Comercio de pares basado en tecnología basada en datos
El autor:- ¿ Por qué?, Creado: 2023-01-05 09:10:25, Actualizado: 2023-09-20 09:42:28
Comercio de pares basado en tecnología basada en datos
El comercio de pares es un buen ejemplo de la formulación de estrategias comerciales basadas en el análisis matemático.
Principios básicos
Supongamos que tienes un par de objetivos de inversión X y Y que tienen algunas conexiones potenciales. Por ejemplo, dos compañías producen los mismos productos, como Pepsi Cola y Coca Cola. Quieres que la relación de precios o los diferenciales de base (también conocidos como diferencia de precios) de los dos permanezcan sin cambios a lo largo del tiempo. Sin embargo, debido a los cambios temporales en la oferta y la demanda, como una gran orden de compra / venta de un objetivo de inversión, y la reacción a las noticias importantes de una de las compañías, la diferencia de precios entre los dos pares puede ser diferente de vez en cuando. En este caso, un objeto de inversión se mueve hacia arriba mientras que el otro se mueve hacia abajo en relación con el otro. Si quieres que este desacuerdo vuelva a la normalidad con el tiempo, puedes encontrar oportunidades de negociación (o oportunidades de arbitraje).
Cuando hay una diferencia de precio temporal, usted venderá el objeto de inversión con un excelente rendimiento (el objeto de inversión en aumento) y comprará el objeto de inversión con un mal rendimiento (el objeto de inversión en caída). Usted está seguro de que el margen de interés entre los dos objetos de inversión eventualmente caerá a través de la caída del objeto de inversión con un excelente rendimiento o el aumento del objeto de inversión con un mal rendimiento, o ambos. Su transacción ganará dinero en todas estas situaciones similares. Si los objetos de inversión se mueven hacia arriba o hacia abajo juntos sin cambiar la diferencia de precio entre ellos, no ganará ni perderá dinero.
Por lo tanto, el comercio de pares es una estrategia de negociación neutral en el mercado, que permite a los operadores beneficiarse de casi todas las condiciones del mercado: tendencia al alza, tendencia a la baja o consolidación horizontal.
Explicar el concepto: dos objetivos de inversión hipotéticos
- Construir nuestro entorno de investigación en la plataforma FMZ Quant
En primer lugar, para trabajar sin problemas, necesitamos construir nuestro entorno de investigación.FMZ.COM) para construir nuestro entorno de investigación, principalmente para utilizar la interfaz API conveniente y rápida y el sistema Docker bien empaquetado de esta plataforma más adelante.
En el nombre oficial de la plataforma FMZ Quant, este sistema Docker se llama sistema Docker.
Por favor, consulte mi artículo anterior sobre cómo desplegar un docker y robot:https://www.fmz.com/bbs-topic/9864.
Los lectores que quieran comprar su propio servidor de computación en la nube para implementar dockers pueden consultar este artículo:https://www.fmz.com/digest-topic/5711.
Después de desplegar el servidor de computación en la nube y el sistema de docker con éxito, a continuación instalaremos el artefacto más grande de Python: Anaconda
Para realizar todos los entornos de programa relevantes (bibliotecas de dependencias, gestión de versiones, etc.) requeridos en este artículo, la forma más simple es usar Anaconda.
Para el método de instalación de Anaconda, consulte la guía oficial de Anaconda:https://www.anaconda.com/distribution/.
Este artículo también utilizará numpy y pandas, dos bibliotecas populares e importantes en computación científica de Python.
El trabajo básico anterior también puede referirse a mis artículos anteriores, que introducen cómo configurar el entorno Anaconda y las bibliotecas numpy y pandas.https://www.fmz.com/bbs-topic/9863.
A continuación, vamos a utilizar el código para implementar un
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
Sí, también usaremos matplotlib, una biblioteca de gráficos muy famosa en Python.
Vamos a generar un objetivo de inversión hipotético X, y simular y trazar su rendimiento diario a través de la distribución normal.
