Mạng thần kinh và chuỗi giao dịch định lượng tiền kỹ thuật số (1) - LSTM dự đoán giá Bitcoin
Tác giả:Lydia., Tạo: 2023-01-12 13:55:01, Cập nhật: 2023-09-20 10:06:28
Mạng thần kinh và chuỗi giao dịch định lượng tiền kỹ thuật số (1) - LSTM dự đoán giá Bitcoin
1. Lời giới thiệu ngắn gọn
Mạng thần kinh sâu đã trở nên ngày càng phổ biến trong những năm gần đây. Nó đã giải quyết các vấn đề không thể giải quyết trong quá khứ trong nhiều lĩnh vực và đã chứng minh khả năng mạnh mẽ của nó. Trong dự đoán chuỗi thời gian, giá mạng thần kinh thường được sử dụng là RNN, vì nó không chỉ có đầu vào dữ liệu hiện tại, mà còn có đầu vào dữ liệu lịch sử. Tất nhiên, khi chúng ta nói về dự đoán giá RNN, chúng ta thường nói về một trong những RNN: LSTM. Bài báo này sẽ xây dựng một mô hình để dự đoán giá Bitcoin dựa trên PyTorch. Mặc dù có rất nhiều thông tin có liên quan trên Internet, nhưng nó vẫn chưa đủ toàn diện, và vẫn còn tương đối ít người sử dụng PyTorch. Bài hướng dẫn này được sản xuất bởi nền tảng FMZ Quant Trading (www.fmz.comChào mừng bạn tham gia nhóm QQ: 863946592 để liên lạc.
2. Dữ liệu và tài liệu tham khảo
Dữ liệu giá Bitcoin lấy từ nền tảng FMZ Quant Trading:https://www.quantinfo.com/Tools/View/4.html- Không. Một ví dụ liên quan về dự đoán giá:https://yq.aliyun.com/articles/538484. Một giới thiệu chi tiết về mô hình RNN:https://zhuanlan.zhihu.com/p/27485750. Hiểu được đầu vào và đầu ra của RNN:https://www.zhihu.com/question/41949741/answer/318771336- Không. Về pytorch: tài liệu chính thức:https://pytorch.org/docsĐể biết thêm thông tin, bạn có thể tự tìm kiếm. Ngoài ra, bạn cần một số kiến thức trước để đọc bài viết này, chẳng hạn như panda / python / xử lý dữ liệu, nhưng nó không quan trọng nếu bạn không.
3. Các thông số của mô hình pytorch LSTM
Các thông số của LSTM:
Lần đầu tiên tôi thấy những thông số dày đặc trên tài liệu, phản ứng của tôi là: Cái quái gì đây?
Khi đọc chậm rãi, cuối cùng tôi cũng hiểu.

input_size: Nhập kích thước đặc trưng của vector x. Nếu giá đóng được dự đoán bởi giá đóng, thì input_size=1; Nếu giá đóng được dự đoán bởi giá mở cao và đóng thấp, thì input_size=4.hidden_size: Kích thước lớp ngụ ýnum_layers: Số lớp RNN.batch_first: Nếu đúng, kích thước đầu tiên là batch_size, cũng rất khó hiểu, và nó sẽ được mô tả chi tiết dưới đây.
Nhập tham số dữ liệu:
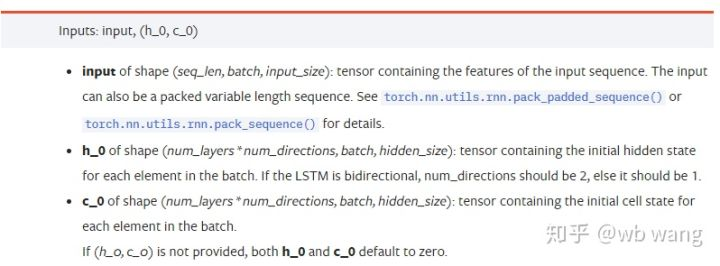
input: Dữ liệu đầu vào cụ thể là một tensor ba chiều, và hình dạng cụ thể là: (seq_len, batch, input_size). Nơi, seq_len đề cập đến độ dài của chuỗi, tức là thời gian mà LSTM cần xem xét dữ liệu lịch sử. Lưu ý rằng điều này chỉ đề cập đến định dạng của dữ liệu, không phải cấu trúc nội bộ của LSTM. Cùng mô hình LSTM có thể nhập dữ liệu seqs_lenh_0: trạng thái ẩn ban đầu, hình dạng như (num_layers * num_directions, batch, hidden_size), nếu đó là một mạng hai chiều, num_directions=2.c_0: Tình trạng tế bào ban đầu, hình dạng như trên, có thể không được xác định.
