
Un recorrido por los algoritmos de aprendizaje automático
Después de entender los problemas de aprendizaje de máquinas que necesitamos resolver, podemos pensar en qué datos necesitamos recopilar y qué algoritmos podemos usar. En este artículo repasaremos los algoritmos de aprendizaje de máquinas más populares y veremos qué métodos pueden ser útiles.
Hay muchos algoritmos en el campo del aprendizaje automático, y cada uno de ellos tiene muchas extensiones, por lo que es muy difícil determinar cuál es el algoritmo correcto para un problema en particular. En este artículo quiero darte dos maneras de resumir los algoritmos que se encuentran en la realidad.
-
Cómo aprender
Los algoritmos se clasifican en diferentes tipos según cómo se manejan las experiencias, el entorno o lo que llamamos datos de entrada. Los libros de texto de aprendizaje automático y inteligencia artificial suelen considerar primero las formas de aprendizaje a las que los algoritmos pueden adaptarse.
Aquí solo se discuten algunos de los principales estilos de aprendizaje o modelos de aprendizaje, y hay algunos ejemplos básicos. Este método de clasificación u organización es bueno porque te obliga a pensar en el rol de los datos de entrada y el proceso de preparación del modelo, y luego elegir un algoritmo que se adapte mejor a tu problema para obtener los mejores resultados.
Aprendizaje supervisado: los datos de entrada se llaman datos de entrenamiento y tienen un resultado conocido o se marcan. Por ejemplo, si un correo es un correo no deseado o si el precio de una acción durante un período de tiempo. El modelo hace predicciones y se corrige si está equivocado, y este proceso continúa hasta que alcanza un cierto estándar de corrección para los datos de entrenamiento.
Aprendizaje no supervisado: los datos de entrada no se etiquetan y no hay resultados definidos. Los modelos recogen la estructura y el valor de los datos. Ejemplos de problemas incluyen el aprendizaje de reglas de asociación y problemas de agrupación, y los algoritmos incluyen el algoritmo Apriori y el algoritmo de K-mean.
Aprendizaje semi-supervisado: los datos de entrada son una mezcla de datos marcados y no marcados, hay algunos problemas de predicción, pero el modelo también debe aprender la estructura y la composición de los datos. Los ejemplos de problemas incluyen problemas de clasificación y regresión, y los ejemplos de algoritmos son básicamente extensiones de algoritmos de aprendizaje no supervisado.
Aprendizaje aumentado: los datos de entrada pueden estimular el modelo y hacer que el modelo reaccione. La retroalimentación se obtiene no solo del proceso de aprendizaje supervisado, sino también de las recompensas o castigos en el entorno. Ejemplos de problemas son el control de robots, y los ejemplos de algoritmos incluyen Q-learning y aprendizaje temporal de diferencias.Cuando se integran decisiones comerciales de simulación de datos, la mayoría utiliza métodos de aprendizaje supervisado y no supervisado. El siguiente tema de actualidad es el aprendizaje semisupervisado, como el problema de clasificación de imágenes, en el que hay una gran base de datos de problemas, pero solo una pequeña parte de las imágenes están marcadas.
-
Similaridad de algoritmos
Los algoritmos se clasifican fundamentalmente en función o forma. Por ejemplo, los algoritmos basados en árboles, los algoritmos de redes neuronales. Esta es una forma útil de clasificación, pero no perfecta.
En esta sección he enumerado los algoritmos de clasificación que considero los más intuitivos. No he terminado de describir los algoritmos o métodos de clasificación, pero creo que es muy útil para que los lectores tengan una idea general.
