Đạt được các chiến lược vốn chủ sở hữu cân bằng với sự điều chỉnh có trật tự
Tác giả:Lydia., Tạo: 2023-01-09 13:46:21, Cập nhật: 2023-09-20 10:13:35
Đạt được các chiến lược vốn chủ sở hữu cân bằng với sự điều chỉnh có trật tự
Trong bài viết trước (https://www.fmz.com/bbs-topic/9862), chúng tôi giới thiệu các chiến lược giao dịch cặp và chứng minh cách tạo và tự động hóa các chiến lược giao dịch bằng cách sử dụng dữ liệu và phân tích toán học.
Chiến lược cổ phần cân bằng các vị trí ngắn dài là một phần mở rộng tự nhiên của chiến lược giao dịch cặp áp dụng cho một giỏ các đối tượng giao dịch. Nó đặc biệt phù hợp với các thị trường giao dịch với nhiều loại và mối quan hệ lẫn nhau, chẳng hạn như thị trường tiền kỹ thuật số và thị trường tương lai hàng hóa.
Nguyên tắc cơ bản
Chiến lược cổ phần cân bằng các vị trí ngắn dài là đi dài và đi ngắn một giỏ các mục tiêu giao dịch đồng thời. Cũng giống như giao dịch cặp, nó xác định mục tiêu đầu tư nào rẻ và mục tiêu đầu tư nào đắt tiền. Sự khác biệt là chiến lược cổ phần cân bằng các vị trí ngắn dài sẽ sắp xếp tất cả các mục tiêu đầu tư trong một hồ bơi lựa chọn cổ phiếu để xác định mục tiêu đầu tư nào tương đối rẻ hoặc đắt tiền. Sau đó, nó sẽ đi dài các mục tiêu đầu tư n trên dựa trên thứ hạng, và đi ngắn các mục tiêu đầu tư n dưới cùng với cùng một số tiền (tổng giá trị các vị trí dài = tổng giá trị các vị trí ngắn).
Bạn có nhớ những gì chúng tôi đã nói rằng giao dịch cặp là một chiến lược trung lập thị trường? Điều tương tự cũng đúng đối với chiến lược cổ phần cân bằng các vị trí ngắn dài, bởi vì số lượng tương đương các vị trí dài và ngắn đảm bảo rằng chiến lược sẽ duy trì trung lập thị trường (không bị ảnh hưởng bởi biến động thị trường). Chiến lược cũng mạnh mẽ về mặt thống kê; Bằng cách xếp hạng các mục tiêu đầu tư và giữ các vị trí dài, bạn có thể mở các vị trí trên mô hình xếp hạng của mình nhiều lần, không chỉ một lần rủi ro vị trí mở. Bạn đang hoàn toàn đặt cược vào chất lượng của kế hoạch xếp hạng của mình.
Hệ thống xếp hạng là gì?
Kế hoạch xếp hạng là một mô hình có thể gán ưu tiên cho từng đối tượng đầu tư theo hiệu suất dự kiến. Các yếu tố có thể là các yếu tố giá trị, các chỉ số kỹ thuật, các mô hình định giá hoặc sự kết hợp của tất cả các yếu tố trên. Ví dụ, bạn có thể sử dụng các chỉ số động lực để xếp hạng một loạt các mục tiêu đầu tư theo dõi xu hướng: dự kiến các mục tiêu đầu tư có động lực cao nhất sẽ tiếp tục hoạt động tốt và nhận được thứ hạng cao nhất; Đối tượng đầu tư có động lực thấp nhất có hiệu suất tồi tệ nhất và lợi nhuận thấp nhất.
Thành công của chiến lược này hầu như hoàn toàn phụ thuộc vào hệ thống xếp hạng được sử dụng, tức là, hệ thống xếp hạng của bạn có thể tách mục tiêu đầu tư hiệu suất cao khỏi mục tiêu đầu tư hiệu suất thấp, để nhận ra tốt hơn lợi nhuận của chiến lược của các mục tiêu đầu tư vị trí dài và ngắn.
Làm thế nào để tạo ra một kế hoạch xếp hạng?
Một khi chúng tôi đã xác định các kế hoạch xếp hạng, chúng tôi hy vọng sẽ kiếm được lợi nhuận từ nó. Chúng tôi làm điều này bằng cách đầu tư cùng một số tiền vốn để đi dài các mục tiêu đầu tư hàng đầu và đi ngắn các mục tiêu đầu tư dưới cùng. Điều này đảm bảo rằng chiến lược sẽ chỉ tạo ra lợi nhuận theo tỷ lệ tương ứng với chất lượng của bảng xếp hạng, và nó sẽ là thị trường trung lập.
Giả sử bạn đang xếp hạng tất cả các mục tiêu đầu tư m, và bạn có n đô la để đầu tư, và bạn muốn giữ tổng cộng 2p (nơi m>2p) các vị trí.
