Сравнение 8 алгоритмов машинного обучения
 0
6946
0
6946
Сравнение 8 алгоритмов машинного обучения
В этой статье мы рассмотрим несколько сценариев адаптации наиболее распространенных алгоритмов и их преимущества и недостатки.
Существует множество алгоритмов машинного обучения, таких как классификация, регрессия, кластеризация, рекомендации, распознавание изображений и т. д. Найти подходящий алгоритм действительно нелегко, поэтому в практическом применении мы обычно экспериментируем с методом иллюстративного обучения.
Обычно вначале мы выбираем алгоритмы, с которыми мы все согласны, такие как SVM, GBDT, Adaboost, но сейчас глубокое обучение очень популярно, и нейронные сети также являются хорошим выбором.
Если вы заинтересованы в точности, то лучший способ - это тестировать каждый алгоритм по отдельности с помощью кросс-валидации, сравнивать, затем корректировать параметры, чтобы убедиться, что каждый алгоритм достиг оптимального решения, и в конце выбрать лучший.
Но если вы просто ищете алгоритм, который достаточно хорош, чтобы решить вашу проблему, или вот некоторые советы, которые вы можете использовать, рассмотрим преимущества и недостатки каждого алгоритма, чтобы нам было легче выбрать его на основе их преимуществ.
- ## Дифференциация
В статистике, хорошая или плохая модель измеряется в зависимости от отклонения и дифференциации, поэтому давайте сначала расширим понятие отклонения и дифференциации:
Отклонение: описывает разницу между ожидаемым E и реальным Y прогнозного значения (оценочного значения). Чем больше отклонение, тем больше отклонение от реальных данных.
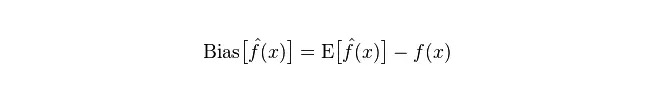
Дифференциация: описывает степень дифференциации, которая является диапазоном изменения прогнозируемого значения P. Дифференциацией является диапазон прогнозируемого значения, то есть расстояние от его ожидаемого значения E. Чем больше диапазон, тем более рассеянным будет распределение данных.
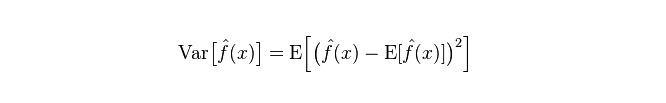
Реальная погрешность модели представляет собой сумму этих двух величин, как показано ниже:
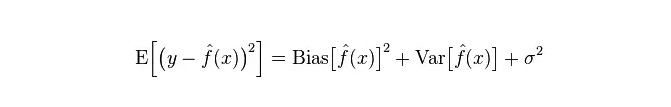
Если это небольшой тренировочный набор, классификатор с высоким отклонением/низким отклонением (например, простой Bayes NB) имеет большое преимущество перед классификатором с низким отклонением/высоким отклонением (например, KNN), поскольку последний будет перенастраиваться.
Однако, по мере роста вашего тренировочного набора, модель становится лучше в прогнозировании исходных данных, и отклонения уменьшаются, в этом случае классификаторы с низкой/высокой погрешностью постепенно показывают свои преимущества (поскольку они имеют меньшую приблизительную погрешность), в то время как классификаторы с высокой погрешностью уже не могут обеспечить точную модель.
Разумеется, вы можете рассматривать это как разницу между генерирующей моделью (NB) и детерминирующей моделью (KNN).
- ## Почему простой Бейес - это высокодифференцированный низкодифференцированный?
В этой статье мы рассмотрим следующее:
Во-первых, предположим, что вы знаете отношение между тренировочным набором и тестовым набором. Проще говоря, мы собираемся изучить модель на тренировочном наборе, а затем использовать тестовый набор. Эффективность измеряется по погрешности тестового набора.
Но зачастую мы можем только предположить, что тест-сеты и тренировочные группы соответствуют одному и тому же распределению данных, но не получаем реальных тестовых данных.
Поскольку образцов для тренировки очень мало (или, по крайней мере, недостаточно), модель, полученная с помощью тренировочного набора, всегда не является действительно правильной. Даже если она правильна на тренировочном наборе на 100%, это не означает, что она изображает реальное распределение данных.
