ڈیٹا پر مبنی ٹیکنالوجی پر مبنی جوڑی ٹریڈنگ
مصنف:لیدیہ, تخلیق: 2023-01-05 09:10:25, تازہ کاری: 2023-09-20 09:42:28
ڈیٹا پر مبنی ٹیکنالوجی پر مبنی جوڑی ٹریڈنگ
جوڑی ٹریڈنگ ریاضیاتی تجزیہ پر مبنی تجارتی حکمت عملیوں کی تشکیل کی ایک اچھی مثال ہے۔ اس مضمون میں ، ہم دکھائیں گے کہ جوڑی ٹریڈنگ کی حکمت عملیوں کو بنانے اور خودکار کرنے کے لئے ڈیٹا کا استعمال کیسے کریں۔
بنیادی اصول
فرض کریں کہ آپ کے پاس سرمایہ کاری کے اہداف X اور Y کی ایک جوڑی ہے جس میں کچھ ممکنہ رابطے ہیں۔ مثال کے طور پر ، دو کمپنیاں ایک ہی مصنوعات تیار کرتی ہیں ، جیسے پیپسی کولا اور کوکا کولا۔ آپ چاہتے ہیں کہ وقت کے ساتھ ساتھ ان دونوں کی قیمت کا تناسب یا بیس اسپریڈ (جسے قیمت کا فرق بھی کہا جاتا ہے) برقرار رہے۔ تاہم ، رسد اور طلب میں عارضی تبدیلیوں کی وجہ سے ، جیسے سرمایہ کاری کے ہدف کا ایک بڑا خرید / فروخت کا آرڈر ، اور کمپنیوں میں سے ایک کی اہم خبروں کا رد عمل ، وقت کے ساتھ ساتھ دونوں جوڑوں کے مابین قیمت کا فرق مختلف ہوسکتا ہے۔ اس معاملے میں ، ایک سرمایہ کاری کا اعتراض ایک دوسرے کے مقابلہ میں نیچے کی طرف بڑھتا ہے جبکہ دوسرا نیچے کی طرف بڑھتا ہے۔ اگر آپ چاہتے ہیں کہ یہ اختلافات وقت کے ساتھ ساتھ معمول پر آجائے ، تو آپ ٹریڈنگ کے مواقع (یا ثالثی کے مواقع) تلاش کرسکتے ہیں۔ اس طرح کے ثالثی کے مواقع ڈیجیٹل کرنسی مارکیٹ میں یا گھریلو اجناس کے مستقبل کی مارکیٹ میں پائے جاسکتے ہیں ، جیسے بی ٹی سی اور ایک کمپنی کی اہم خبروں کا رد عمل۔
جب عارضی قیمت کا فرق ہوتا ہے تو ، آپ بہترین کارکردگی کے ساتھ سرمایہ کاری کا اعتراض بیچیں گے (اعلی سرمایہ کاری کا اعتراض) اور ناقص کارکردگی کے ساتھ سرمایہ کاری کا اعتراض خریدیں گے (گرنے والا سرمایہ کاری کا اعتراض) ۔ آپ کو یقین ہے کہ دو سرمایہ کاری کے اشیاء کے مابین سود کا مارجن بالآخر بہترین کارکردگی کے ساتھ سرمایہ کاری کے اعتراض کے گرنے یا ناقص کارکردگی کے ساتھ سرمایہ کاری کے اعتراض کے اضافے کے ذریعے گر جائے گا ، یا دونوں۔ آپ کا لین دین ان تمام اسی طرح کی صورتحال میں پیسہ کمائے گا۔ اگر سرمایہ کاری کے اشیاء ان کے درمیان قیمت کے فرق کو تبدیل کیے بغیر ایک ساتھ اوپر یا نیچے چلتے ہیں تو ، آپ پیسہ نہیں کمائیں گے یا نہیں کھوئیں گے۔
لہذا، جوڑی ٹریڈنگ ایک مارکیٹ غیر جانبدار ٹریڈنگ کی حکمت عملی ہے، جو تاجروں کو تقریبا کسی بھی مارکیٹ کے حالات سے فائدہ اٹھانے کے قابل بناتا ہے: اوپر کی رجحان، نیچے کی رجحان یا افقی استحکام.
تصور کی وضاحت کریں: دو فرضی سرمایہ کاری کے اہداف
- ایف ایم زیڈ کوانٹ پلیٹ فارم پر اپنا تحقیقی ماحول بنائیں
سب سے پہلے ، ہم آسانی سے کام کرنے کے ل our ، ہمیں اپنے تحقیقی ماحول کی تعمیر کرنے کی ضرورت ہے۔ اس مضمون میں ، ہم ایف ایم زیڈ کوانٹ پلیٹ فارم کا استعمال کرتے ہیں (FMZ.COM) اپنے تحقیقی ماحول کی تعمیر کے لئے ، بنیادی طور پر آسان اور تیز رفتار API انٹرفیس اور اس پلیٹ فارم کے اچھی طرح سے پیکڈ ڈوکر سسٹم کو استعمال کرنے کے لئے۔
ایف ایم زیڈ کوانٹ پلیٹ فارم کے سرکاری نام میں ، اس ڈوکر سسٹم کو ڈوکر سسٹم کہا جاتا ہے۔
براہ کرم میرے پچھلے مضمون کا حوالہ دیں کہ ڈوکر اور روبوٹ کو کیسے تعینات کیا جائے:https://www.fmz.com/bbs-topic/9864.
