Erreichung einer ausgewogenen Eigenkapitalstrategie mit einer ordnungsgemäßen Ausrichtung von Long-Short-Positionen
Schriftsteller:Lydia., Erstellt: 2023-01-09 13:46:21, aktualisiert: 2023-09-20 10:13:35
Erreichung einer ausgewogenen Eigenkapitalstrategie mit einer ordnungsgemäßen Ausrichtung von Long-Short-Positionen
In dem vorherigen Artikel (https://www.fmz.com/bbs-topic/9862), führten wir Paarhandelsstrategien ein und zeigten, wie man Handelsstrategien mithilfe von Daten und mathematischer Analyse erstellt und automatisiert.
Die Balanced Equity-Strategie für Long-Short-Positionen ist eine natürliche Erweiterung der für einen Korb von Handelsobjekten anwendbaren Paarhandelsstrategie. Sie eignet sich besonders für Handelsmärkte mit vielen Varianten und Wechselbeziehungen wie digitale Währungsmärkte und Rohstoff-Futuresmärkte.
Grundprinzipien
Die lang-short-Positionen ausgeglichene Aktienstrategie besteht darin, einen Korb von Handelsziele gleichzeitig lang und kurz zu gehen. Genau wie beim Paarhandel bestimmt sie, welches Anlageziel billig ist und welches Anlageziel teuer ist. Der Unterschied besteht darin, dass die lang-short-Positionen ausgeglichenen Aktienstrategie alle Anlageziele in einem Aktien-Auswahlpool ordnet, um festzustellen, welche Anlageziele relativ billig oder teuer sind. Dann wird es die oberen n Anlageziele basierend auf der Rangliste lang gehen und die unteren n Anlageziele in der gleichen Menge (Gesamtwert der langen Positionen = Gesamtwert der kurzen Positionen) kurz gehen.
Erinnern Sie sich daran, was wir gesagt haben, dass der Paarhandel eine marktneutrale Strategie ist? Dasselbe gilt für die ausgeglichene Equity-Strategie für lange Short-Positionen, da die gleiche Menge an langen und kurzen Positionen sicherstellt, dass die Strategie marktneutral bleibt (nicht von Marktschwankungen beeinflusst). Die Strategie ist auch statistisch robust; Durch das Ranking der Anlageziele und das Halten langer Positionen können Sie Positionen auf Ihrem Ranking-Modell viele Male öffnen, nicht nur eine einmalige Risikoöffnungsposition. Sie setzen rein auf die Qualität Ihres Ranking-Schemas.
Was ist das Rangordnungsverfahren?
Das Ranking-Schema ist ein Modell, das jedem Anlageobjekt je nach erwarteter Performance Priorität zuweisen kann. Die Faktoren können Wertfaktoren, technische Indikatoren, Preismodelle oder eine Kombination aller oben genannten Faktoren sein. Zum Beispiel können Sie Dynamikindikatoren verwenden, um eine Reihe von Trendverfolgungsinvestitionszielen zu rangieren: Es wird erwartet, dass die Anlageziele mit der höchsten Dynamik weiterhin gut abschneiden und die höchste Rangliste erhalten; Das Anlageobjekt mit dem geringsten Momentum hat die schlechteste Performance und die niedrigsten Renditen.
Der Erfolg dieser Strategie hängt fast ausschließlich vom eingesetzten Ranking-System ab, d.h. Ihr Ranking-System kann das Hochleistungs-Investitionsziel von dem Niedrigleistungs-Investitionsziel trennen, um die Rendite der Strategie von Long- und Short-Positions-Investitionszielen besser zu realisieren.
Wie macht man ein Rangliste?
Wenn wir das Ranking-System ermittelt haben, hoffen wir, daraus einen Gewinn zu erzielen. Wir tun dies, indem wir die gleiche Kapitalmenge investieren, um die oberen Investitionsziele zu verlängern und die unteren Investitionsziele zu verkürzen. Dies stellt sicher, dass die Strategie nur im Verhältnis zur Qualität des Rankings Gewinne erzielt und
Nehmen wir an, dass Sie alle Anlageziele m auflisten, und Sie haben n Dollar für die Investition, und Sie wollen insgesamt 2p (wo m>2p) Positionen halten. Wenn erwartet wird, dass das Anlageobjekt Rang 1 die schlechteste Performance hat, wird erwartet, dass das Anlageobjekt Rang m die beste Performance hat:
-
Sie sortieren die Anlageobjekte wie: 1,...,p Position, gehen kurz das Anlageziel von 2/2p USD.
-
Sie sortieren die Anlageobjekte wie: m-p,...,m Position, gehen lang das Anlageziel von n/2p USD.
