طویل مختصر پوزیشنوں کے لیے متوازن ایکویٹی حکمت عملیوں کو منظم طریقے سے سیدھ میں لانا
مصنف:لیدیہ, تخلیق: 2023-01-09 13:46:21, تازہ کاری: 2023-09-20 10:13:35
طویل مختصر پوزیشنوں کے لیے متوازن ایکویٹی حکمت عملیوں کو منظم طریقے سے سیدھ میں لانا
پچھلے مضمون میں (https://www.fmz.com/bbs-topic/9862), ہم نے جوڑی ٹریڈنگ کی حکمت عملی متعارف کروائی اور دکھایا کہ ڈیٹا اور ریاضیاتی تجزیہ کا استعمال کرتے ہوئے ٹریڈنگ کی حکمت عملیوں کو کیسے بنایا اور خودکار کیا جائے۔
لمبی مختصر پوزیشنوں کی متوازن ایکویٹی حکمت عملی تجارتی اشیاء کی ٹوکری پر لاگو جوڑی ٹریڈنگ حکمت عملی کا ایک فطری توسیع ہے۔ یہ خاص طور پر بہت سی اقسام اور باہمی تعلقات کے ساتھ تجارتی منڈیوں کے لئے موزوں ہے ، جیسے ڈیجیٹل کرنسی مارکیٹوں اور خام مال کے مستقبل کی منڈیوں میں۔
بنیادی اصول
لانگ شارٹ پوزیشنز متوازن ایکویٹی حکمت عملی ایک ہی وقت میں تجارتی اہداف کی ایک ٹوکری کو طویل اور مختصر کرنا ہے۔ جوڑی کی تجارت کی طرح ، یہ طے کرتا ہے کہ کون سا سرمایہ کاری کا ہدف سستا ہے اور کون سا سرمایہ کاری کا ہدف مہنگا ہے۔ فرق یہ ہے کہ لانگ شارٹ پوزیشنز متوازن ایکویٹی حکمت عملی تمام سرمایہ کاری کے اہداف کو اسٹاک کے انتخاب کے پول میں ترتیب دے گی تاکہ یہ معلوم کیا جاسکے کہ کون سے سرمایہ کاری کے اہداف نسبتا cheap سستے یا مہنگے ہیں۔ پھر ، یہ درجہ بندی کی بنیاد پر سب سے اوپر n سرمایہ کاری کے اہداف کو طویل کرے گا ، اور نیچے n سرمایہ کاری کے اہداف کو اسی رقم میں مختصر کرے گا (لانگ پوزیشنوں کی کل قیمت = مختصر پوزیشنوں کی کل قیمت) ۔
کیا آپ کو یاد ہے کہ ہم نے کیا کہا تھا کہ جوڑی ٹریڈنگ مارکیٹ میں غیر جانبدار حکمت عملی ہے؟ لمبی مختصر پوزیشنوں کی متوازن ایکویٹی حکمت عملی کے لئے بھی یہی سچ ہے ، کیونکہ لمبی اور مختصر پوزیشنوں کی مساوی مقدار اس بات کو یقینی بناتی ہے کہ حکمت عملی مارکیٹ میں غیر جانبدار رہے گی (مارکیٹ کی اتار چڑھاؤ سے متاثر نہیں ہوگی) ۔ حکمت عملی بھی اعدادوشمار کے لحاظ سے مضبوط ہے۔ سرمایہ کاری کے اہداف کو درجہ بندی کرکے اور لمبی پوزیشنوں کو تھام کر ، آپ اپنی درجہ بندی کے ماڈل پر کئی بار پوزیشن کھول سکتے ہیں ، نہ کہ صرف ایک بار خطرہ کھولنے کی پوزیشن۔ آپ خالص طور پر اپنی درجہ بندی کی اسکیم کے معیار پر شرط لگا رہے ہیں۔
درجہ بندی کا نظام کیا ہے؟
درجہ بندی کا نظام ایک ایسا ماڈل ہے جو ہر سرمایہ کاری کے موضوع کو متوقع کارکردگی کے مطابق ترجیح دے سکتا ہے۔ عوامل قدر کے عوامل ، تکنیکی اشارے ، قیمتوں کا تعین کرنے والے ماڈل یا مذکورہ بالا تمام عوامل کا مجموعہ ہوسکتے ہیں۔ مثال کے طور پر ، آپ رجحان کی پیروی کرنے والے سرمایہ کاری کے اہداف کی ایک سیریز کو درجہ بندی کرنے کے لئے رفتار کے اشارے استعمال کرسکتے ہیں۔ یہ توقع کی جاتی ہے کہ سب سے زیادہ رفتار والے سرمایہ کاری کے اہداف اچھی کارکردگی کا مظاہرہ کرتے رہیں گے اور سب سے زیادہ درجہ بندی حاصل کریں گے۔ کم رفتار والے سرمایہ کاری کے اعتراض میں بدترین کارکردگی اور سب سے کم واپسی ہے۔
اس حکمت عملی کی کامیابی تقریبا مکمل طور پر استعمال شدہ درجہ بندی کے نظام پر منحصر ہے ، یعنی ، آپ کا درجہ بندی کا نظام اعلی کارکردگی کی سرمایہ کاری کے ہدف کو کم کارکردگی کی سرمایہ کاری کے ہدف سے الگ کرسکتا ہے ، تاکہ طویل اور مختصر پوزیشنوں کی سرمایہ کاری کے اہداف کی حکمت عملی کی واپسی کو بہتر طور پر حاصل کیا جاسکے۔ لہذا ، درجہ بندی کا نظام تیار کرنا بہت ضروری ہے۔
درجہ بندی کا نظام کیسے بنایا جائے؟
ایک بار جب ہم نے درجہ بندی کا نظام طے کرلیا ہے تو ، ہم اس سے منافع کمانے کی امید کرتے ہیں۔ ہم سب سے اوپر کے سرمایہ کاری کے اہداف کو طویل اور سب سے نیچے کے سرمایہ کاری کے اہداف کو مختصر کرنے کے لئے ایک ہی مقدار میں سرمایہ کاری کرکے ایسا کرتے ہیں۔ اس سے یہ یقینی بنتا ہے کہ حکمت عملی صرف درجہ بندی کے معیار کے متناسب منافع حاصل کرے گی ، اور یہ
فرض کریں کہ آپ تمام سرمایہ کاری کے اہداف m کی درجہ بندی کر رہے ہیں ، اور آپ کے پاس سرمایہ کاری کے لئے n ڈالر ہیں ، اور آپ مجموعی طور پر 2p (جہاں m> 2p) پوزیشن رکھنا چاہتے ہیں۔ اگر سرمایہ کاری کے اعتراض کی درجہ بندی کی درجہ بندی 1 کی توقع ہے کہ بدترین کارکردگی کا مظاہرہ کرے گا تو ، سرمایہ کاری کے اعتراض کی درجہ بندی m کی توقع ہے کہ بہترین کارکردگی کا مظاہرہ کرے:
-
آپ کی درجہ بندی کی سرمایہ کاری کے اشیاء کے طور پر: 1،...، پی پوزیشن، 2/2p امریکی ڈالر کی سرمایہ کاری کے ہدف کو مختصر جانا.
