Достижение сбалансированной стратегии акций для длинных коротких позиций с упорядоченным согласованием
Автор:Лидия., Создано: 2023-01-09 13:46:21, Обновлено: 2023-09-20 10:13:35
Достижение сбалансированной стратегии акций для длинных коротких позиций с упорядоченным согласованием
В предыдущей статьеhttps://www.fmz.com/bbs-topic/9862), мы представили стратегии торговли парами и продемонстрировали, как создавать и автоматизировать торговые стратегии с помощью данных и математического анализа.
Стратегия сбалансированных акций для длинных и коротких позиций является естественным продолжением стратегии торговли парой, применимой к корзине торговых объектов. Она особенно подходит для торговых рынков со многими разновидностями и взаимосвязями, такими как рынки цифровой валюты и рынки товарных фьючерсов.
Основные принципы
Стратегия сбалансированного капитала для длинных коротких позиций заключается в том, чтобы одновременно удлинять и укорачивать корзину торговых целей. Точно так же, как и для торговли парами, она определяет, какая инвестиционная цель дешева, а какая инвестиционная цель дорогая. Разница заключается в том, что стратегия сбалансированного капитала для длинных коротких позиций расставит все инвестиционные цели в пул отбора акций, чтобы определить, какие инвестиционные цели относительно дешевы или дорогие. Затем она удлиняет верхние n инвестиционных целей на основе рейтинга и укорачивает нижние n инвестиционных целей в той же сумме (общая стоимость длинных позиций = общая стоимость коротких позиций).
Помните, что мы говорили, что торговля парами является нейтральной стратегией рынка? То же самое верно и для долгосрочных коротких позиций сбалансированной стратегии акций, потому что равное количество длинных и коротких позиций гарантирует, что стратегия останется нейтральной на рынке (не зависит от колебаний рынка). Стратегия также статистически надежна; путем ранжирования инвестиционных целей и удержания длинных позиций вы можете открывать позиции на своей модели ранжирования много раз, а не только один раз рискуете открыть позицию. Вы чисто делаете ставку на качество вашей схемы ранжирования.
Какова система ранжирования?
Схема ранжирования - это модель, которая может присваивать приоритет каждому инвестиционному субъекту в соответствии с ожидаемой производительностью. Факторами могут быть стоимостные факторы, технические показатели, модели ценообразования или комбинация всех вышеперечисленных факторов. Например, вы можете использовать индикаторы импульса для ранжирования серии инвестиционных целей отслеживания тенденций: ожидается, что инвестиционные цели с самым высоким импульсом будут продолжать хорошо работать и получать самый высокий рейтинг; Инвестиционный объект с наименьшим импульсом имеет худшую производительность и самые низкие доходы.
Успех этой стратегии почти полностью зависит от используемой схемы ранжирования, то есть ваша схема ранжирования может отделить высокопроизводительную инвестиционную цель от низкопроизводительной инвестиционной цели, чтобы лучше реализовать прибыль стратегии инвестиционных целей длинных и коротких позиций.
Как сделать схему ранжирования?
После того, как мы определили схему ранжирования, мы надеемся получить прибыль от нее. Мы делаем это, инвестируя одинаковую сумму капитала, чтобы продолжить первые инвестиционные цели и сократить нижние инвестиционные цели. Это гарантирует, что стратегия будет приносить прибыль только пропорционально качеству рейтинга, и она будет "рыночно нейтральной".
Предположим, что вы ранжируете все инвестиционные цели m, и у вас есть n долларов для инвестиций, и вы хотите держать в общей сложности 2p (где m>2p) позиции. Если ожидается, что рейтинг 1 инвестиционного объекта будет наихудшим, ожидается, что рейтинг m инвестиционного объекта будет лучшим:
-
Вы ранжируете инвестиционные объекты как: 1,...,p позиции, идти короткий инвестиционный целевой 2/2p USD.
-
Вы ранжируете инвестиционные объекты как: m-p,...,m позиция, идти длинный инвестиционный целевой n/2p USD.
Примечание: поскольку цена объекта инвестиций, вызванная колебаниями цен, не всегда будет равномерно делиться на n/2p, и некоторые объекты инвестиций должны быть куплены с целыми числами, будут некоторые неточные алгоритмы, которые должны быть как можно ближе к этому числу.
n/2p = 100000/1000 = 100
Это вызовет большую проблему для счетов с ценой выше 100 (например, товарный фьючерсный рынок), потому что вы не можете открыть позицию с дробной ценой (эта проблема не существует на рынках цифровой валюты).
Давайте возьмем гипотетический пример.
- Построить нашу исследовательскую среду на платформе FMZ Quant
Прежде всего, для того, чтобы работать беспрепятственно, нам необходимо создать нашу исследовательскую среду.FMZ.COM) для создания нашей исследовательской среды, в основном для использования удобного и быстрого интерфейса API и хорошо упакованной системы Docker этой платформы позже.
В официальном названии платформы FMZ Quant эта система Docker называется системой Docker.
Пожалуйста, ознакомьтесь с моей предыдущей статьей о том, как развернуть докер и робота:https://www.fmz.com/bbs-topic/9864.
Читатели, которые хотят приобрести собственный сервер облачных вычислений для развертывания докеров, могут обратиться к этой статье:https://www.fmz.com/digest-topic/5711.
После успешного развертывания сервера облачных вычислений и системы докеров, следующим мы установим самый большой артефакт Python: Anaconda.
Чтобы реализовать все соответствующие программные среды (библиотеки зависимостей, управление версиями и т. д.), необходимые в этой статье, самый простой способ - использовать Anaconda.
Для установки Anaconda, пожалуйста, обратитесь к официальному руководству Anaconda:https://www.anaconda.com/distribution/.
В этой статье также будут использованы numpy и панды, две популярные и важные библиотеки в научном вычислении Python.
Вышеуказанная основная работа также может относиться к моим предыдущим статьям, в которых представлено, как настроить среду Anaconda и библиотеки numpy и pandas.https://www.fmz.com/digest-topic/9863.
Мы генерируем случайные инвестиционные цели и случайные факторы для их ранжирования.
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
import scipy
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
## PROBLEM SETUP ##
# Generate stocks and a random factor value for them
stock_names = ['stock ' + str(x) for x in range(10000)]
current_factor_values = np.random.normal(0, 1, 10000)
# Generate future returns for these are dependent on our factor values
future_returns = current_factor_values + np.random.normal(0, 1, 10000)
# Put both the factor values and returns into one dataframe
data = pd.DataFrame(index = stock_names, columns=['Factor Value','Returns'])
data['Factor Value'] = current_factor_values
data['Returns'] = future_returns
# Take a look
data.head(10)
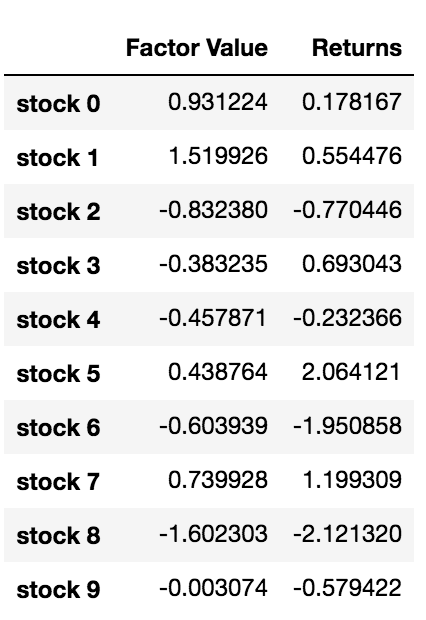
Теперь, когда у нас есть значения и доходы факторов, мы можем увидеть, что произойдет, если мы ранжируем инвестиционные цели на основе стоимости факторов, а затем открываем длинные и короткие позиции.
# Rank stocks
ranked_data = data.sort_values('Factor Value')
# Compute the returns of each basket with a basket size 500, so total (10000/500) baskets
number_of_baskets = int(10000/500)
basket_returns = np.zeros(number_of_baskets)
for i in range(number_of_baskets):
start = i * 500
end = i * 500 + 500
basket_returns[i] = ranked_data[start:end]['Returns'].mean()
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
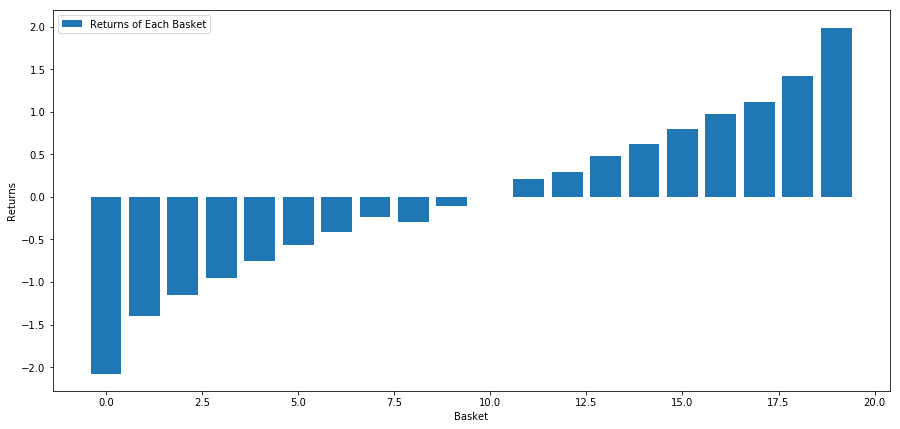
Наша стратегия заключается в том, чтобы пойти длинный первый рейтинг корзины инвестиционных целевых пулов; идти короткий десятый рейтинг корзины.
basket_returns[number_of_baskets-1] - basket_returns[0]
Результат: 4,172
Вложите деньги в нашу модель рейтинга, чтобы она могла отделить высокоэффективные инвестиционные цели от низкоэффективных инвестиционных целей.
Преимущество арбитража, основанного на рейтинге, заключается в том, что на него не влияет нарушение рынка, вместо этого можно использовать нарушение рынка.
Давайте рассмотрим реальный пример.
Мы загрузили данные 32 акций в различных отраслях в индексе S&P 500 и попытались их ранжировать.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2010/01/01'
endDateStr = '2017/12/31'
cachedFolderName = '/Users/chandinijain/Auquan/yahooData/'
dataSetId = 'testLongShortTrading'
instrumentIds = ['ABT','AKS','AMGN','AMD','AXP','BK','BSX',
'CMCSA','CVS','DIS','EA','EOG','GLW','HAL',
'HD','LOW','KO','LLY','MCD','MET','NEM',
'PEP','PG','M','SWN','T','TGT',
'TWX','TXN','USB','VZ','WFC']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
price = 'adjClose'
Давайте воспользуемся стандартизированным индикатором импульса за месячный период времени в качестве основы для ранжирования.
## Define normalized momentum
def momentum(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0) / dataDf.iloc[-1]
## Load relevant prices in a dataframe
data = ds.getBookDataByFeature()['Adj Close']
#Let's load momentum score and returns into separate dataframes
index = data.index
mscores = pd.DataFrame(index=index,columns=assetList)
mscores = momentum(data, 30)
returns = pd.DataFrame(index=index,columns=assetList)
day = 30
Теперь мы проанализируем поведение наших акций и посмотрим, как наши акции работают на рынке в рейтинговом факторе, который мы выбираем.
Анализируйте данные
Поведение запасов
Давайте посмотрим, как наша выбранная корзина акций работает в нашей модели ранжирования. Для этого давайте вычислим еженедельную форвардную доходность для всех акций. Затем мы можем увидеть корреляцию между 1-недельной форвардной доходностью каждой акции и импульсом предыдущих 30 дней. Акции, показывающие положительную корреляцию, являются последователями тренда, в то время как акции, показывающие отрицательную корреляцию, представляют собой средние перевороты.
# Calculate Forward returns
forward_return_day = 5
returns = data.shift(-forward_return_day)/data -1
returns.dropna(inplace = True)
# Calculate correlations between momentum and returns
correlations = pd.DataFrame(index = returns.columns, columns = ['Scores', 'pvalues'])
mscores = mscores[mscores.index.isin(returns.index)]
for i in correlations.index:
score, pvalue = stats.spearmanr(mscores[i], returns[i])
correlations[‘pvalues’].loc[i] = pvalue
correlations[‘Scores’].loc[i] = score
correlations.dropna(inplace = True)
correlations.sort_values('Scores', inplace=True)
l = correlations.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correlations['Scores'])
plt.xlabel('Stocks')
plt.xlim((1, l+1))
plt.xticks(range(1,1+l), correlations.index)
plt.legend(['Correlation over All Data'])
plt.ylabel('Correlation between %s day Momentum Scores and %s-day forward returns by Stock'%(day,forward_return_day));
plt.show()
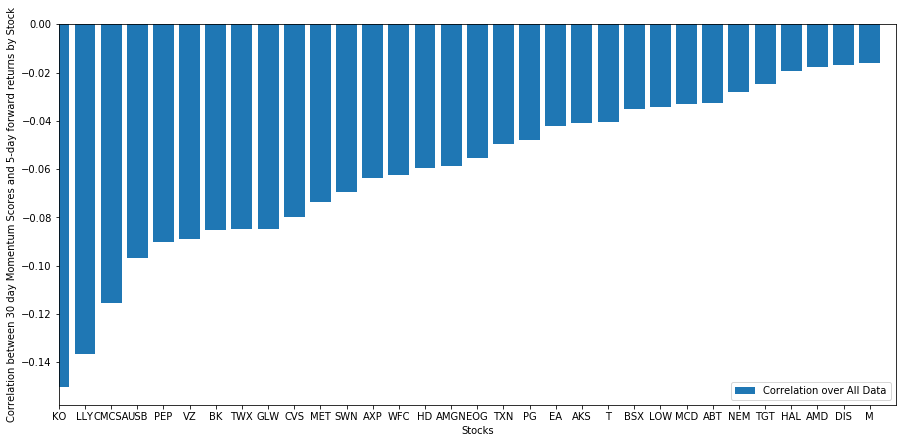
Все наши акции имеют среднюю реверсию в определенной степени! (Очевидно, вселенная, которую мы выбрали, работает так.) Это говорит нам, что если акции занимают первое место в анализе импульса, мы должны ожидать, что они будут плохо работать на следующей неделе.
Корреляция между ранжированием результатов анализа импульса и доходами
Далее, нам нужно увидеть корреляцию между нашим рейтингом и общими форвардными доходами рынка, то есть связь между прогнозируемым уровнем доходности и нашим рейтинговым фактором.
Для этого мы рассчитываем суточную корреляцию между 30-дневным импульсом всех акций и 1-недельной форвардной доходностью.
correl_scores = pd.DataFrame(index = returns.index.intersection(mscores.index), columns = ['Scores', 'pvalues'])
for i in correl_scores.index:
score, pvalue = stats.spearmanr(mscores.loc[i], returns.loc[i])
correl_scores['pvalues'].loc[i] = pvalue
correl_scores['Scores'].loc[i] = score
correl_scores.dropna(inplace = True)
l = correl_scores.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correl_scores['Scores'])
plt.hlines(np.mean(correl_scores['Scores']), 1,l+1, colors='r', linestyles='dashed')
plt.xlabel('Day')
plt.xlim((1, l+1))
plt.legend(['Mean Correlation over All Data', 'Daily Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
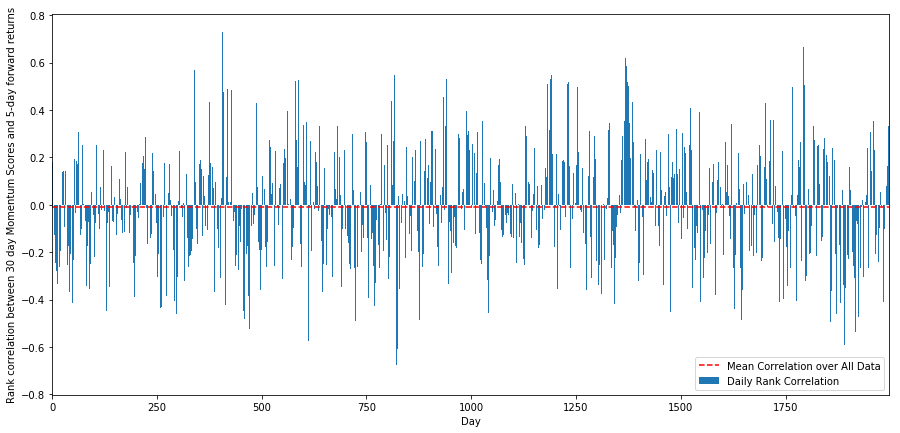
Ежедневные корреляции показывают очень сложную, но очень незначительную корреляцию (что ожидается, поскольку мы сказали, что все запасы вернутся к среднему показателю).
monthly_mean_correl =correl_scores['Scores'].astype(float).resample('M').mean()
plt.figure(figsize=(15,7))
plt.bar(range(1,len(monthly_mean_correl)+1), monthly_mean_correl)
plt.hlines(np.mean(monthly_mean_correl), 1,len(monthly_mean_correl)+1, colors='r', linestyles='dashed')
plt.xlabel('Month')
plt.xlim((1, len(monthly_mean_correl)+1))
plt.legend(['Mean Correlation over All Data', 'Monthly Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
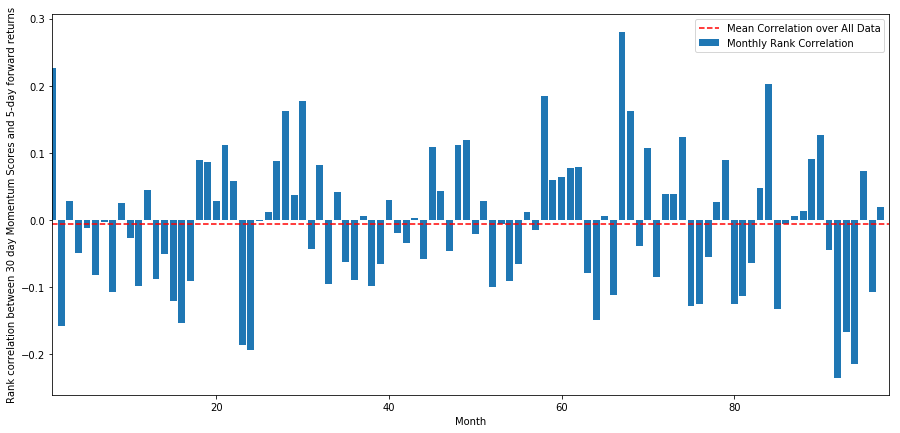
Мы видим, что средняя корреляция снова немного отрицательная, но она также сильно меняется каждый месяц.
Средняя доходность за корзину акций
Мы рассчитали доходность на корзине акций, взятых из нашего рейтинга. если мы ранжируем все акции и делим их на нн группы, какова средняя доходность каждой группы?
Первый шаг - создать функцию, которая даст средний показатель доходности и коэффициент ранжирования каждой корзины, данной каждый месяц.
def compute_basket_returns(factor, forward_returns, number_of_baskets, index):
data = pd.concat([factor.loc[index],forward_returns.loc[index]], axis=1)
# Rank the equities on the factor values
data.columns = ['Factor Value', 'Forward Returns']
data.sort_values('Factor Value', inplace=True)
# How many equities per basket
equities_per_basket = np.floor(len(data.index) / number_of_baskets)
basket_returns = np.zeros(number_of_baskets)
# Compute the returns of each basket
for i in range(number_of_baskets):
start = i * equities_per_basket
if i == number_of_baskets - 1:
# Handle having a few extra in the last basket when our number of equities doesn't divide well
end = len(data.index) - 1
else:
end = i * equities_per_basket + equities_per_basket
# Actually compute the mean returns for each basket
#s = data.index.iloc[start]
#e = data.index.iloc[end]
basket_returns[i] = data.iloc[int(start):int(end)]['Forward Returns'].mean()
return basket_returns
Когда мы ранжируем акции по этому показателю, мы рассчитываем среднюю доходность каждой корзины. Это должно позволить нам понять их взаимосвязь в течение длительного времени.
number_of_baskets = 8
mean_basket_returns = np.zeros(number_of_baskets)
resampled_scores = mscores.astype(float).resample('2D').last()
resampled_prices = data.astype(float).resample('2D').last()
resampled_scores.dropna(inplace=True)
resampled_prices.dropna(inplace=True)
forward_returns = resampled_prices.shift(-1)/resampled_prices -1
forward_returns.dropna(inplace = True)
for m in forward_returns.index.intersection(resampled_scores.index):
basket_returns = compute_basket_returns(resampled_scores, forward_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
mean_basket_returns /= l
print(mean_basket_returns)
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), mean_basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
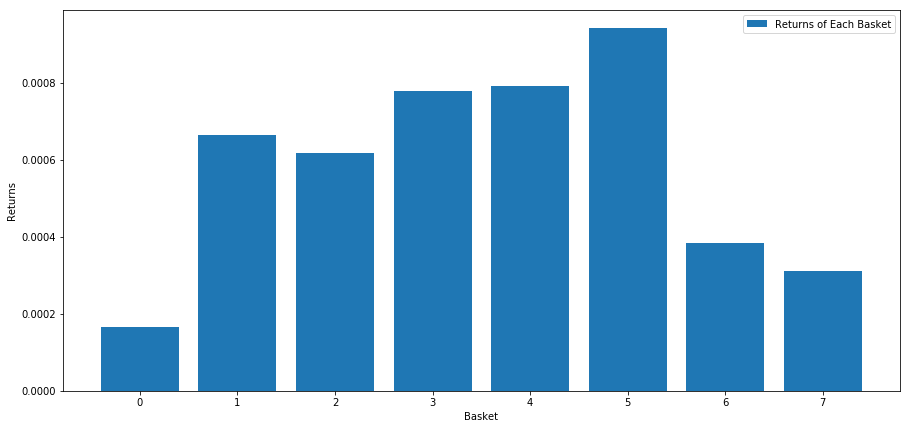
Похоже, мы можем отделить высокопроизводителей от низкопроизводителей.
Соответствие маржи (основы)
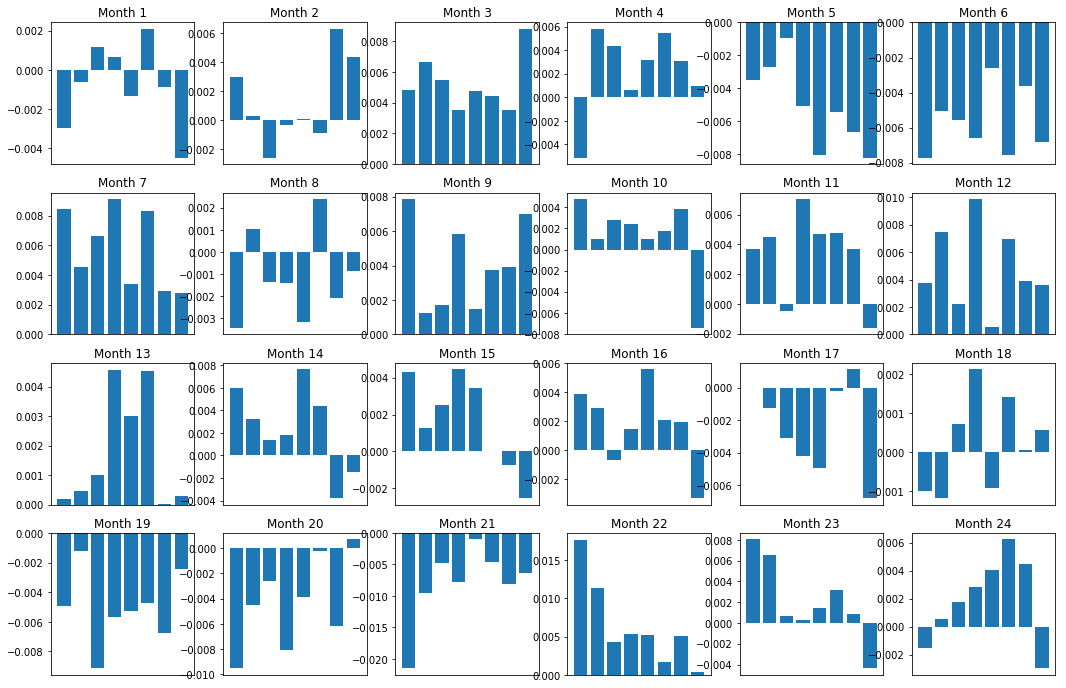
Конечно, это всего лишь средние отношения. Чтобы понять, насколько последовательны отношения и готовы ли мы торговать, мы должны со временем изменить свой подход и отношение к ним. Далее мы рассмотрим их ежемесячную процентную маржу (базу) за предыдущие два года. Мы можем увидеть больше изменений и провести дальнейший анализ, чтобы определить, можно ли торговать этим импульсом.
total_months = mscores.resample('M').last().index
months_to_plot = 24
monthly_index = total_months[:months_to_plot+1]
mean_basket_returns = np.zeros(number_of_baskets)
strategy_returns = pd.Series(index = monthly_index)
f, axarr = plt.subplots(1+int(monthly_index.size/6), 6,figsize=(18, 15))
for month in range(1, monthly_index.size):
temp_returns = forward_returns.loc[monthly_index[month-1]:monthly_index[month]]
temp_scores = resampled_scores.loc[monthly_index[month-1]:monthly_index[month]]
for m in temp_returns.index.intersection(temp_scores.index):
basket_returns = compute_basket_returns(temp_scores, temp_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
strategy_returns[monthly_index[month-1]] = mean_basket_returns[ number_of_baskets-1] - mean_basket_returns[0]
mean_basket_returns /= temp_returns.index.intersection(temp_scores.index).size
r = int(np.floor((month-1) / 6))
c = (month-1) % 6
axarr[r, c].bar(range(number_of_baskets), mean_basket_returns)
axarr[r, c].xaxis.set_visible(False)
axarr[r, c].set_title('Month ' + str(month))
plt.show()
plt.figure(figsize=(15,7))
plt.plot(strategy_returns)
plt.ylabel('Returns')
plt.xlabel('Month')
plt.plot(strategy_returns.cumsum())
plt.legend(['Monthly Strategy Returns', 'Cumulative Strategy Returns'])
plt.show()
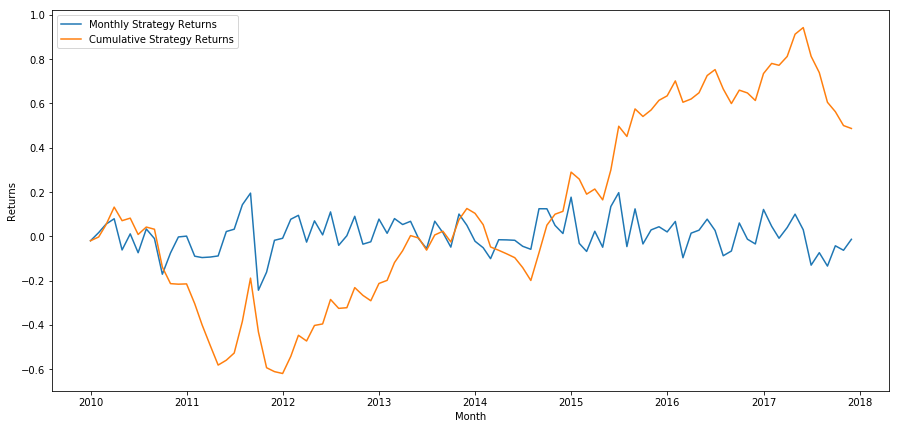
Наконец, если мы хотим продать последний кошелек и продавать первый кошелек каждый месяц, то давайте посмотрим на доходность (предполагая равное распределение капитала на ценную бумагу).
total_return = strategy_returns.sum()
ann_return = 100*((1 + total_return)**(12.0 /float(strategy_returns.index.size))-1)
print('Annual Returns: %.2f%%'%ann_return)
Годовой доход: 5,03%
Мы видим, что у нас очень слабая схема ранжирования, которая может только нежно отличать высокопроизводительные акции от низкопроизводительных акций.
Найдите правильную схему ранжирования
Чтобы реализовать долго-короткую стратегию сбалансированного капитала, на самом деле, вам нужно только определить схему ранжирования. После этого все механическое. Как только у вас есть долго-короткая стратегия сбалансированного капитала, вы можете обмениваться различными факторами ранжирования без особых изменений. Это очень удобный способ быстро повторять свои идеи, не беспокоясь о корректировке кода каждый раз.
Система рейтинга также может исходить практически из любой модели. Это не обязательно модель фактора на основе стоимости. Это может быть технология машинного обучения, которая может предсказывать доходы за месяц и ранжировать в соответствии с этим уровнем.
Выбор и оценка системы ранжирования
Система ранжирования является преимуществом и самой важной частью долгосрочной стратегии сбалансированного капитала.
Хорошей отправной точкой является выбор существующих известных технологий и посмотреть, можете ли вы их немного изменить, чтобы получить более высокую доходность.
-
Клон и корректировка: Выберите тему, которая часто обсуждается, и посмотрите, можете ли вы немного изменить ее, чтобы получить преимущества.
-
Модель ценообразования: любая модель, которая предсказывает будущие доходы, может быть фактором, который потенциально может быть использован для ранжирования вашей корзины торговых объектов.
-
Факторы, основанные на ценах (технические показатели): факторы, основанные на ценах, как обсуждалось сегодня, получают информацию об исторической цене каждой акции и используют ее для получения стоимости факторов.
-
Регрессия и импульс: Стоит отметить, что некоторые факторы считают, что, как только цены движутся в одном направлении, они будут продолжать это делать, в то время как некоторые факторы являются прямо противоположными. Оба являются эффективными моделями для разных временных горизонтов и активов, и важно изучить, основывается ли базовое поведение на импульсе или регрессии.
-
Базовый фактор (основанный на стоимости): это сочетание базовых ценностей, таких как ПЭ, дивиденды и т. Д. Базовая стоимость содержит информацию, связанную с реальными фактами компании, поэтому она может быть более мощной, чем цена во многих аспектах.
В конечном счете, прогноз развития - это гонка вооружений, и вы пытаетесь оставаться на шаг впереди. Факторы будут арбитражем с рынка и будут иметь полезный срок службы, поэтому вы должны постоянно работать, чтобы определить, сколько рецессий испытали ваши факторы и какие новые факторы могут быть использованы для их замены.
Другие соображения
- Частота ребалансирования
Каждая система ранжирования предсказывает доходность в несколько разных временных рамках. Средняя регрессия на основе цены может быть предсказуемой в течение нескольких дней, в то время как факторная модель на основе стоимости может быть предсказуемой в течение нескольких месяцев. Важно определить временной диапазон, который должна предсказывать модель, и провести статистическую проверку перед выполнением стратегии. Конечно, вы не хотите перестраиваться, пытаясь оптимизировать частоту ребалансирования. Вы неизбежно найдете случайную частоту, которая лучше других частот. После того, как вы определили временный диапазон предсказания схемы ранжирования, попробуйте перебалансировать примерно на этой частоте, чтобы в полной мере использовать свою модель.
- Капитальная способность и затраты на транзакции
Каждая стратегия имеет минимальный и максимальный объем капитала, а минимальный порог обычно определяется стоимостью сделки.
Торговля слишком большим количеством акций приведет к высоким затратам на транзакции. Если вы хотите купить 1000 акций, это будет стоить тысячи долларов на каждое ребалансирование. Ваша капитальная база должна быть достаточно высокой, чтобы затраты на транзакции могли составлять небольшую часть доходов, генерируемых вашей стратегией. Например, если ваш капитал составляет 100 000 долларов, а ваша стратегия зарабатывает 1% ($ 1000) в месяц, все эти доходы будут потреблены затратами на транзакции. Вам нужно запустить стратегию с миллионами долларов капитала, чтобы заработать более 1000 акций.
Наименьший порог активов в основном зависит от количества торгуемых акций. Тем не менее, максимальная емкость также очень высока. Долгосрочная краткосрочная стратегия сбалансированных акций может торговать сотнями миллионов долларов, не теряя преимущества. Это факт, потому что эта стратегия относительно редко подвергается ребалансированию. Долларная стоимость каждой акции будет очень низкой, когда общие активы делятся на количество торгуемых акций. Вам не нужно беспокоиться о том, повлияет ли ваш объем торговли на рынок. Предположим, что вы торгуете 1000 акциями, то есть 100 000 000 долларов. Если вы перебалансируете весь портфель каждый месяц, каждая акция будет торговать только 100 000 долларов в месяц, что недостаточно, чтобы быть важным рынком для большинства ценных бумаг.
- Количественный анализ фундаментального анализа на рынке криптовалют: пусть данные говорят сами за себя!
- Не стоит больше верить всяким хитроумным учителям, которые говорят, что данные объективны.
- Необходимый инструмент для количественной торговли - изобретатель модуля количественного исследования данных
- Освоение всего - Введение в FMZ Новая версия торгового терминала (с TRB Arbitrage Source Code)
- Ознакомьтесь с новым типом терминала FMZ (с кодом TRB)
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (II)
- Как использовать бесмозговых роботов с высокочастотной стратегией в 80 строках кода
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (II)
- Как использовать высокочастотную стратегию 80-линейного кода для эксплуатации безмозговых роботов
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (I)
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (1)