Anmerkung: Da der Preis des Investitionsgegenstands, der durch Preisschwankungen verursacht wird, n/2p nicht immer gleichmäßig teilt, und einige Investitionsgegenstände mit Ganzzahlen gekauft werden müssen, gibt es einige ungenaue Algorithmen, die so nah wie möglich an dieser Zahl liegen sollten.
n/2p = 100000/1000 = 100
Dies verursacht ein großes Problem für Scores mit einem Preis von mehr als 100 (wie der Rohstoff-Futures-Markt), da Sie keine Position mit einem Bruchteilpreis eröffnen können (dieses Problem existiert nicht in digitalen Währungsmärkten).
Nehmen wir ein hypothetisches Beispiel.
- Aufbau unserer Forschungsumgebung auf der FMZ Quant-Plattform
Um eine reibungslose Arbeit zu ermöglichen, müssen wir zunächst unser Forschungsumfeld aufbauen.FMZ.COM) um unsere Forschungsumgebung aufzubauen, hauptsächlich um die bequeme und schnelle API-Schnittstelle und das gut verpackte Docker-System dieser Plattform später zu nutzen.
In der offiziellen Bezeichnung der FMZ Quant-Plattform wird dieses Docker-System das Docker-System genannt.
Bitte beachten Sie meinen vorherigen Artikel über die Bereitstellung eines Dockers und eines Roboters:https://www.fmz.com/bbs-topic/9864.
Leser, die ihren eigenen Cloud-Computing-Server kaufen möchten, um Dockers zu implementieren, können sich auf diesen Artikel beziehen:https://www.fmz.com/digest-topic/5711.
Nachdem wir den Cloud-Computing-Server und das Docker-System erfolgreich bereitgestellt haben, installieren wir als nächstes das derzeit größte Artefakt von Python: Anaconda.
Um alle relevanten Programmumgebungen (Abhängigkeitsbibliotheken, Versionsmanagement usw.) zu realisieren, die in diesem Artikel erforderlich sind, ist es am einfachsten, Anaconda zu verwenden.
Für die Installationsmethode von Anaconda lesen Sie bitte den offiziellen Anleitungsbericht zu Anaconda:https://www.anaconda.com/distribution/.
In diesem Artikel werden auch numpy und pandas verwendet, zwei beliebte und wichtige Bibliotheken im Python-Wissenschaftsrechnen.
Die obige Grundlagenarbeit kann sich auch auf meine früheren Artikel beziehen, die einführen, wie man die Anaconda-Umgebung und die Numpy- und Pandas-Bibliotheken einrichtet.https://www.fmz.com/digest-topic/9863.
Wir generieren zufällige Anlageziele und zufällige Faktoren, um sie zu rangieren.
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
import scipy
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
## PROBLEM SETUP ##
# Generate stocks and a random factor value for them
stock_names = ['stock ' + str(x) for x in range(10000)]
current_factor_values = np.random.normal(0, 1, 10000)
# Generate future returns for these are dependent on our factor values
future_returns = current_factor_values + np.random.normal(0, 1, 10000)
# Put both the factor values and returns into one dataframe
data = pd.DataFrame(index = stock_names, columns=['Factor Value','Returns'])
data['Factor Value'] = current_factor_values
data['Returns'] = future_returns
# Take a look
data.head(10)
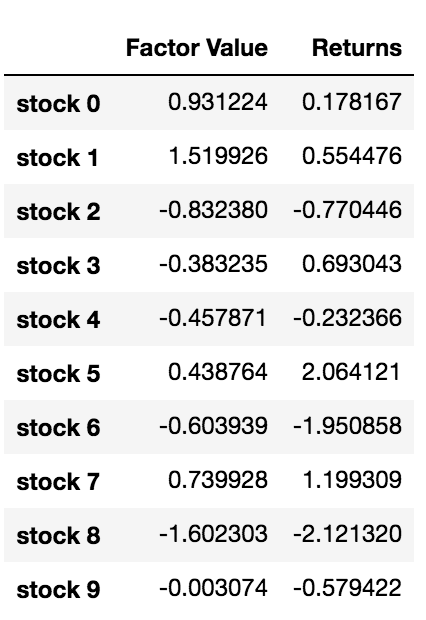
Jetzt, da wir die Faktorwerte und Renditen haben, können wir sehen, was passiert, wenn wir die Anlageziele basierend auf den Faktorwerten sortieren und dann Long- und Short-Positionen eröffnen.