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
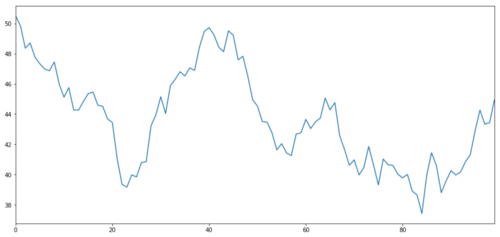
La X del objeto de inversión se simula para trazar su rendimiento diario mediante una distribución normal
Ahora generamos Y, que está fuertemente integrado con X, por lo que el precio de Y debe ser muy similar al cambio de X. Modela esto tomando X, moviéndolo hacia arriba y añadiendo un poco de ruido aleatorio extraído de la distribución normal.
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
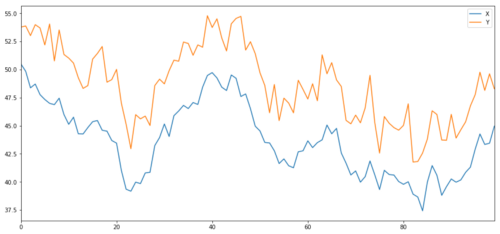
X y Y del objeto de inversión de cointegración
Cointegración
La cointegración es muy similar a la correlación, lo que significa que la relación entre dos series de datos cambiará cerca del valor promedio.
Y =
Donde
Para los pares que operan entre dos series de tiempo, el valor esperado de la relación a lo largo del tiempo debe converger al valor medio, es decir, deben ser cointegrados.
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
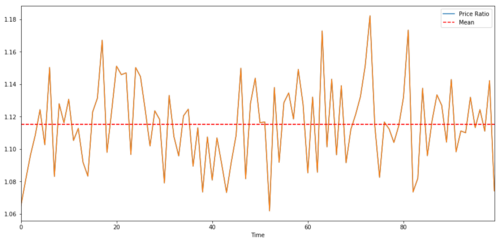
Relación y valor medio entre dos precios objetivo de inversión cointegrados
Prueba de cointegración
Un método de prueba conveniente es usar statsmodels.tsa.stattools. Veremos un valor de p muy bajo, porque creamos dos series de datos artificialmente que están tan co-integradas como sea posible.
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
El resultado es: 1.81864477307e-17
Nota: correlación y cointegración
La correlación y la cointegración, aunque similares en teoría, no son lo mismo. Veamos ejemplos de series de datos relevantes pero no cointegradas y viceversa. Primero, comprobemos la correlación de las series que acabamos de generar.
X.corr(Y)
El resultado es: 0,951.
Como esperábamos, esto es muy alto. ¿Pero qué pasa con dos series relacionadas pero no co-integradas?
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
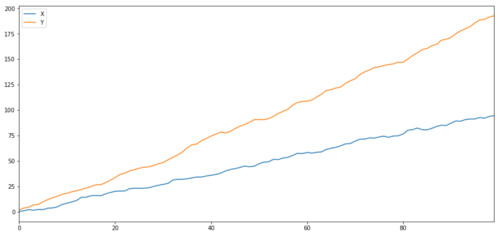
Dos series relacionadas (no integradas entre sí)
Coeficiente de correlación: 0,998 Valor P del ensayo de cointegración: 0,258
Ejemplos simples de cointegración sin correlación son las secuencias de distribución normal y las ondas cuadradas.
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
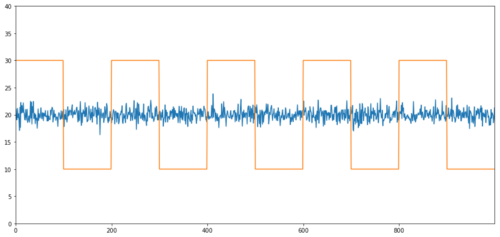
Correlación: 0,007546 Valor P del ensayo de cointegración: 0,0
La correlación es muy baja, pero el valor de p muestra una perfecta co-integración!
¿Cómo realizar el comercio de pares?
