머신러닝을 기반으로 한 주문장 고빈도 거래 전략
 1
8025
1
8025
머신러닝을 기반으로 한 주문장 고빈도 거래 전략
- ### 제1설명
증권 시장의 거래 메커니즘은 제안 드라이브 시장과 주문 드라이브 시장 두 종류로 나눌 수 있습니다. 전자는 시장 상인이 유동성을 제공하는 것에 의존하고, 후자는 제한 가격 서한을 통해 유동성을 제공하며, 거래는 투자자의 구매 위탁 및 판매 위탁 경매 가격을 통해 형성됩니다. 중국의 증권 시장은 주식 시장과 선물 시장을 포함한 주문 드라이브 시장에 속합니다.
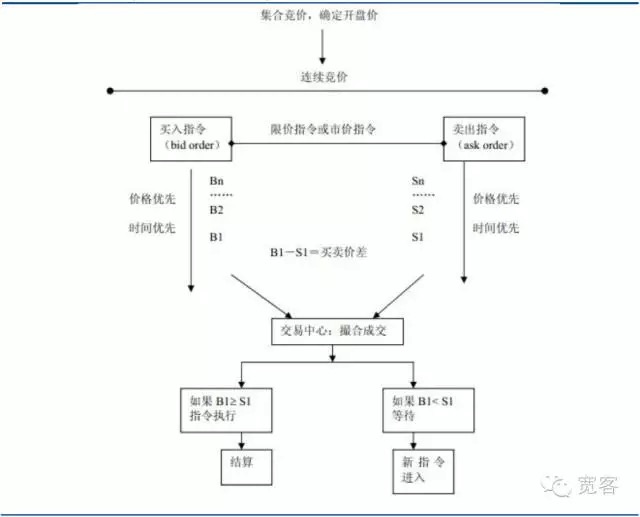 도 1 주문 동력 시장 도표
도 1 주문 동력 시장 도표
-
(i) 제한 가격 주문 서적 설명서
주문서기의 연구는 시장 미시 구조 연구의 범주에 속한다. 시장 미시 구조 이론은 미시 경제학의 가격 이론과 제조자 이론을 사상적 근원으로 하고, 그 핵심 문제에 대한 금융 자산 거래 및 가격 형성 과정과 이유에 대한 분석에는 일반 균형, 지역 균형, 경계 수익, 경계 비용, 시장 연속성, 재고 이론, 게임 이론, 정보 경제학 등의 여러 이론과 방법을 사용한다.
해외 연구의 발전을 볼 때, 시장 미시구조 분야는 O’Hara로 대표되며, 대부분의 이론은 시장 상자 시장 (즉, 제안 구동 시장) 을 기반으로 한다. 예를 들어, 재고 모델 및 정보 모델 등이다. 올해, 실제 거래 시장에서 주문 구동은 점진적으로 상위를 차지하고 있지만, 주문 구동 시장에 대한 연구는 상대적으로 적다.
국내 증권 시장과 선물 시장은 모두 주문 구동 시장에 속한다. 아래 그림은 주식 지수 선물 계약 IF1312의 Level_1 거래 주문 서적 스냅샷이다. 위에서 직접 얻을 수 있는 정보는 많지 않으며, 기본 정보는 구매 가격, 판매 가격, 구매량 및 판매량을 포함한다. 해외의 일부 학술 논문에서, 주문 서적과 대응하는 정보 서적도 있다.
