نیورل نیٹ ورکس اور ڈیجیٹل کرنسی کی کوانٹیٹیٹو ٹریڈنگ سیریز (1) - LSTM Bitcoin قیمت کی پیش گوئی کرتا ہے
مصنف:لیدیہ, تخلیق: 2023-01-12 13:55:01, تازہ کاری: 2023-09-20 10:06:28
نیورل نیٹ ورکس اور ڈیجیٹل کرنسی کی کوانٹیٹیٹو ٹریڈنگ سیریز (1) - LSTM Bitcoin قیمت کی پیش گوئی کرتا ہے
۱. مختصر تعارف
ڈیپ نیورل نیٹ ورک حالیہ برسوں میں زیادہ سے زیادہ مقبول ہو گیا ہے۔ اس نے بہت سے شعبوں میں ماضی میں حل نہیں ہوسکنے والے مسائل کو حل کیا ہے اور اپنی مضبوط صلاحیت کا مظاہرہ کیا ہے۔ وقت کی سیریز کی پیش گوئی میں ، عام طور پر استعمال ہونے والا نیورل نیٹ ورک کی قیمت آر این این ہے ، کیونکہ اس میں نہ صرف موجودہ ڈیٹا ان پٹ ہے ، بلکہ تاریخی ڈیٹا ان پٹ بھی ہے۔ یقینا ، جب ہم آر این این کی قیمت کی پیش گوئی کے بارے میں بات کرتے ہیں تو ، ہم اکثر آر این این میں سے ایک کے بارے میں بات کرتے ہیں: ایل ایس ٹی ایم۔ یہ مقالہ پائی ٹورچ کی بنیاد پر بٹ کوائن کی قیمت کی پیش گوئی کرنے کے لئے ایک ماڈل تیار کرے گا۔ اگرچہ انٹرنیٹ پر بہت ساری متعلقہ معلومات موجود ہیں ، لیکن یہ ابھی تک کافی حد تک مکمل نہیں ہے ، اور نسبتا few کم لوگ پائی ٹورچ استعمال کرتے ہیں۔ اب بھی ایک مضمون لکھنا ضروری ہے۔ حتمی نتیجہ بٹ کوائن کی اگلی قیمت ، اختتامی قیمت ، سب سے زیادہ قیمت ، کم ترین قیمت ، اور تجارتی حجم کی پیش گوئی کرنے کے لئے استعمال کرنا ہے۔ میرا ذاتی علم یہ سبق ایف ایم زیڈ کوانٹ ٹریڈنگ پلیٹ فارم کے ذریعہ تیار کیا گیا ہے (www.fmz.com) ، QQ گروپ میں شامل ہونے کے لئے خوش آمدید: 863946592 مواصلات کے لئے.
2۔ اعداد و شمار اور حوالہ جات
بٹ کوائن کی قیمت کا ڈیٹا ایف ایم زیڈ کوانٹ ٹریڈنگ پلیٹ فارم سے حاصل کیا گیا ہے:https://www.quantinfo.com/Tools/View/4.html. قیمت کی پیشن گوئی کا ایک متعلقہ مثال:https://yq.aliyun.com/articles/538484. RNN ماڈل کا تفصیلی تعارف:https://zhuanlan.zhihu.com/p/27485750. RNN کے ان پٹ اور آؤٹ پٹ کو سمجھنا:https://www.zhihu.com/question/41949741/answer/318771336. پیٹورچ کے بارے میں: سرکاری دستاویزات:https://pytorch.org/docsدیگر معلومات کے لیے آپ خود تلاش کر سکتے ہیں۔ اس کے علاوہ، آپ کو اس مضمون کو پڑھنے کے لئے کچھ پہلے علم کی ضرورت ہے، جیسے پانڈا / پطرون / ڈیٹا پروسیسنگ، لیکن اگر آپ نہیں کرتے تو اس سے کوئی فرق نہیں پڑتا.