Debido a que dos series temporales cointegradas (como X y Y arriba) se enfrentan y se desvían entre sí, a veces los spreads básicos son altos o bajos. Llevamos a cabo el comercio de pares comprando un objeto de inversión y vendiendo otro. De esta manera, si los dos objetivos de inversión caen o aumentan juntos, no ganaremos ni perderemos dinero, es decir, somos neutrales en el mercado.
Volviendo a lo anterior, X y Y en Y =
-
En el ejemplo anterior, abrimos la posición al ir largo Y y ir corto X.
-
En el ejemplo anterior, abrimos la posición al acortar Y e ir largo X.
Tenga en cuenta que siempre tenemos una posición de cobertura: si el sujeto de negociación compra valor de pérdida, la posición corta hará dinero, y viceversa, por lo que somos inmunes a la tendencia general del mercado.
Si la X y Y del objeto de negociación se mueven en relación entre sí, vamos a ganar dinero o perder dinero.
Usar datos para encontrar objetos comerciales con un comportamiento similar
La mejor manera de hacerlo es comenzar con el sujeto de negociación que usted sospecha que puede ser la cointegración y realizar una prueba estadística.sesgo de comparación múltiple.
Parcialidad de las comparaciones múltiplesse refiere a la mayor probabilidad de generar incorrectamente valores p importantes al ejecutar muchas pruebas, porque necesitamos ejecutar un gran número de pruebas. Si ejecutamos 100 pruebas en datos aleatorios, deberíamos ver 5 valores p por debajo de 0.05. Si desea comparar n objetivos comerciales para la cointegración, realizará n (n-1) / 2 comparaciones, y verá muchos valores p incorrectos, que aumentarán con el aumento de sus muestras de prueba. Para evitar esta situación, seleccione unos pocos pares comerciales y tenga razón para determinar que pueden ser cointegración, y luego pruebe por separado. Esto reducirá en gran medidasesgo de comparación múltiple.
Por lo tanto, vamos a tratar de encontrar algunos objetivos de negociación que muestran la co-integración. Tomemos una cesta de grandes acciones de tecnología de EE.UU. en el índice S&P 500 como ejemplo. Estos objetivos de negociación operan en segmentos de mercado similares y tienen precios de co-integración.
La matriz de puntuación de la prueba de cointegración devuelta, la matriz de valor p y todos los pares con valor p inferior a 0,05.Este método es propenso a múltiples sesgos de comparación, por lo que, de hecho, necesitan llevar a cabo una segunda verificación.En este artículo, por conveniencia de nuestra explicación, elegimos ignorar este punto del ejemplo.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
Nota: Hemos incluido el índice de referencia de mercado (SPX) en los datos - el mercado ha impulsado el flujo de muchos objetos comerciales. Por lo general, puede encontrar dos objetos comerciales que parecen estar cointegrados; Pero de hecho, no se cointegran entre sí, sino con el mercado. Esto se llama una variable de confusión. Es importante verificar la participación del mercado en cualquier relación que encuentre.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

Ahora vamos a tratar de utilizar nuestro método para encontrar pares comerciales cointegrados.
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
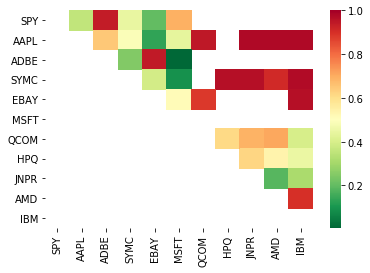
Parece que
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
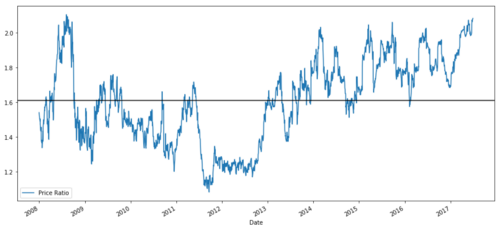
En este sentido, la Comisión concluye que la medida no constituye una ayuda estatal.