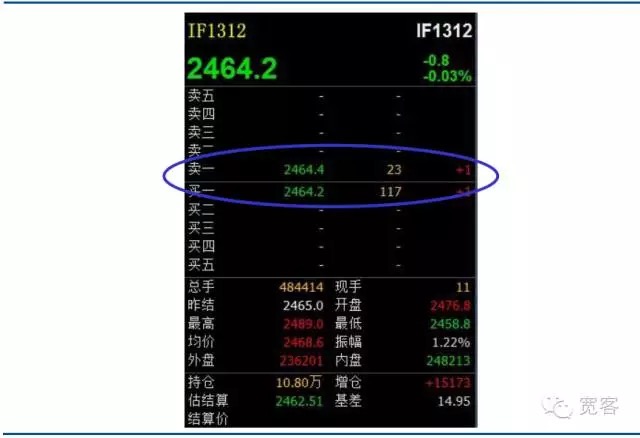 도 2 주식 지수 선물 주력 계약 레벨-1 주문서
도 2 주식 지수 선물 주력 계약 레벨-1 주문서 -
2) 주문서고의 고주파 거래 연구 진행
주문서기의 동적 모형화에는 크게 두 가지 방법이 있는데, 하나는 고전적인 측량경제학 방법이고, 다른 하나는 기계학습 방법이다. 측량경제학 방법은 고전적인 주류 연구 방법 중 하나이며, 예를 들어 가격차 분석의 MRR 분해, Huang 및 Stoll 분해, 주문 지속 기간의 ACD 모델, 가격 예측의 Logistic 모델 등을 연구한다.
기계학습은 금융 분야의 학문적 연구에도 매우 활발하다. 예를 들어 2012년 ?? Forecasting trends of high_frequency KOSPI200 index data using learning classifiers ?? 는 기술분석의 일반적인 지표 (MA, EMA, RSI 등) 를 이용한 일반적인 연구 사고방식이며, 기계학습의 분류 방법을 도입하여 시장 예측을 한다. 그러나 이러한 방법은 주문서치의 동적 정보에 대한 채굴이 부족하다. 즉, 주문서치의 동적 정보를 이용한 높은 가격 거래 연구는 국내외에서 상대적으로 적은 편이며, 이는 깊이있는 연구의 가치가 있다.
-
2. 주문서고의 고주파 거래에 대한 기계학습의 적용
- #### (a) 시스템 아키텍처
아래의 그림은 전형적인 기계 학습 거래 전략의 시스템 아키텍처 도표이며, 주문서 데이터, 특징 발견, 모델 구축 및 검증 및 거래 기회의 몇 가지 주요 모듈을 포함합니다.
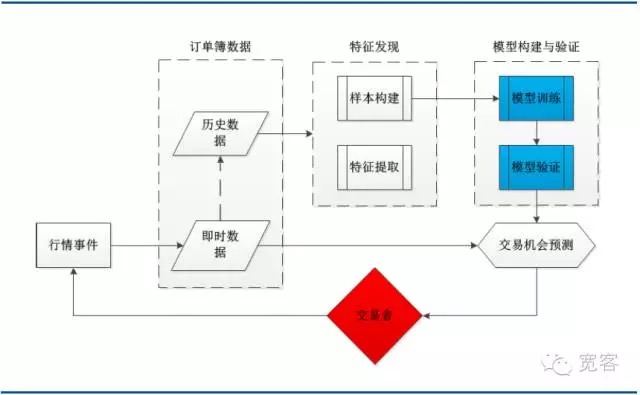 도 3 기계 학습 기반의 주문 서적 모델링 시스템 아키텍처 도표
도 3 기계 학습 기반의 주문 서적 모델링 시스템 아키텍처 도표- #### (ii) 지원 벡터 기계 설명
1970년대, Vapnik 등은 비교적 완성된 이론 체계인 통계학습이론 (SLT, Statistical Learning Theory) 을 구축하기 시작했으며, 이는 제한된 샘플 상황에서 통계적 규칙과 학습 방법의 성질을 연구하기 위해 사용되었으며, 제한된 샘플의 기계학습 문제에 대한 좋은 이론적 프레임워크를 구축했으며, 작은 샘플, 비선형성, 고차원, 지역 극소수점과 같은 실제 문제를 더 잘 해결했다. 1995년, Vapnik 등은 새로운 일반학습이론 (SVM, Support Vector Machine) 을 명확히 제시한 후, 이 이론은 광범위한 관심을 받으며 다양한 분야에 적용되었으며, 초기에는 자체 방법보다 많은 우수한 성능을 보여주었다.