# Rank stocks
ranked_data = data.sort_values('Factor Value')
# Compute the returns of each basket with a basket size 500, so total (10000/500) baskets
number_of_baskets = int(10000/500)
basket_returns = np.zeros(number_of_baskets)
for i in range(number_of_baskets):
start = i * 500
end = i * 500 + 500
basket_returns[i] = ranked_data[start:end]['Returns'].mean()
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
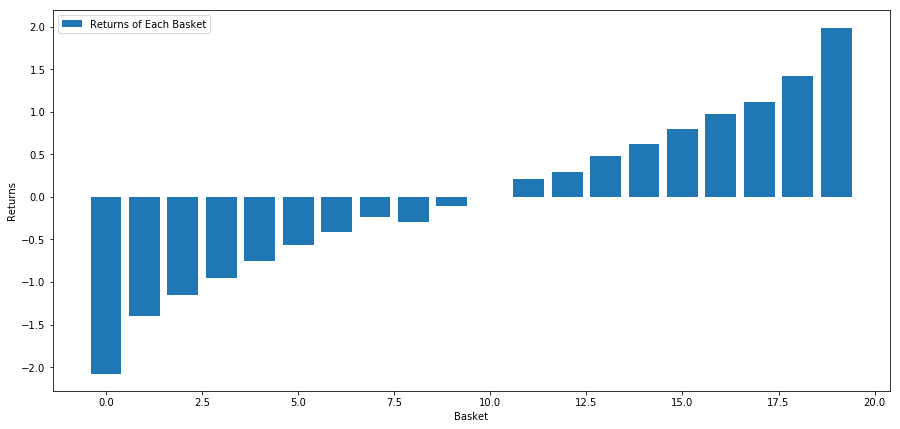
Unsere Strategie ist es, den ersten Rang des Korbes der Anlagezielpools lang zu gehen; den zehnten Rang des Korbes kurz zu gehen.
basket_returns[number_of_baskets-1] - basket_returns[0]
Das Ergebnis ist: 4.172
Setzen Sie Geld in unser Ranking-Modell, damit es Hochleistungs-Investitionsziele von Niedrigleistungs-Investitionszielen trennen kann.
Der Vorteil des rankingbasierten Arbitrages besteht darin, dass es nicht von Marktstörungen beeinflusst wird, sondern die Marktstörung verwendet werden kann.
Betrachten wir ein Beispiel aus der realen Welt.
Wir haben Daten für 32 Aktien in verschiedenen Branchen im S&P 500-Index geladen und versucht, sie zu bewerten.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2010/01/01'
endDateStr = '2017/12/31'
cachedFolderName = '/Users/chandinijain/Auquan/yahooData/'
dataSetId = 'testLongShortTrading'
instrumentIds = ['ABT','AKS','AMGN','AMD','AXP','BK','BSX',
'CMCSA','CVS','DIS','EA','EOG','GLW','HAL',
'HD','LOW','KO','LLY','MCD','MET','NEM',
'PEP','PG','M','SWN','T','TGT',
'TWX','TXN','USB','VZ','WFC']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
price = 'adjClose'
Wir verwenden den standardisierten Momentumsindikator für einen Zeitraum von einem Monat als Basis für die Rangliste.
## Define normalized momentum
def momentum(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0) / dataDf.iloc[-1]
## Load relevant prices in a dataframe
data = ds.getBookDataByFeature()['Adj Close']
#Let's load momentum score and returns into separate dataframes
index = data.index
mscores = pd.DataFrame(index=index,columns=assetList)
mscores = momentum(data, 30)
returns = pd.DataFrame(index=index,columns=assetList)
day = 30
Jetzt werden wir das Verhalten unserer Aktie analysieren und sehen, wie unsere Aktie auf dem Markt im Rankingfaktor wir wählen funktioniert.
Analyse der Daten
Verhalten der Lagerbestände
Lassen Sie uns sehen, wie unser ausgewählter Korb von Aktien in unserem Ranking-Modell funktioniert. Um dies zu tun, berechnen wir die wöchentliche Forward-Rendite für alle Aktien. Dann können wir die Korrelation zwischen der 1-Wochen-Forward-Rendite jeder Aktie und der Dynamik der vorherigen 30 Tage sehen. Die Aktien, die eine positive Korrelation zeigen, sind Trendfolger, während die Aktien, die eine negative Korrelation zeigen, durchschnittliche Umkehrungen sind.