پیٹورچ LSTM ماڈل کے پیرامیٹرز
LSTM کے پیرامیٹرز:
پہلی بار جب میں نے دستاویز پر ان گھنے پیرامیٹرز کو دیکھا، میرا رد عمل تھا: یہ کیا ہے؟
میں نے آہستہ آہستہ پڑھنا شروع کیا

input_size: ویکٹر ایکس کا مخصوص سائز ان پٹ کریں۔ اگر اختتامی قیمت کی پیشن گوئی اختتامی قیمت سے کی جاتی ہے تو ، پھر ان پٹ_سائز = 1؛ اگر اختتامی قیمت کی پیشن گوئی اعلی افتتاحی اور کم اختتامی کے ذریعہ کی جاتی ہے تو ، پھر ان پٹ_سائز = 4۔hidden_size: ضمنی پرت کا سائزnum_layers: RNN کی تہوں کی تعداد.batch_first: اگر سچ ہے تو، پہلی ان پٹ طول و عرض batch_size ہے، جو بھی بہت الجھن میں ہے، اور یہ ذیل میں تفصیل سے بیان کیا جائے گا.
ڈیٹا پیرامیٹرز درج کریں:
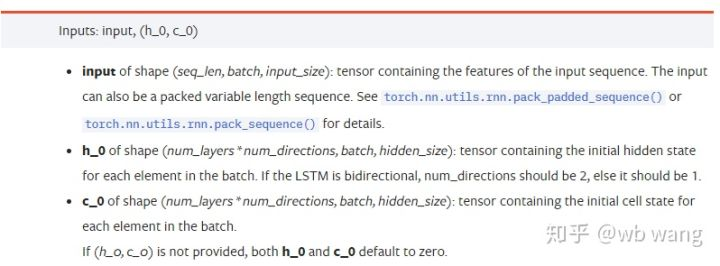
input: مخصوص ان پٹ ڈیٹا ایک تین جہتی ٹینسر ہے ، اور مخصوص شکل یہ ہے: (seq_len ، بیچ ، ان پٹ_سائز) ۔ جہاں ، seq_len ترتیب کی لمبائی سے مراد ہے ، یعنی ، تاریخی ڈیٹا پر غور کرنے کے لئے LSTM کو کتنا وقت درکار ہے۔ نوٹ کریں کہ اس سے صرف اعداد و شمار کی شکل سے مراد ہے ، نہ کہ LSTM کی داخلی ساخت سے۔ ایک ہی LSTM ماڈل مختلف seqs_lenh_0: ابتدائی پوشیدہ حالت، شکل کے طور پر (num_layers * num_directions، بیچ، hidden_size) ، اگر یہ دو طرفہ نیٹ ورک ہے تو، num_directions=2.c_0: سیل کی ابتدائی حالت، شکل جیسا کہ اوپر ہے، غیر مخصوص ہوسکتی ہے.
آؤٹ پٹ پیرامیٹرز:
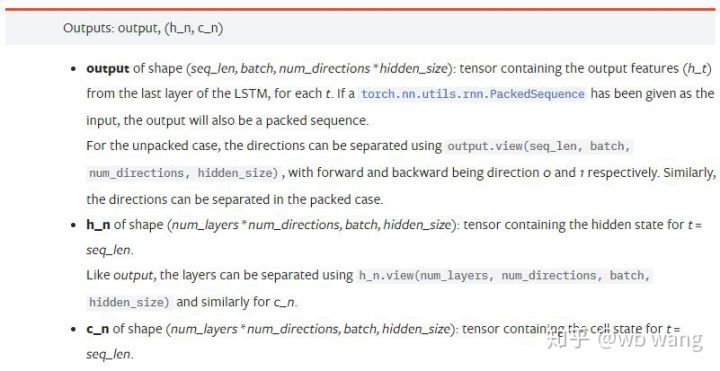
output: پیداوار کی شکل (seq_len، بیچ، num_directions * پوشیدہ_size) ، نوٹ کریں کہ یہ ماڈل پیرامیٹر batch_first سے متعلق ہے.h_n: t = seq_len کے لمحے میں h حالت، h_0 کے طور پر ایک ہی شکل.c_n: t = seq_len کے وقت کی حالت c، c_0 کے طور پر ایک ہی شکل.