-
Bạn xếp hạng các đối tượng đầu tư như: 1,...,p vị trí, đi ngắn mục tiêu đầu tư 2/2p USD.
-
Bạn xếp hạng các đối tượng đầu tư như: m-p,...,m vị trí, đi dài mục tiêu đầu tư n/2p USD.
Lưu ý: Vì giá của đầu tư gây ra bởi biến động giá sẽ không phải lúc nào cũng chia n/2p đồng đều, và một số đầu tư phải được mua với số nguyên, sẽ có một số thuật toán không chính xác, nên càng gần với con số này càng tốt.
n/2p = 100000/1000 = 100
Điều này sẽ gây ra một vấn đề lớn đối với điểm số với giá lớn hơn 100 (như thị trường tương lai hàng hóa), bởi vì bạn không thể mở một vị trí với giá phân số (vấn đề này không tồn tại trong thị trường tiền kỹ thuật số).
Hãy lấy một ví dụ giả thuyết.
- Xây dựng môi trường nghiên cứu trên nền tảng FMZ Quant
Trước hết, để làm việc trơn tru, chúng ta cần xây dựng môi trường nghiên cứu của mình.FMZ.COM) để xây dựng môi trường nghiên cứu của chúng tôi, chủ yếu để sử dụng giao diện API thuận tiện và nhanh chóng và hệ thống Docker được đóng gói tốt của nền tảng này sau đó.
Trong tên chính thức của nền tảng FMZ Quant, hệ thống Docker này được gọi là hệ thống Docker.
Vui lòng tham khảo bài viết trước của tôi về cách triển khai một docker và robot:https://www.fmz.com/bbs-topic/9864.
Người đọc muốn mua máy chủ điện toán đám mây của riêng mình để triển khai các dockers có thể tham khảo bài viết này:https://www.fmz.com/digest-topic/5711.
Sau khi triển khai thành công máy chủ điện toán đám mây và hệ thống docker, tiếp theo chúng tôi sẽ cài đặt hiện tại lớn nhất hiện vật của Python: Anaconda
Để thực hiện tất cả các môi trường chương trình có liên quan (thư viện phụ thuộc, quản lý phiên bản, v.v.) được yêu cầu trong bài viết này, cách đơn giản nhất là sử dụng Anaconda.
Đối với phương pháp cài đặt của Anaconda, vui lòng tham khảo hướng dẫn chính thức của Anaconda:https://www.anaconda.com/distribution/.
Bài viết này cũng sẽ sử dụng numpy và panda, hai thư viện phổ biến và quan trọng trong máy tính khoa học Python.
Công trình cơ bản trên cũng có thể tham chiếu đến các bài viết trước của tôi, giới thiệu cách thiết lập môi trường Anaconda và thư viện numpy và panda.https://www.fmz.com/digest-topic/9863.
Chúng ta tạo ra các mục tiêu đầu tư ngẫu nhiên và các yếu tố ngẫu nhiên để xếp hạng chúng.
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
import scipy
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
## PROBLEM SETUP ##
# Generate stocks and a random factor value for them
stock_names = ['stock ' + str(x) for x in range(10000)]
current_factor_values = np.random.normal(0, 1, 10000)
# Generate future returns for these are dependent on our factor values
future_returns = current_factor_values + np.random.normal(0, 1, 10000)
# Put both the factor values and returns into one dataframe
data = pd.DataFrame(index = stock_names, columns=['Factor Value','Returns'])
data['Factor Value'] = current_factor_values
data['Returns'] = future_returns
# Take a look
data.head(10)
Bây giờ chúng ta có giá trị và lợi nhuận của các yếu tố, chúng ta có thể thấy điều gì sẽ xảy ra nếu chúng ta xếp hạng các mục tiêu đầu tư dựa trên giá trị của các yếu tố và sau đó mở các vị trí dài và ngắn.
# Rank stocks
ranked_data = data.sort_values('Factor Value')
# Compute the returns of each basket with a basket size 500, so total (10000/500) baskets
number_of_baskets = int(10000/500)
basket_returns = np.zeros(number_of_baskets)
for i in range(number_of_baskets):
start = i * 500
end = i * 500 + 500
basket_returns[i] = ranked_data[start:end]['Returns'].mean()
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
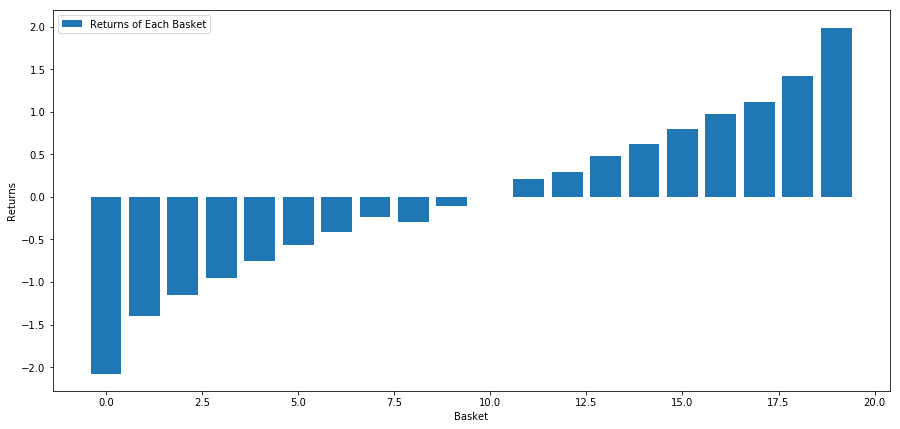
Chiến lược của chúng tôi là đi dài giỏ xếp hạng đầu tiên của các nhóm mục tiêu đầu tư; đi ngắn của giỏ xếp hạng thứ mười.