-
Regression
La regresión se refiere a la relación entre variables. Se aplica a métodos estadísticos. Algunos ejemplos de algoritmos incluyen:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
El aprendizaje basado en instancias simula un problema de decisión en el que los ejemplos o ejemplos utilizados son muy importantes para el modelo. Este método crea una base de datos de los datos existentes y luego agrega nuevos datos, y luego usa un método de medición de similitud para encontrar la mejor coincidencia en la base de datos y hacer una predicción. Por esta razón, este método también se conoce como el método del ganador como rey y el método basado en la memoria.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
Se trata de una extensión de otros métodos (generalmente el método de regresión), que favorece a modelos más simples y mejores en la inducción. La incluyo aquí porque es popular y potente.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Los métodos de árbol de decisión construyen un modelo basado en decisiones de valores reales en los datos. Los árboles de decisión se utilizan para resolver problemas de integración y regresión.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
El método bayesiano es un método que aplica el teorema de Bayes para resolver problemas de clasificación y regresión.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
El método Kernel más conocido es el de las máquinas vectoriales de soporte (Support Vector Machines). Este método mapea los datos de entrada en una dimensión más alta, lo que facilita la modelación de algunos problemas de clasificación y regresión.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
Clustering, en sí mismo, describe el problema y el método. Los métodos de agrupación generalmente se clasifican por el modo de modelado. Todos los métodos de agrupación organizan los datos con una estructura de datos unificada para que cada grupo tenga el máximo de puntos en común.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
El aprendizaje de reglas de asociación es un método para extraer reglas entre los datos, a través de las cuales se pueden encontrar conexiones entre enormes cantidades de datos en el espacio multidimensional, y estas conexiones importantes pueden ser utilizadas por la organización.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
Las Redes Neurales Artificiales se inspiran en la estructura y funcionalidad de las redes neuronales biológicas. Pertenece a la clase de la correspondencia de patrones, y se utiliza a menudo para problemas de regresión y clasificación, pero se compone de cientos de algoritmos y variantes.
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
El método de aprendizaje profundo es una actualización moderna de las redes neuronales artificiales. En comparación con las redes neuronales tradicionales, tiene una composición de red más compleja. Muchos métodos se preocupan por el aprendizaje semisupervisado, un tipo de aprendizaje en el que hay grandes cantidades de datos, pero pocos de los cuales son datos marcados.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionalidad Reducción, como el método de agrupación, busca y utiliza una estructura unificada en los datos, pero utiliza menos información para resumir y describir los datos. Esto es útil para visualizar o simplificar los datos.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Los métodos de ensamblaje consisten en muchos modelos pequeños, que se entrenan de forma independiente, llegan a conclusiones independientes y finalmente forman una predicción general. Muchos estudios se centran en qué modelos se usan y cómo se combinan. Esta es una técnica muy poderosa y popular.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
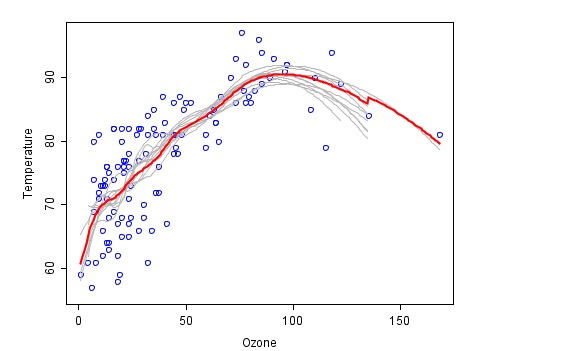
Este es un ejemplo de la combinación de las predicciones de cada ley de incendios en gris, y el pronóstico final de la última combinación en rojo.
-
Otros recursos
Este recorrido por los algoritmos de aprendizaje automático pretende darte una idea general de lo que son los algoritmos y algunas de las herramientas para relacionarlos.
A continuación se incluyen algunos otros recursos, pero no es demasiado, ya que aprender más sobre los algoritmos es bueno para ti, pero también puede ser útil tener un conocimiento profundo de algunos de ellos.
- List of Machine Learning Algorithms: Este es un recurso en la wiki, aunque es completo, creo que la clasificación no es muy buena.
- Machine Learning Algorithms Category: Esta es otra fuente en la wiki, un poco mejor que la anterior, ordenada alfabéticamente.
- CRAN Task View: Machine Learning & Statistical Learning: Un paquete de extensiones del lenguaje R para los algoritmos de aprendizaje automático, para comparar mejor lo que otros están usando.
- Top 10 Algorithms in Data Mining: Este es un artículo publicado, ahora un libro, que incluye los algoritmos de minería de datos más populares. Otra lista de algoritmos básicos, los que se enumeran aquí son pocos, para ayudarlo a profundizar.
Se trata de un proyecto de desarrollo de software para el desarrollo de aplicaciones para la web, desarrollado por el desarrollador de Python.
- 1