قارئین جو اپنے ڈاکرز کو تعینات کرنے کے لئے اپنا کلاؤڈ کمپیوٹنگ سرور خریدنا چاہتے ہیں وہ اس مضمون کا حوالہ دے سکتے ہیں:https://www.fmz.com/digest-topic/5711.
کلاؤڈ کمپیوٹنگ سرور اور ڈوکر سسٹم کو کامیابی کے ساتھ تعینات کرنے کے بعد، اگلا ہم پائیتھون کے موجودہ سب سے بڑے آرٹیفیکٹ انسٹال کریں گے: اناکونڈا
اس مضمون میں درکار تمام متعلقہ پروگرام ماحول (تبعیت لائبریریاں ، ورژن مینجمنٹ ، وغیرہ) کو سمجھنے کے ل the ، آسان ترین طریقہ ایناکونڈا کا استعمال کرنا ہے۔ یہ پیتھون ڈیٹا سائنس ماحولیاتی نظام اور انحصار لائبریری مینیجر ہے۔
Anaconda کی تنصیب کے طریقہ کار کے لئے، برائے مہربانی Anaconda کے سرکاری گائیڈ سے رجوع کریں:https://www.anaconda.com/distribution/.
اس مضمون میں پیتھون سائنسی کمپیوٹنگ میں دو مشہور اور اہم لائبریریاں نمپی اور پانڈا کا بھی استعمال کیا جائے گا۔
مذکورہ بالا بنیادی کام میرے پچھلے مضامین کا بھی حوالہ دے سکتا ہے ، جس میں اناکونڈا ماحول اور نومی اور پانڈا لائبریریوں کو ترتیب دینے کا طریقہ متعارف کرایا گیا ہے۔ تفصیلات کے لئے ، براہ کرم ملاحظہ کریں:https://www.fmz.com/bbs-topic/9863.
اگلا، آئیے
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
جی ہاں، ہم بھی استعمال کریں گے matplotlib، پائیتھون میں ایک بہت مشہور چارٹ لائبریری.
آئیے ایک فرضی سرمایہ کاری کا ہدف X پیدا کریں، اور اس کی روزانہ واپسی کو معمول کی تقسیم کے ذریعے نمونہ بنائیں اور اس کا نقشہ بنائیں۔ پھر ہم روزانہ X قدر حاصل کرنے کے لئے مجموعی رقم انجام دیتے ہیں۔
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
سرمایہ کاری کے اعتراض کے X کو ایک عام تقسیم کے ذریعے اس کی روزانہ واپسی کا نقشہ بنانے کے لئے تیار کیا جاتا ہے
اب ہم Y پیدا کرتے ہیں، جو X کے ساتھ مضبوطی سے مربوط ہے، لہذا Y کی قیمت X کی تبدیلی سے بہت ملتی جلتی ہونی چاہئے۔ ہم X لے کر اس کا ماڈل بناتے ہیں، اسے اوپر منتقل کرتے ہیں اور معمول کی تقسیم سے نکالے گئے کچھ بے ترتیب شور کو شامل کرتے ہیں۔
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
X اور Y کو انٹیگریشن سرمایہ کاری کا مقصد
ہم آہنگی
ہم آہنگی ارتباط سے بہت ملتی جلتی ہے ، جس کا مطلب ہے کہ دو ڈیٹا سیریز کے مابین تناسب اوسط قدر کے قریب بدل جائے گا۔ Y اور X سیریز مندرجہ ذیل ہیں:
Y =
جہاں
دو ٹائم سیریز کے مابین تجارت کرنے والے جوڑوں کے ل the ، وقت کے ساتھ تناسب کی متوقع قیمت کو اوسط قیمت پر ملنا چاہئے ، یعنی ، انہیں مربوط ہونا چاہئے۔ ہم نے جو ٹائم سیریز اوپر بنائی ہے وہ مربوط ہے۔ ہم اب ان کے مابین تناسب کا نقشہ بنائیں گے تاکہ ہم دیکھ سکیں کہ یہ کیسا لگتا ہے۔
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
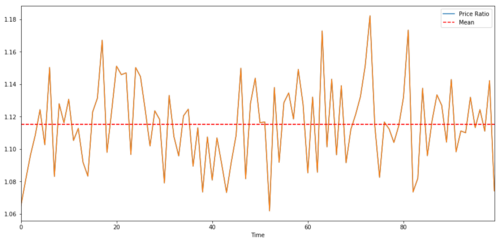
دو مربوط سرمایہ کاری ہدف کی قیمتوں کے درمیان تناسب اور اوسط قیمت
ہم آہنگی کا ٹیسٹ
ایک آسان ٹیسٹ کا طریقہ یہ ہے کہ statsmodels.tsa.stattools استعمال کریں۔ ہم ایک بہت ہی کم پی ویلیو دیکھیں گے ، کیونکہ ہم نے دو ڈیٹا سیریز مصنوعی طور پر بنائی ہیں جو زیادہ سے زیادہ مربوط ہیں۔
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
نتیجہ: 1.81864477307e-17
نوٹ: تعلق اور ہم آہنگی
ہم آہنگی اور ہم آہنگی ، اگرچہ نظریاتی طور پر ملتے جلتے ہیں ، لیکن ایک جیسے نہیں ہیں۔ آئیے متعلقہ لیکن ہم آہنگ نہیں ہونے والی ڈیٹا سیریز کی مثالوں کو دیکھیں اور اس کے برعکس۔ پہلے ، آئیے ہم نے ابھی پیدا کردہ سیریز کے ہم آہنگی کی جانچ کریں۔
X.corr(Y)
نتیجہ ہے: 0.951
جیسا کہ ہم نے توقع کی تھی، یہ بہت زیادہ ہے۔ لیکن دو متعلقہ لیکن مربوط نہیں ہونے والی سیریز کے بارے میں کیا خیال ہے؟ ایک سادہ مثال دو انحراف اعداد و شمار کی سیریز ہے۔
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
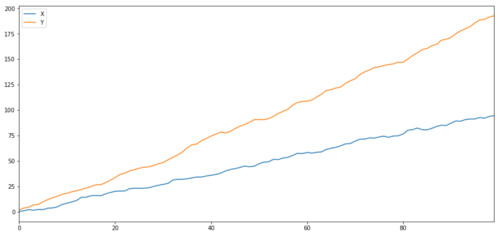
دو متعلقہ سیریز (ایک دوسرے کے ساتھ مربوط نہیں)
رابطے کا گتانک: 0.998 ہم آہنگی ٹیسٹ کی P قدر: 0.258
بغیر کسی ارتباط کے ہم آہنگی کی سادہ مثالیں عام تقسیم کی ترتیب اور مربع لہریں ہیں۔
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
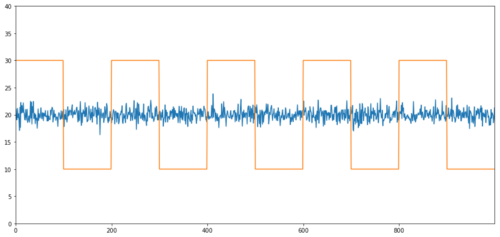
ارتباط: 0.007546 ہم آہنگی ٹیسٹ کی P قدر: 0.0
correlation بہت کم ہے، لیکن p قدر کامل co-انٹیگریشن ظاہر کرتا ہے!