-
آپ سرمایہ کاری کے اشیاء کو درجہ بندی کرتے ہیں: m-p،،،m پوزیشن، n/2p USD کے سرمایہ کاری کے ہدف کو طویل عرصے تک جائیں.
نوٹ: چونکہ قیمتوں میں اتار چڑھاؤ کی وجہ سے سرمایہ کاری کے موضوع کی قیمت ہمیشہ n / 2p کو یکساں طور پر تقسیم نہیں کرے گی ، اور کچھ سرمایہ کاری کے مضامین کو عددی اعداد کے ساتھ خریدا جانا چاہئے ، لہذا کچھ ناقص الگورتھم ہوں گے ، جو اس تعداد کے زیادہ سے زیادہ قریب ہونا چاہئے۔ n = 100000 اور p = 500 چلنے والی حکمت عملیوں کے ل we ، ہم دیکھتے ہیں کہ:
n/2p = 100000/1000 = 100
یہ 100 سے زیادہ قیمت والے اسکور کے ل a ایک بہت بڑا مسئلہ پیدا کرے گا (جیسے کہ خام مال کی فیوچر مارکیٹ) ، کیونکہ آپ ایک جزوی قیمت کے ساتھ پوزیشن نہیں کھول سکتے ہیں (یہ مسئلہ ڈیجیٹل کرنسی مارکیٹوں میں موجود نہیں ہے۔ ہم جزوی قیمت کے لین دین کو کم کرکے یا دارالحکومت میں اضافہ کرکے اس صورتحال کو کم کرتے ہیں۔
آئیے ایک فرضی مثال لیتے ہیں۔
- ایف ایم زیڈ کوانٹ پلیٹ فارم پر اپنا تحقیقی ماحول بنائیں
سب سے پہلے ، ہم آسانی سے کام کرنے کے ل our ، ہمیں اپنے تحقیقی ماحول کی تعمیر کرنے کی ضرورت ہے۔ اس مضمون میں ، ہم ایف ایم زیڈ کوانٹ پلیٹ فارم کا استعمال کرتے ہیں (FMZ.COM) اپنے تحقیقی ماحول کی تعمیر کے لئے ، بنیادی طور پر آسان اور تیز رفتار API انٹرفیس اور اس پلیٹ فارم کے اچھی طرح سے پیکڈ ڈوکر سسٹم کو استعمال کرنے کے لئے۔
ایف ایم زیڈ کوانٹ پلیٹ فارم کے سرکاری نام میں ، اس ڈوکر سسٹم کو ڈوکر سسٹم کہا جاتا ہے۔
براہ کرم میرے پچھلے مضمون کا حوالہ دیں کہ ڈوکر اور روبوٹ کو کیسے تعینات کیا جائے:https://www.fmz.com/bbs-topic/9864.
قارئین جو اپنے ڈاکرز کو تعینات کرنے کے لئے اپنا کلاؤڈ کمپیوٹنگ سرور خریدنا چاہتے ہیں وہ اس مضمون کا حوالہ دے سکتے ہیں:https://www.fmz.com/digest-topic/5711.
کلاؤڈ کمپیوٹنگ سرور اور ڈوکر سسٹم کو کامیابی کے ساتھ تعینات کرنے کے بعد، اگلا ہم پائیتھون کے موجودہ سب سے بڑے آرٹیفیکٹ انسٹال کریں گے: اناکونڈا
اس مضمون میں درکار تمام متعلقہ پروگرام ماحول (تبعیت لائبریریاں ، ورژن مینجمنٹ ، وغیرہ) کو سمجھنے کے ل the ، آسان ترین طریقہ ایناکونڈا کا استعمال کرنا ہے۔ یہ پیتھون ڈیٹا سائنس ماحولیاتی نظام اور انحصار لائبریری مینیجر ہے۔
Anaconda کی تنصیب کے طریقہ کار کے لئے، برائے مہربانی Anaconda کے سرکاری گائیڈ سے رجوع کریں:https://www.anaconda.com/distribution/.
اس مضمون میں پیتھون سائنسی کمپیوٹنگ میں دو مشہور اور اہم لائبریریاں نمپی اور پانڈا کا بھی استعمال کیا جائے گا۔
مذکورہ بالا بنیادی کام میرے پچھلے مضامین کا بھی حوالہ دے سکتا ہے ، جس میں اناکونڈا ماحول اور نومی اور پانڈا لائبریریوں کو ترتیب دینے کا طریقہ متعارف کرایا گیا ہے۔ تفصیلات کے لئے ، براہ کرم ملاحظہ کریں:https://www.fmz.com/digest-topic/9863.