# Calculate Forward returns
forward_return_day = 5
returns = data.shift(-forward_return_day)/data -1
returns.dropna(inplace = True)
# Calculate correlations between momentum and returns
correlations = pd.DataFrame(index = returns.columns, columns = ['Scores', 'pvalues'])
mscores = mscores[mscores.index.isin(returns.index)]
for i in correlations.index:
score, pvalue = stats.spearmanr(mscores[i], returns[i])
correlations[‘pvalues’].loc[i] = pvalue
correlations[‘Scores’].loc[i] = score
correlations.dropna(inplace = True)
correlations.sort_values('Scores', inplace=True)
l = correlations.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correlations['Scores'])
plt.xlabel('Stocks')
plt.xlim((1, l+1))
plt.xticks(range(1,1+l), correlations.index)
plt.legend(['Correlation over All Data'])
plt.ylabel('Correlation between %s day Momentum Scores and %s-day forward returns by Stock'%(day,forward_return_day));
plt.show()
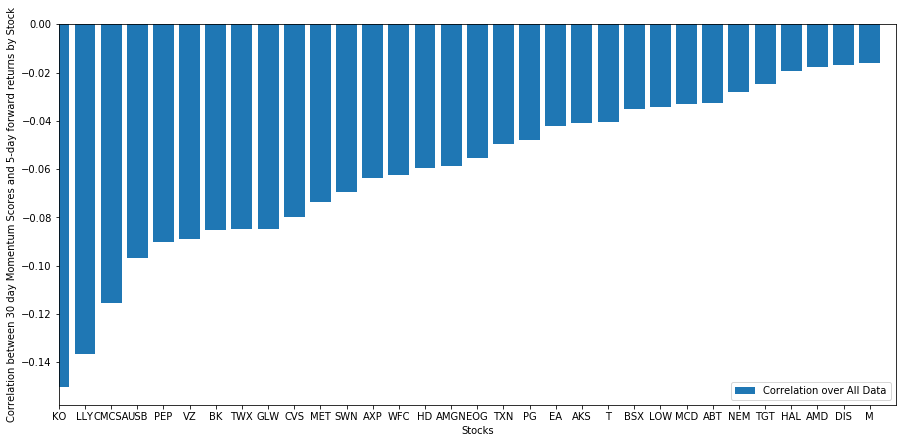
Alle unsere Aktien haben eine mittlere Umkehrung in einem gewissen Maße! (Natürlich funktioniert das Universum, das wir gewählt haben, so.) Dies sagt uns, dass, wenn Aktien in der Momentum-Analyse an der Spitze stehen, wir erwarten sollten, dass sie nächste Woche schlecht abschneiden.
Korrelation zwischen Ranking der Momentum-Analyse-Scores und Renditen
Als nächstes müssen wir die Korrelation zwischen unseren Ranking-Scores und den allgemeinen Zukunftsrenditen des Marktes sehen, d.h. die Beziehung zwischen der prognostizierten Rendite und unserem Ranking-Faktor. Kann ein höheres Korrelationsniveau eine niedrigere relative Rendite vorhersagen oder umgekehrt?
Zu diesem Zweck berechnen wir die tägliche Korrelation zwischen der 30-Tage-Dynamik aller Aktien und der 1-Wochen-Foreward-Rendite.
correl_scores = pd.DataFrame(index = returns.index.intersection(mscores.index), columns = ['Scores', 'pvalues'])
for i in correl_scores.index:
score, pvalue = stats.spearmanr(mscores.loc[i], returns.loc[i])
correl_scores['pvalues'].loc[i] = pvalue
correl_scores['Scores'].loc[i] = score
correl_scores.dropna(inplace = True)
l = correl_scores.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correl_scores['Scores'])
plt.hlines(np.mean(correl_scores['Scores']), 1,l+1, colors='r', linestyles='dashed')
plt.xlabel('Day')
plt.xlim((1, l+1))
plt.legend(['Mean Correlation over All Data', 'Daily Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
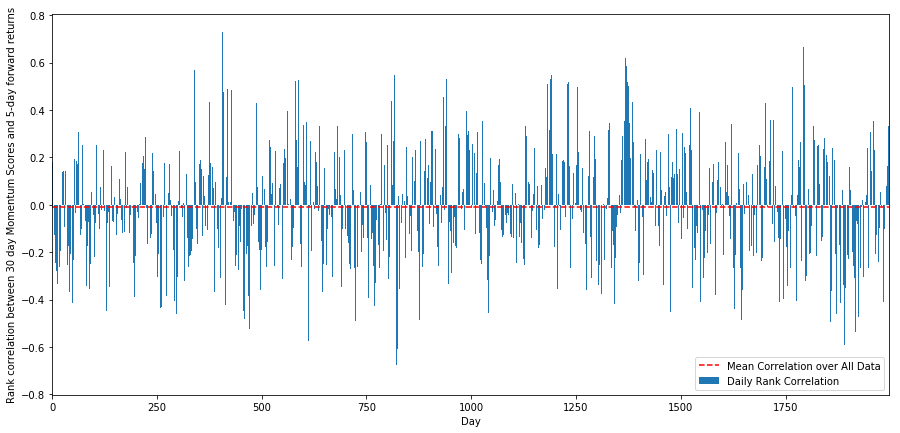
Die täglichen Korrelationen zeigen eine sehr komplexe, aber sehr leichte Korrelation (die erwartet wird, da wir gesagt haben, dass alle Aktien zum Mittel zurückkehren werden).