Các thông số đầu ra:
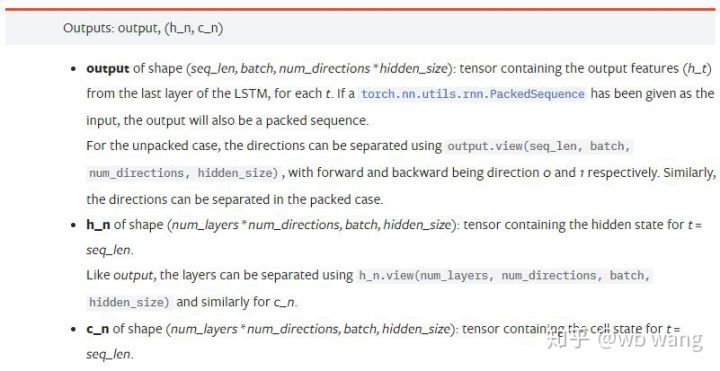
output: Hình dạng của đầu ra (seq_len, batch, num_directions * hidden_size), lưu ý rằng nó liên quan đến tham số mô hình batch_first.h_n: Tình trạng h tại thời điểm t = seq_len, cùng hình dạng với h_0.c_n: C trạng thái tại thời điểm của t = seq_len, cùng hình dạng như c_0.
4. Một ví dụ đơn giản về đầu vào và đầu ra LSTM
Nhập gói cần thiết trước
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
Định nghĩa mô hình LSTM
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
Chuẩn bị dữ liệu đầu vào
x = torch.randn(3,4,5)
# The value of x is:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
Hình dạng của x là (3,4,5), bởi vì chúng ta đã xác địnhbatch_first=Truetrước đây, kích thước của batch_size tại thời điểm này là 3, sqe_len là 4, input_size là 5. X [0] đại diện cho lô đầu tiên.
Nếu batch_first không được định nghĩa, giá trị mặc định là False, sau đó đại diện dữ liệu hoàn toàn khác nhau tại thời điểm này. kích thước lô là 4, sqe_len là 3, input_size là 5. Tại thời điểm này, x [0] đại diện cho dữ liệu của tất cả các lô khi t = 0, v.v. Tôi cảm thấy rằng cài đặt này không trực quan, vì vậy tôi đã thêm tham sốbatch_first=True.
Chuyển đổi dữ liệu giữa hai cũng rất thuận tiện:x.permute (1,0,2)
Input và output
Hình dạng đầu vào và đầu ra của LSTM rất khó hiểu và hình dưới đây có thể giúp chúng ta hiểu:
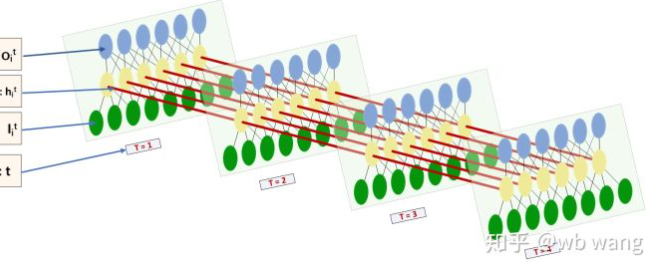
Từ:https://www.zhihu.com/question/41949741/answer/318771336.