جوڑے کی تجارت کیسے کی جائے؟
چونکہ دو مربوط وقت کی سیریز (جیسے اوپر X اور Y) ایک دوسرے کا سامنا کر رہی ہیں اور ایک دوسرے سے انحراف کر رہی ہیں ، لہذا بعض اوقات بیس اسپریڈ زیادہ یا کم ہوتا ہے۔ ہم ایک سرمایہ کاری کا اعتراض خرید کر اور دوسرا بیچ کر جوڑی ٹریڈنگ کرتے ہیں۔ اس طرح ، اگر دونوں سرمایہ کاری کے اہداف ایک ساتھ گر جاتے ہیں یا بڑھتے ہیں تو ، ہم نہ تو پیسہ کماتے ہیں اور نہ ہی پیسہ کھوتے ہیں ، یعنی ، ہم مارکیٹ میں غیر جانبدار ہیں۔
اوپر کی طرف لوٹتے ہوئے ، X اور Y میں Y =
-
طویل تناسب: یہ اس وقت ہوتا ہے جب تناسب
بہت چھوٹا ہوتا ہے اور ہم توقع کرتے ہیں کہ یہ بڑھ جائے گا۔ مذکورہ بالا مثال میں ، ہم طویل Y اور مختصر X جا کر پوزیشن کھولتے ہیں۔ -
مختصر تناسب: یہ اس وقت ہوتا ہے جب تناسب
بہت بڑا ہوتا ہے اور ہم توقع کرتے ہیں کہ اس میں کمی واقع ہوگی۔ مذکورہ بالا مثال میں ، ہم مختصر Y اور طویل X جا کر پوزیشن کھولتے ہیں۔
براہ کرم نوٹ کریں کہ ہمارے پاس ہمیشہ ہیج پوزیشن ہوتی ہے۔ اگر ٹریڈنگ کا موضوع نقصان کی قیمت خریدتا ہے تو ، مختصر پوزیشن پیسہ کمائے گی ، اور اس کے برعکس ، لہذا ہم مارکیٹ کے مجموعی رجحان سے محفوظ ہیں۔
اگر تجارتی اعتراض کے X اور Y ایک دوسرے کے حوالے سے منتقل ہوتے ہیں، تو ہم پیسہ کماتے ہیں یا پیسے کھو دیتے ہیں.
اسی طرح کے رویے کے ساتھ ٹریڈنگ اشیاء تلاش کرنے کے لئے ڈیٹا کا استعمال کریں
ایسا کرنے کا بہترین طریقہ یہ ہے کہ تجارتی موضوع سے شروع کریں جس کے بارے میں آپ کو شبہ ہے کہ وہ مربوط ہوسکتا ہے اور ایک شماریاتی ٹیسٹ انجام دیں۔ اگر آپ تمام تجارتی جوڑوں پر شماریاتی ٹیسٹ کرتے ہیں تو آپ اس کا شکار ہوجائیں گےمتعدد موازنہ تعصب.
متعدد موازنہ تعصببہت سے ٹیسٹ چلانے پر غلط طریقے سے اہم پی ویلیوز پیدا کرنے کے بڑھتے ہوئے امکان سے مراد ہے ، کیونکہ ہمیں بڑی تعداد میں ٹیسٹ چلانے کی ضرورت ہے۔ اگر ہم بے ترتیب اعداد و شمار پر 100 ٹیسٹ چلاتے ہیں تو ، ہمیں 0.5 سے کم 5 پی ویلیوز دیکھنا چاہئے۔ اگر آپ شریک انضمام کے لئے n تجارتی اہداف کا موازنہ کرنا چاہتے ہیں تو ، آپ n (n-1) / 2 موازنہ کریں گے ، اور آپ کو بہت سے غلط پی ویلیوز نظر آئیں گے ، جو آپ کے ٹیسٹ کے نمونے میں اضافے کے ساتھ بڑھیں گے۔ اس صورتحال سے بچنے کے ل select ، کچھ تجارتی جوڑے منتخب کریں اور آپ کو یہ طے کرنے کا سبب ہے کہ وہ شریک انضمام ہوسکتے ہیں ، اور پھر ان کو الگ الگ جانچیں۔ اس سے بہت کم ہوجائے گا۔متعدد موازنہ تعصب.