basket_returns[number_of_baskets-1] - basket_returns[0]
Kết quả là: 4.172
Đầu tư vào mô hình xếp hạng của chúng tôi để nó có thể tách mục tiêu đầu tư hiệu suất cao khỏi mục tiêu đầu tư hiệu suất thấp.
Trong phần còn lại của bài viết này, chúng ta sẽ thảo luận về cách đánh giá hệ thống xếp hạng.
Hãy xem xét một ví dụ thực tế.
Chúng tôi tải dữ liệu cho 32 cổ phiếu trong các ngành công nghiệp khác nhau trong chỉ số S&P 500 và cố gắng xếp hạng chúng.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2010/01/01'
endDateStr = '2017/12/31'
cachedFolderName = '/Users/chandinijain/Auquan/yahooData/'
dataSetId = 'testLongShortTrading'
instrumentIds = ['ABT','AKS','AMGN','AMD','AXP','BK','BSX',
'CMCSA','CVS','DIS','EA','EOG','GLW','HAL',
'HD','LOW','KO','LLY','MCD','MET','NEM',
'PEP','PG','M','SWN','T','TGT',
'TWX','TXN','USB','VZ','WFC']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
price = 'adjClose'
Chúng ta hãy sử dụng chỉ số động lực tiêu chuẩn cho một khoảng thời gian một tháng làm cơ sở xếp hạng.
## Define normalized momentum
def momentum(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0) / dataDf.iloc[-1]
## Load relevant prices in a dataframe
data = ds.getBookDataByFeature()['Adj Close']
#Let's load momentum score and returns into separate dataframes
index = data.index
mscores = pd.DataFrame(index=index,columns=assetList)
mscores = momentum(data, 30)
returns = pd.DataFrame(index=index,columns=assetList)
day = 30
Bây giờ chúng ta sẽ phân tích hành vi của cổ phiếu của chúng tôi và xem cổ phiếu của chúng tôi hoạt động như thế nào trên thị trường trong yếu tố xếp hạng mà chúng tôi chọn.
Phân tích dữ liệu
Hành vi cổ phiếu
Hãy xem giỏ cổ phiếu được chọn của chúng tôi hoạt động như thế nào trong mô hình xếp hạng của chúng tôi. Để làm điều này, chúng ta hãy tính toán lợi nhuận hàng tuần cho tất cả các cổ phiếu. Sau đó chúng ta có thể thấy mối tương quan giữa lợi nhuận 1 tuần cho mỗi cổ phiếu và đà tăng của 30 ngày trước đó. Các cổ phiếu cho thấy mối tương quan tích cực là những người theo xu hướng, trong khi các cổ phiếu cho thấy mối tương quan tiêu cực là sự đảo ngược trung bình.
# Calculate Forward returns
forward_return_day = 5
returns = data.shift(-forward_return_day)/data -1
returns.dropna(inplace = True)
# Calculate correlations between momentum and returns
correlations = pd.DataFrame(index = returns.columns, columns = ['Scores', 'pvalues'])
mscores = mscores[mscores.index.isin(returns.index)]
for i in correlations.index:
score, pvalue = stats.spearmanr(mscores[i], returns[i])
correlations[‘pvalues’].loc[i] = pvalue
correlations[‘Scores’].loc[i] = score
correlations.dropna(inplace = True)
correlations.sort_values('Scores', inplace=True)
l = correlations.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correlations['Scores'])
plt.xlabel('Stocks')
plt.xlim((1, l+1))
plt.xticks(range(1,1+l), correlations.index)
plt.legend(['Correlation over All Data'])
plt.ylabel('Correlation between %s day Momentum Scores and %s-day forward returns by Stock'%(day,forward_return_day));
plt.show()
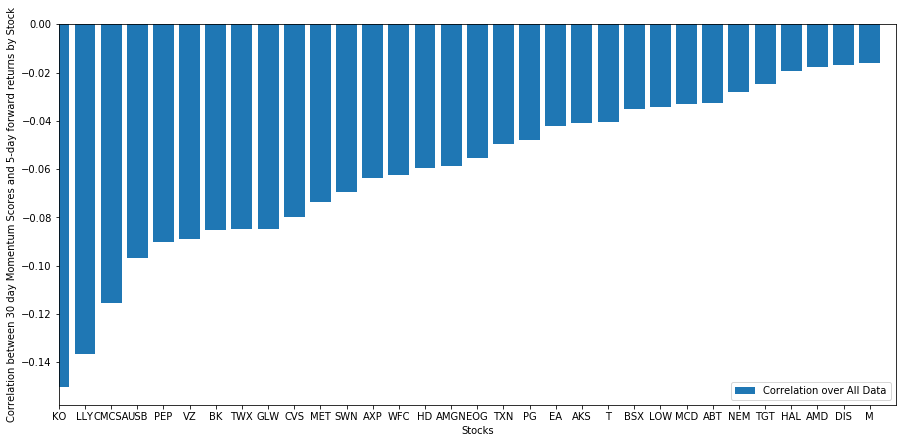
Tất cả các cổ phiếu của chúng tôi đều có sự đảo ngược trung bình đến một mức độ nhất định! (Rõ ràng, vũ trụ chúng tôi đã chọn hoạt động như thế này.) Điều này cho chúng ta biết rằng nếu cổ phiếu xếp hạng hàng đầu trong phân tích động lượng, chúng ta nên mong đợi chúng hoạt động kém vào tuần tới.
