
Tur Algoritma Pembelajaran Mesin
Setelah memahami masalah pembelajaran mesin yang perlu kita selesaikan, kita dapat memikirkan data apa yang perlu kita kumpulkan dan algoritma apa yang bisa kita gunakan. Dalam artikel ini, kita akan membahas algoritma pembelajaran mesin yang paling populer dan melihat secara umum metode apa yang tersedia.
Ada banyak algoritma dalam bidang pembelajaran mesin, dan setiap algoritma memiliki banyak ekstensi, sehingga sangat sulit untuk menentukan algoritma yang benar untuk masalah tertentu. Dalam artikel ini saya ingin memberi Anda dua cara untuk merangkum algoritma yang akan Anda temui di dunia nyata.
-
Cara Belajar
Algoritma dibagi menjadi beberapa jenis berdasarkan bagaimana mereka memproses pengalaman, lingkungan, atau apa pun yang kita sebut input data. Buku teks pembelajaran mesin dan kecerdasan buatan biasanya mempertimbangkan cara belajar yang dapat disesuaikan dengan algoritma.
Hanya beberapa gaya atau model pembelajaran utama yang dibahas di sini, dan beberapa contoh dasar. Cara pengelompokan atau pengorganisasian ini bagus karena memaksa Anda untuk memikirkan peran dan proses persiapan model untuk memasukkan data, dan kemudian memilih algoritma yang paling sesuai dengan masalah Anda, sehingga mendapatkan hasil terbaik.
Pembelajaran yang diawasi: data yang dimasukkan disebut data pelatihan dan memiliki hasil yang diketahui atau ditandai. Misalnya, mengatakan apakah sebuah email adalah spam, atau mengatakan harga saham dalam jangka waktu tertentu. Model membuat prediksi, dan jika salah akan dikoreksi, dan proses ini terus berlanjut sampai mencapai standar tertentu yang benar untuk data pelatihan.
Pembelajaran tanpa pengawasan: input data tidak ditandai dan tidak ada hasil yang pasti. Model menginduksi struktur dan nilai data. Contoh masalah termasuk pembelajaran aturan asosiasi dan masalah pengelompokan, contoh algoritma termasuk algoritma Apriori dan algoritma K-mean.
Pembelajaran Semi-diawasi: Data input adalah campuran dari data yang ditandai dan tidak ditandai, ada beberapa masalah prediktif tetapi model juga harus mempelajari struktur dan komposisi data. Contoh masalah termasuk klasifikasi dan regresi, dan contoh algoritma pada dasarnya merupakan perpanjangan dari algoritma pembelajaran yang tidak diawasi.
Enhanced learning: input data dapat merangsang model dan membuat model bereaksi. Umpan balik tidak hanya berasal dari proses pembelajaran yang diawasi, tetapi juga dari reward atau hukuman di lingkungan. Contoh masalah adalah kontrol robot, contoh algoritma termasuk Q-learning dan Temporal difference learning.Ketika mengintegrasikan simulasi data dalam keputusan bisnis, sebagian besar menggunakan pembelajaran yang diawasi dan pembelajaran yang tidak diawasi. Topik populer berikutnya adalah pembelajaran yang diawasi setengah, seperti masalah klasifikasi gambar, di mana ada database besar masalah, tetapi hanya sebagian kecil dari gambar yang diberi label.
-
Kesamaan algoritma
Algoritma pada dasarnya diklasifikasikan berdasarkan fungsi atau bentuknya. Misalnya, algoritma berbasis pohon, algoritma jaringan neural. Ini adalah cara yang sangat berguna untuk mengklasifikasikan, tetapi tidak sempurna.
Dalam bagian ini saya telah mencantumkan apa yang saya anggap sebagai cara yang paling intuitif untuk mengklasifikasikan algoritma. Saya tidak akan mengakhiri algoritma atau metode klasifikasi, tetapi saya pikir ini akan sangat membantu bagi pembaca untuk memiliki gambaran umum. Jika ada yang Anda ketahui yang tidak saya cantumkan, silakan tinggalkan komentar.
