
1. Introdução
O artigo anterior introduziu o uso da rede LSTM para prever preços de Bitcoin https://www.fmz.com/digest-topic/4035. Conforme mencionado no artigo, é apenas um pequeno projeto para praticar e se familiarizar com RNN e pytorch . Este artigo apresentará o uso de métodos de aprendizagem por reforço para treinar diretamente estratégias de negociação. O modelo de aprendizagem por reforço é o PPO de código aberto da OpenAI, e o ambiente é baseado no estilo de academia. Para facilitar a compreensão e os testes, o modelo LSTM PPO e o ambiente de backtesting gym são escritos diretamente, sem usar pacotes prontos.
PPO, nome completo de Proximal Policy Optimization, é uma melhoria de otimização do Policy Gradient, ou seja, gradiente de política. O Gym também é lançado pela OpenAI. Ele pode interagir com a rede de políticas e fornecer feedback sobre o estado atual e a recompensa do ambiente. É como o exercício de aprendizado por reforço que usa o modelo LSTM PPO para fazer diretamente a compra, venda ou nenhuma operação com base no informações de mercado do Bitcoin. As instruções são dadas pelo ambiente de backtesting, e o modelo é continuamente otimizado por meio de treinamento para atingir a meta de lucratividade da estratégia.
Ler este artigo requer certa base em Python, PyTorch e aprendizado por reforço profundo DRL. Mas não importa se você não sabe como fazer. É fácil aprender e começar com o código dado neste artigo. Este artigo é produzido pela FMZ, a inventora da plataforma de negociação quantitativa de moeda digital (www.fmz.com). Bem-vindo ao grupo QQ: 863946592 para comunicação.
2. Dados e referências de aprendizagem
Os dados de preço do Bitcoin vêm da plataforma de negociação quantitativa FMZ Inventor: https://www.quantinfo.com/Tools/View/4.html
Um artigo sobre o uso de DRL+gym para treinar estratégias de negociação: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
Alguns exemplos de como começar a usar o pytorch: https://github.com/yunjey/pytorch-tutorial
Este artigo usará diretamente esta curta implementação do modelo LSTM-PPO: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
Artigos sobre PPO: https://zhuanlan.zhihu.com/p/38185553
Mais artigos sobre DRL: https://www.zhihu.com/people/flood-sung/posts
Sobre academia, este artigo não precisa de instalação, mas o aprendizado por reforço é muito comum: https://gym.openai.com/
3.LSTM-PPO
Para uma explicação aprofundada de PPO, você pode estudar as referências anteriores. Aqui está apenas uma introdução ao conceito simples. Na edição anterior, a rede LSTM apenas previu um preço. Como comprar e vender transações com base neste preço previsto precisa ser implementado separadamente. Naturalmente, pode-se imaginar que seria mais direto produzir diretamente as ações de compra e venda , certo? Policy Gradient é assim. Ele pode dar a probabilidade de várias ações com base nas informações ambientais de entrada. A perda de LSTM é a diferença entre o preço previsto e o preço real, enquanto a perda de PG é -log(p)*Q, onde p é a probabilidade de uma ação ser produzida, e Q é o valor da ação (como uma pontuação de recompensa). A explicação intuitiva é que se o valor de uma ação for maior, a rede deve produzir uma probabilidade maior para reduzir a perda. Embora o PPO seja muito mais complicado, o princípio é similar. A chave está em como avaliar melhor o valor de cada ação e como atualizar melhor os parâmetros.
O código fonte do LSTM-PPO é fornecido abaixo, o qual pode ser entendido em combinação com as informações anteriores:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Ambiente de backtesting do Bitcoin
Seguindo o formato do gym, há um método de inicialização de reset, ação de entrada de etapa e o resultado retornado é (próximo estado, benefício da ação, se está concluído, informações adicionais). Todo o ambiente de backtest tem apenas 60 linhas, o que pode ser modificado por você mesmo. Versão complexa, código específico:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Vários detalhes dignos de nota
Por que a conta inicial tem moedas?
A fórmula para calcular retornos no ambiente de backtesting é: Retorno Atual = Valor da Conta Atual - Valor Atual da Conta Inicial. Isso significa que se o preço do Bitcoin cair e a estratégia vender as moedas, a estratégia deverá ser recompensada mesmo que o valor total da conta diminua. Se o período de backtesting for longo, a conta inicial pode não ser muito afetada, mas ainda terá um grande impacto no início. O cálculo de retornos relativos garante que cada operação correta obtenha uma recompensa positiva.
Por que fazemos amostragem do mercado durante o treinamento?