monthly_mean_correl =correl_scores['Scores'].astype(float).resample('M').mean()
plt.figure(figsize=(15,7))
plt.bar(range(1,len(monthly_mean_correl)+1), monthly_mean_correl)
plt.hlines(np.mean(monthly_mean_correl), 1,len(monthly_mean_correl)+1, colors='r', linestyles='dashed')
plt.xlabel('Month')
plt.xlim((1, len(monthly_mean_correl)+1))
plt.legend(['Mean Correlation over All Data', 'Monthly Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
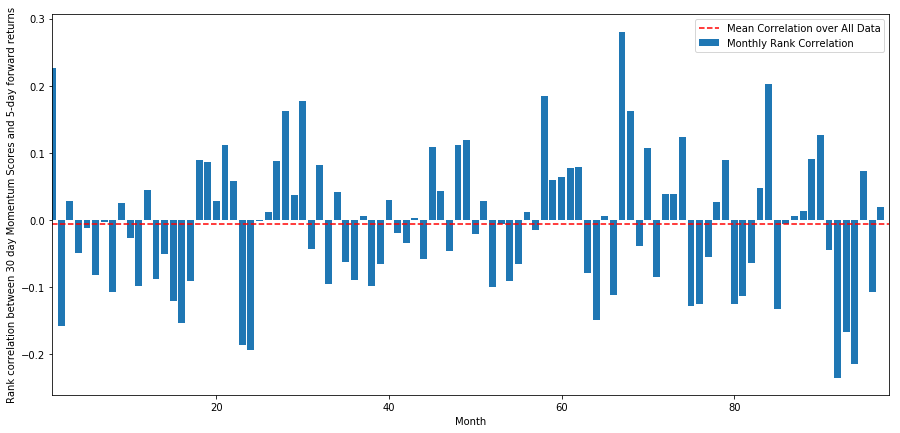
Wir können sehen, dass die durchschnittliche Korrelation wieder etwas negativ ist, aber sie ändert sich auch jeden Monat stark.
Durchschnittliche Rendite eines Bestandskorbits
Wir haben die Rendite für einen Korb von Aktien berechnet, die aus unserem Ranking stammen. Wenn wir alle Aktien sortieren und in nn Gruppen aufteilen, was ist die durchschnittliche Rendite jeder Gruppe?
Der erste Schritt besteht darin, eine Funktion zu erstellen, die die durchschnittliche Rendite und den Ranking-Faktor für jeden jeden Monat gibt.
def compute_basket_returns(factor, forward_returns, number_of_baskets, index):
data = pd.concat([factor.loc[index],forward_returns.loc[index]], axis=1)
# Rank the equities on the factor values
data.columns = ['Factor Value', 'Forward Returns']
data.sort_values('Factor Value', inplace=True)
# How many equities per basket
equities_per_basket = np.floor(len(data.index) / number_of_baskets)
basket_returns = np.zeros(number_of_baskets)
# Compute the returns of each basket
for i in range(number_of_baskets):
start = i * equities_per_basket
if i == number_of_baskets - 1:
# Handle having a few extra in the last basket when our number of equities doesn't divide well
end = len(data.index) - 1
else:
end = i * equities_per_basket + equities_per_basket
# Actually compute the mean returns for each basket
#s = data.index.iloc[start]
#e = data.index.iloc[end]
basket_returns[i] = data.iloc[int(start):int(end)]['Forward Returns'].mean()
return basket_returns
Wenn wir Aktien auf der Grundlage dieser Punktzahl bewerten, berechnen wir die durchschnittliche Rendite jedes Korbs. Dies sollte uns erlauben, ihre Beziehung für eine lange Zeit zu verstehen.
number_of_baskets = 8
mean_basket_returns = np.zeros(number_of_baskets)
resampled_scores = mscores.astype(float).resample('2D').last()
resampled_prices = data.astype(float).resample('2D').last()
resampled_scores.dropna(inplace=True)
resampled_prices.dropna(inplace=True)
forward_returns = resampled_prices.shift(-1)/resampled_prices -1
forward_returns.dropna(inplace = True)
for m in forward_returns.index.intersection(resampled_scores.index):
basket_returns = compute_basket_returns(resampled_scores, forward_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
mean_basket_returns /= l
print(mean_basket_returns)
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), mean_basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
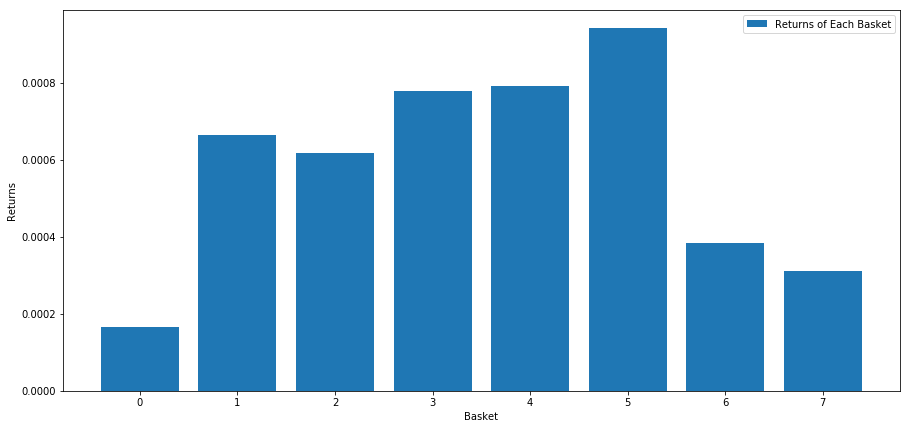
Es scheint, dass wir die Hochleistenden von den Niedrigen trennen können.