Sự tương quan giữa xếp hạng điểm phân tích động lực và lợi nhuận
Tiếp theo, chúng ta cần xem mối tương quan giữa điểm xếp hạng của chúng ta và tổng lợi nhuận tương lai của thị trường, nghĩa là mối quan hệ giữa tỷ lệ lợi nhuận dự đoán và yếu tố xếp hạng của chúng ta.
Để làm được điều này, chúng tôi tính toán mối tương quan hàng ngày giữa động lực 30 ngày của tất cả các cổ phiếu và lợi nhuận 1 tuần.
correl_scores = pd.DataFrame(index = returns.index.intersection(mscores.index), columns = ['Scores', 'pvalues'])
for i in correl_scores.index:
score, pvalue = stats.spearmanr(mscores.loc[i], returns.loc[i])
correl_scores['pvalues'].loc[i] = pvalue
correl_scores['Scores'].loc[i] = score
correl_scores.dropna(inplace = True)
l = correl_scores.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correl_scores['Scores'])
plt.hlines(np.mean(correl_scores['Scores']), 1,l+1, colors='r', linestyles='dashed')
plt.xlabel('Day')
plt.xlim((1, l+1))
plt.legend(['Mean Correlation over All Data', 'Daily Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
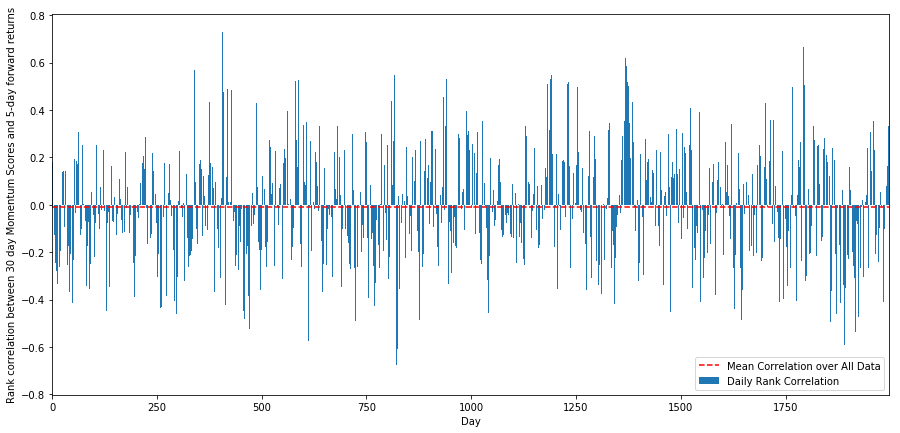
Các mối tương quan hàng ngày cho thấy một mối tương quan rất phức tạp nhưng rất nhẹ (được mong đợi vì chúng tôi đã nói rằng tất cả các cổ phiếu sẽ trở lại mức trung bình).