A quantidade total de dados é mais de 10.000 K-lines. Se um ciclo completo for executado toda vez, levará muito tempo, e a estratégia enfrentará exatamente a mesma situação toda vez, o que pode levar ao overfitting. 500 barras são desenhadas a cada vez como dados de backtest. Embora o overfitting ainda seja possível, a estratégia enfrenta mais de 10.000 inícios possíveis diferentes.
O que fazer se você não tiver moedas ou dinheiro?
Esta situação não é considerada no ambiente de backtest. Se a moeda foi vendida ou o volume mínimo de transação não foi atingido, executar a operação de venda neste momento é, na verdade, equivalente a não executar nenhuma operação. Se o preço cair, de acordo com o relativo método de cálculo de retorno, ele ainda é baseado na recompensa positiva da estratégia. O impacto dessa situação é que quando a estratégia determina que o mercado está caindo e as moedas restantes na conta não podem ser vendidas, é impossível distinguir entre ações de venda e nenhuma operação, mas não tem impacto no julgamento da própria estratégia. o mercado.
Por que retornar informações da conta como status?
O modelo PPO tem uma rede de valor usada para avaliar o valor do estado atual. Obviamente, se a estratégia determinar que o preço vai subir, todo o estado só terá valor positivo se a conta corrente tiver Bitcoin, e vice-versa. Portanto, as informações da conta são uma base importante para julgar a rede de valor. Observe que as informações de ações passadas não são retornadas como estado, o que eu pessoalmente acho inútil para julgar valor.
Em que circunstâncias ele não retornará nenhuma operação?
Quando a estratégia determina que o lucro da compra e venda não pode cobrir a taxa de transação, ela deve retornar para nenhuma ação. Embora a descrição anterior tenha usado estratégias repetidamente para determinar tendências de preço, foi apenas para facilitar o entendimento. Na verdade, esse modelo PPO não faz nenhuma previsão sobre o mercado, mas apenas produz as probabilidades de três ações.
6. Aquisição de dados e treinamento
Assim como no artigo anterior, os dados são obtidos no seguinte formato: a linha K de uma hora do par de negociação BTC_USD na bolsa Bitfinex de 07/05/2018 a 27/06/2019:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Como a rede LSTM foi usada, o tempo de treinamento foi muito longo, então mudei para uma versão de GPU, que era cerca de 3 vezes mais rápida.
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
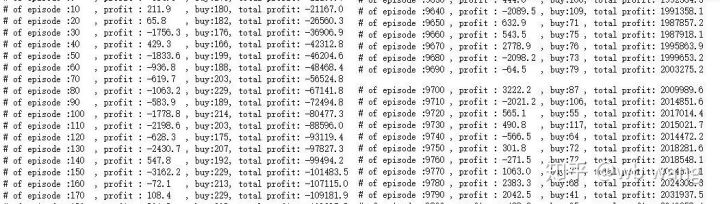
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Resultados e análise do treinamento
Depois de uma longa espera:

Primeiro, vamos dar uma olhada nas tendências de mercado dos dados de treinamento. Em termos gerais, a primeira metade foi um longo declínio, e a segunda metade foi uma forte recuperação.
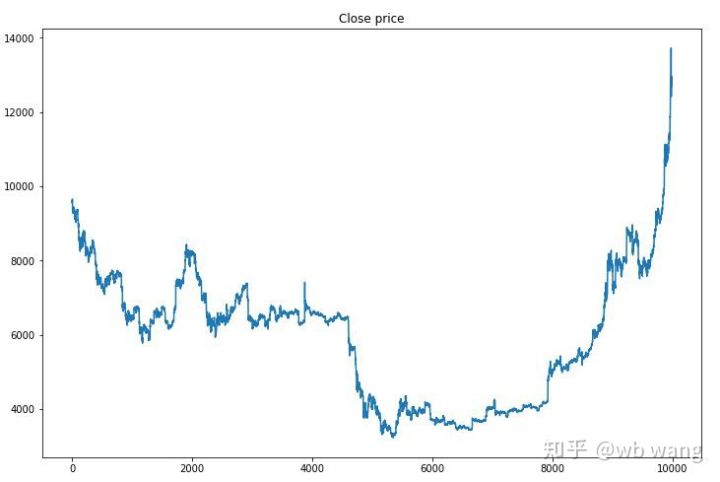
Há muitas operações de compra nos estágios iniciais do treinamento e basicamente não há rodadas lucrativas. No meio do período de treinamento, o número de operações de compra diminuiu gradualmente e a probabilidade de lucro tornou-se cada vez maior, mas ainda havia uma alta probabilidade de perda.