Esta proporción parece un promedio estable. Las proporciones absolutas no son estadísticamente útiles. Es más útil estandarizar nuestras señales tratandolas como puntaje Z. La puntuación Z se define como:
Puntuación Z (valor) = (valor
Advertencia
De hecho, por lo general tratamos de ampliar los datos en la premisa de que los datos están distribuidos normalmente. Sin embargo, muchos datos financieros no están distribuidos normalmente, por lo que debemos tener mucho cuidado de no simplemente asumir la normalidad o cualquier distribución específica al generar estadísticas. La verdadera distribución de las proporciones puede tener un efecto de cola de grasa, y esos datos que tienden a ser extremos confundirán nuestro modelo y conducirán a enormes pérdidas.
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
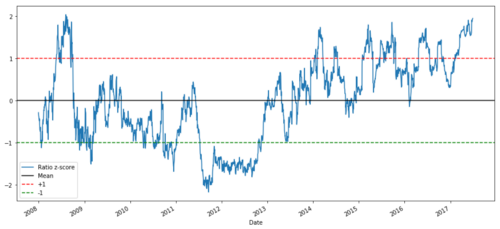
La relación de precios Z entre MSFT y ADBE desde 2008 hasta 2017
Ahora es más fácil observar el movimiento de la relación cerca del valor medio, pero a veces es fácil tener una gran diferencia del valor medio.
Ahora que hemos discutido los conocimientos básicos de la estrategia de negociación de pares y hemos determinado el tema de la integración conjunta basada en el precio histórico, tratemos de desarrollar una señal de negociación.
-
Recopilar datos fiables y limpiarlos;
-
Crear funciones a partir de datos para identificar señales/lógica de negociación;
-
Las funciones pueden ser promedios móviles o datos de precios, correlaciones o ratios de señales más complejas, combinándolas para crear nuevas funciones;
-
Utilice estas funciones para generar señales comerciales, es decir, qué señales están comprando, vendiendo o posicionando corto para ver.
Afortunadamente, tenemos la plataforma FMZ Quant (fmz.comEn este sentido, el informe de la Comisión sobre el desarrollo de la estrategia de la Unión Europea para el desarrollo de las tecnologías de la información y de la comunicación (R & TD) (COM (90) 615 final - doc. C30183/90) ha completado para nosotros los cuatro aspectos anteriores, lo que es una gran bendición para los desarrolladores de estrategias.
En la plataforma FMZ Quant, hay interfaces encapsuladas para varios intercambios convencionales. Lo que necesitamos hacer es llamar a estas interfaces API. El resto de la lógica de implementación subyacente ha sido terminada por un equipo profesional.
Para completar la lógica y explicar el principio en este artículo, presentaremos estas lógicas subyacentes en detalle. Sin embargo, en el funcionamiento real, los lectores pueden llamar a la interfaz de la API FMZ Quant directamente para completar los cuatro aspectos anteriores.
Empecemos:
Paso 1: Prepare su pregunta
Aquí, tratamos de crear una señal para decirnos si la relación va a comprar o vender en el próximo momento, es decir, nuestra predicción variable Y:
Y = Ratio es compra (1) o venta (-1)
Y (t) = Signo (t+1)
Tenga en cuenta que no necesitamos predecir el precio objetivo real de la transacción, o incluso el valor real de la relación (aunque podemos hacerlo), sino solo la dirección de la relación en el siguiente paso.
Paso 2: Recopilar datos fiables y precisos
FMZ Quant es tu amigo! Sólo necesitas especificar el objeto de transacción a ser negociado y el origen de datos a ser utilizado, y extraerá los datos requeridos y lo limpiará para dividendos y división de objetos de transacción. Así que los datos aquí son muy limpios.
En los días de negociación de los últimos 10 años (aproximadamente 2500 puntos de datos), obtuvimos los siguientes datos utilizando Yahoo Finance: precio de apertura, precio de cierre, precio más alto, precio más bajo y volumen de negociación.
Paso 3: Dividir los datos
No se olvide este paso muy importante en la prueba de la exactitud del modelo: utilizamos los siguientes datos para la división formación/validación/prueba.