LSTM ان پٹ اور آؤٹ پٹ کی ایک سادہ مثال
پہلے مطلوبہ پیکیج درآمد کریں
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
LSTM ماڈل کی وضاحت کریں
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
ان پٹ ڈیٹا تیار کریں
x = torch.randn(3,4,5)
# The value of x is:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
x کی شکل (3,4,5) ہے، کیونکہ ہم نے وضاحت کی ہےbatch_first=Trueپہلے، اس وقت batch_size کا سائز 3 ہے، sqe_len 4 ہے، input_size 5 ہے۔ X [0] پہلے بیچ کی نمائندگی کرتا ہے۔
اگر batch_first کی وضاحت نہیں کی گئی ہے تو ، پہلے سے طے شدہ قدر غلط ہے ، پھر اس وقت ڈیٹا کی نمائندگی مکمل طور پر مختلف ہے۔ بیچ کا سائز 4 ہے ، sqe_len 3 ہے ، input_size 5 ہے۔ اس وقت ، x [0] t = 0 پر تمام بیچوں کے ڈیٹا کی نمائندگی کرتا ہے ، اور اسی طرح۔ مجھے لگتا ہے کہ یہ ترتیب بدیہی نہیں ہے ، لہذا میں نے پیرامیٹر شامل کیاbatch_first=True.
دونوں کے درمیان اعداد و شمار کی تبدیلی بھی بہت آسان ہے:x.permute (1,0,2)
ان پٹ اور آؤٹ پٹ
LSTM کے ان پٹ اور آؤٹ پٹ کی شکل بہت الجھن میں ہے، اور مندرجہ ذیل اعداد و شمار ہمیں سمجھنے میں مدد مل سکتی ہے:
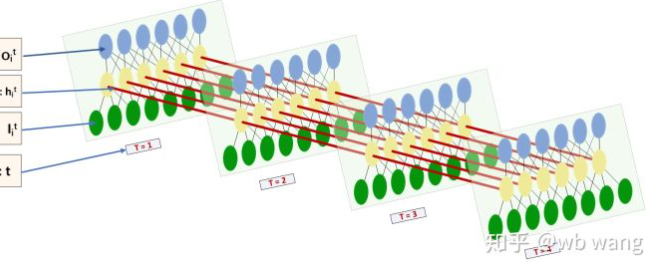
سے:https://www.zhihu.com/question/41949741/answer/318771336.
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) # Thinking about it, what would be the size of the output if batch_first=False?
print(hn.size())
print(cn.size())
# result
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
آؤٹ پٹ کا نتیجہ ملاحظہ کریں ، جو پچھلے پیرامیٹر کی تشریح کے مطابق ہے۔ نوٹ کریں کہ hn.size() کی دوسری قیمت 3 ہے ، جو batch_size کے سائز کے مطابق ہے ، جس کا مطلب ہے کہ انٹرمیڈیٹ اسٹیٹ کو hn میں محفوظ نہیں کیا جاتا ہے ، صرف آخری مرحلہ محفوظ کیا جاتا ہے۔ چونکہ ہمارے ایل ایس ٹی ایم نیٹ ورک میں دو پرتیں ہیں ، در حقیقت ، hn کی آخری پرت کا آؤٹ پٹ آؤٹ پٹ کی قیمت ہے۔ آؤٹ پٹ کی شکل [3 ، 4 ، 10] ہے ، جو t = 0 ، 1 ، 2 ، 3 کے تمام اوقات میں نتائج کو محفوظ کرتی ہے ، لہذا:
hn[-1][0] == output[0][-1] # The output of the first batch at the last level of hn is equal to the output of the first batch at t=3.
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5۔ بٹ کوائن مارکیٹ کے اعداد و شمار تیار کریں
اس سے پہلے بہت کچھ کہا گیا ہے ، جو صرف ایک تعارف ہے۔ LSTM کے ان پٹ اور آؤٹ پٹ کو سمجھنا بہت ضروری ہے۔ بصورت دیگر ، انٹرنیٹ سے بے ترتیب طور پر کچھ کوڈز نکال کر غلطیاں کرنا آسان ہے۔ وقت کی سیریز میں LSTM کی مضبوط صلاحیت کی وجہ سے ، یہاں تک کہ اگر ماڈل غلط ہے تو ، آخر میں اچھے نتائج حاصل کیے جاسکتے ہیں۔
ڈیٹا اکٹھا کرنا
Bitfinex Exchange میں BTC_USD ٹریڈنگ جوڑی کے مارکیٹ ڈیٹا کا استعمال کیا جاتا ہے۔
import requests
import json
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1562658565')
data = resp.json()
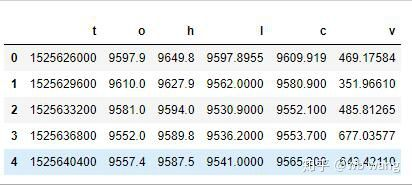
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
اعداد و شمار کی شکل مندرجہ ذیل ہے:
اعداد و شمار کی پیشگی پروسیسنگ
df.index = df['t'] # index is set to timestamp
df = (df-df.mean())/df.std() # The standardization of the data, otherwise the loss of the model will be very large, which is not conducive to convergence.
