
머신 러닝 알고리즘 투어
우리가 해결해야 할 기계 학습 문제를 이해 한 후, 우리는 우리가 수집해야 할 데이터와 우리가 사용할 수있는 알고리즘에 대해 생각해 볼 수 있습니다. 이 글에서는 가장 인기있는 기계 학습 알고리즘을 살펴보고 사용 가능한 방법을 대략적으로 이해하는데 도움이 될 것입니다.
기계학습 분야에는 많은 알고리즘이 있고, 각각의 알고리즘에는 많은 확장들이 있기 때문에, 특정 문제에 대해 올바른 알고리즘을 어떻게 결정하느냐는 매우 어렵다. 이 글에서는 현실에서 만날 수 있는 알고리즘을 정리하는 두 가지 방법을 제시하고자 한다.
-
학습 방법
알고리즘은 경험, 환경, 또는 우리가 입력이라고 부르는 어떤 데이터를 처리하는 방법에 따라 다른 종류로 분류됩니다. 기계 학습과 인공 지능 교과서는 일반적으로 알고리즘이 적응할 수 있는 학습 방법을 먼저 고려합니다.
여기서는 몇 가지 주요 학습 스타일이나 학습 모델에 대해서만 이야기하며 몇 가지 기본적인 예가 있습니다. 이러한 분류 또는 조직 방식은 좋은데, 왜냐하면 입력 데이터의 역할과 모델을 준비하는 과정을 생각하도록 강요하고, 그 다음에는 당신에게 가장 적합한 문제를 해결하기 위해 가장 적합한 알고리즘을 선택하여 최상의 결과를 얻을 수 있기 때문입니다.
감독 학습: 입력된 데이터는 훈련 데이터로 불리며, 알려진 결과 또는 표기된다. 예를 들어, 이메일이 스팸 메일인지, 또는 일정 기간 동안의 주가 가격을 말한다. 모델은 예측을 하고, 틀리면 수정된다. 이 과정은 훈련 데이터에 대해 특정 올바른 기준을 달성할 수 있을 때까지 계속된다. 문제 예는 분류 및 회귀 문제를 포함하며, 알고리즘 예는 논리 회귀 및 역신경 네트워크를 포함한다.
감독되지 않은 학습: 입력 데이터는 표기되지 않으며, 결과가 결정되지 않습니다. 모델은 데이터의 구조와 수치를归纳합니다. 문제 예는 협회 규칙 학습 및 클러지 문제, 알고리즘 예는 Apriori 알고리즘 및 K-평균 알고리즘을 포함한다.
반감독 학습: 입력 데이터는 표기된 데이터와 표기되지 않은 데이터의 혼합물이며, 약간의 예측 문제가 있지만, 모델은 데이터의 구조와 구성도 배워야 한다. 문제 예는 분류와 회귀 문제를 포함하며, 알고리즘 예는 기본적으로 감독되지 않은 학습 알고리즘의 확장이다.
증강 학습: 입력 데이터는 모델을 자극하고 모델을 반응하게 한다. 피드백은 감시 학습의 학습 과정에서뿐만 아니라 환경의 보상이나 처벌에서 얻을 수 있다. 문제 예는 로봇 제어이며, 알고리즘 예는 Q-learning 및 Temporal difference learning 을 포함한다.데이터 시뮬레이션 비즈니스 의사결정을 통합할 때, 대부분 감독 학습과 무감독 학습의 방법을 사용한다. 다음으로 인기있는 주제는 반감독 학습이다. 예를 들어, 이미지 분류 문제는, 그 문제에는 큰 데이터베이스가 있지만, 소수의 이미지가 표기된다. 강화 학습은 대부분 로봇 제어 및 기타 제어 시스템의 개발에 사용된다.
-
알고리즘 유사성
알고리즘은 기본적으로 기능적으로 또는 형식으로 분류된다. 예를 들어, 나무 기반의 알고리즘, 신경 네트워크 알고리즘이다. 이것은 매우 유용한 분류 방법이지만 완벽하지 않다. 많은 알고리즘이 두 가지로 쉽게 분류될 수 있기 때문에, 예를 들어, 학습 벡터 양산은 동시에 신경 네트워크 유형의 알고리즘과 인스턴스 기반의 방법이다. 기계 학습 알고리즘 자체에는 완벽한 모델이 없듯이, 알고리즘의 분류 방법도 완벽하지 않다.
이 부분에서는 제가 가장 직관적인 방법으로 분류하는 알고리즘을 나열했습니다. 저는 알고리즘이나 분류 방법을 다 다 써놓지는 않았지만, 독자들에게 대략적인 이해를 돕기 위해 도움이 될 것 같습니다. 제가 나열하지 않은 것을 알고 있다면, 댓글로 공유하십시오. 이제 시작하겠습니다!