monthly_mean_correl =correl_scores['Scores'].astype(float).resample('M').mean()
plt.figure(figsize=(15,7))
plt.bar(range(1,len(monthly_mean_correl)+1), monthly_mean_correl)
plt.hlines(np.mean(monthly_mean_correl), 1,len(monthly_mean_correl)+1, colors='r', linestyles='dashed')
plt.xlabel('Month')
plt.xlim((1, len(monthly_mean_correl)+1))
plt.legend(['Mean Correlation over All Data', 'Monthly Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
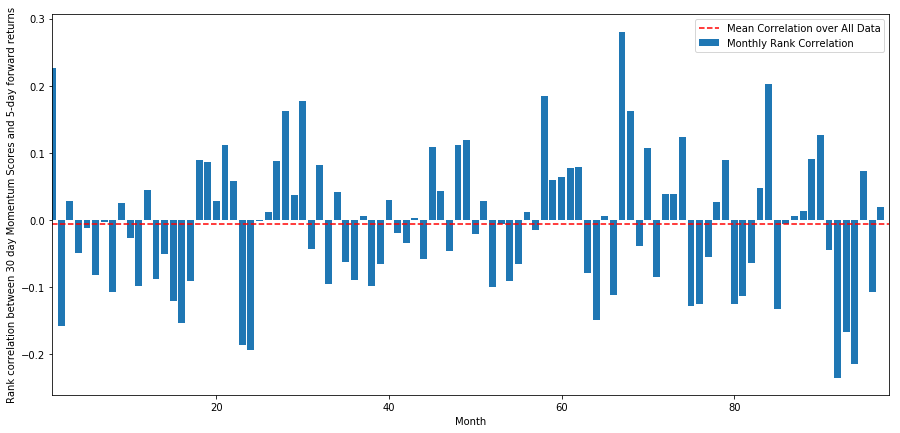
Chúng ta có thể thấy rằng mối tương quan trung bình lại âm một chút, nhưng nó cũng thay đổi rất nhiều mỗi tháng.
Lợi nhuận trung bình trên một giỏ cổ phiếu
Chúng tôi đã tính toán lợi nhuận trên một giỏ cổ phiếu lấy từ bảng xếp hạng của chúng tôi. Nếu chúng tôi xếp hạng tất cả các cổ phiếu và chia chúng thành nn nhóm, lợi nhuận trung bình của mỗi nhóm là gì?
Bước đầu tiên là tạo một hàm sẽ cung cấp lợi nhuận trung bình và yếu tố xếp hạng của mỗi giỏ cho mỗi tháng.
def compute_basket_returns(factor, forward_returns, number_of_baskets, index):
data = pd.concat([factor.loc[index],forward_returns.loc[index]], axis=1)
# Rank the equities on the factor values
data.columns = ['Factor Value', 'Forward Returns']
data.sort_values('Factor Value', inplace=True)
# How many equities per basket
equities_per_basket = np.floor(len(data.index) / number_of_baskets)
basket_returns = np.zeros(number_of_baskets)
# Compute the returns of each basket
for i in range(number_of_baskets):
start = i * equities_per_basket
if i == number_of_baskets - 1:
# Handle having a few extra in the last basket when our number of equities doesn't divide well
end = len(data.index) - 1
else:
end = i * equities_per_basket + equities_per_basket
# Actually compute the mean returns for each basket
#s = data.index.iloc[start]
#e = data.index.iloc[end]
basket_returns[i] = data.iloc[int(start):int(end)]['Forward Returns'].mean()
return basket_returns
Khi chúng ta xếp hạng cổ phiếu dựa trên điểm số này, chúng ta tính toán lợi nhuận trung bình của mỗi giỏ. Điều này sẽ cho phép chúng ta hiểu mối quan hệ của chúng trong một thời gian dài.
number_of_baskets = 8
mean_basket_returns = np.zeros(number_of_baskets)
resampled_scores = mscores.astype(float).resample('2D').last()
resampled_prices = data.astype(float).resample('2D').last()
resampled_scores.dropna(inplace=True)
resampled_prices.dropna(inplace=True)
forward_returns = resampled_prices.shift(-1)/resampled_prices -1
forward_returns.dropna(inplace = True)
for m in forward_returns.index.intersection(resampled_scores.index):
basket_returns = compute_basket_returns(resampled_scores, forward_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
mean_basket_returns /= l
print(mean_basket_returns)
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), mean_basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
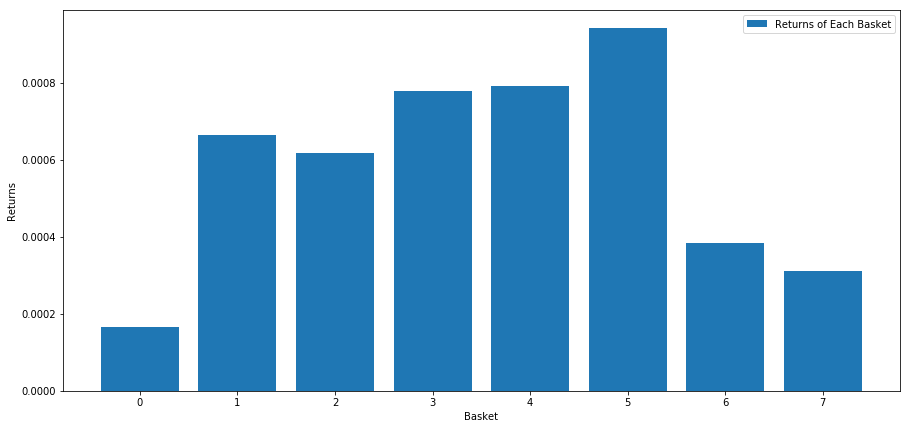
Có vẻ như chúng ta có thể tách những người có hiệu suất cao khỏi những người có hiệu suất thấp.