-
Formación 7 años ~ 70%
-
Prueba ~ 3 años 30%
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
Idealmente, también deberíamos hacer conjuntos de validación, pero no lo haremos por ahora.
Paso 4: Ingeniería de características
¿Cuáles pueden ser las funciones relacionadas? Queremos predecir la dirección del cambio de la relación. Hemos visto que nuestros dos objetivos comerciales están cointegrados, por lo que esta relación tiende a cambiar y regresar al valor promedio. Parece que nuestras características deben ser algunas medidas de la relación promedio, y la diferencia entre el valor actual y el valor promedio puede generar nuestra señal comercial.
Usamos las siguientes funciones:
-
Relación de la media móvil de 60 días: medición de la media móvil;
-
índice de la media móvil de 5 días: medición del valor actual de la media;
-
la desviación estándar de 60 días;
-
Puntuación Z: (5d MA - 60d MA) / 60d SD
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
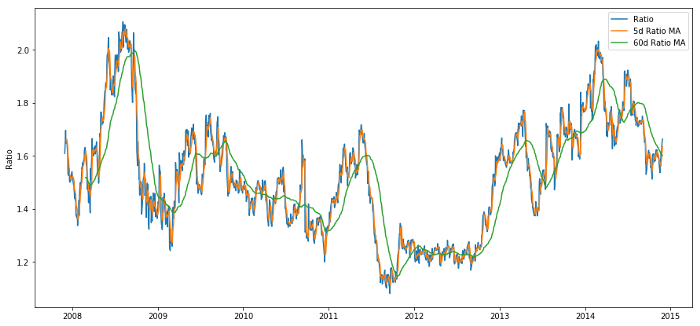
Relación de precios entre 60d y 5d MA
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
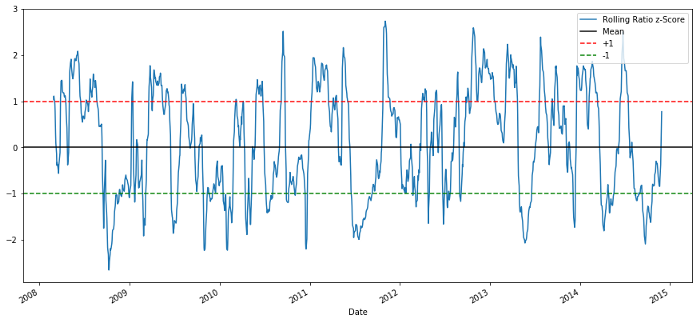
60-5 Z Indicador de las relaciones de precios
La puntuación Z del valor promedio móvil saca la propiedad de regresión de valor promedio de la relación!
Paso 5: Selección del modelo
Comencemos con un modelo muy simple. Mirando el gráfico de puntuación z, podemos ver que si la puntuación z es demasiado alta o demasiado baja, volverá. Utilicemos +1/- 1 como nuestro umbral para definir demasiado alto y demasiado bajo, y luego podemos usar el siguiente modelo para generar señales comerciales:
-
Cuando z está por debajo de - 1.0, la relación es comprar (1), porque esperamos que z regrese a 0, por lo que la relación aumenta;
-
Cuando z es superior a 1.0, la relación es vender (- 1), porque esperamos que z regrese a 0, por lo que la relación disminuye.
Paso 6: Formación, verificación y optimización
Por último, echemos un vistazo al impacto real de nuestro modelo en los datos reales.