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) # Thinking about it, what would be the size of the output if batch_first=False?
print(hn.size())
print(cn.size())
# result
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
Quan sát kết quả đầu ra, phù hợp với giải thích tham số trước. Lưu ý rằng giá trị thứ hai của hn.size (()) là 3, phù hợp với kích thước của batch_size, có nghĩa là trạng thái trung gian không được lưu trong hn, chỉ bước cuối cùng được lưu. Vì mạng LSTM của chúng tôi có hai lớp, thực tế đầu ra của lớp hn cuối cùng là giá trị đầu ra. hình dạng đầu ra là [3, 4, 10], lưu kết quả ở mọi thời điểm của t = 0,1,2,3, vì vậy:
hn[-1][0] == output[0][-1] # The output of the first batch at the last level of hn is equal to the output of the first batch at t=3.
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5. Chuẩn bị dữ liệu thị trường Bitcoin
Vì vậy, rất nhiều đã được nói trước đây, mà chỉ là một phần mở đầu. Nó là rất quan trọng để hiểu đầu vào và đầu ra của LSTM. Nếu không, nó là dễ dàng để làm cho sai lầm bằng cách lấy ngẫu nhiên một số mã từ Internet. Bởi vì khả năng mạnh mẽ của LSTM trong chuỗi thời gian, ngay cả khi mô hình là sai, kết quả tốt có thể được thu được ở cuối cùng.
Thu thập dữ liệu
Sử dụng dữ liệu thị trường của cặp giao dịch BTC_USD trong Bitfinex Exchange.
import requests
import json
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1562658565')
data = resp.json()
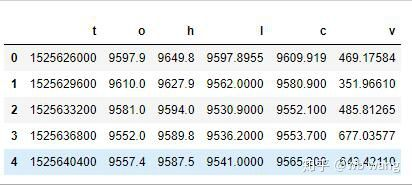
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
Định dạng dữ liệu là như sau:
Xử lý trước dữ liệu
df.index = df['t'] # index is set to timestamp
df = (df-df.mean())/df.std() # The standardization of the data, otherwise the loss of the model will be very large, which is not conducive to convergence.
df['n'] = df['c'].shift(-1) # n is the closing price of the next period, which is our forecast target.
df = df.dropna()
df = df.astype(np.float32) # Change the data format to fit pytorch.
Chỉ để chứng minh, bạn có thể sử dụng tiêu chuẩn hóa dữ liệu như tỷ lệ trả lại.
Chuẩn bị dữ liệu đào tạo
seq_len = 10 # Input 10 periods of data
train_size = 800 # Training set batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) # The change in shape, -1 represents the value that will be calculated automatically.
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
Các hình dạng cuối cùng của train_x và train_y là: torch.Size ([800, 10, 5]), torch.Size ([800, 10, 1]). Bởi vì mô hình của chúng tôi dự đoán giá đóng cửa của giai đoạn tiếp theo dựa trên dữ liệu của 10 giai đoạn, theo lý thuyết có 800 lô, miễn là có 800 giá đóng cửa dự đoán. Nhưng train_y trong mỗi lô có 10 dữ liệu. Trên thực tế, kết quả trung gian của mỗi dự đoán lô được lưu giữ. Khi tính toán tổn thất cuối cùng, tất cả 10 kết quả dự đoán có thể được tính đến và so sánh với giá trị thực tế trong train_y. Về lý thuyết, chúng ta chỉ có thể tính toán Loss của kết quả dự đoán cuối cùng. Bởi vì mô hình LSTM không chứa tham số seq_lenful thực sự, vì vậy mô hình có thể được áp dụng cho các chiều dài khác nhau, và kết quả dự đoán ở giữa cũng có ý nghĩa, vì vậy tôi thích kết hợp và tính toán Loss.
Lưu ý rằng khi chuẩn bị dữ liệu đào tạo, chuyển động của cửa sổ là nhảy, và các dữ liệu đã được sử dụng không còn được sử dụng nữa. Tất nhiên, cửa sổ cũng có thể được di chuyển một lần một lần, do đó tập tập đào tạo thu được lớn hơn nhiều. Tuy nhiên, tôi cảm thấy rằng dữ liệu lô liền kề quá lặp đi lặp lại, vì vậy tôi đã áp dụng phương pháp hiện tại.
6. Xây dựng mô hình LSTM
Mô hình cuối cùng được xây dựng như sau, chứa một LSTM hai lớp và một lớp tuyến tính.