Tính nhất quán của biên (dựa)
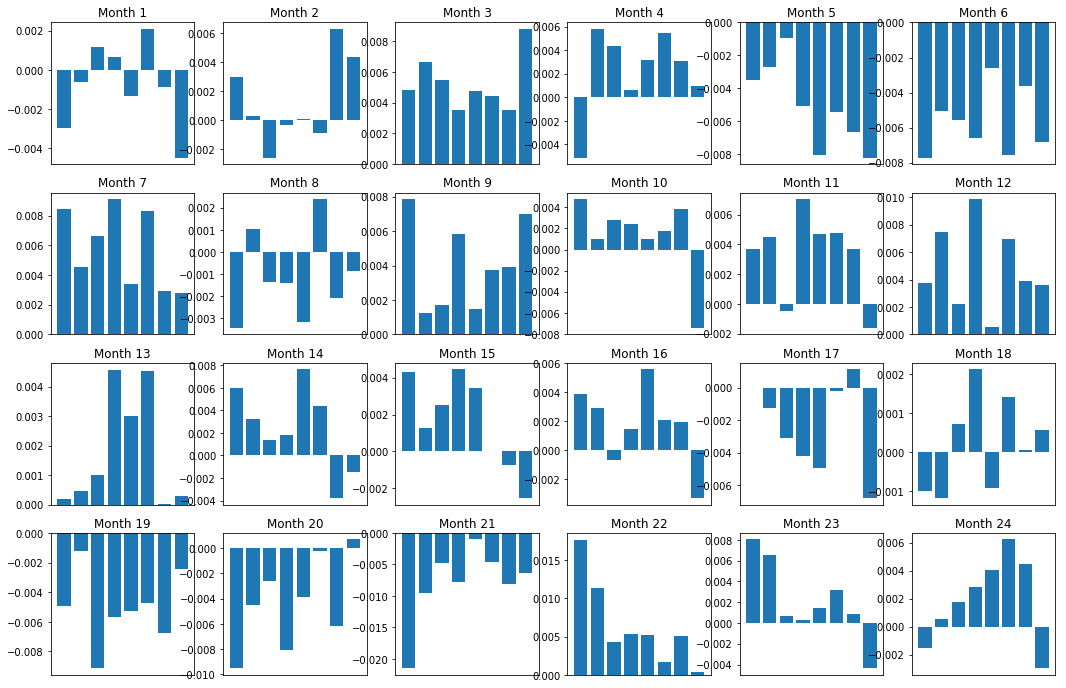
Tất nhiên, đây chỉ là các mối quan hệ trung bình. Để hiểu mối quan hệ này phù hợp như thế nào và liệu chúng ta có sẵn sàng giao dịch hay không, chúng ta nên thay đổi cách tiếp cận và thái độ của mình đối với nó theo thời gian. Tiếp theo, chúng ta sẽ xem xét biên lãi suất hàng tháng của họ (cơ sở) trong hai năm trước. Chúng ta có thể thấy nhiều thay đổi hơn và tiến hành phân tích thêm để xác định liệu điểm số đà này có thể giao dịch hay không.
total_months = mscores.resample('M').last().index
months_to_plot = 24
monthly_index = total_months[:months_to_plot+1]
mean_basket_returns = np.zeros(number_of_baskets)
strategy_returns = pd.Series(index = monthly_index)
f, axarr = plt.subplots(1+int(monthly_index.size/6), 6,figsize=(18, 15))
for month in range(1, monthly_index.size):
temp_returns = forward_returns.loc[monthly_index[month-1]:monthly_index[month]]
temp_scores = resampled_scores.loc[monthly_index[month-1]:monthly_index[month]]
for m in temp_returns.index.intersection(temp_scores.index):
basket_returns = compute_basket_returns(temp_scores, temp_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
strategy_returns[monthly_index[month-1]] = mean_basket_returns[ number_of_baskets-1] - mean_basket_returns[0]
mean_basket_returns /= temp_returns.index.intersection(temp_scores.index).size
r = int(np.floor((month-1) / 6))
c = (month-1) % 6
axarr[r, c].bar(range(number_of_baskets), mean_basket_returns)
axarr[r, c].xaxis.set_visible(False)
axarr[r, c].set_title('Month ' + str(month))
plt.show()
plt.figure(figsize=(15,7))
plt.plot(strategy_returns)
plt.ylabel('Returns')
plt.xlabel('Month')
plt.plot(strategy_returns.cumsum())
plt.legend(['Monthly Strategy Returns', 'Cumulative Strategy Returns'])
plt.show()
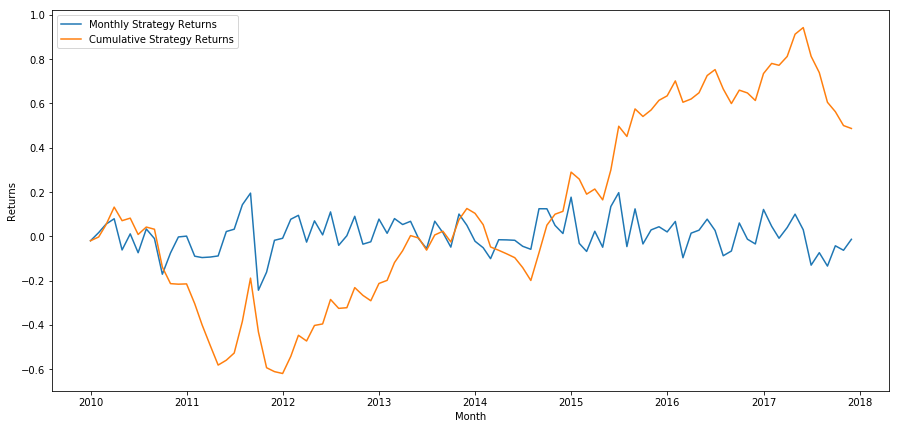
Cuối cùng, nếu chúng ta đi dài giỏ cuối cùng và đi ngắn giỏ đầu tiên mỗi tháng, sau đó hãy nhìn vào lợi nhuận (giả sử phân bổ vốn bằng nhau cho mỗi chứng khoán).