-
Regression
Regression는 변수들 사이의 관계에 관심이 있다. 그것은 통계적 방법을 적용한다. 몇 가지 알고리즘의 예는 다음과 같다:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
인스턴스 기반 학습 (instance based learning) 은 어떤 결정 문제를 모의하고, 어떤 사례를 사용하느냐가 모델에 매우 중요하다. 이 방법은 기존의 데이터에 대한 데이터베이스를 구축하고 새로운 데이터를 추가한 다음, 유사성 측정 방법을 사용하여 데이터베이스에서 최적의 매칭을 찾아 예측을 한다. 이러한 이유로, 이 방법은 승자가 왕이라는 방법과 메모리 기반의 방법이라고도 불린다.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
이것은 다른 방법들의 확장이다 (일반적으로 회귀 방법) 이 확장은 더 단순한 모델에 유리하며 더 잘 귀납한다. 나는 여기에 그것을 나열한 것은 그 대중성과 강함 때문이다.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Decision tree methods는 데이터의 실제 값에 따라 결정을 하는 모델을 구축한다. 의사 결정 나무는 통합과 회귀 문제를 해결하는 데 사용됩니다.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
Bayesian method (베이지안 방법) 은 분류 및 회귀 문제를 해결하는 데 베이지안 정리 (Bayesian theorem) 를 적용하는 방법이다.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
커널 메소드 (Kernel Method) 중 가장 유명한 것은 지원 벡터 기계 (Support Vector Machines) 이다. 이 방법은 입력 데이터를 더 높은 차원으로 매핑하고, 일부 분류 및 회귀 문제를 더 쉽게 모델링한다.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
클러스터링 (clustering) 은 문제와 방법을 그 자체로 설명한다. 클러스터링 방법은 일반적으로 모델링 방식에 의해 분류된다. 모든 클러스터링 방법은 통일된 데이터 구조를 사용하여 데이터를 조직하여 각 그룹 내에서 공통점이 가장 많도록 한다.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
협회 규칙 학습 (Association rule learning) 은 데이터 사이의 법칙을 추출하는 데 사용되는 방법이며, 이러한 법칙을 통해 거대한 다차원 공간 데이터 사이의 관계를 발견 할 수 있으며, 이러한 중요한 연결은 조직에서 사용할 수 있습니다.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
인공신경망은 생물학적 신경망의 구조와 기능에서 영감을 얻었다. 그것은 패턴 매칭의 일종이며, 종종 회귀 및 분류 문제에 사용되지만, 수백 가지의 알고리즘과 변형으로 구성되어 있다.
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
딥 러닝 (Deep Learning) 방법은 인공 신경망의 현대적인 업데이트이다. 전통적인 신경망에 비해 더 많은 더 복잡한 네트워크 구성을 가지고 있으며, 많은 방법은 반감독 학습에 관심을 가지고 있으며, 이러한 학습의 문제에는 많은 데이터가 있지만, 그 중 거의 표시된 데이터가 없다.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionality Reduction (차원 감소) 은 집약 방법과 같이 데이터의 통일된 구조를 추구하고 이용하지만, 더 적은 정보를 사용하여 데이터에 대한 회합과 서술을 한다. 이것은 데이터를 시각화하거나 데이터를 단순화하는데 유용하다.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
앙상블 메소드 (Ensemble methods) 는 많은 작은 모델들로 이루어져 있는데, 이 모델들은 독립적으로 훈련되어 독립적인 결론을 내리고, 결국에는 전체적인 예측을 구성한다. 많은 연구들이 어떤 모델을 사용하고 어떻게 이 모델들이 앙상블되어 있는지에 초점을 맞추고 있다. 이것은 매우 강력하고 인기있는 기술이다.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
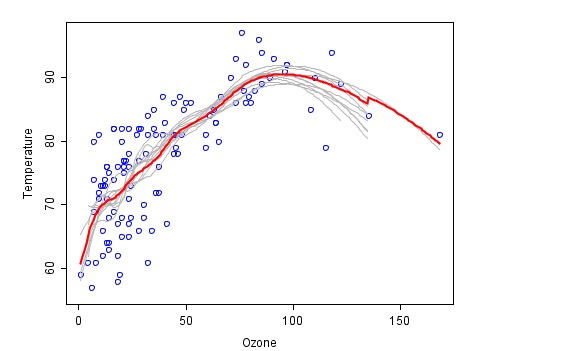
이것은 조합방법으로 합성된 예시입니다. 각 소방법이 회색으로 표시되고, 최종 합성된 최종 예측은 빨간색으로 표시됩니다.
-
다른 자료
이 기계 학습 알고리즘 여행은 어떤 알고리즘과 연관된 알고리즘에 대한 몇 가지 도구에 대한 전반적인 이해를 제공하고자 합니다.
아래는 다른 몇 가지 자료입니다. 너무 많이 생각하지 마십시오. 알고리즘을 더 많이 아는 것이 더 유용하지만 일부 알고리즘에 대한 깊은 지식이 유용합니다.
- Machine Learning Algorithms (기계 학습 알고리즘 목록): 위키에 있는 자료입니다.
- Machine Learning Algorithms Category: 위키에 있는 자료입니다. 위키보다 조금 더 좋은 자료입니다. 알파벳 순으로 분류하세요.
- CRAN Task View: Machine Learning & Statistical Learning: 머신러닝 알고리즘의 R 언어 확장 패키지, 다른 사람들이 사용하는 것을 더 잘 이해하기 위해 보세요.
- Top 10 Algorithms in Data Mining: 이것은 출판된 기사 (Published article), 지금은 책 (book) 으로, 가장 인기있는 데이터 마이닝 알고리즘을 포함하고 있다. 또 다른 기본 알고리즘 목록은, 여기에 나열된 알고리즘은 많지 않아, 더 깊이 학습하는 데 도움이 된다.
이 글은 베를로 칼럼 / 대피 파이썬 개발자에서 가져온 것입니다.
- 1