ہم بے ترتیب سرمایہ کاری کے اہداف پیدا کرتے ہیں اور ان کی درجہ بندی کے لئے بے ترتیب عوامل۔ آئیے فرض کریں کہ ہماری مستقبل کی واپسی اصل میں ان عوامل کی اقدار پر منحصر ہے۔
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
import scipy
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
## PROBLEM SETUP ##
# Generate stocks and a random factor value for them
stock_names = ['stock ' + str(x) for x in range(10000)]
current_factor_values = np.random.normal(0, 1, 10000)
# Generate future returns for these are dependent on our factor values
future_returns = current_factor_values + np.random.normal(0, 1, 10000)
# Put both the factor values and returns into one dataframe
data = pd.DataFrame(index = stock_names, columns=['Factor Value','Returns'])
data['Factor Value'] = current_factor_values
data['Returns'] = future_returns
# Take a look
data.head(10)
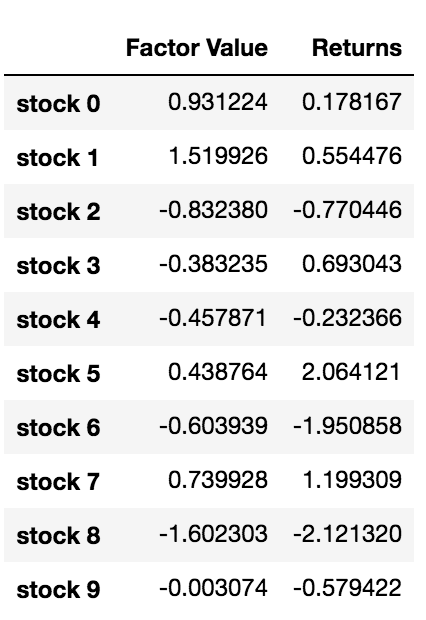
اب جب ہمارے پاس فیکٹر ویلیوز اور ریٹرنز ہیں، ہم دیکھ سکتے ہیں کہ کیا ہوتا ہے اگر ہم فیکٹر ویلیوز کی بنیاد پر سرمایہ کاری کے اہداف کی درجہ بندی کریں اور پھر لمبی اور مختصر پوزیشن کھولیں۔
# Rank stocks
ranked_data = data.sort_values('Factor Value')
# Compute the returns of each basket with a basket size 500, so total (10000/500) baskets
number_of_baskets = int(10000/500)
basket_returns = np.zeros(number_of_baskets)
for i in range(number_of_baskets):
start = i * 500
end = i * 500 + 500
basket_returns[i] = ranked_data[start:end]['Returns'].mean()
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
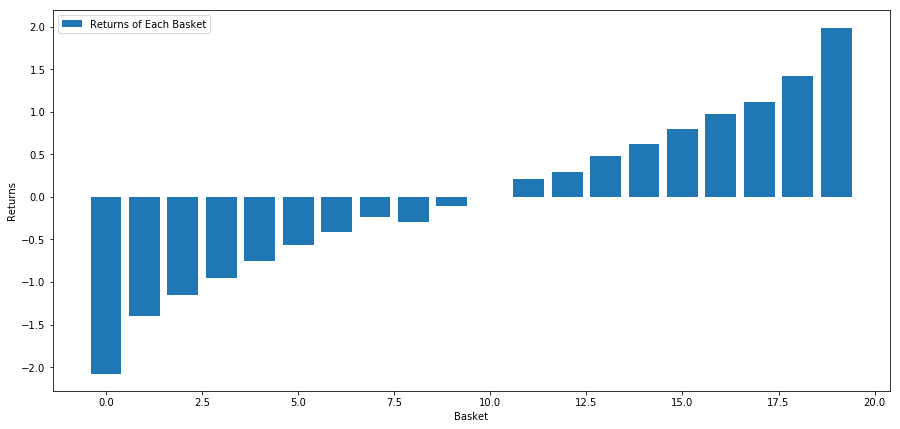
ہماری حکمت عملی یہ ہے کہ سرمایہ کاری کے ہدف والے پولز کی پہلی درجہ بندی والی ٹوکری میں طویل عرصے تک جانا؛ دسویں درجہ بندی والی ٹوکری سے کم جانا۔ اس حکمت عملی کے لئے واپسی یہ ہے:
basket_returns[number_of_baskets-1] - basket_returns[0]
نتیجہ: 4.172
ہمارے رینکنگ ماڈل پر پیسہ لگائیں تاکہ یہ اعلی کارکردگی والے سرمایہ کاری کے اہداف کو کم کارکردگی والے سرمایہ کاری کے اہداف سے الگ کرسکے۔
اس مضمون کے باقی حصے میں ، ہم درجہ بندی کے نظام کا جائزہ لینے کے طریقوں پر تبادلہ خیال کریں گے۔ درجہ بندی پر مبنی ثالثی کا فائدہ یہ ہے کہ یہ مارکیٹ کی خرابی سے متاثر نہیں ہوتا ہے ، اس کے بجائے مارکیٹ کی خرابی کا استعمال کیا جاسکتا ہے۔
آئیے ایک حقیقی دنیا کی مثال پر غور کریں۔
ہم نے ایس اینڈ پی 500 انڈیکس میں مختلف صنعتوں میں 32 اسٹاک کے اعداد و شمار لوڈ کیے اور ان کی درجہ بندی کرنے کی کوشش کی۔
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2010/01/01'
endDateStr = '2017/12/31'
cachedFolderName = '/Users/chandinijain/Auquan/yahooData/'
dataSetId = 'testLongShortTrading'
instrumentIds = ['ABT','AKS','AMGN','AMD','AXP','BK','BSX',
'CMCSA','CVS','DIS','EA','EOG','GLW','HAL',
'HD','LOW','KO','LLY','MCD','MET','NEM',
'PEP','PG','M','SWN','T','TGT',
'TWX','TXN','USB','VZ','WFC']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
price = 'adjClose'
آئیے درجہ بندی کی بنیاد کے طور پر ایک ماہ کی مدت کے لئے معیاری رفتار اشارے کا استعمال کریں۔
## Define normalized momentum
def momentum(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0) / dataDf.iloc[-1]