total_return = strategy_returns.sum()
ann_return = 100*((1 + total_return)**(12.0 /float(strategy_returns.index.size))-1)
print('Annual Returns: %.2f%%'%ann_return)
Tỷ lệ lợi nhuận hàng năm: 5,03%
Chúng ta có thể thấy rằng chúng ta có một hệ thống xếp hạng rất yếu, chỉ có thể phân biệt nhẹ các cổ phiếu hiệu suất cao từ các cổ phiếu hiệu suất thấp.
Tìm đúng bảng xếp hạng
Để thực hiện chiến lược cổ phiếu cân bằng dài ngắn, thực tế, bạn chỉ cần xác định sơ đồ xếp hạng. Mọi thứ sau đó là cơ học. Một khi bạn có một chiến lược cổ phiếu cân bằng dài ngắn, bạn có thể trao đổi các yếu tố xếp hạng khác nhau mà không có nhiều thay đổi. Đây là một cách rất thuận tiện để lặp lại ý tưởng của bạn nhanh chóng mà không phải lo lắng về việc điều chỉnh tất cả các mã mỗi lần.
Kế hoạch xếp hạng cũng có thể đến từ hầu hết các mô hình. Nó không nhất thiết phải là mô hình yếu tố dựa trên giá trị. Nó có thể là một công nghệ học máy có thể dự đoán lợi nhuận một tháng trước và xếp hạng theo mức này.
Chọn và đánh giá hệ thống xếp hạng
Hệ thống xếp hạng là lợi thế và là phần quan trọng nhất của chiến lược cổ phần cân bằng dài ngắn.
Một điểm khởi đầu tốt là chọn các công nghệ hiện có và xem liệu bạn có thể sửa đổi chúng một chút để có được lợi nhuận cao hơn.
-
Clone và điều chỉnh: Chọn một chủ đề thường được thảo luận, và xem bạn có thể sửa đổi nó một chút để có được lợi thế. Nói chung, các yếu tố có sẵn công khai sẽ không còn có tín hiệu giao dịch, bởi vì chúng đã hoàn toàn điều chỉnh ra khỏi thị trường. Nhưng đôi khi chúng sẽ dẫn bạn theo đúng hướng.
-
Mô hình định giá: Bất kỳ mô hình nào dự đoán lợi nhuận trong tương lai có thể là một yếu tố có khả năng được sử dụng để xếp hạng giỏ đối tượng giao dịch của bạn. Bạn có thể lấy bất kỳ mô hình định giá phức tạp nào và chuyển đổi nó thành một chương trình xếp hạng.
-
Các yếu tố dựa trên giá (định số kỹ thuật): các yếu tố dựa trên giá, như được thảo luận ngày hôm nay, thu thập thông tin về giá lịch sử của mỗi cổ phiếu và sử dụng nó để tạo ra các giá trị yếu tố.
-
Sự hồi quy và động lực: Điều đáng chú ý là một số yếu tố tin rằng một khi giá di chuyển theo một hướng, chúng sẽ tiếp tục làm như vậy, trong khi một số yếu tố chỉ ngược lại. Cả hai đều là các mô hình hiệu quả cho các chân trời thời gian và tài sản khác nhau, và điều quan trọng là phải nghiên cứu xem hành vi cơ bản dựa trên động lực hay hồi quy.
-
Yếu tố cơ bản (dựa trên giá trị): Đây là sự kết hợp của các giá trị cơ bản, chẳng hạn như PE, cổ tức, v.v. Giá trị cơ bản chứa thông tin liên quan đến các thực tế thực tế của công ty, vì vậy nó có thể mạnh hơn giá trong nhiều khía cạnh.