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
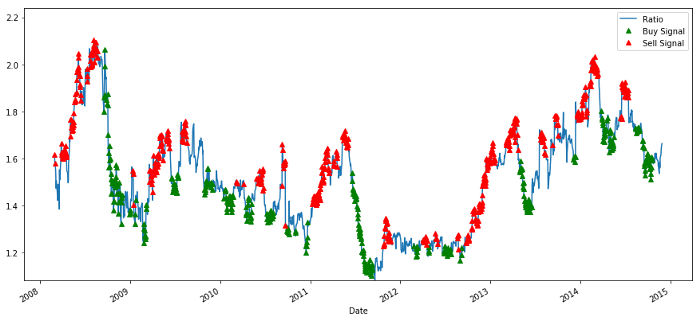
Señales de relación de precios de compra y venta
La señal parece razonable. Parece que vendemos cuando es alta o creciente (puntos rojos) y la compramos cuando es baja (puntos verdes) y disminuyendo. ¿Qué significa esto para el objeto real de nuestra transacción?
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
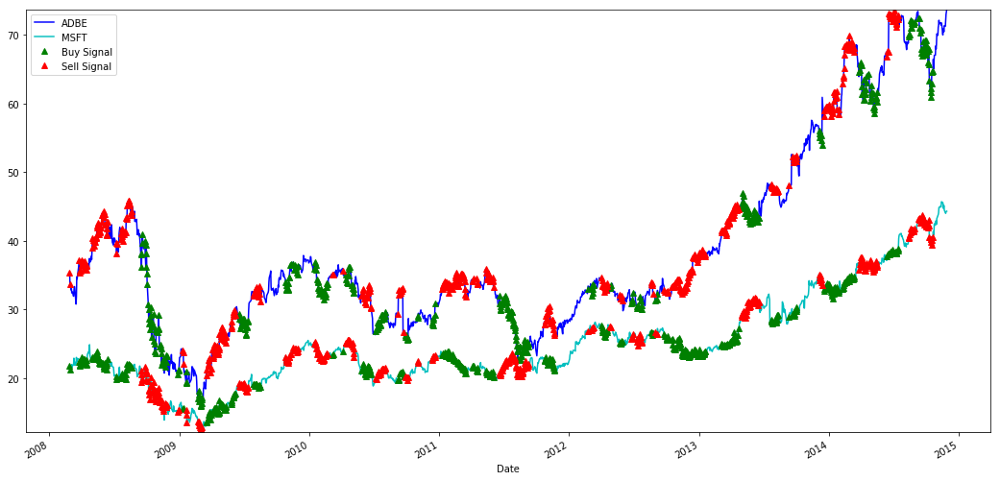
Señales para comprar y vender acciones de MSFT y ADBE
Por favor, preste atención a cómo a veces hacemos ganancias con "piernas cortas", a veces con "piernas largas", y a veces con ambas.
Estamos satisfechos con la señal de los datos de entrenamiento. Veamos qué tipo de ganancia puede generar esta señal. Cuando la relación es baja, podemos hacer una simple prueba de retroceso, comprar una relación (comprar 1 acción ADBE y vender relación x acción MSFT), y vender una relación (vender 1 acción ADBE y comprar x relación de acciones MSFT) cuando es alta, y calcular las transacciones PnL de estas relaciones.
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
El resultado es: 1783.375
Ahora, podemos optimizar aún más cambiando la ventana de tiempo promedio móvil, cambiando los umbrales de compra / venta y posiciones cerradas, y comprobar la mejora del rendimiento de los datos de validación.
También podemos probar modelos más complejos, como la regresión logística y SVM, para predecir 1/-1.
Ahora, vamos a avanzar este modelo, que nos lleva a:
Paso 7: Prueba posterior de los datos de ensayo
Aquí también, la plataforma FMZ Quant adopta un motor de backtesting QPS / TPS de alto rendimiento para reproducir el entorno histórico verdaderamente, eliminar las trampas comunes de backtesting cuantitativo y descubrir las deficiencias de las estrategias a tiempo, para ayudar mejor a la inversión real de bots.
Para explicar el principio, este artículo todavía elige mostrar la lógica subyacente. En la aplicación práctica, recomendamos a los lectores que usen la plataforma FMZ Quant. Además de ahorrar tiempo, es importante mejorar la tasa de tolerancia a fallos.
El backtesting es simple. Podemos usar la función anterior para ver el PnL de los datos de prueba.
trade(data['ADBE'].iloc[1762:], data['MSFT'].iloc[1762:], 60, 5)
El resultado es: 5262.868
Se convirtió en nuestro primer modelo simple de comercio de pares.