Более того, в практике обученные образцы часто имеют некоторую шумовую погрешность, поэтому если слишком стремиться к совершенству в обучающем наборе и использовать очень сложную модель, это приведет к тому, что модель будет принимать ошибки в обучающем наборе за истинные характеристики распределения данных, что приведет к ошибочным оценкам распределения данных.
В таком случае, в реальном тестовом наборе ошибки будут совершенно размытыми (это называется совпадением). Однако нельзя использовать слишком простые модели, иначе, когда распределение данных является более сложным, модели не будут достаточными, чтобы изобразить распределение данных (это проявляется в высоком уровне ошибок даже в тренировочном наборе, это явление является менее подходящим).
Сверхсоответствие указывает на то, что используемая модель более сложна, чем истинное распределение данных, в то время как недостаточное соответствие указывает на то, что используемая модель проще, чем истинное распределение данных.
В рамках статистического обучения, когда мы изображаем сложность модели, есть такая точка зрения, что ошибка = Bias + Variance. Здесь ошибка, вероятно, может быть понята как прогнозная погрешность модели, состоит из двух частей, одна из которых состоит из неточных оценок, вызванных слишком простой моделью (Bias), а другая часть - из большего пространства изменений и неопределенности, вызванных слишком сложной моделью (Variance).
Таким образом, легко анализировать простого Бейеса. Его простое предположение о том, что данные не связаны друг с другом, является сильно упрощенной моделью. Таким образом, для такой простой модели большинство случаев часть Bias будет больше, чем часть Variance, то есть высокая отклонение и низкая диапазона.
На практике, чтобы уменьшить ошибку, мы должны сбалансировать пропорции, которые составляют Bias и Variance при выборе модели, то есть сбалансировать over-fitting и under-fitting.
Отношение отклонения и квадратного отклонения к сложности модели проясняется на следующем графике:
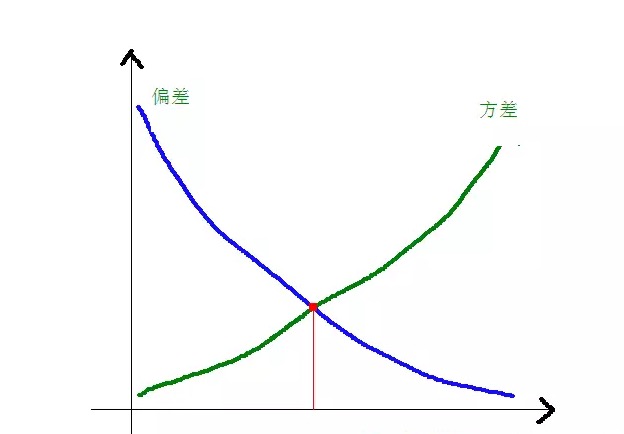
По мере роста сложности модели, отклонения становятся меньше, а расхождения - больше.
-
Общие достоинства и недостатки алгоритмов
- ### 1. Проклятый Байес
Простая Бейес относится к генерируемым моделям (в отношении генерирующих моделей и детерминирующих моделей, главным образом, это касается того, требуется ли совместное распределение), очень просто, вы просто делаете кучу вычислений.
Если предположить условно-независимость ((одно из более строгих условий), примитивный байесовский классификатор будет сходиться быстрее, чем различающие модели, такие как логическая регрессия, поэтому вам потребуется меньше тренировочных данных. Даже если предположение о условной независимости НБ не подтверждается, НБ-классификатор все равно отлично работает на практике.
Его главный недостаток заключается в том, что он не может изучать взаимодействие между характеристиками, и R в mRMR - это избыточность характеристик. Приведем более классический пример, например, хотя вам нравятся фильмы с Брэдом Питом и Томом Крузом, он не может выучить, что вам не нравятся фильмы, в которых они вместе.
Преимущества:
Простая бейесовская модель, основанная на классической математической теории, имеет прочную математическую основу и стабильную эффективность классификации. Хорошая производительность в малых масштабах, способность к выполнению многоклассных задач в одиночку, подходит для инкрементированной тренировки; Алгоритмы, менее чувствительные к отсутствующим данным, более просты и часто используются для классификации текста. Недостатки:
В этом случае необходимо вычислить вероятность предварительного выбора. Ошибки в принятии классификационных решений; Очень чувствительны к формам ввода данных.
- ### 2. Логическая регрессия
Есть множество способов, как сделать модель регулятивной (L0, L1, L2, и т. д.), и вам не нужно беспокоиться о том, что ваши характеристики будут релевантны, как это было с простым Бейесом.