-
Regression
Regression (analisis regresi) berkaitan dengan hubungan antara variabel. Regression digunakan dalam metode statistik, beberapa contoh algoritma meliputi:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
Pembelajaran berbasis instansi memodelkan sebuah masalah keputusan, dimana contoh yang digunakan sangat penting bagi model. Metode ini membangun sebuah database dari data yang ada dan kemudian menambahkan data baru ke dalamnya, kemudian menggunakan metode pengukuran kesamaan untuk menemukan yang paling cocok di dalam database, membuat sebuah prediksi.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
Ini adalah perpanjangan dari metode lain (biasanya metode regresi), yang lebih menguntungkan untuk model yang lebih sederhana, dan lebih baik dalam penggabungan. Saya mencantumkannya di sini karena popularitas dan kekuatannya.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Decision tree methods adalah metode yang membangun sebuah model dari keputusan berdasarkan nilai aktual dalam data. Pohon keputusan digunakan untuk memecahkan masalah integrasi dan regresi.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
Metode Bayesian (bahasa Inggris: Bayesian method) adalah metode yang menggunakan Teorema Bayesian untuk memecahkan masalah klasifikasi dan regresi.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
Metode Kernel yang paling terkenal adalah Support Vector Machines. Metode ini memetakan data input ke dimensi yang lebih tinggi, sehingga beberapa masalah klasifikasi dan regresi lebih mudah dimodelkan.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
Clustering, dalam dirinya sendiri menggambarkan masalah dan metode. Metode pengelompokan biasanya diklasifikasikan oleh metode pemodelan. Semua metode pengelompokan menggunakan struktur data yang seragam untuk mengatur data sehingga setiap kelompok memiliki sebanyak mungkin kesamaan.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
Association rule learning adalah metode yang digunakan untuk mengekstrak aturan antar data, yang dapat digunakan untuk menemukan hubungan antara sejumlah besar data dalam ruang multidimensi, dan hubungan penting ini dapat digunakan oleh organisasi.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
Artificial Neural Networks diilhamkan dari struktur dan fungsi jaringan saraf biologis. Ini termasuk dalam kategori pencocokan pola yang sering digunakan untuk masalah regresi dan klasifikasi, tetapi ada ratusan algoritma dan varian. Beberapa di antaranya adalah algoritma klasik yang populer (saya mengambil pembelajaran mendalam secara terpisah):
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
Metode Deep Learning adalah pembaruan modern dari jaringan neural buatan. Dibandingkan dengan jaringan neural tradisional, ia memiliki jaringan yang lebih banyak dan lebih kompleks. Banyak metode yang berkaitan dengan pembelajaran yang tidak terpantau.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionality Reduction (pengurangan dimensi), seperti metode pengelompokan, mengejar dan memanfaatkan struktur kesatuan dalam data, tetapi menggunakan lebih sedikit informasi untuk merangkum dan menggambarkan data. Ini berguna untuk memvisualisasikan atau menyederhanakan data.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Ensemble methods terdiri dari banyak model kecil, yang dilatih secara independen, membuat kesimpulan independen, dan akhirnya membentuk prediksi keseluruhan. Banyak penelitian berfokus pada model apa yang digunakan dan bagaimana model-model ini digabungkan. Ini adalah teknik yang sangat kuat dan populer.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
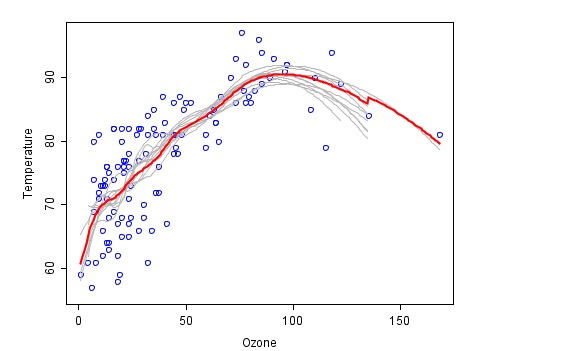
Ini adalah contoh dari kombinasi yang dilakukan dengan metode gabungan (diambil dari wiki), dengan masing-masing kode kebakaran digambarkan dengan warna abu-abu, dan prediksi terakhir yang disintesis adalah warna merah.
-
Sumber daya lainnya
Perjalanan algoritma pembelajaran mesin ini dimaksudkan untuk memberi Anda gambaran tentang apa algoritma dan beberapa alat untuk algoritma terkait.
Berikut ini adalah beberapa sumber daya lainnya, jangan terlalu banyak, semakin banyak pengetahuan tentang algoritma yang akan membantu Anda, tetapi pengetahuan yang lebih dalam tentang beberapa algoritma juga akan berguna.
- List of Machine Learning Algorithms: Ini adalah sumber daya di wiki, dan meskipun lengkap, menurut saya tidak terlalu baik dalam pengelompokan.
- Machine Learning Algorithms Category: Ini juga sumber daya di wiki, sedikit lebih baik dari yang di atas, diurutkan dalam alfabet.
- CRAN Task View: Machine Learning & Statistical Learning: Ekstensi bahasa R untuk algoritma pembelajaran mesin, untuk melihat apa yang lebih baik dibandingkan dengan apa yang digunakan orang lain.
- Top 10 Algorithms in Data Mining: Ini adalah artikel yang diterbitkan, sekarang menjadi buku, yang mencakup algoritma penambangan data yang paling populer. Daftar algoritma dasar lainnya, yang tidak banyak, dapat membantu Anda mempelajari lebih dalam.
Dikutip dari Berle Columns/Dafei Python Developer
- 1