Konsistenz der Marge (Basis)
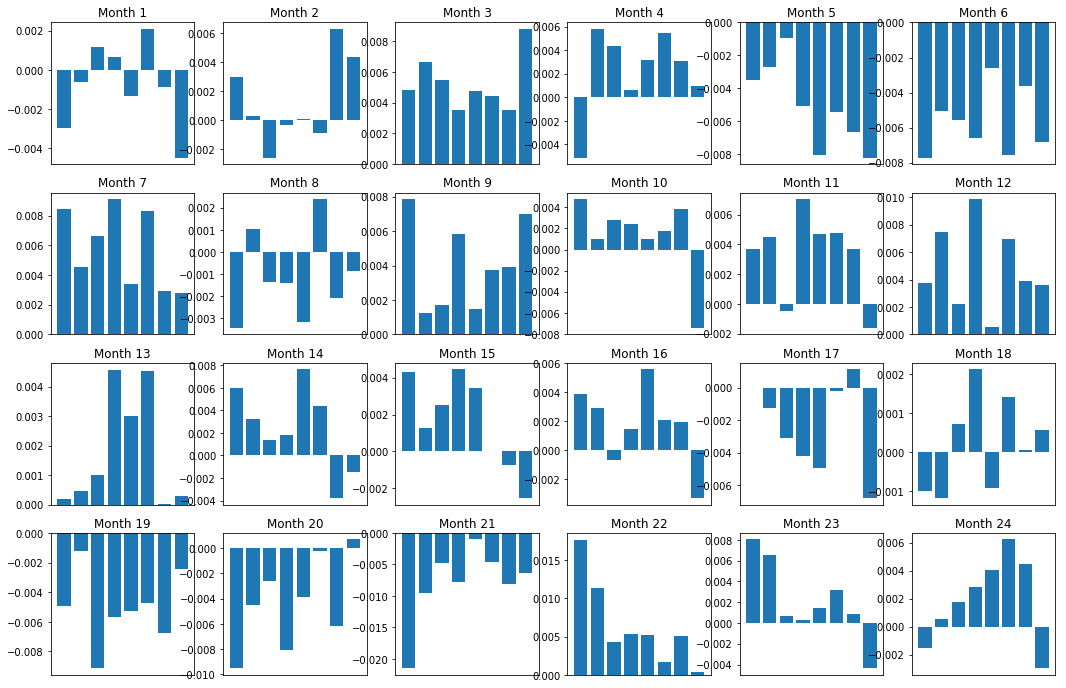
Natürlich sind dies nur durchschnittliche Beziehungen. Um zu verstehen, wie konsistent die Beziehung ist und ob wir bereit sind, zu handeln, sollten wir unseren Ansatz und unsere Einstellung dazu im Laufe der Zeit ändern. Als nächstes werden wir ihre monatliche Zinsmarge (Basis) für die letzten zwei Jahre betrachten. Wir können mehr Veränderungen sehen und weitere Analysen durchführen, um festzustellen, ob dieser Momentum-Score gehandelt werden kann.