Suavizando a receita por rodada, os resultados são os seguintes:
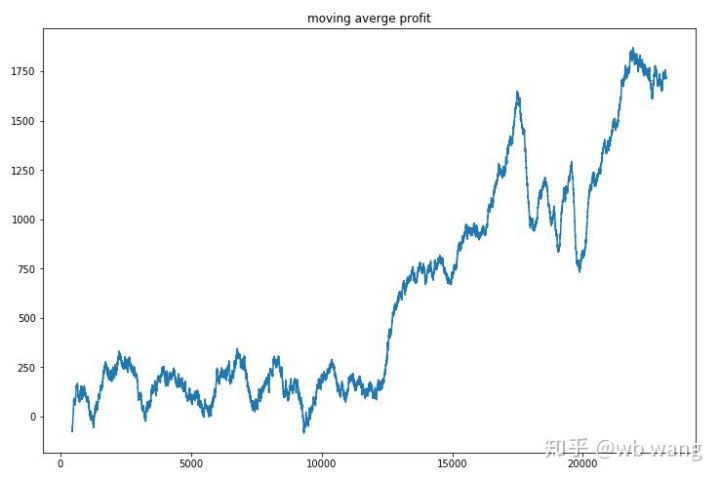
A estratégia rapidamente se livrou dos retornos negativos nos estágios iniciais, mas as flutuações eram grandes. Não foi até 10.000 rodadas que os retornos começaram a crescer rapidamente. Em geral, o treinamento do modelo foi difícil.
Após o treinamento final ser concluído, deixe o modelo executar todos os dados novamente para ver como ele se sai. Durante esse período, registre o valor total de mercado da conta, o número de bitcoins mantidos, a proporção do valor do bitcoin e a renda total .
Primeiro é o valor total de mercado. A receita total é similar, então não vou postá-la aqui:
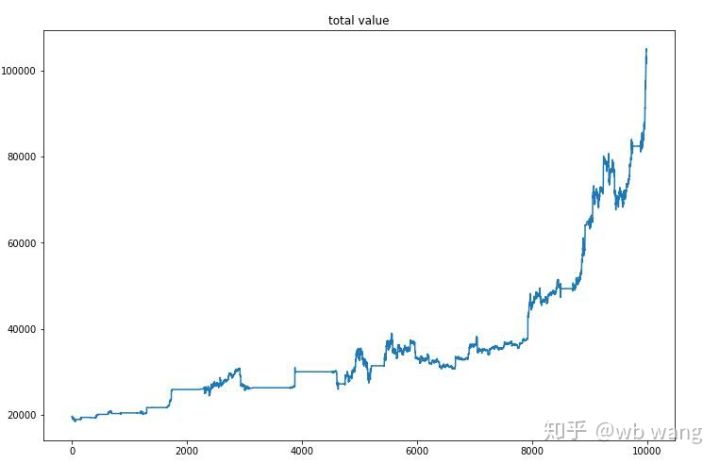
O valor total de mercado aumentou lentamente durante o início do mercado de baixa e também acompanhou o aumento durante o mercado de alta posterior, mas ainda houve perdas periódicas.
Por fim, vamos dar uma olhada na proporção de posições. O eixo esquerdo do gráfico é a proporção de posições, e o eixo direito é a situação do mercado. Pode ser preliminarmente determinado que o modelo foi superajustado. A frequência de posições foi baixo no início do mercado de baixa, e a frequência de posições era muito alta no fundo do mercado. Também podemos ver que o modelo não aprendeu a manter posições por muito tempo e sempre vende rápido.