df['n'] = df['c'].shift(-1) # n is the closing price of the next period, which is our forecast target.
df = df.dropna()
df = df.astype(np.float32) # Change the data format to fit pytorch.
اعداد و شمار کی معیاری کاری کا طریقہ بہت سخت ہے، اور کچھ مسائل پیدا ہوں گے۔ صرف مظاہرے کے لئے، آپ ڈیٹا معیاری کاری جیسے واپسی کی شرح کا استعمال کرسکتے ہیں۔
تربیت کے اعداد و شمار تیار کریں
seq_len = 10 # Input 10 periods of data
train_size = 800 # Training set batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) # The change in shape, -1 represents the value that will be calculated automatically.
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
train_x اور train_y کی حتمی شکلیں ہیں: torch.Size ([800, 10, 5]) ، torch.Size ([800, 10, 1]). چونکہ ہمارا ماڈل 10 ادوار کے اعداد و شمار کی بنیاد پر اگلی مدت کی اختتامی قیمت کی پیش گوئی کرتا ہے ، لہذا نظریاتی طور پر 800 بیچ ہیں ، جب تک کہ 800 پیش گوئی کی گئی اختتامی قیمتیں ہوں۔ لیکن ہر بیچ میں train_y کے پاس 10 ڈیٹا ہوتے ہیں۔ در حقیقت ، ہر بیچ کی پیش گوئی کا انٹرمیڈیٹ نتیجہ محفوظ ہے۔ حتمی نقصان کا حساب کرتے وقت ، تمام 10 پیش گوئی کے نتائج کو مدنظر رکھا جاسکتا ہے اور train_y میں اصل قدر سے موازنہ کیا جاسکتا ہے۔ نظریاتی طور پر ، ہم صرف آخری پیش گوئی کے نتیجے کا نقصان کا حساب لگاسکتے ہیں۔ چونکہ LSTM ماڈل میں اصل میں seq_lenful پیرامیٹر نہیں ہوتا ہے ، لہذا ماڈل کو مختلف لمبائی پر لاگو کیا جاسکتا ہے ، اور وسط میں پیش گوئی کے نتائج بھی معنی خیز ہیں ، لہذا میں نقصان کو جوڑنا اور حساب لگانا پسند کرتا ہوں۔
نوٹ کریں کہ جب تربیت کے اعداد و شمار کی تیاری کرتے ہیں تو ، ونڈو کی نقل و حرکت چھلانگ لگتی ہے ، اور پہلے ہی استعمال شدہ اعداد و شمار کو استعمال نہیں کیا جاتا ہے۔ یقینا ، ونڈو کو ایک ایک کرکے بھی منتقل کیا جاسکتا ہے ، تاکہ حاصل کردہ تربیتی سیٹ بہت بڑا ہو۔ تاہم ، مجھے لگا کہ ملحقہ بیچ ڈیٹا بہت بار بار ہوتا ہے ، لہذا میں نے موجودہ طریقہ اپنایا۔
6. LSTM ماڈل کی تعمیر
حتمی ماڈل مندرجہ ذیل طور پر بنایا گیا ہے، جس میں دو پرتوں والا LSTM اور ایک لکیری پرت ہے۔
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # Linear layer, output the result of LSTM into a value.
def forward(self, x):
x, _ = self.rnn(x) # If you don't understand the change of data dimension in forward propagation, you can debug it separately.
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size is 5, which represents the high opening and low closing and trading volume. The implicit layer is 10.
۷۔ ماڈل کو تربیت دینا شروع کریں
آخر میں ہم تربیت شروع، کوڈ مندرجہ ذیل ہے:
criterion = nn.MSELoss() # A simple mean square error loss function is used.
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # Optimize function, lr is adjustable.
for epoch in range(600): # Because of the speed, there are more epochs here.
out = net(train_x) # Due to the small amount of data, the full amount of data is directly used for calculation.