total_months = mscores.resample('M').last().index
months_to_plot = 24
monthly_index = total_months[:months_to_plot+1]
mean_basket_returns = np.zeros(number_of_baskets)
strategy_returns = pd.Series(index = monthly_index)
f, axarr = plt.subplots(1+int(monthly_index.size/6), 6,figsize=(18, 15))
for month in range(1, monthly_index.size):
temp_returns = forward_returns.loc[monthly_index[month-1]:monthly_index[month]]
temp_scores = resampled_scores.loc[monthly_index[month-1]:monthly_index[month]]
for m in temp_returns.index.intersection(temp_scores.index):
basket_returns = compute_basket_returns(temp_scores, temp_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
strategy_returns[monthly_index[month-1]] = mean_basket_returns[ number_of_baskets-1] - mean_basket_returns[0]
mean_basket_returns /= temp_returns.index.intersection(temp_scores.index).size
r = int(np.floor((month-1) / 6))
c = (month-1) % 6
axarr[r, c].bar(range(number_of_baskets), mean_basket_returns)
axarr[r, c].xaxis.set_visible(False)
axarr[r, c].set_title('Month ' + str(month))
plt.show()
plt.figure(figsize=(15,7))
plt.plot(strategy_returns)
plt.ylabel('Returns')
plt.xlabel('Month')
plt.plot(strategy_returns.cumsum())
plt.legend(['Monthly Strategy Returns', 'Cumulative Strategy Returns'])
plt.show()
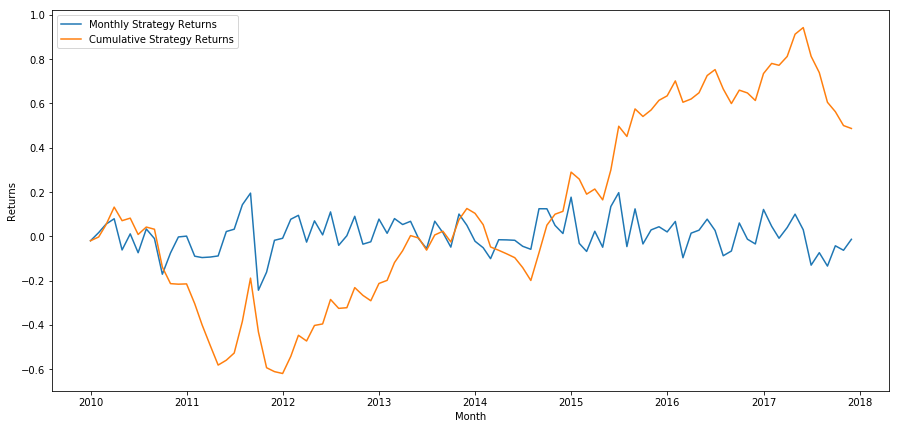
Schließlich, wenn wir den letzten Korb lang gehen und den ersten Korb jeden Monat kurz gehen, dann schauen wir uns die Renditen an (vorausgesetzt gleiche Kapitalzuweisung pro Wertpapier).
total_return = strategy_returns.sum()
ann_return = 100*((1 + total_return)**(12.0 /float(strategy_returns.index.size))-1)
print('Annual Returns: %.2f%%'%ann_return)
Jahresrendite: 5,03%
Wir können sehen, daß wir ein sehr schwaches Ranking-System haben, das nur sanft zwischen leistungsstarken und leistungsschwachen Aktien unterscheiden kann.
Finden Sie das richtige Rangordnungssystem
Um die lang-kurze ausgeglichene Aktienstrategie zu realisieren, müssen Sie eigentlich nur das Ranking-Schema bestimmen. Alles danach ist mechanisch. Sobald Sie eine lang-kurze ausgeglichene Aktienstrategie haben, können Sie ohne große Veränderungen verschiedene Ranking-Faktoren austauschen. Es ist eine sehr bequeme Möglichkeit, Ihre Ideen schnell zu iterieren, ohne sich jedes Mal um die Anpassung des gesamten Codes zu kümmern.
Das Ranking-Schema kann auch von fast jedem Modell stammen. Es ist nicht unbedingt ein wertbasiertes Faktormodell. Es kann eine maschinelle Lerntechnologie sein, die die Renditen einen Monat im Voraus vorhersagen und entsprechend diesem Niveau rangieren kann.
Auswahl und Bewertung des Rangordnungssystems
Das Ranking-System ist der Vorteil und der wichtigste Teil der lang-kurzfristigen ausgewogenen Aktienstrategie.
Ein guter Ausgangspunkt ist die Auswahl bestehender, bekannter Technologien und der Versuch, sie leicht zu modifizieren, um höhere Renditen zu erzielen.
-
Klonen und Anpassen: Wählen Sie ein Thema aus, das oft diskutiert wird, und sehen Sie, ob Sie es leicht ändern können, um Vorteile zu erzielen. Im Allgemeinen haben die öffentlich verfügbaren Faktoren keine Handelssignale mehr, weil sie vollständig aus dem Markt ausgestiegen sind. Aber manchmal führen sie Sie in die richtige Richtung.
-
Preismodell: Jedes Modell, das zukünftige Renditen vorhersagt, kann ein Faktor sein, der möglicherweise verwendet werden kann, um Ihren Warenkorb zu bewerten.
-
Preisbasierte Faktoren (technische Indikatoren): Preisbasierte Faktoren, wie heute diskutiert, erhalten Informationen über den historischen Preis jeder Aktie und verwenden sie, um Faktorwerte zu generieren.
-
Regression und Dynamik: Es ist erwähnenswert, dass einige Faktoren glauben, dass sich die Preise in eine Richtung bewegen, während einige Faktoren genau das Gegenteil sind. Beide sind effektive Modelle für verschiedene Zeithorizonte und Vermögenswerte, und es ist wichtig zu untersuchen, ob das grundlegende Verhalten auf Dynamik oder Regression basiert.