## Load relevant prices in a dataframe
data = ds.getBookDataByFeature()['Adj Close']
#Let's load momentum score and returns into separate dataframes
index = data.index
mscores = pd.DataFrame(index=index,columns=assetList)
mscores = momentum(data, 30)
returns = pd.DataFrame(index=index,columns=assetList)
day = 30
اب ہم اپنے اسٹاک کے رویے کا تجزیہ کریں گے اور دیکھیں گے کہ ہمارے اسٹاک کا انتخاب کردہ درجہ بندی کے عنصر میں مارکیٹ میں کس طرح کام کرتا ہے۔
ڈیٹا کا تجزیہ کریں
اسٹاک کا رویہ
آئیے دیکھتے ہیں کہ ہمارے منتخب کردہ اسٹاک کی ٹوکری ہمارے درجہ بندی کے ماڈل میں کس طرح کارکردگی کا مظاہرہ کرتی ہے۔ ایسا کرنے کے لئے ، آئیے ہم تمام اسٹاک کے لئے ہفتہ وار فارورڈ ریٹرن کا حساب لگائیں۔ پھر ہم ہر اسٹاک کی 1 ہفتہ کی فارورڈ ریٹرن اور پچھلے 30 دن کی رفتار کے مابین تعلق دیکھ سکتے ہیں۔ مثبت ارتباط دکھانے والے اسٹاک ٹرینڈ فالورز ہیں ، جبکہ منفی ارتباط دکھانے والے اسٹاک اوسط الٹ ہیں۔
# Calculate Forward returns
forward_return_day = 5
returns = data.shift(-forward_return_day)/data -1
returns.dropna(inplace = True)
# Calculate correlations between momentum and returns
correlations = pd.DataFrame(index = returns.columns, columns = ['Scores', 'pvalues'])
mscores = mscores[mscores.index.isin(returns.index)]
for i in correlations.index:
score, pvalue = stats.spearmanr(mscores[i], returns[i])
correlations[‘pvalues’].loc[i] = pvalue
correlations[‘Scores’].loc[i] = score
correlations.dropna(inplace = True)
correlations.sort_values('Scores', inplace=True)
l = correlations.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correlations['Scores'])
plt.xlabel('Stocks')
plt.xlim((1, l+1))
plt.xticks(range(1,1+l), correlations.index)
plt.legend(['Correlation over All Data'])
plt.ylabel('Correlation between %s day Momentum Scores and %s-day forward returns by Stock'%(day,forward_return_day));
plt.show()
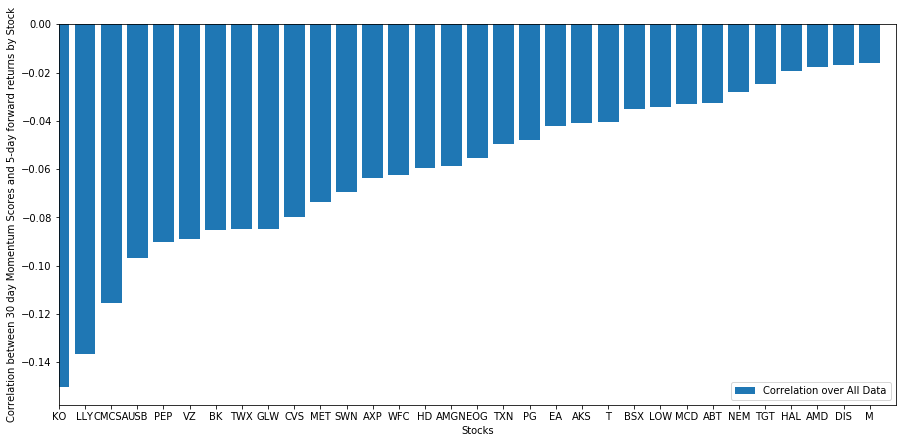
ہمارے تمام اسٹاک میں ایک خاص حد تک اوسط ردوبدل ہوتا ہے۔ (ظاہر ہے ، ہم نے جو کائنات منتخب کی ہے وہ اس طرح کام کرتی ہے۔) اس سے ہمیں پتہ چلتا ہے کہ اگر اسٹاک مومنٹم تجزیہ میں سرفہرست ہیں تو ، ہمیں توقع کرنی چاہئے کہ اگلے ہفتے ان کی کارکردگی خراب ہوگی۔
رفتار تجزیہ کے سکور اور واپسی کے درمیان تعلق
اگلا ، ہمیں اپنی درجہ بندی کے اسکور اور مارکیٹ کی مجموعی طور پر فارورڈ ریٹرن کے مابین ارتباط دیکھنے کی ضرورت ہے ، یعنی ، پیش گوئی شدہ ریٹرن ریٹرن اور ہماری درجہ بندی کے عنصر کے مابین تعلق۔ کیا اعلی سطح کا تعلق کم رشتہ دار واپسی کی پیش گوئی کرسکتا ہے ، یا اس کے برعکس؟
اس مقصد کے لئے، ہم تمام اسٹاک کی 30 دن کی رفتار اور 1 ہفتہ کے مستقبل کی واپسی کے درمیان روزانہ تعلق کا حساب لگاتے ہیں.
correl_scores = pd.DataFrame(index = returns.index.intersection(mscores.index), columns = ['Scores', 'pvalues'])
for i in correl_scores.index:
score, pvalue = stats.spearmanr(mscores.loc[i], returns.loc[i])
correl_scores['pvalues'].loc[i] = pvalue
correl_scores['Scores'].loc[i] = score
correl_scores.dropna(inplace = True)