SVM은 선형적으로 분할할 수 있는 상황의 최우수 분류 초평면으로부터 발전하였다. 두 종류의 분류 문제에 대해, 훈련 샘플 집합을 ((xi,yi), i=1,2…l, l는 훈련 샘플의 개수, xi는 훈련 샘플, yi는 입력 샘플의 클래스 마크인 {-1,+1}에 속한다 ((기대한 출력). SVM 알고리즘의 출발점은 최우수 분류 초평면을 찾는 것이다.
최적 분류 초평면은 모든 샘플을 올바르게 분리할 수 있을 뿐만 아니라, 두 종류 사이의 경계 (margin) 를 최대화할 수 있다. 경계 (margin) 는 훈련 데이터 세트에서 이 분류 초평면의 최소 거리의 합으로 정의된다. 최적 분류 초평면은 테스트 데이터의 평균 분류 오류가 최소라는 것을 의미한다.
만약 d차원 벡터 공간에 하나의 초평면이 존재한다면:
F(x)=w*x+b=0
위의 두 종류의 데이터를 분리할 수 있는 초평면은 분기 인터페이스라고 한다.*x는 d차원 벡터 공간에 있는 두 벡터 w와 x의 내积이다.
만약 인터페이스는
w*x+b=0
이 분기면을 가장 가까운 두 종류의 샘플 사이의 거리를 (마진) 최대로 만들 수 있는 분기면을 최적분기면이라고 한다.
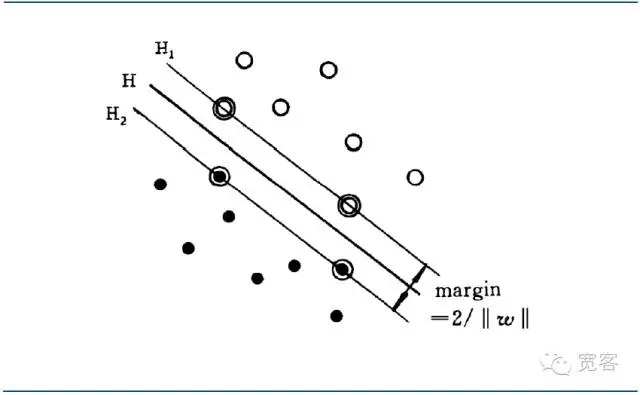 도 4 SVM 이분류 최우선 분화 인터페이스 도표
도 4 SVM 이분류 최우선 분화 인터페이스 도표최적의 분수면 방정식을 정형화하면 두 종류의 샘플 사이의 거리를
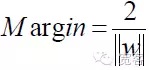
그래서 어떤 표본에 대해,
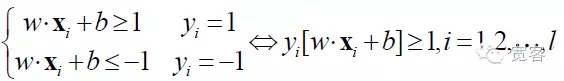
최적화된 인터페이스를 얻으려면 위의 식을 만족하는 것 외에도 최소화해야 합니다.
따라서 SVM 문제의 수학적 모델은 다음과 같습니다.
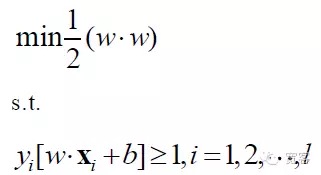
결국 SVM은 최적화된 기획 문제로 바뀌었고, 학계의 연구의 중심은 급속한 해결, 다중계, 실제 문제 응용 등에 대한 확산이다.
SVM은 원래 2등급 문제를 위해 제안되었으며, 현재 실제 응용 요구에 따라 다등급 문제에 확대되었다. 기존 다등급 알고리즘에는 1쌍, 1쌍, 오류 수정 코딩, DAG-SVM 및 Mult i-class SVM 분류기 등이 포함된다.
- #### (III) 주문서기 지표 추출
주식 지수 선물 레벨-1 상황을 예로 들자면, 주문서는 주로 구매 가격, 판매 가격, 구매량, 판매량과 같은 기본 지표를 포함하며, 깊이, 기울기, 상대 가격 차등과 같은 지표를 도출할 수 있다. 다른 지표는 보유량, 거래량, 기본 차등과 같은 총 17개의 지표를 포함하고 있다. 또한 일반적인 기술 분석 지표인 RSI, KDJMA, EMA 등을 도입할 수 있다.