لہذا ، آئیے کچھ تجارتی اہداف تلاش کرنے کی کوشش کریں جو ہم آہنگی کا مظاہرہ کرتے ہیں۔ آئیے مثال کے طور پر ایس اینڈ پی 500 انڈیکس میں بڑی امریکی ٹکنالوجی اسٹاک کی ایک ٹوکری لیتے ہیں۔ یہ تجارتی اہداف اسی طرح کے مارکیٹ کے حصوں میں کام کرتے ہیں اور ان کی ہم آہنگی کی قیمتیں ہیں۔ ہم تجارتی اشیاء کی فہرست کو اسکین کرتے ہیں اور تمام جوڑوں کے مابین ہم آہنگی کی جانچ کرتے ہیں۔
واپس آنے والے کو انٹیگریشن ٹیسٹ اسکور میٹرکس، پی ویلیو میٹرکس اور تمام جوڑے جن کی پی ویلیو 0.05 سے کم ہے۔یہ طریقہ متعدد موازنہ تعصب کا شکار ہے، لہذا حقیقت میں، انہیں دوسری تصدیق کرنے کی ضرورت ہے.اِس مضمون میں، اپنی وضاحت کی سہولت کے لیے، ہم اِس مثال کے اس نکتے کو نظر انداز کرنے کا انتخاب کرتے ہیں۔
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
نوٹ: ہم نے مارکیٹ بینچ مارک (ایس پی ایکس) کو اعداد و شمار میں شامل کیا ہے - مارکیٹ نے بہت سارے تجارتی اشیاء کے بہاؤ کو چلایا ہے۔ عام طور پر آپ کو دو تجارتی اشیاء مل سکتی ہیں جو مربوط نظر آتی ہیں۔ لیکن حقیقت میں ، وہ ایک دوسرے کے ساتھ نہیں ، بلکہ مارکیٹ کے ساتھ مربوط ہیں۔ اس کو الجھانے والا متغیر کہا جاتا ہے۔ آپ کو ملنے والے کسی بھی تعلقات میں مارکیٹ کی شرکت کی جانچ کرنا ضروری ہے۔
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

اب آئیے ہم اپنے طریقہ کار کا استعمال کرتے ہوئے کو انٹیگریٹڈ ٹریڈنگ جوڑے تلاش کرنے کی کوشش کریں۔
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
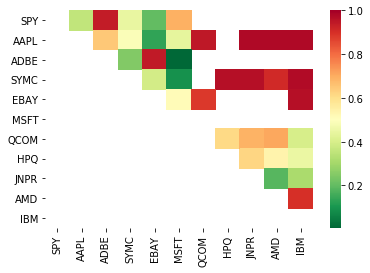
ایسا لگتا ہے کہ
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
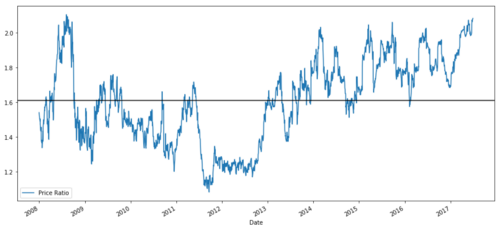
MSFT اور ADBE کے درمیان قیمت تناسب کا گراف 2008 سے 2017 تک
یہ تناسب ایک مستحکم اوسط کی طرح لگتا ہے۔ مطلق تناسب شماریاتی طور پر مفید نہیں ہے۔ ان کے ساتھ Z اسکور کے طور پر سلوک کرکے اپنے اشاروں کو معیاری بنانا زیادہ مددگار ہے۔ Z اسکور کی وضاحت اس طرح کی گئی ہے:
Z سکور (قیمت) = (قیمت
انتباہ
حقیقت میں ، ہم عام طور پر اس مفروضے پر اعداد و شمار کو بڑھانے کی کوشش کرتے ہیں کہ اعداد و شمار عام طور پر تقسیم ہوتے ہیں۔ تاہم ، بہت سے مالی اعداد و شمار عام طور پر تقسیم نہیں ہوتے ہیں ، لہذا ہمیں اعداد و شمار تیار کرتے وقت صرف معمول یا کسی خاص تقسیم کا فرض نہ کرنے کا بہت محتاط رہنا چاہئے۔ تناسب کی حقیقی تقسیم میں چربی کا اثر پڑ سکتا ہے ، اور وہ اعداد و شمار جو انتہائی ہوتے ہیں وہ ہمارے ماڈل کو الجھا دیتے ہیں اور بڑے نقصانات کا باعث بنتے ہیں۔
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
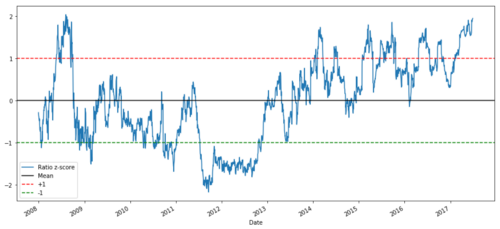
ایم ایس ایف ٹی اور اے ڈی بی ای کے درمیان 2008 سے 2017 تک Z قیمت کا تناسب
اب اوسط قدر کے قریب تناسب کی نقل و حرکت کا مشاہدہ کرنا آسان ہے ، لیکن بعض اوقات اوسط قدر سے بڑا فرق ہونا آسان ہے۔ ہم اس کا فائدہ اٹھا سکتے ہیں۔
اب جب ہم نے جوڑی ٹریڈنگ کی حکمت عملی کے بنیادی علم پر تبادلہ خیال کیا ہے ، اور تاریخی قیمت کی بنیاد پر مشترکہ انضمام کا موضوع طے کیا ہے ، آئیے ایک تجارتی سگنل تیار کرنے کی کوشش کریں۔ سب سے پہلے ، آئیے ڈیٹا ٹکنالوجی کا استعمال کرتے ہوئے تجارتی سگنل تیار کرنے کے اقدامات کا جائزہ لیں:
-
قابل اعتماد اعداد و شمار جمع کریں اور اعداد و شمار کو صاف کریں؛
-
ٹریڈنگ سگنل/منطق کی شناخت کے لیے ڈیٹا سے افعال بنائیں۔
-
افعال متحرک اوسط یا قیمت کے اعداد و شمار ، تعلق یا زیادہ پیچیدہ اشاروں کے تناسب ہوسکتے ہیں - ان کو نئے افعال بنانے کے لئے جوڑیں۔
-
ان افعال کو تجارتی سگنل پیدا کرنے کے لئے استعمال کریں، یعنی کون سے سگنل خریدنے، فروخت کرنے یا مختصر پوزیشن دیکھنے کے لئے ہیں.