l = correl_scores.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correl_scores['Scores'])
plt.hlines(np.mean(correl_scores['Scores']), 1,l+1, colors='r', linestyles='dashed')
plt.xlabel('Day')
plt.xlim((1, l+1))
plt.legend(['Mean Correlation over All Data', 'Daily Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
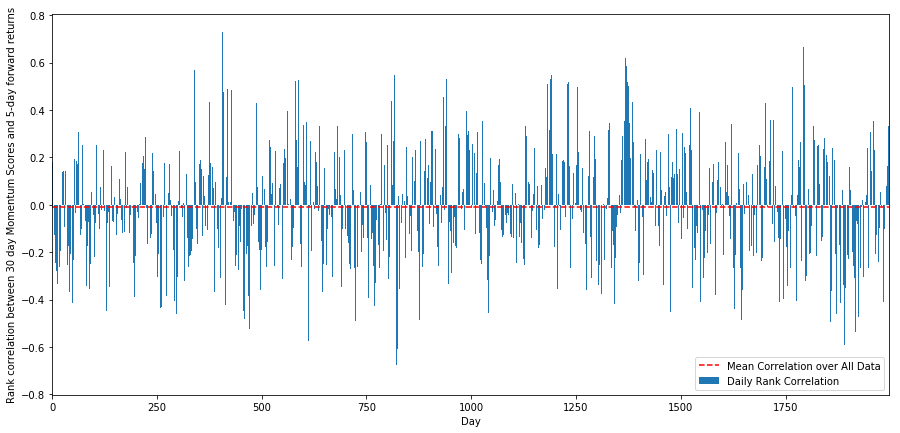
یومیہ ارتباط ایک بہت پیچیدہ لیکن بہت ہلکا تعلق ظاہر کرتا ہے (جس کی توقع کی جاتی ہے کیونکہ ہم نے کہا ہے کہ تمام اسٹاک اوسط پر واپس آجائیں گے۔) ہمیں ایک ماہ کی فارورڈ ریٹرن کے اوسط ماہانہ تعلق کو بھی دیکھنا ہوگا۔
monthly_mean_correl =correl_scores['Scores'].astype(float).resample('M').mean()
plt.figure(figsize=(15,7))
plt.bar(range(1,len(monthly_mean_correl)+1), monthly_mean_correl)
plt.hlines(np.mean(monthly_mean_correl), 1,len(monthly_mean_correl)+1, colors='r', linestyles='dashed')
plt.xlabel('Month')
plt.xlim((1, len(monthly_mean_correl)+1))
plt.legend(['Mean Correlation over All Data', 'Monthly Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
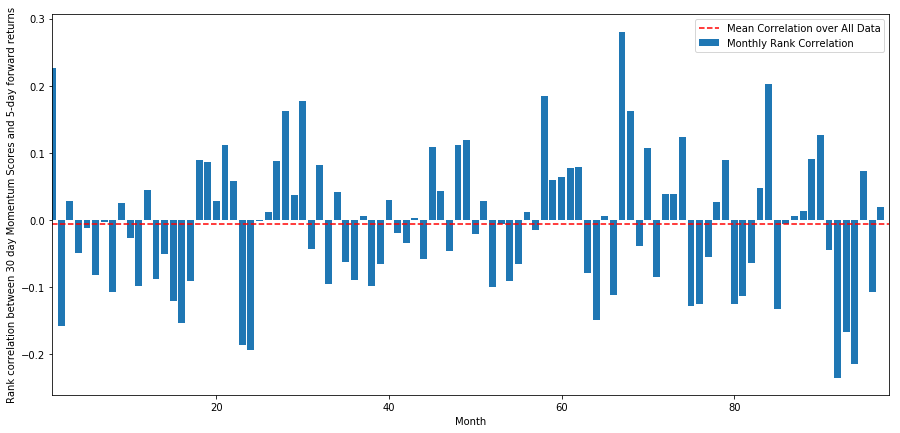
ہم دیکھ سکتے ہیں کہ اوسطا تعلق ایک بار پھر تھوڑا منفی ہے، لیکن یہ بھی ہر مہینے بہت بدلتا ہے.
اسٹاک کی ٹوکری پر اوسط منافع
ہم نے اپنی درجہ بندی سے لی گئی اسٹاک کی ٹوکری پر واپسی کا حساب لگایا ہے۔ اگر ہم تمام اسٹاک کو درجہ بندی کریں اور انہیں این این گروپس میں تقسیم کریں تو ہر گروپ کی اوسط واپسی کیا ہوگی؟
پہلا قدم ایک فنکشن بنانا ہے جو ہر مہینے دی گئی ہر ٹوکری کی اوسط واپسی اور درجہ بندی کا عنصر دے گا۔
def compute_basket_returns(factor, forward_returns, number_of_baskets, index):
data = pd.concat([factor.loc[index],forward_returns.loc[index]], axis=1)
# Rank the equities on the factor values
data.columns = ['Factor Value', 'Forward Returns']
data.sort_values('Factor Value', inplace=True)
# How many equities per basket
equities_per_basket = np.floor(len(data.index) / number_of_baskets)
basket_returns = np.zeros(number_of_baskets)
# Compute the returns of each basket
for i in range(number_of_baskets):
start = i * equities_per_basket
if i == number_of_baskets - 1:
# Handle having a few extra in the last basket when our number of equities doesn't divide well
end = len(data.index) - 1
else:
end = i * equities_per_basket + equities_per_basket
# Actually compute the mean returns for each basket
#s = data.index.iloc[start]
#e = data.index.iloc[end]
basket_returns[i] = data.iloc[int(start):int(end)]['Forward Returns'].mean()
return basket_returns
جب ہم اس اسکور کی بنیاد پر اسٹاک کی درجہ بندی کرتے ہیں تو ہم ہر ٹوکری کی اوسط واپسی کا حساب لگاتے ہیں۔ اس سے ہمیں ان کے تعلقات کو طویل عرصے تک سمجھنے کی اجازت دینی چاہئے۔
number_of_baskets = 8
mean_basket_returns = np.zeros(number_of_baskets)
resampled_scores = mscores.astype(float).resample('2D').last()
resampled_prices = data.astype(float).resample('2D').last()
resampled_scores.dropna(inplace=True)
resampled_prices.dropna(inplace=True)
forward_returns = resampled_prices.shift(-1)/resampled_prices -1
forward_returns.dropna(inplace = True)