-
Basisfaktor (wertbasiert): Dies ist eine Kombination von Grundwerten wie PE, Dividenden usw. Der Basiswert enthält Informationen über die realen Fakten des Unternehmens, so dass er in vielen Aspekten stärker sein kann als der Preis.
Letztendlich ist der Entwicklungsvorhersager ein Wettrüsten, und Sie versuchen, einen Schritt voraus zu bleiben. Faktoren werden von dem Markt arbitragiert werden und haben eine Nutzungsdauer, so müssen Sie ständig arbeiten, um festzustellen, wie viele Rezessionen Ihre Faktoren erlebt haben und welche neuen Faktoren verwendet werden können, um sie zu ersetzen.
Weitere Erwägungen
- Häufigkeit der Neubalancierung
Jedes Ranking-System prognostiziert Renditen in einem etwas unterschiedlichen Zeitrahmen. Die durchschnittliche Regression basierend auf dem Preis kann in wenigen Tagen vorhersehbar sein, während das Faktormodell basierend auf dem Wert in wenigen Monaten vorausschauend sein kann. Es ist wichtig, den Zeitrahmen zu bestimmen, den das Modell vorhersagen sollte, und vor der Ausführung der Strategie eine statistische Überprüfung durchzuführen. Natürlich möchten Sie nicht überanpassen, indem Sie versuchen, die Re-Balance-Frequenz zu optimieren. Sie werden unweigerlich eine zufällige Frequenz finden, die besser ist als andere Frequenzen. Sobald Sie den Zeitrahmen der Ranking-Schema-Vorhersage bestimmt haben, versuchen Sie, bei ungefähr dieser Frequenz wieder auszugleichen, um Ihr Modell voll auszunutzen.
- Kapitalkapazität und Transaktionskosten
Jede Strategie hat ein Mindest- und ein Höchstkapitalvolumen, wobei der Mindestschwellenwert in der Regel durch die Transaktionskosten bestimmt wird.
Der Handel mit zu vielen Aktien führt zu hohen Transaktionskosten. Wenn Sie 1.000 Aktien kaufen möchten, kostet es Tausende von Dollar bei jeder Neuausgewogenheit. Ihre Kapitalbasis muss hoch genug sein, damit die Transaktionskosten einen kleinen Teil der Rendite ausmachen können, die Ihre Strategie erzeugt. Zum Beispiel, wenn Ihr Kapital 100.000 USD beträgt und Ihre Strategie monatlich 1% ($ 1.000) verdient, werden alle diese Renditen von Transaktionskosten verbraucht. Sie müssen die Strategie mit Millionen von Dollar Kapital laufen lassen, um mehr als 1.000 Aktien zu verdienen.
Die niedrigste Vermögensschwelle hängt hauptsächlich von der Anzahl der gehandelten Aktien ab. Die maximale Kapazität ist jedoch auch sehr hoch. Die lang-kurze ausgewogene Aktienstrategie kann Hunderte von Millionen Dollar handeln, ohne den Vorteil zu verlieren. Dies ist eine Tatsache, da diese Strategie relativ selten wieder ausgeglichen wird. Der Dollarwert jeder Aktie wird sehr niedrig sein, wenn die Gesamtvermögenswerte durch die Anzahl der gehandelten Aktien geteilt werden. Sie müssen sich nicht darum kümmern, ob Ihr Handelsvolumen den Markt beeinflusst. Angenommen, Sie handeln mit 1.000 Aktien, dh 100.000.000 Dollar. Wenn Sie das gesamte Portfolio jeden Monat wieder ausgleichen, wird jede Aktie nur 100.000 Dollar pro Monat handeln, was für die meisten Wertpapiere nicht ausreicht, um ein wichtiger Markt zu sein.
- Quantifizierung der Fundamentalanalyse auf dem Kryptowährungsmarkt: Die Daten sprechen für sich!
- Die Quantifizierung der Kernforschung der Münzkreise - nicht mehr auf alle Arten von Lehrern zu vertrauen, die überzeugt sind, dass die Daten objektiv sind!
- Ein wichtiges Werkzeug im Bereich der Quantitative Transaktionen - der Erfinder der Quantitative Data Exploration Module
- Mastering Everything - Einführung in FMZ Neue Version des Handelsterminals (mit TRB Arbitrage Source Code)
- Die neue Version des FMZ-Trading-Terminals ist verfügbar.
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (II)
- Wie man Hirnlose Verkaufs-Bots mit einer Hochfrequenz-Strategie in 80 Codezeilen ausnutzt
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt (II)
- Wie man Hirnlose Roboter ausbeuten und verkaufen kann mit einer 80-Zeilen-code-Hochfrequenz-Strategie
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (I)
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt