sigmoid):
Pertama, jika jumlah sampel kurang daripada jumlah ciri, maka tidak perlu memilih teras bukan linear, dan hanya menggunakan teras linear;
Kedua, jika jumlah sampel lebih besar daripada jumlah ciri, teras bukan linear boleh digunakan untuk memetakan sampel ke dimensi yang lebih tinggi, yang biasanya memberikan hasil yang lebih baik;
Ketiga, jika jumlah sampel dan jumlah ciri sama, teras bukan linear boleh digunakan, prinsipnya sama seperti yang kedua.
Dalam kes pertama, data boleh dikurangkan terlebih dahulu, dan kemudian menggunakan teras bukan linear, yang juga merupakan kaedah.
- ### 7. Kelebihan dan Kelemahan Rangkaian Neural AI
Kelebihan rangkaian saraf buatan: Kelas ini mempunyai ketepatan yang tinggi. Perisian ini mempunyai banyak kelebihan seperti pemprosesan berparallel, penyimpanan berparallel, dan pembelajaran. Ia mempunyai kebolehan yang kuat terhadap saraf bising dan toleransi terhadap kesilapan, yang dapat mendekati hubungan bukan linear yang kompleks; Ia mempunyai fungsi memori memori.
Kelemahan rangkaian saraf buatan: Rangkaian saraf memerlukan banyak parameter, seperti struktur topologi rangkaian, nilai awal dan nilai terhad; Proses pembelajaran yang tidak dapat diperhatikan antara satu sama lain, dan hasil keluaran yang sukar untuk ditafsirkan, yang akan mempengaruhi kebolehpercayaan dan penerimaan hasil; Masa belajar terlalu lama dan mungkin tidak mencapainya.
- ### 8 K-Maksud Kelompok
Sebelum ini, saya telah menulis mengenai K-Means Cluster, sebuah algoritma pembelajaran mesin yang mempunyai pemikiran EM yang kuat.
kelebihan Algoritma mudah dan mudah dilaksanakan; Untuk menangani set data besar, algoritma ini agak berskala dan cekap kerana kerumitannya adalah kira-kira O{\displaystyle O} nkt, di mana n adalah bilangan semua objek, k adalah bilangan kerucut, dan t adalah bilangan kali iterasi. Biasanya k<
kekurangan Keperluan yang lebih tinggi untuk jenis data, sesuai untuk data berangka; Mungkin bertepatan dengan nilai minimum tempatan, bertepatan lebih lambat pada data besar Nilai K lebih sukar untuk dipilih; Sensitif kepada nilai fokus awal, mungkin menyebabkan hasil pengelompokan yang berbeza untuk nilai awal yang berbeza; Tidak sesuai untuk mencari kerang yang tidak berbentuk kerang, atau kerang yang sangat berbeza saiznya. Untuk data sensitiviti pada bunyi bunyi dan titik-titik terpencil, jumlah kecil data ini boleh memberi kesan yang besar kepada nilai purata.
Algoritma pilihan rujukan
Dalam satu artikel yang telah diterjemahkan beberapa kali sebelum ini, terdapat satu teknik mudah untuk memilih algoritma:
Yang pertama yang harus dipilih ialah logik regresi, jika kesannya tidak begitu baik, maka hasilnya boleh digunakan sebagai rujukan, dibandingkan dengan algoritma lain berdasarkan;
Kemudian cubalah pokok keputusan (hutan rawak) untuk melihat apakah ia dapat meningkatkan prestasi model anda secara besar-besaran. Walaupun anda tidak menganggapnya sebagai model akhir, anda boleh menggunakan hutan rawak untuk membuang pembolehubah kebisingan dan membuat pilihan ciri.
Jika jumlah ciri dan sampel pemerhatian sangat banyak, maka penggunaan SVM adalah pilihan apabila sumber dan masa mencukupi (ini adalah asas yang penting).
Biasanya: GBDT>=SVM>=RF>=Adaboost>=Other…, sekarang pembelajaran mendalam sangat popular, banyak bidang yang digunakan, ia adalah berdasarkan rangkaian saraf, saya sendiri sedang belajar, hanya pengetahuan teori tidak cukup tebal, pemahaman tidak cukup mendalam, tidak akan diperkenalkan di sini.
Algoritma memang penting, tetapi data yang baik lebih baik daripada algoritma yang baik, dan ciri-ciri reka bentuk yang baik sangat berguna. Jika anda mempunyai set data yang sangat besar, maka algoritma yang anda gunakan mungkin tidak banyak mempengaruhi prestasi pengelompokan (pada masa ini anda boleh membuat pilihan berdasarkan kelajuan dan kemudahan penggunaan).
-
Rujukan