for m in forward_returns.index.intersection(resampled_scores.index):
basket_returns = compute_basket_returns(resampled_scores, forward_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
mean_basket_returns /= l
print(mean_basket_returns)
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), mean_basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
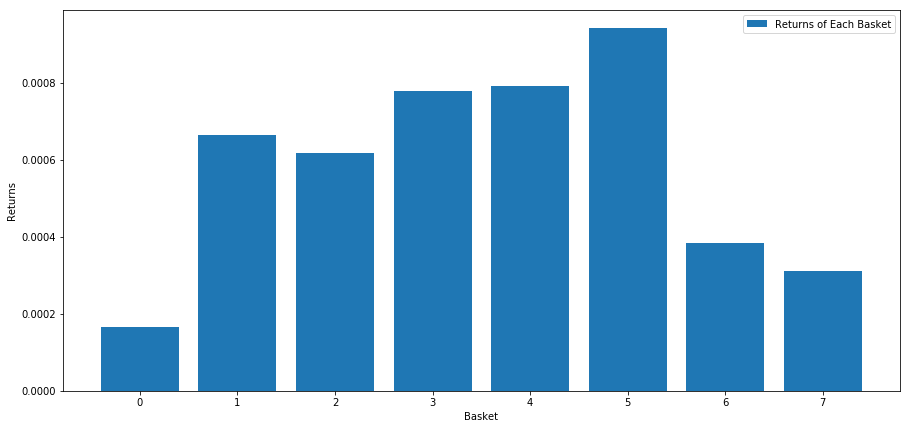
ایسا لگتا ہے کہ ہم اعلی کارکردگی کا مظاہرہ کرنے والوں کو کم کارکردگی کا مظاہرہ کرنے والوں سے الگ کر سکتے ہیں۔
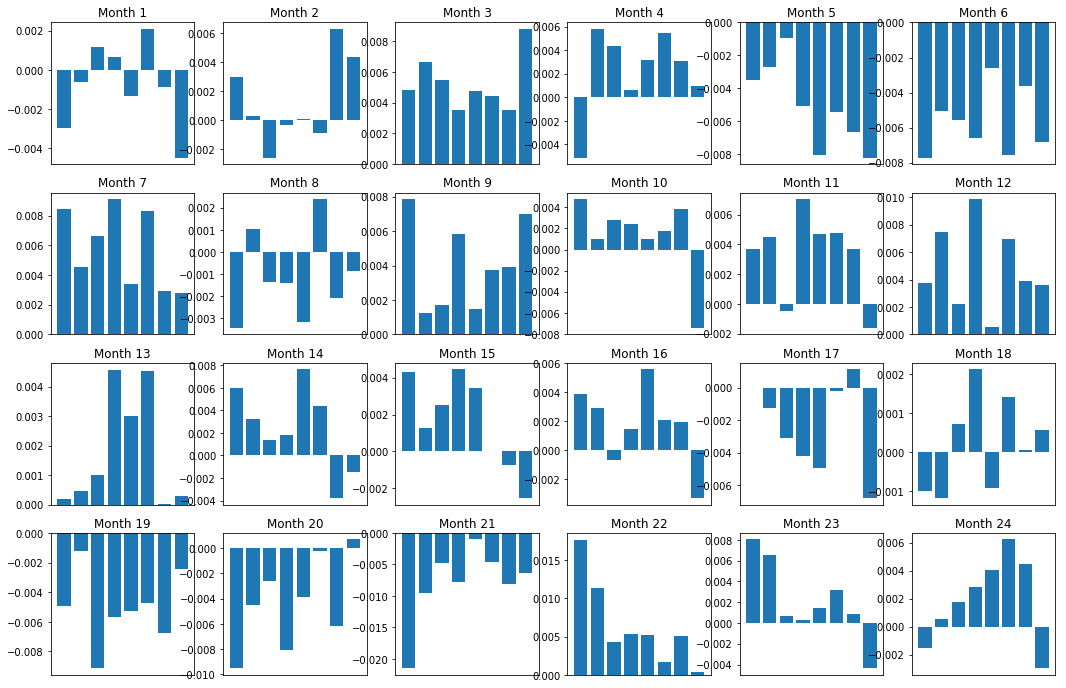
مارجن (بنیاد) کا تسلسل
یقینا ، یہ صرف اوسط تعلقات ہیں۔ اس بات کو سمجھنے کے لئے کہ یہ رشتہ کتنا مستقل ہے اور کیا ہم تجارت کرنے کے لئے تیار ہیں ، ہمیں وقت کے ساتھ ساتھ اس کے بارے میں اپنا نقطہ نظر اور رویہ تبدیل کرنا چاہئے۔ اگلا ، ہم پچھلے دو سالوں کے لئے ان کے ماہانہ سود کے حاشیے (بنیاد) کو دیکھیں گے۔ ہم مزید تبدیلیاں دیکھ سکتے ہیں اور اس بات کا تعین کرنے کے لئے مزید تجزیہ کرسکتے ہیں کہ آیا اس رفتار کے اسکور کی تجارت کی جاسکتی ہے۔
total_months = mscores.resample('M').last().index
months_to_plot = 24
monthly_index = total_months[:months_to_plot+1]
mean_basket_returns = np.zeros(number_of_baskets)
strategy_returns = pd.Series(index = monthly_index)
f, axarr = plt.subplots(1+int(monthly_index.size/6), 6,figsize=(18, 15))
for month in range(1, monthly_index.size):
temp_returns = forward_returns.loc[monthly_index[month-1]:monthly_index[month]]
temp_scores = resampled_scores.loc[monthly_index[month-1]:monthly_index[month]]
for m in temp_returns.index.intersection(temp_scores.index):
basket_returns = compute_basket_returns(temp_scores, temp_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
strategy_returns[monthly_index[month-1]] = mean_basket_returns[ number_of_baskets-1] - mean_basket_returns[0]
mean_basket_returns /= temp_returns.index.intersection(temp_scores.index).size
r = int(np.floor((month-1) / 6))
c = (month-1) % 6
axarr[r, c].bar(range(number_of_baskets), mean_basket_returns)
axarr[r, c].xaxis.set_visible(False)
axarr[r, c].set_title('Month ' + str(month))
plt.show()
plt.figure(figsize=(15,7))
plt.plot(strategy_returns)
plt.ylabel('Returns')
plt.xlabel('Month')
plt.plot(strategy_returns.cumsum())
plt.legend(['Monthly Strategy Returns', 'Cumulative Strategy Returns'])
plt.show()
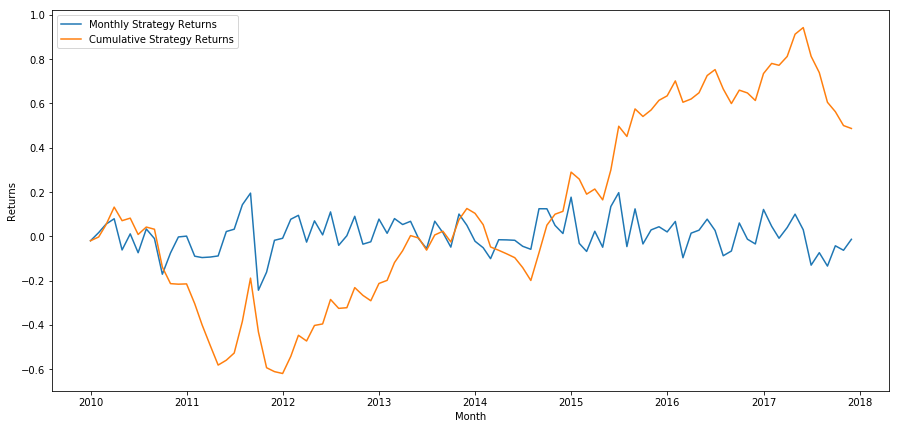
آخر میں، اگر ہم ہر مہینے آخری ٹوکری کو طویل اور پہلی ٹوکری کو مختصر کرتے ہیں، تو آئیے منافع کو دیکھیں (ہر سیکیورٹی کے لئے برابر سرمایہ مختص کرنے کا فرض کرتے ہوئے) ۔
total_return = strategy_returns.sum()
ann_return = 100*((1 + total_return)**(12.0 /float(strategy_returns.index.size))-1)
print('Annual Returns: %.2f%%'%ann_return)
سالانہ منافع کی شرح: 5.03٪
ہم دیکھ سکتے ہیں کہ ہمارے پاس درجہ بندی کا ایک بہت کمزور نظام ہے ، جو اعلی کارکردگی والے اسٹاک کو کم کارکردگی والے اسٹاک سے صرف آہستہ آہستہ الگ کرسکتا ہے۔ اس کے علاوہ ، یہ درجہ بندی کا نظام مستقل نہیں ہے اور ہر ماہ بہت مختلف ہوتا ہے۔
صحیح درجہ بندی کا نظام تلاش کریں