Вы также получите хорошее вероятностное объяснение по сравнению с деревьями решений и SVM, и вы даже можете легко использовать новые данные для обновления модели (с помощью алгоритма онлайн-градиентного спуска).
Если вам нужна архитектура вероятности (например, для простой регулировки классификационных крайностей, указания неопределенности или для получения доверительных интервалов), или вы хотите быстро интегрировать больше тренировочных данных в модель, используйте ее.
Функция сигмоида:
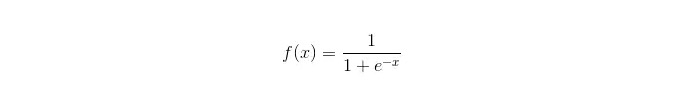
Преимущества: Простая, широко применяемая в промышленности; Очень мало вычислений при классификации, очень быстрая скорость, низкие ресурсы хранения; Скорее всего, это будет означать, что у вас есть возможность использовать данные, полученные в ходе наблюдений. Для логической регрессии множественная колинейность не является проблемой, которую можно решить в сочетании с L2 нормализацией; Недостатки: Логическая регрессия не очень хорошо работает при большом пространстве признаков. Недостаточное соответствие, обычно не очень точное Недостаточно хорошо справляется с большим количеством разнообразных признаков или переменных; может обрабатывать только два вопроса классификации (softmax, полученный на этой основе, может использоваться для многоклассификации) и должен быть линейно делимым; Нелинейные признаки требуют преобразования.
- ### 3. Линейная регрессия
Линейное регрессирование используется для регрессии, в отличие от логистического регрессирования, используемого для классификации, основной идеей которого является оптимизация ошибочных функций в форме наименьшего двоичного умножения с помощью метода градиентного снижения, а также решение параметров, полученных непосредственно с помощью нормального уравнения.
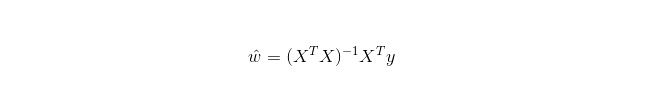
В LWLR (Local Weighted Linear Regression) вычисление параметров выражается следующим образом:
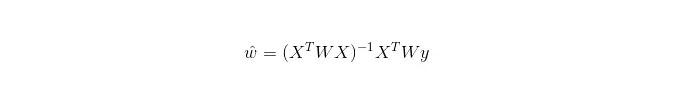
Отсюда следует, что LWLR отличается от LR, LWLR является непараметрической моделью, поскольку каждый раз, когда выполняется регрессионный вычисление, необходимо пройти через тренировочный образец как минимум один раз.
Преимущества: простота в реализации, простота в расчете;
Недостатки: невозможно сопоставить нелинейные данные.
- ### 4. алгоритм ближайшего соседа
KNN - Nearest Neighborhood Algorithm, основной процесс которого заключается в:
вычислить расстояние от каждой точки выборки в тренировочном образце и в тестовом образце (обычные измерения расстояния имеют европейское расстояние, расстояние по Марсу и т. д.);
Сортировка всех вышеперечисленных значений расстояния;
выберите k наименьших проб;
В результате голосования за этикетки из k образцов получается окончательная классификация.
Как выбрать оптимальное значение K зависит от данных. Как правило, более высокие значения K при классификации способны уменьшить влияние шума, но могут привести к размытию границ между категориями.
Лучшее значение K может быть получено с помощью различных иллюстративных технологий, таких как, например, перекрестная проверка. Кроме того, присутствие векторов для шумов и некоррелятивных характеристик снижает точность алгоритмов близкого соседства K.
Крайне близкие алгоритмы имеют более сильные результаты согласованности. По мере того, как данные становятся бесконечными, алгоритм гарантирует, что погрешность не превысит в два раза погрешность базеевского алгоритма. Для некоторых хороших значений K, близкие соседи K гарантируют, что погрешность не превысит погрешность теории Бейеса.
Преимущества алгоритма KNN
Теоретически зрелый, с простыми мыслями, который можно использовать как для классификации, так и для регрессии; может использоваться для нелинейной классификации; сложность времени тренировки O ((n); В результате исследования было установлено, что данные не имеют никаких предположений, а являются очень точными и не восприимчивыми к аутлиерам. недостаток
Большие расчеты; Неравновесие в выборке ((то есть, в некоторых категориях выборка большая, а в других - маленькая); Это требует большого объема памяти.