Cuối cùng, dự đoán phát triển là một cuộc chạy đua vũ trang, và bạn đang cố gắng để giữ một bước trước. Các yếu tố sẽ được điều chỉnh từ thị trường và có một cuộc sống hữu ích, vì vậy bạn phải liên tục làm việc để xác định bao nhiêu suy thoái các yếu tố của bạn đã trải qua và những yếu tố mới có thể được sử dụng để thay thế chúng.
Các cân nhắc khác
- Tần suất tái cân bằng
Mỗi hệ thống xếp hạng dự đoán lợi nhuận trong một khung thời gian hơi khác nhau. Tỷ lệ hồi quy trung bình dựa trên giá có thể dự đoán được trong vài ngày, trong khi mô hình nhân tố dựa trên giá trị có thể dự đoán được trong vài tháng. Điều quan trọng là xác định khoảng thời gian mà mô hình nên dự đoán và thực hiện xác minh thống kê trước khi thực hiện chiến lược. Tất nhiên, bạn không muốn quá phù hợp bằng cách cố gắng tối ưu hóa tần suất tái cân bằng. Bạn chắc chắn sẽ tìm thấy tần số ngẫu nhiên tốt hơn các tần số khác. Một khi bạn đã xác định khoảng thời gian dự đoán sơ đồ xếp hạng, hãy cố gắng tái cân bằng ở tần số này để tận dụng đầy đủ mô hình của bạn.
- Khả năng vốn và chi phí giao dịch
Mỗi chiến lược có khối lượng vốn tối thiểu và tối đa, và ngưỡng tối thiểu thường được xác định bởi chi phí giao dịch.
Giao dịch quá nhiều cổ phiếu sẽ dẫn đến chi phí giao dịch cao. Nếu bạn muốn mua 1.000 cổ phiếu, nó sẽ tốn hàng ngàn đô la cho mỗi lần tái cân bằng. Cơ sở vốn của bạn phải đủ cao để chi phí giao dịch có thể chiếm một phần nhỏ lợi nhuận mà chiến lược của bạn tạo ra. Ví dụ, nếu vốn của bạn là 100.000 đô la và chiến lược của bạn kiếm được 1% (1.000 đô la) mỗi tháng, tất cả các lợi nhuận này sẽ bị tiêu thụ bởi chi phí giao dịch. Bạn cần chạy chiến lược với hàng triệu đô la vốn để kiếm được hơn 1.000 cổ phiếu.
Mức ngưỡng tài sản thấp nhất chủ yếu phụ thuộc vào số lượng cổ phiếu giao dịch. Tuy nhiên, khả năng tối đa cũng rất cao. Chiến lược cổ phiếu cân bằng dài ngắn có thể giao dịch hàng trăm triệu đô la mà không mất lợi thế. Đây là một sự thật, bởi vì chiến lược này tương đối hiếm khi tái cân bằng. Giá trị đô la của mỗi cổ phiếu sẽ rất thấp khi tổng tài sản được chia cho số lượng cổ phiếu giao dịch. Bạn không phải lo lắng về việc khối lượng giao dịch của bạn có ảnh hưởng đến thị trường hay không. Giả sử bạn giao dịch 1.000 cổ phiếu, tức là 100.000.000 đô la. Nếu bạn tái cân bằng toàn bộ danh mục đầu tư mỗi tháng, mỗi cổ phiếu sẽ chỉ giao dịch 100.000 đô la một tháng, điều này không đủ để trở thành một thị trường quan trọng đối với hầu hết các chứng khoán.
- Xác định số lượng phân tích cơ bản trong thị trường tiền điện tử: Hãy để dữ liệu nói cho chính nó!
- Các nghiên cứu định lượng cơ bản của vòng đồng tiền - đừng tin vào những giáo viên mờ nhạt, nói khách quan về dữ liệu!
- Một công cụ thiết yếu trong lĩnh vực giao dịch định lượng - nhà phát minh mô-đun khám phá dữ liệu định lượng
- Kiểm soát mọi thứ - giới thiệu về FMZ Phiên bản mới của Terminal giao dịch (với mã nguồn TRB Arbitrage)
- Có tất cả các thông tin về FMZ phiên bản mới của giao dịch đầu cuối (được thêm mã nguồn TRB)
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (II)
- Làm thế nào để khai thác robot bán hàng không có não với một chiến lược tần số cao trong 80 dòng mã
- FMZ định lượng: Phân tích các trường hợp thiết kế nhu cầu phổ biến của thị trường tiền điện tử (II)
- Cách khai thác robot vô trí tuệ để bán bằng chiến lược tần số cao 80 dòng mã
- FMZ Quant: Phân tích các ví dụ thiết kế yêu cầu chung trong thị trường tiền điện tử (I)
- FMZ định lượng: Các nhu cầu phổ biến của thị trường tiền điện tử