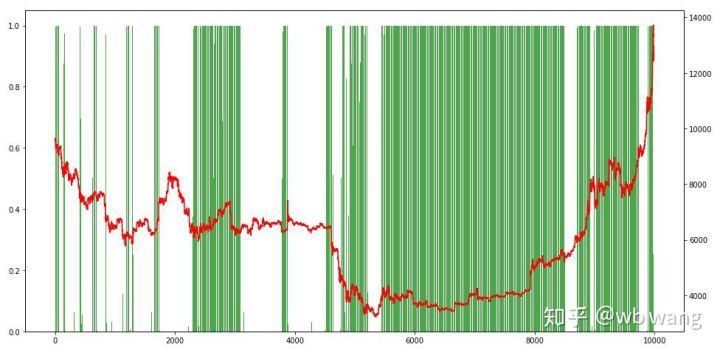
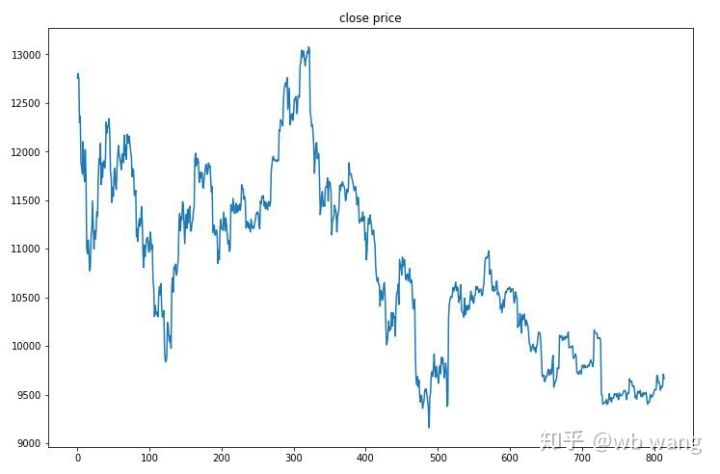
8. Análise de dados de teste
Os dados de teste foram obtidos do mercado de Bitcoin de uma hora de 27/06/2019 até o presente. Como pode ser visto na figura, o preço caiu de US\( 13.000 no início para mais de US\) 9.000 hoje, o que é um ótimo teste para o modelo.
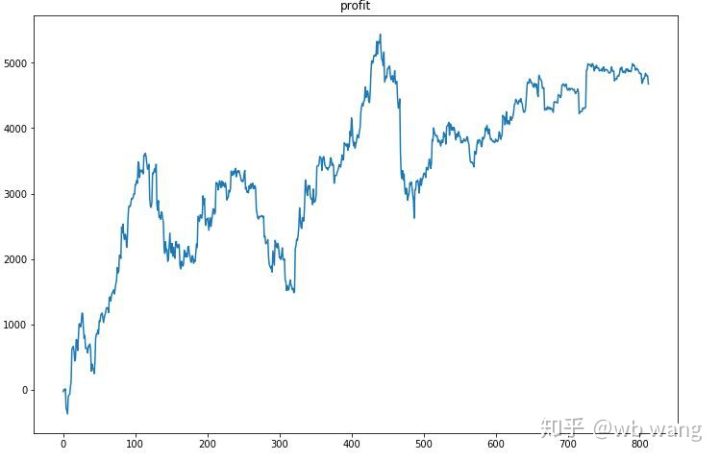
Em primeiro lugar, o retorno relativo final não foi satisfatório, mas também não houve perda.
Olhando para as posições, podemos supor que o modelo tende a comprar após uma queda acentuada e vender após uma recuperação. O mercado de Bitcoin flutuou muito pouco nos últimos tempos, e o modelo tem estado em uma posição curta.
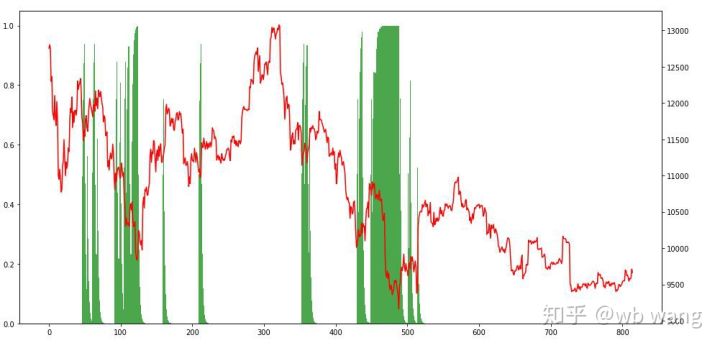
9. Resumo
Este artigo usa o método de aprendizado por reforço profundo PPO para treinar um robô de negociação automática de Bitcoin e obtém algumas conclusões. Devido ao tempo limitado, ainda há algumas áreas que podem ser melhoradas no modelo. Todos são bem-vindos para discutir. A maior lição é que a padronização de dados é o método certo. Não use métodos como escalonamento, caso contrário, o modelo rapidamente se lembrará da relação entre preço e condições de mercado e cairá em overfitting. Após a normalização, a taxa de mudança se torna um dado relativo, o que dificulta que o modelo se lembre de sua relação com o mercado e o força a encontrar a conexão entre a taxa de mudança e a ascensão e queda.
Artigos anteriores:
Algumas estratégias públicas compartilhadas na plataforma quantitativa FMZ Inventor: https://zhuanlan.zhihu.com/p/64961672
Curso de negociação quantitativa em moeda digital da NetEase Cloud Classroom, por apenas 20 yuans: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
Tornei pública uma estratégia de alta frequência que já foi muito lucrativa: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1