- ### 5. Дерево решения
Легко интерпретируемый. Он может без стресса обрабатывать взаимоотношения между признаками и является непатриметричным, поэтому вам не нужно беспокоиться о том, являются ли аномальные значения или ли данные линейно разделяемыми (например, дерево решений может легко обрабатывать ситуацию, когда категория A находится на конце некоторого измерения x признака, категория B в середине, а затем категория A появляется на переднем конце измерения x признака).
Одним из недостатков является то, что он не поддерживает онлайн-обучение, поэтому, когда приходят новые образцы, дерево решений необходимо полностью перестроить.
Еще один недостаток заключается в том, что они легко пересоединяются, но это также является точкой отсчета для интеграционных методов, таких как RF в случайных лесах (или Boosted Tree).
Кроме того, случайные леса часто выигрывают в классификационных задачах (обычно немного лучше, чем поддерживаемые векторные машины), они быстрые и настраиваемые, и вам не нужно беспокоиться о том, чтобы настраивать множество параметров, как это было с поддерживаемыми векторными машинами, поэтому они всегда были популярны раньше.
Важным моментом в дереве принятия решения является выбор атрибута для разветвления, поэтому обратите внимание на расчетную формулу информационного прироста и глубоко разобраться в ней.
Формула расчета информационного ящика:
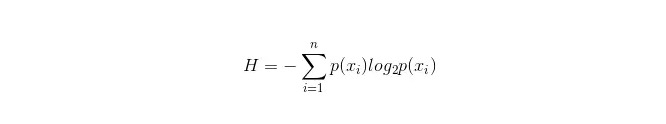
Из них n представляет собой n классификационных категорий ((предположим, что это 2-классный вопрос, тогда n = 2). Расчет вероятности появления этих 2-классных образцов в общей выборке, p1 и p2 соответственно, позволяет рассчитать информационный слой перед разветвлением невыбранных атрибутов.
Теперь выберите свойство xixi, которое будет использоваться для разветвления, и тогда правила разветвления следуют: если xi = vxi = v, разделите образец на одну ветвь дерева; если неравно, перейдите в другую ветвь.
Очевидно, что выборка в ответвлениях, скорее всего, включает в себя 2 категории, рассчитывая соответственно прибыль H1 и H2 в этих двух ответвлениях, рассчитывая общую информационную прибыль после ответвления H = p1 H1 + p2 H2, тогда информационный прирост ΔH = H - H. Используя информационный прирост в качестве принципа, тестируя все свойства в сторону, выберите один из свойств с наибольшим приростом как свойство ответвления.
Преимущества самого дерева решения
Это означает, что вычисления должны быть простыми, понятными и объяснимыми. Сравнение образцов с недостающими свойствами; Умение обрабатывать неуместные черты; Умение в относительно короткие сроки получать эффективные результаты из больших источников данных. недостаток
Обычно это происходит из-за того, что леса, в которых высаживаются растения, имеют высокий уровень биологической устойчивости. Некоторые исследователи считают, что это не так. Для тех данных, в которых количество выборки в разных категориях несовместимо, в дереве принятия решений результаты информационного прироста привязаны к тем, которые имеют больше количественных характеристик ((до тех пор, пока используется информационный прирост, есть этот недостаток, например, RF)).
- ### 5.1 Adaboosting
Adaboost - это модель ассимиляции, в которой каждая модель построена на основе погрешности предыдущей модели. Слишком большое внимание уделяется ошибочным образцам, а меньше внимания правильно классифицированным образцам. После последовательной итерации можно получить относительно хорошую модель.
преимущество
adaboost - классификатор с высокой точностью. Субклассификатор может быть построен с помощью различных методов, основанных на алгоритме Adaboost. При использовании простого классификатора результаты вычислений понятны, а конструкция слабого классификатора чрезвычайно проста. Простая, без фильтрации по признакам. Не подвержены переоборудованию. О комбинационных алгоритмах, таких как случайные леса и GBDT, см. статью: Машинное обучение - резюме комбинационных алгоритмов
Недостатки: чувствительность к аутлиеру
- ### 6. Векторные машины с поддержкой SVM
Высокая точность обеспечивает хорошую теоретическую гарантию для предотвращения пересогласования, и даже если данные линейно неразделимы в исходном пространстве характеристик, они могут работать хорошо, если дать подходящую ядерную функцию.