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # Reverse propagation losses
optimizer.step() # Update parameters
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
تربیت کے نتائج مندرجہ ذیل ہیں:
8. ماڈل کی تشخیص
ماڈل کی متوقع قیمت:
p = net(torch.from_numpy(data_X))[:,-1,0] # Only the last predicted value is taken here for comparison.
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
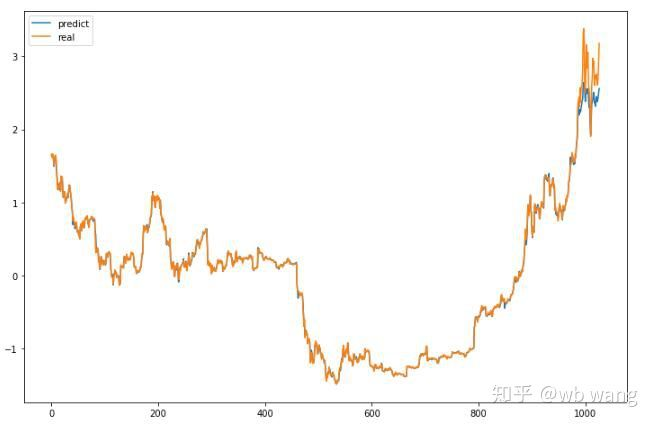
یہ چارٹ سے دیکھا جاسکتا ہے کہ تربیت کے اعداد و شمار (800 سے پہلے) بہت مستقل ہیں ، لیکن بعد کے عرصے میں بٹ کوائن کی قیمت میں اضافہ ہوا ہے۔ ماڈل نے یہ اعداد و شمار نہیں دیکھے ہیں ، لہذا پیش گوئی ناکافی ہے۔ اس سے یہ بھی ظاہر ہوتا ہے کہ اعداد و شمار کی معیاری کاری میں مسائل ہیں۔ اگرچہ پیش گوئی کی گئی قیمت درست نہیں ہوسکتی ہے ، لیکن بڑھتی ہوئی اور کم ہونے کی پیش گوئی کی درستگی کیا ہے؟ پیش گوئی کے اعداد و شمار کا ایک حصہ لیں تاکہ دیکھیں:
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
نتیجے کے طور پر، عروج اور زوال کی پیش گوئی کی درستگی کی شرح 81.4 فیصد تک پہنچ گئی، جو میری توقعات سے بھی زیادہ ہے۔ مجھے نہیں معلوم کہ کچھ غلط ہے۔
یقینا، یہ ماڈل حقیقی بوٹ پر لاگو نہیں ہوتا، لیکن یہ سادہ اور سمجھنے میں آسان ہے۔ صرف اس کے ساتھ شروع کریں۔ اگلا، ڈیجیٹل کرنسی کی مقدار میں اعصابی نیٹ ورک کی درخواست کے مزید تعارفی کورسز ہوں گے۔
- کریپٹوکرنسی مارکیٹ میں بنیادی تجزیہ کی مقدار: اعداد و شمار کو اپنے لئے بولنے دیں!
- ایک بار پھر ، ہم نے ایک بار پھر اس بات کا یقین کرلیا ہے کہ یہ ایک بہت بڑا مسئلہ ہے ، لیکن ہم اس کے بارے میں مزید نہیں جانتے ہیں۔
- کوانٹائزڈ ٹرانزیکشنز کے لیے ایک لازمی ٹول۔
- ہر چیز پر قابو پانا - ایف ایم زیڈ ٹریڈنگ ٹرمینل کا نیا ورژن (ٹی آر بی آربیٹریج سورس کوڈ کے ساتھ) کا تعارف
- FMZ کے نئے ورژن کے ٹرانزیکشن ٹرمینل کے بارے میں سب کچھ جاننے کے لئے یہاں کلک کریں
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (II)
- 80 لائنوں کے کوڈ میں ہائی فریکوئینسی حکمت عملی کے ساتھ دماغ کے بغیر سیلز بوٹس کا استحصال کیسے کریں
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (ب)
- 80 لائنوں کے کوڈ کے ساتھ ہائی فریکوئینسی کی حکمت عملی کے ساتھ فروخت کے لیے بے دماغ روبوٹ کا استحصال کیسے کیا گیا؟
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (I)
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (1)