لمبی لمبی متوازن ایکویٹی حکمت عملی کو سمجھنے کے ل actually ، دراصل ، آپ کو صرف درجہ بندی کی اسکیم کا تعین کرنے کی ضرورت ہے۔ اس کے بعد کی ہر چیز مکینیکل ہے۔ ایک بار جب آپ کے پاس لمبی لمبی متوازن ایکویٹی حکمت عملی ہوجاتی ہے ، تو آپ بہت زیادہ تبدیلی کے بغیر مختلف درجہ بندی کے عوامل کا تبادلہ کرسکتے ہیں۔ یہ ہر بار تمام کوڈ کو ایڈجسٹ کرنے کی فکر کیے بغیر اپنے خیالات کو تیزی سے دہرانے کا ایک بہت ہی آسان طریقہ ہے۔
درجہ بندی کی اسکیم تقریبا کسی بھی ماڈل سے بھی آسکتی ہے۔ یہ ضروری نہیں ہے کہ یہ قدر پر مبنی فیکٹر ماڈل ہو۔ یہ مشین لرننگ ٹکنالوجی ہوسکتی ہے جو ایک ماہ قبل واپسی کی پیش گوئی کرسکتی ہے اور اس سطح کے مطابق درجہ بندی کرسکتی ہے۔
درجہ بندی کے نظام کا انتخاب اور تشخیص
درجہ بندی کا نظام طویل مدتی متوازن ایکویٹی حکمت عملی کا فائدہ اور سب سے اہم حصہ ہے۔ ایک اچھا درجہ بندی کا نظام منتخب کرنا ایک منظم منصوبہ ہے ، اور کوئی آسان جواب نہیں ہے۔
ایک اچھا نقطہ آغاز یہ ہے کہ موجودہ مشہور ٹیکنالوجیز کا انتخاب کریں اور دیکھیں کہ کیا آپ ان کو زیادہ منافع حاصل کرنے کے ل slightly تھوڑا سا ترمیم کرسکتے ہیں۔ یہاں ہم کئی نقطہ آغاز پر تبادلہ خیال کریں گے:
-
کلون اور ایڈجسٹمنٹ: ایک ایسا موضوع منتخب کریں جس پر اکثر تبادلہ خیال کیا جاتا ہے ، اور دیکھیں کہ کیا آپ فوائد حاصل کرنے کے ل slightly اس میں قدرے ترمیم کرسکتے ہیں۔ عام طور پر ، عوامی طور پر دستیاب عوامل میں اب تجارتی سگنل نہیں ہوں گے ، کیونکہ وہ مارکیٹ سے مکمل طور پر الگ ہوگئے ہیں۔ لیکن بعض اوقات وہ آپ کو صحیح سمت میں لے جائیں گے۔
-
قیمتوں کا تعین کرنے کا ماڈل: کوئی بھی ماڈل جو مستقبل کی واپسی کی پیش گوئی کرتا ہے وہ ایک ایسا عنصر ہوسکتا ہے جس کا ممکنہ طور پر آپ کے تجارتی اشیاء کی ٹوکری کو درجہ بندی کرنے کے لئے استعمال کیا جاسکتا ہے۔ آپ کسی بھی پیچیدہ قیمتوں کا تعین کرنے کا ماڈل لے سکتے ہیں اور اسے درجہ بندی کے نظام میں تبدیل کرسکتے ہیں۔
-
قیمت پر مبنی عوامل (تکنیکی اشارے): قیمت پر مبنی عوامل ، جیسا کہ آج تبادلہ خیال کیا گیا ہے ، ہر ایکوئٹی کی تاریخی قیمت کے بارے میں معلومات حاصل کرتے ہیں اور اس کا استعمال فیکٹر ویلیوز پیدا کرنے کے لئے کرتے ہیں۔ مثال کے طور پر متحرک اوسط اشارے ، رفتار کے اشارے ، یا اتار چڑھاؤ کے اشارے ہوسکتے ہیں۔
-
رجعت اور رفتار: یہ نوٹ کرنے کے قابل ہے کہ کچھ عوامل کا خیال ہے کہ ایک بار قیمتیں ایک ہی سمت میں منتقل ہوجاتی ہیں ، تو وہ ایسا کرتے رہیں گے ، جبکہ کچھ عوامل بالکل اس کے برعکس ہیں۔ دونوں مختلف وقت کے افقوں اور اثاثوں کے لئے موثر ماڈل ہیں ، اور یہ مطالعہ کرنا ضروری ہے کہ بنیادی رویہ رفتار یا رجعت پر مبنی ہے یا نہیں۔
-
بنیادی عنصر (قیمت پر مبنی): یہ بنیادی اقدار کا ایک مجموعہ ہے ، جیسے پی ای ، منافع وغیرہ۔ بنیادی قدر میں کمپنی کے حقیقی دنیا کے حقائق سے متعلق معلومات شامل ہیں ، لہذا یہ بہت سے پہلوؤں میں قیمت سے زیادہ طاقتور ہوسکتا ہے۔
آخر کار ، ترقی کا پیش گوئی کرنے والا ایک ہتھیاروں کی دوڑ ہے ، اور آپ ایک قدم آگے رہنے کی کوشش کر رہے ہیں۔ عوامل مارکیٹ سے ثالثی کریں گے اور ان کی مفید زندگی ہوگی ، لہذا آپ کو مستقل طور پر یہ معلوم کرنے کے لئے کام کرنا ہوگا کہ آپ کے عوامل نے کتنے بحرانوں کا سامنا کیا ہے اور ان کی جگہ لینے کے لئے کون سے نئے عوامل استعمال کیے جاسکتے ہیں۔
دیگر تحفظات
- دوبارہ توازن کی تعدد