표 1 레벨 시장 주문 서적을 기반으로 한 지표 저장소
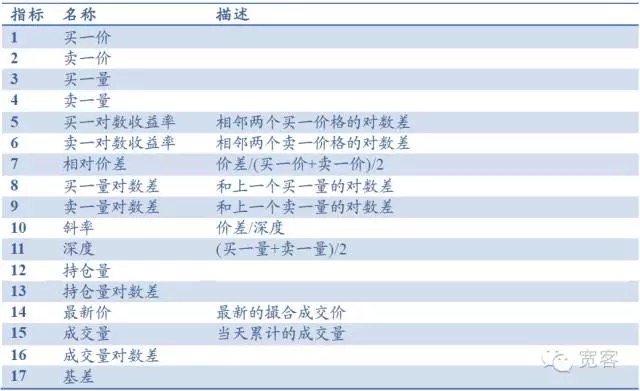
- #### (iv) 주문책의 동적 특징 그리고 거래 기회
시장 미시 관점에서, 단기간에 가격 동력을 측정하는 두 가지 방법이 있는데, 하나는 중간 가격 동력이고, 다른 하나는 차차 교차이다. 이 글에서는 보다 간단하고 직관적인 중간 가격 동력을 선택한다. 중간 가격의 정의:
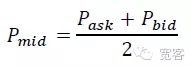
주문서기에 Δt 내의 중간값 ΔP 변화의 크기를 기준으로 하락 평준을 세 가지로 나눌 수 있다.
아래는 10월 29일 주력 계약 IF1311의 중간 가격 동력의 분포입니다. 매일 32400개의 틱 트레이드 데이터가 있습니다.
Δt=1tick의 경우, 중간값의 절대값변동은 0.2가 약 6000배, 절대값변동은 0.4가 약 1500배, 절대값변동은 0.6가 약 150배, 절대값변동은 0.8가 50배 이상, 절대값변동은 1보다 큰 것은 약 10배이다.
Δt=2tick의 경우, 중간값의 절대값변동은 0.2가 약 7000배, 절대값변동은 0.4가 약 3000배, 절대값변동은 0.6가 약 550배, 절대값변동은 0.8가 약 205배, 1보다 큰 절대값변동은 약 10배이다.
우리는 변화의 절대값이 0.4보다 크면 잠재적인 거래 기회라고 생각합니다. Δt = 1tick의 경우, 하루에 약 1700개의 기회가 있고, Δt = 2tick의 경우, 하루에 약 4000개의 기회가 있습니다.
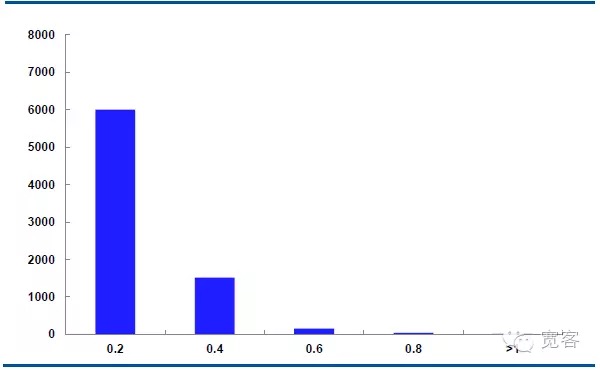
도 5 IF1311 10월 29일 중도 가격 변화 분포 도표 (Δt=1tick)
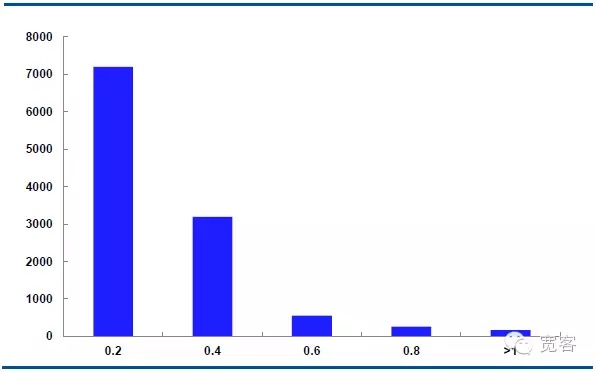
도 6 IF1311 10월 29일 중도 가격 변화 분포 도표 (Δt=2tick)
-
3 전략과 실증
SVM 모형은 대용량 샘플 상황에서 훈련 복잡성이 높고 훈련 시간이 길기 때문에, 우리는 IF1311 계약의 10 월 레벨_1 시드 데이터의 예를 들어, 모델의 유효성을 검증하기 위해 비교적 짧은 기간의 역사 실태 데이터를 선택했습니다.