خوش قسمتی سے، ہمارے پاس FMZ Quant پلیٹ فارم ہے (fmz.com), جس نے ہمارے لئے مذکورہ بالا چار پہلوؤں کو مکمل کیا ہے ، جو حکمت عملی کے ڈویلپرز کے لئے ایک بڑی برکت ہے۔ ہم اپنی توانائی اور وقت کو حکمت عملی کی منطق کے ڈیزائن اور افعال کے توسیع میں وقف کرسکتے ہیں۔
ایف ایم زیڈ کوانٹ پلیٹ فارم میں ، مختلف مرکزی دھارے کے تبادلے کے لئے انٹرفیس موجود ہیں۔ ہمیں کیا کرنے کی ضرورت ہے ان API انٹرفیس کو کال کرنا ہے۔ باقی بنیادی نفاذ کی منطق کو ایک پیشہ ور ٹیم نے ختم کردیا ہے۔
منطق کو مکمل کرنے اور اس مضمون میں اصول کی وضاحت کرنے کے لئے ، ہم ان بنیادی منطق کو تفصیل سے پیش کریں گے۔ تاہم ، اصل آپریشن میں ، قارئین مذکورہ بالا چار پہلوؤں کو مکمل کرنے کے لئے ایف ایم زیڈ کوانٹ اے پی آئی انٹرفیس کو براہ راست کال کرسکتے ہیں۔
چلو شروع کرتے ہیں:
پہلا مرحلہ: اپنا سوال پیش کریں
یہاں، ہم ایک سگنل بنانے کی کوشش کرتے ہیں کہ ہمیں بتائیں کہ آیا تناسب اگلے لمحے خریدے گا یا فروخت کرے گا، یعنی ہماری پیشن گوئی متغیر Y:
Y = تناسب خرید (1) یا فروخت (-1) ہے
Y ((t) = Sign ((Ratio ((t+1)
براہ کرم نوٹ کریں کہ ہمیں اصل ٹرانزیکشن ہدف کی قیمت کی پیشن گوئی کرنے کی ضرورت نہیں ہے، یا یہاں تک کہ تناسب کی اصل قیمت (اگرچہ ہم کر سکتے ہیں) ، لیکن صرف اگلے مرحلے میں تناسب کی سمت.
مرحلہ 2: قابل اعتماد اور درست ڈیٹا اکٹھا کریں
ایف ایم زیڈ کوانٹ آپ کا دوست ہے! آپ کو صرف اس ٹرانزیکشن آبجیکٹ کی وضاحت کرنے کی ضرورت ہے جس کی تجارت کی جائے گی اور ڈیٹا کا ذریعہ استعمال کیا جائے گا ، اور یہ مطلوبہ ڈیٹا نکالے گا اور اسے منافع اور ٹرانزیکشن آبجیکٹ کی تقسیم کے لئے صاف کرے گا۔ لہذا یہاں کا ڈیٹا بہت صاف ہے۔
پچھلے 10 سالوں کے تجارتی دنوں (تقریبا 2500 ڈیٹا پوائنٹس) پر، ہم نے مندرجہ ذیل اعداد و شمار حاصل کیے ہیں جو Yahoo Finance کا استعمال کرتے ہوئے: افتتاحی قیمت، بند ہونے کی قیمت، سب سے زیادہ قیمت، سب سے کم قیمت اور تجارتی حجم.
مرحلہ 3: ڈیٹا کو تقسیم کریں
ماڈل کی درستگی کی جانچ میں یہ بہت اہم مرحلہ مت بھولنا۔ ہم تربیت / توثیق / ٹیسٹ تقسیم کے لئے مندرجہ ذیل ڈیٹا استعمال کر رہے ہیں۔
-
تربیت 7 سال ~ 70٪
-
ٹیسٹ ~ 3 سال 30٪
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
مثالی طور پر، ہمیں توثیق سیٹ بھی بنانا چاہئے، لیکن ہم ابھی ایسا نہیں کریں گے۔
مرحلہ 4: خصوصیت انجینئرنگ
متعلقہ افعال کیا ہوسکتے ہیں؟ ہم تناسب کی تبدیلی کی سمت کی پیش گوئی کرنا چاہتے ہیں۔ ہم نے دیکھا ہے کہ ہمارے دو تجارتی اہداف مربوط ہیں ، لہذا یہ تناسب اوسط قدر میں منتقل اور واپس آنے کا رجحان رکھتا ہے۔ ایسا لگتا ہے کہ ہماری خصوصیات اوسط تناسب کے کچھ اقدامات ہونی چاہئیں ، اور موجودہ قدر اور اوسط قدر کے مابین فرق ہماری تجارتی سگنل تیار کرسکتا ہے۔
ہم مندرجہ ذیل افعال استعمال کرتے ہیں:
-
60 دن کا چلتا ہوا اوسط تناسب: رولنگ اوسط کی پیمائش؛
-
پانچ روزہ چلتی اوسط تناسب: اوسط کی موجودہ قیمت کی پیمائش؛
-
60 دن کا معیاری انحراف؛
-
Z اسکور: (5d MA - 60d MA) / 60d SD.
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
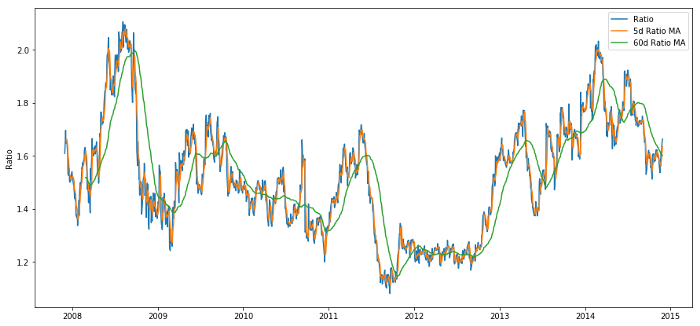
60d اور 5d MA کے درمیان قیمت کا تناسب
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
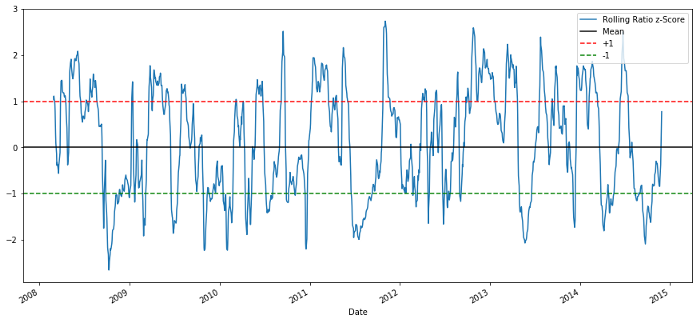
60-5 Z سکور قیمت تناسب
رولنگ اوسط قدر کے Z سکور تناسب کی اوسط قدر رجعت کی خاصیت کو باہر لاتا ہے!
مرحلہ 5: ماڈل کا انتخاب
آئیے ایک بہت ہی آسان ماڈل سے شروع کریں۔ زیڈ اسکور چارٹ کو دیکھتے ہوئے ، ہم دیکھ سکتے ہیں کہ اگر زیڈ اسکور بہت زیادہ یا بہت کم ہے تو ، یہ واپس آجائے گا۔ آئیے +1/- 1 کو اپنے حد کے طور پر استعمال کریں تاکہ بہت زیادہ اور بہت کم کی وضاحت کی جاسکے ، اور پھر ہم مندرجہ ذیل ماڈل کا استعمال ٹریڈنگ سگنل تیار کرنے کے لئے کرسکتے ہیں:
-
جب z - 1.0 سے کم ہے، تناسب خریدنا ہے (1) ، کیونکہ ہم توقع کرتے ہیں کہ z 0 پر واپس آئے گا، لہذا تناسب بڑھتا ہے؛
-
جب z 1.0 سے اوپر ہے، تناسب فروخت ہوتا ہے (- 1) ، کیونکہ ہم توقع کرتے ہیں کہ z 0 پر واپس آئے گا، لہذا تناسب کم ہوتا ہے.
مرحلہ 6: تربیت، تصدیق اور اصلاح
آخر میں، آئیے اصل اعداد و شمار پر ہمارے ماڈل کے اصل اثرات پر ایک نظر ڈالتے ہیں۔ آئیے اصل تناسب پر اس سگنل کی کارکردگی پر ایک نظر ڈالتے ہیں:
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
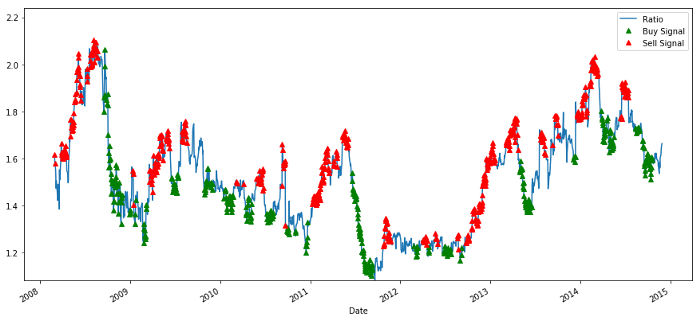
خرید و فروخت کی قیمت کا تناسب سگنل
سگنل معقول لگتا ہے۔ ایسا لگتا ہے کہ جب یہ زیادہ ہے یا بڑھ رہا ہے (سرخ نقطے) تو ہم اسے بیچتے ہیں اور جب یہ کم ہے (سبز نقطے) اور کم ہو رہا ہے تو ہم اسے واپس خریدتے ہیں۔ ہمارے لین دین کے اصل موضوع کے لئے اس کا کیا مطلب ہے؟ آئیے دیکھتے ہیں:
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
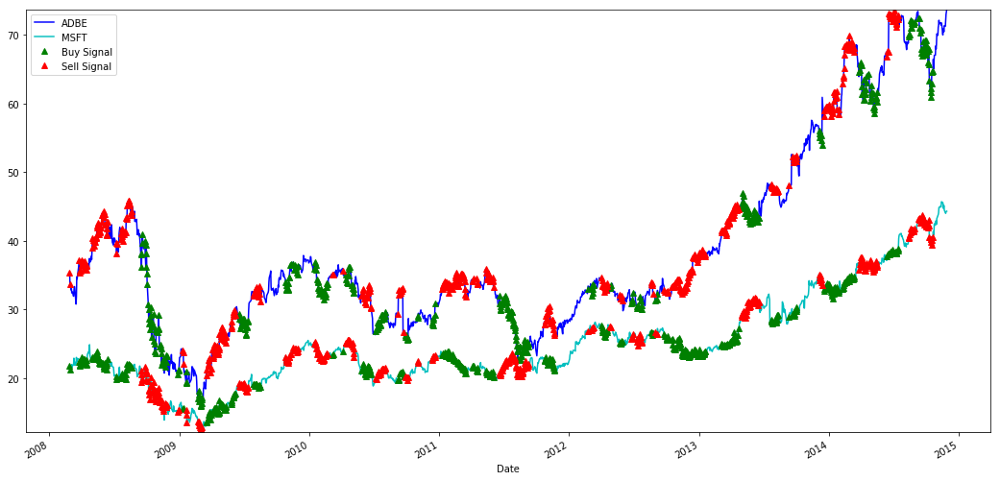
ایم ایس ایف ٹی اور اے ڈی بی ای کے حصص خریدنے اور فروخت کرنے کے لئے سگنل
براہ کرم اس بات پر توجہ دیں کہ ہم کبھی کبھی
ہم تربیت کے اعداد و شمار کے سگنل سے مطمئن ہیں۔ آئیے دیکھتے ہیں کہ یہ سگنل کس طرح کا منافع پیدا کرسکتا ہے۔ جب تناسب کم ہوتا ہے تو ، ہم ایک سادہ بیک ٹیسٹر کرسکتے ہیں ، تناسب خرید سکتے ہیں (1 ADBE اسٹاک خریدیں اور تناسب ایکس MSFT اسٹاک فروخت کریں) ، اور تناسب فروخت کریں (1 ADBE اسٹاک فروخت کریں اور ایکس تناسب MSFT اسٹاک خریدیں) جب یہ زیادہ ہو ، اور ان تناسب کے PnL لین دین کا حساب لگائیں۔
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
نتیجہ: 1783.375
تو یہ حکمت عملی منافع بخش لگتی ہے! اب، ہم چلتی اوسط وقت کی ونڈو کو تبدیل کرکے، خرید / فروخت اور بند پوزیشنوں کی حد کو تبدیل کرکے، اور توثیق کے اعداد و شمار کی کارکردگی میں بہتری کی جانچ پڑتال کرکے مزید بہتر بنا سکتے ہیں.
ہم بھی زیادہ پیچیدہ ماڈل، جیسے لاجسٹک رجسٹریشن اور ایس وی ایم کی کوشش کر سکتے ہیں، 1/-1 کی پیشن گوئی کرنے کے لئے.
اب، آئیے اس ماڈل کو آگے بڑھائیں، جو ہمیں لے جاتا ہے:
مرحلہ 7: ٹیسٹ کے اعداد و شمار کا بیک ٹیسٹ کریں
یہاں بھی ، ایف ایم زیڈ کوانٹ پلیٹ فارم نے تاریخی ماحول کو صحیح طور پر دوبارہ پیش کرنے ، عام مقداری بیک ٹسٹنگ کے خطرات کو ختم کرنے اور وقت میں حکمت عملیوں کی کمیوں کا پتہ لگانے کے لئے ایک اعلی کارکردگی کا مظاہرہ کرنے والا کیو پی ایس / ٹی پی ایس بیک ٹسٹنگ انجن اپنایا ہے ، تاکہ حقیقی بوٹ سرمایہ کاری کی بہتر مدد کی جاسکے۔
اصول کی وضاحت کرنے کے لئے ، یہ مضمون اب بھی بنیادی منطق کو ظاہر کرنے کا انتخاب کرتا ہے۔ عملی درخواست میں ، ہم قارئین کو ایف ایم زیڈ کوانٹ پلیٹ فارم استعمال کرنے کی سفارش کرتے ہیں۔ وقت کی بچت کے علاوہ ، غلطی برداشت کی شرح کو بہتر بنانا بھی ضروری ہے۔
بیک ٹسٹنگ آسان ہے۔ ہم ٹیسٹ کے اعداد و شمار کی پی این ایل کو دیکھنے کے لئے مذکورہ بالا فنکشن کا استعمال کرسکتے ہیں۔
trade(data['ADBE'].iloc[1762:], data['MSFT'].iloc[1762:], 60, 5)
نتیجہ: 5262.868
اس ماڈل نے بہت اچھا کام کیا! یہ ہمارا پہلا سادہ جوڑا جوڑی ٹریڈنگ ماڈل بن گیا.
زیادہ سے زیادہ فٹ ہونے سے بچیں
بحث کے اختتام سے پہلے ، میں خاص طور پر اوور فٹنگ پر تبادلہ خیال کرنا چاہتا ہوں۔ اوور فٹنگ تجارتی حکمت عملیوں میں سب سے خطرناک جال ہے۔ اوور فٹنگ الگورتھم بیک ٹسٹ میں بہت اچھی کارکردگی کا مظاہرہ کرسکتا ہے لیکن نئے پوشیدہ ڈیٹا پر ناکام ہوسکتا ہے - جس کا مطلب ہے کہ یہ واقعی میں اعداد و شمار کا کوئی رجحان ظاہر نہیں کرتا ہے اور اس کی کوئی حقیقی پیش گوئی کی صلاحیت نہیں ہے۔ آئیے ایک سادہ مثال دیتے ہیں۔
ہمارے ماڈل میں ، ہم ٹائم ونڈو کی لمبائی کا اندازہ لگانے اور بہتر بنانے کے لئے رولنگ پیرامیٹرز کا استعمال کرتے ہیں۔ ہم صرف تمام امکانات ، ایک معقول لمبائی کی ونڈو پر تکرار کرنے کا فیصلہ کرسکتے ہیں ، اور اپنے ماڈل کی بہترین کارکردگی کے مطابق وقت کی لمبائی کا انتخاب کرسکتے ہیں۔ آئیے ایک سادہ لوپ لکھیں تاکہ ٹریننگ ڈیٹا کے پی این ایل کے مطابق ٹائم ونڈو کی لمبائی کو اسکور کیا جاسکے اور بہترین لوپ تلاش کریں۔
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
اب ہم ٹیسٹ کے اعداد و شمار پر ماڈل کی کارکردگی کا جائزہ لیتے ہیں، اور ہمیں پتہ چلتا ہے کہ اس وقت ونڈو کی لمبائی زیادہ سے زیادہ ہے! اس کی وجہ یہ ہے کہ ہمارے اصل انتخاب واضح طور پر نمونے کے اعداد و شمار پر زیادہ فٹ بیٹھا ہے.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
یہ واضح ہے کہ ہمارے لئے موزوں نمونہ ڈیٹا مستقبل میں ہمیشہ اچھے نتائج نہیں لائے گا۔ صرف جانچ کے لئے ، آئیے دو ڈیٹا سیٹوں سے حساب لگائے گئے لمبائی کے اسکوروں کا خاکہ بنائیں:
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
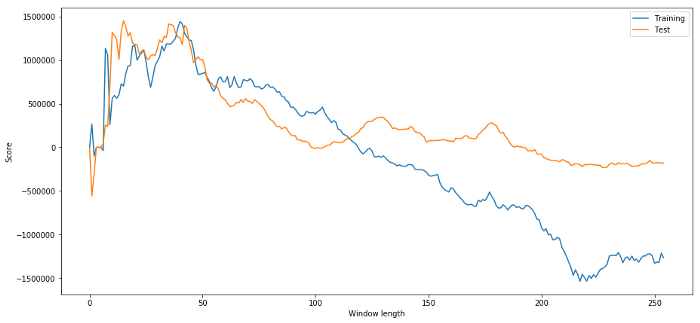
ہم دیکھ سکتے ہیں کہ 20 اور 50 کے درمیان کچھ بھی وقت کی کھڑکیوں کے لئے ایک اچھا انتخاب ہے.
اوور فٹ ہونے سے بچنے کے ل we ، ہم وقت کی کھڑکی کی لمبائی کا انتخاب کرنے کے لئے معاشی استدلال یا الگورتھم کی نوعیت کا استعمال کرسکتے ہیں۔ ہم کالمین فلٹر کا بھی استعمال کرسکتے ہیں ، جس میں ہمیں لمبائی کی وضاحت کرنے کی ضرورت نہیں ہے۔ اس نقطہ نظر کی وضاحت بعد میں ایک اور مضمون میں کی جائے گی۔
اگلا قدم
اس مضمون میں ، ہم تجارتی حکمت عملیوں کی تیاری کے عمل کو ظاہر کرنے کے لئے کچھ آسان تعارفی طریقوں کی تجویز کرتے ہیں۔ عملی طور پر ، زیادہ پیچیدہ اعدادوشمار کا استعمال کرنا چاہئے۔ آپ مندرجہ ذیل اختیارات پر غور کرسکتے ہیں:
-
Hurst اشاریہ؛
-
Ornstein-Uhlenbeck عمل سے infered اوسط رجعت کی نصف زندگی؛
-
Kalman فلٹر.
- کریپٹوکرنسی مارکیٹ میں بنیادی تجزیہ کی مقدار: اعداد و شمار کو اپنے لئے بولنے دیں!
- ایک بار پھر ، ہم نے ایک بار پھر اس بات کا یقین کرلیا ہے کہ یہ ایک بہت بڑا مسئلہ ہے ، لیکن ہم اس کے بارے میں مزید نہیں جانتے ہیں۔
- کوانٹائزڈ ٹرانزیکشنز کے لیے ایک لازمی ٹول۔
- ہر چیز پر قابو پانا - ایف ایم زیڈ ٹریڈنگ ٹرمینل کا نیا ورژن (ٹی آر بی آربیٹریج سورس کوڈ کے ساتھ) کا تعارف
- FMZ کے نئے ورژن کے ٹرانزیکشن ٹرمینل کے بارے میں سب کچھ جاننے کے لئے یہاں کلک کریں
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (II)
- 80 لائنوں کے کوڈ میں ہائی فریکوئینسی حکمت عملی کے ساتھ دماغ کے بغیر سیلز بوٹس کا استحصال کیسے کریں
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (ب)
- 80 لائنوں کے کوڈ کے ساتھ ہائی فریکوئینسی کی حکمت عملی کے ساتھ فروخت کے لیے بے دماغ روبوٹ کا استحصال کیسے کیا گیا؟
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (I)
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (1)