ہر درجہ بندی کا نظام قدرے مختلف وقت کے فریم میں واپسی کی پیش گوئی کرتا ہے۔ قیمت پر مبنی اوسط رجعت چند دنوں میں پیش گوئی کی جاسکتی ہے ، جبکہ قدر پر مبنی فیکٹر ماڈل چند مہینوں میں پیش گوئی کرسکتا ہے۔ یہ ضروری ہے کہ ماڈل کی پیش گوئی کرنے والی وقت کی حد کا تعین کریں ، اور حکمت عملی کو انجام دینے سے پہلے اعدادوشمار کی توثیق کریں۔ یقینا ، آپ دوبارہ توازن کی تعدد کو بہتر بنانے کی کوشش کرکے زیادہ فٹ نہیں ہونا چاہتے ہیں۔ آپ کو لازمی طور پر ایک بے ترتیب تعدد مل جائے گا جو دوسری تعدد سے بہتر ہے۔ ایک بار جب آپ نے درجہ بندی کے منصوبے کی پیش گوئی کی وقت کی حد کا تعین کرلیا ہے تو ، اپنے ماڈل کا مکمل استعمال کرنے کے ل about اس تعدد پر دوبارہ توازن کرنے کی کوشش کریں۔
- سرمایہ کاری کی صلاحیت اور لین دین کے اخراجات
ہر حکمت عملی میں کم سے کم اور زیادہ سے زیادہ سرمایہ حجم ہوتا ہے ، اور کم سے کم حد عام طور پر لین دین کی لاگت سے طے ہوتی ہے۔
بہت زیادہ اسٹاک کی تجارت سے لین دین کے اخراجات زیادہ ہوں گے۔ اگر آپ 1،000 حصص خریدنا چاہتے ہیں تو ، ہر ری بیلنسنگ پر اس کی قیمت ہزاروں ڈالر ہوگی۔ آپ کے سرمایہ کی بنیاد کافی زیادہ ہونی چاہئے تاکہ آپ کی حکمت عملی سے پیدا ہونے والی واپسی کا ایک چھوٹا سا حصہ لین دین کے اخراجات پر مشتمل ہو۔ مثال کے طور پر ، اگر آپ کا سرمایہ 100،000 ڈالر ہے اور آپ کی حکمت عملی ماہانہ 1٪ (1،000 ڈالر) کمائی کرتی ہے تو ، یہ تمام واپسی لین دین کے اخراجات کے ذریعہ استعمال ہوگی۔ آپ کو 1،000 سے زیادہ حصص حاصل کرنے کے لئے لاکھوں ڈالر کی سرمایہ کاری کے ساتھ حکمت عملی چلانے کی ضرورت ہے۔
سب سے کم اثاثہ کی حد بنیادی طور پر تجارت شدہ حصص کی تعداد پر منحصر ہے۔ تاہم ، زیادہ سے زیادہ صلاحیت بھی بہت زیادہ ہے۔ لمبی مختصر متوازن ایکویٹی حکمت عملی فائدہ کھونے کے بغیر سیکڑوں لاکھوں ڈالر کی تجارت کرسکتی ہے۔ یہ ایک حقیقت ہے ، کیونکہ اس حکمت عملی میں نسبتا rarly غیر متوازن ہوتا ہے۔ جب کل اثاثوں کو تجارت شدہ اسٹاک کی تعداد سے تقسیم کیا جاتا ہے تو ہر ایک حصص کی ڈالر کی قیمت بہت کم ہوگی۔ آپ کو اس بارے میں فکر کرنے کی ضرورت نہیں ہے کہ آیا آپ کا تجارتی حجم مارکیٹ کو متاثر کرے گا۔ فرض کریں کہ آپ 1،000 حصص ، یعنی 100،000،000 ڈالر کی تجارت کرتے ہیں۔ اگر آپ ہر ماہ پورے پورٹ فولیو کو دوبارہ متوازن کرتے ہیں تو ، ہر اسٹاک صرف ایک ماہ میں 100،000 ڈالر کی تجارت کرے گا ، جو زیادہ تر سیکیورٹیز کے لئے ایک اہم مارکیٹ ہونے کے لئے کافی نہیں ہے۔
- کریپٹوکرنسی مارکیٹ میں بنیادی تجزیہ کی مقدار: اعداد و شمار کو اپنے لئے بولنے دیں!
- ایک بار پھر ، ہم نے ایک بار پھر اس بات کا یقین کرلیا ہے کہ یہ ایک بہت بڑا مسئلہ ہے ، لیکن ہم اس کے بارے میں مزید نہیں جانتے ہیں۔
- کوانٹائزڈ ٹرانزیکشنز کے لیے ایک لازمی ٹول۔
- ہر چیز پر قابو پانا - ایف ایم زیڈ ٹریڈنگ ٹرمینل کا نیا ورژن (ٹی آر بی آربیٹریج سورس کوڈ کے ساتھ) کا تعارف
- FMZ کے نئے ورژن کے ٹرانزیکشن ٹرمینل کے بارے میں سب کچھ جاننے کے لئے یہاں کلک کریں
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (II)
- 80 لائنوں کے کوڈ میں ہائی فریکوئینسی حکمت عملی کے ساتھ دماغ کے بغیر سیلز بوٹس کا استحصال کیسے کریں
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (ب)
- 80 لائنوں کے کوڈ کے ساتھ ہائی فریکوئینسی کی حکمت عملی کے ساتھ فروخت کے لیے بے دماغ روبوٹ کا استحصال کیسے کیا گیا؟
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (I)
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (1)