Evite el exceso de ajuste
Antes de concluir la discusión, me gustaría discutir sobre el sobreajuste en particular. El sobreajuste es la trampa más peligrosa en las estrategias comerciales. El algoritmo de sobreajuste puede funcionar muy bien en la prueba de retroceso, pero falla en los nuevos datos invisibles, lo que significa que realmente no revela ninguna tendencia de los datos y no tiene una capacidad de predicción real.
En nuestro modelo, utilizamos parámetros de rodaje para estimar y optimizar la longitud de la ventana de tiempo. Podemos decidir simplemente iterar sobre todas las posibilidades, una longitud de ventana de tiempo razonable, y elegir la longitud de tiempo de acuerdo con el mejor rendimiento de nuestro modelo.
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
Ahora examinamos el rendimiento del modelo en los datos de prueba, y encontramos que esta longitud de la ventana de tiempo está lejos de ser óptima! Esto se debe a que nuestra elección original claramente sobreajusta los datos de la muestra.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
Es obvio que los datos de muestra adecuados para nosotros no siempre producirán buenos resultados en el futuro.
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
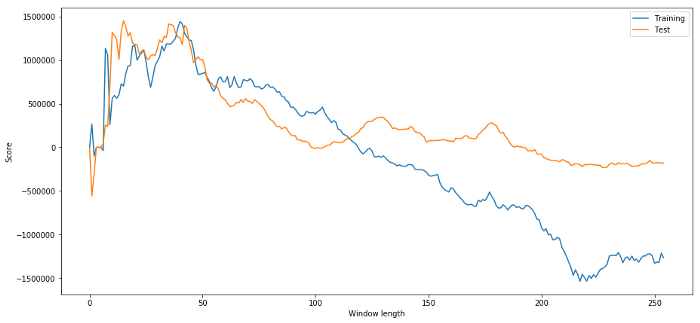
Podemos ver que cualquier cosa entre 20 y 50 es una buena opción para ventanas de tiempo.
Para evitar el sobreajuste, podemos usar el razonamiento económico o la naturaleza del algoritmo para seleccionar la longitud de la ventana de tiempo. También podemos usar el filtro de Kalman, que no requiere que especificemos la longitud; Este enfoque se describirá más adelante en otro artículo.
El siguiente paso.
En este artículo, proponemos algunos métodos de introducción simples para demostrar el proceso de desarrollo de estrategias comerciales. En la práctica, se deben utilizar estadísticas más complejas.
-
El exponente de Hurst;
-
La medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición de la medición.
-
El filtro de Kalman.
- Cuantificar el análisis fundamental en el mercado de criptomonedas: ¡Deja que los datos hablen por sí mismos!
- La investigación cuantitativa básica del círculo monetario - ¡No confíes más en los profesores de idiomas, los datos hablan objetivamente!
- Una herramienta esencial en el campo de la transacción cuantitativa - inventor de módulos de exploración de datos cuantitativos
- Dominarlo todo - Introducción a FMZ Nueva versión de la terminal de negociación (con el código fuente de TRB Arbitrage)
- Conozca todo acerca de la nueva versión del terminal de operaciones de FMZ (con código de código de TRB)
- FMZ Quant: Análisis de ejemplos de diseño de requisitos comunes en el mercado de criptomonedas (II)
- Cómo explotar robots de venta sin cerebro con una estrategia de alta frecuencia en 80 líneas de código
- Cuantificación FMZ: Desarrollo de casos de diseño de necesidades comunes en el mercado de criptomonedas (II)
- Cómo utilizar una estrategia de alta frecuencia de 80 líneas de código para explotar y vender robots sin cerebro
- FMZ Quant: Análisis de ejemplos de diseño de requisitos comunes en el mercado de criptomonedas (I)
- Cuantificación FMZ: Desarrollo de casos de diseño de necesidades comunes en el mercado de criptomonedas (1)