-
(a) 모델 효과 테스트
데이터 주기: IF1311 계약의 10월 실적 자료;
Δt 가치: Δt가 작을수록 거래 세부 사항에 대한 요구가 높습니다. Δt=1tick일 때 실제 거래에서 수익을 얻는 것은 어렵습니다. 모델의 효과를 비교하기 위해, 여기 각각 1tick, 2tick, 3tick을 가치화합니다.
모델 평가 지표: 샘플 정확도, 검사 정확도, 예측 시간.
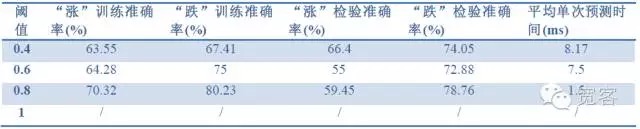 표 2 1 tick 데이터로 1 tick의 효과를 예측
표 2 1 tick 데이터로 1 tick의 효과를 예측 표 3 1 tick 데이터로 tick2의 효과를 예측
표 3 1 tick 데이터로 tick2의 효과를 예측 표4 2tick 데이터로 2tick의 효과를 예측
표4 2tick 데이터로 2tick의 효과를 예측위 세 개의 표에서 우리는 다음과 같은 결론을 얻을 수 있습니다. 최대 정확도는 약 70%이며, 정확도가 60%에 이르면 거래 전략으로 변환할 수 있다.
-
(ii) 전략 모형 수익
예를 들어 10월 31일, 우리는 시뮬레이션 거래를 하고, 기관의 주식 지수 선물 거래 수수료는 일반적으로 기관의 주식 지수 선물 거래 수수료는 일반적으로 0.26/10000입니다. 우리는 거래의 수를 상수 제한없이 가정하고, 거래의 일방적 지각이 0.2점으로 가정하고, 매번의 하향 수치는 1이다.
표 5 모의 전략 10월 31일 거래

하루 605번의 거래, 수차 포함, 339번의 수익, 승률 56%, 순이익 11814.99원.
이론적 낙하값은 14520원이며, 이는 전략적 실전전략의 핵심이다. 주문 세부사항이 더 정밀하게 통제된다면 낙하값을 줄이고, 순이익을 올릴 수 있다. 주문 세부사항이 적절히 통제되지 않거나, 시장의 변동이 이상하면 낙하값이 더 커지고, 순이익은 줄어들 수 있다. 따라서 고주파 거래의 승패는 세부사항의 실행에 달려 있다.
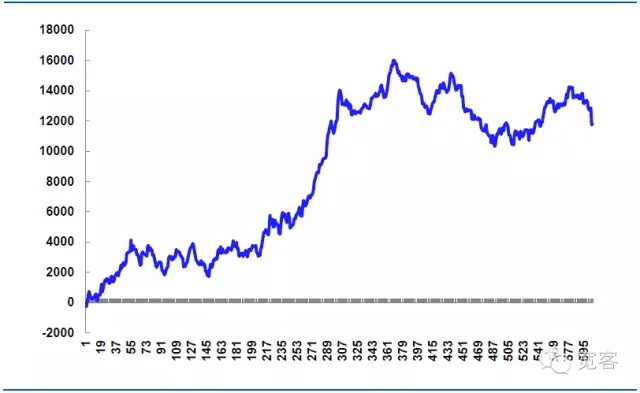
도 7 모의 전략이 10월 31일 수익
이 글은 宽客公众号 저자의 원작이며, 번역본은 출처를 기재해 주시기 바랍니다.