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # Linear layer, output the result of LSTM into a value.
def forward(self, x):
x, _ = self.rnn(x) # If you don't understand the change of data dimension in forward propagation, you can debug it separately.
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size is 5, which represents the high opening and low closing and trading volume. The implicit layer is 10.
7. Bắt đầu huấn luyện mô hình
Cuối cùng chúng ta bắt đầu đào tạo, mã là như sau:
criterion = nn.MSELoss() # A simple mean square error loss function is used.
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # Optimize function, lr is adjustable.
for epoch in range(600): # Because of the speed, there are more epochs here.
out = net(train_x) # Due to the small amount of data, the full amount of data is directly used for calculation.
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # Reverse propagation losses
optimizer.step() # Update parameters
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
Kết quả đào tạo là như sau:
8. Đánh giá mô hình
Giá trị dự đoán của mô hình:
p = net(torch.from_numpy(data_X))[:,-1,0] # Only the last predicted value is taken here for comparison.
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
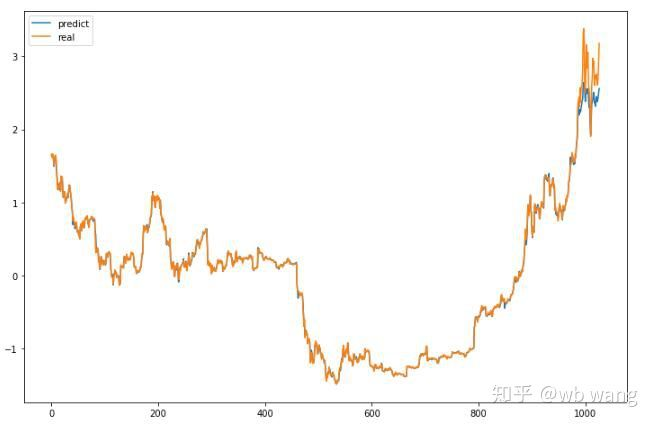
Có thể thấy từ biểu đồ rằng dữ liệu đào tạo (trước 800) rất phù hợp, nhưng giá Bitcoin đã tăng trong giai đoạn sau đó. Mô hình đã không nhìn thấy dữ liệu này, vì vậy dự đoán là không đầy đủ. Điều này cũng cho thấy có những vấn đề trong tiêu chuẩn hóa dữ liệu. Mặc dù giá dự đoán có thể không chính xác, nhưng độ chính xác của dự đoán tăng và giảm là bao nhiêu?
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
Kết quả là tỷ lệ chính xác của dự báo tăng và giảm đạt 81,4%, vẫn vượt quá mong đợi của tôi.
Tất nhiên, mô hình này không áp dụng cho bot thực tế, nhưng nó đơn giản và dễ hiểu. Chỉ cần bắt đầu với nó. tiếp theo, sẽ có nhiều khóa học giới thiệu về ứng dụng mạng thần kinh trong định lượng tiền kỹ thuật số.
- Xác định số lượng phân tích cơ bản trong thị trường tiền điện tử: Hãy để dữ liệu nói cho chính nó!
- Các nghiên cứu định lượng cơ bản của vòng đồng tiền - đừng tin vào những giáo viên mờ nhạt, nói khách quan về dữ liệu!
- Một công cụ thiết yếu trong lĩnh vực giao dịch định lượng - nhà phát minh mô-đun khám phá dữ liệu định lượng
- Kiểm soát mọi thứ - giới thiệu về FMZ Phiên bản mới của Terminal giao dịch (với mã nguồn TRB Arbitrage)
- Có tất cả các thông tin về FMZ phiên bản mới của giao dịch đầu cuối (được thêm mã nguồn TRB)
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (II)
- Làm thế nào để khai thác robot bán hàng không có não với một chiến lược tần số cao trong 80 dòng mã
- FMZ định lượng: Phân tích các trường hợp thiết kế nhu cầu phổ biến của thị trường tiền điện tử (II)
- Cách khai thác robot vô trí tuệ để bán bằng chiến lược tần số cao 80 dòng mã
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (I)
- FMZ định lượng: Các nhu cầu phổ biến của thị trường tiền điện tử