Особенно популярен в вопросах классификации текста сверхвысокого размера. К сожалению, он требует большой объем памяти, трудно интерпретировать, а также некоторые неудобства в работе и корректировке, а случайные леса, в отличие от этих недостатков, являются более практичными.
преимущество Это позволяет решить проблему высоких измерений, то есть пространства больших характеристик. способность обрабатывать взаимодействие нелинейных признаков; Не нужно полагаться на все данные. Повышение способности к генерализации;
недостаток Если вы используете многочисленные образцы, эффективность не будет высокой. Не существует универсального решения для нелинейных задач, и иногда бывает трудно найти подходящую ядерную функцию; Ощущение отсутствия данных; Выбор ядра также уместен (libsvm имеет четыре собственных ядра: линейные ядра, многоядерные ядра, RBF и сигмоидные ядра):
Во-первых, если количество образцов меньше, чем количество характеристик, то нет необходимости выбирать нелинейные ядра, просто используйте линейные ядра.
Во-вторых, если количество образцов больше количества признаков, то можно использовать нелинейные ядра, чтобы отобразить образцы в более высоких измерениях, что обычно дает лучшие результаты.
В-третьих, если количество образцов и количество признаков равны, то в этом случае можно использовать нелинейные ядра, принцип которых тот же, что и во втором случае.
В первом случае можно также начать с уменьшения размера данных, а затем использовать нелинейные ядра, что также является методом.
- ### 7. Преимущества и недостатки искусственных нейронных сетей
Преимущества искусственных нейронных сетей: высокая точность классификации; Сильная параллельная распределенная обработка, распределенное хранение и обучение. Имеет большую грубость и устойчивость к ошибкам, а также способность приближаться к сложным нелинейным отношениям. Функция вспоминания.
Недостатки искусственных нейронных сетей: Нейронная сеть требует большого количества параметров, таких как топограмма сети, начальные значения значений веса и отметки; отсутствие возможности наблюдения за процессом обучения, а также трудность интерпретации результатов, что может повлиять на их достоверность и приемлемость; Учеба может занять слишком много времени и даже не достичь цели.
- ### 8 К-средний кластер
В предыдущей статье мы писали о кластерах K-Means, в которой содержатся очень сильные идеи EM.
преимущество Алгоритмы просты и легко реализуемы; Для обработки больших наборов данных этот алгоритм является относительно масштабируемым и эффективным, поскольку его сложность составляет около O{\displaystyle O{\displaystyle O} nkt, где n - количество всех объектов, k - количество параллелей, t - количество повторений. Обычно k<]]. Алгоритм пытается найти наименьшее k разделение, которое дает наименьшую квадратную погрешность. Классификация эффективна, когда углерод плотный, шарообразный или клубнеобразный, и отличия между углеродом и углеродом очевидны.
недостаток более высокие требования к типу данных, подходящие для цифровых данных; Возможно сближение локальных минимумов, медленное сближение в больших массивах данных Очень сложно выбрать значение K. чувствительны к начальным значениям центров концентрации, которые могут привести к различным результатам сгруппировки для различных начальных значений; Не подходит для обнаружения не выпуклых форм или больших размерах. Небольшое количество таких данных может оказать огромное влияние на средние значения, чувствительные к шуму и данным о точках изоляции.
Алгоритм выбора ссылок
В одной из статей, переведенных за рубежом, есть простой алгоритмический подход к выбору:
В качестве первоочередного метода следует выбрать логическую регрессию, и если она не очень эффективна, ее результаты можно использовать в качестве ориентира для сравнения с другими алгоритмами;
Затем попробуйте дерево решения (случайный лес) и посмотрите, может ли оно значительно улучшить производительность вашей модели. Даже если вы не считаете его конечной моделью, вы можете использовать случайный лес для удаления переменных шума и выбора характеристик.
Если количество признаков и образцов наблюдений особенно велико, то использование SVM является обязательным вариантом, когда ресурсов и времени достаточно (это важно).
Обычно:
Хотя алгоритмы и важны, но хорошие данные лучше хороших алгоритмов, и хорошие конструктивные характеристики очень полезны. Если у вас есть гигантский набор данных, то какой бы алгоритм вы ни использовали, он может не иметь большого влияния на производительность классификации (тогда вы можете сделать выбор в зависимости от скорости и удобства использования).
-
Ссылки