Стратегия высокочастотной торговли книгой заказов, основанная на машинном обучении
 1
8025
1
8025
Стратегия высокочастотной торговли книгой заказов, основанная на машинном обучении
- ### Первая теория
Торговые механизмы на рынке ценных бумаг можно разделить на две категории: рынок, основанный на предложении, и рынок, основанный на заказах. Первый полагается на то, что рыночные торговцы обеспечивают ликвидность, а второй обеспечивает ликвидность через лимитированные ценные бумаги, сделки формируются путем покупки инвесторов и продажи по порученным ценам.
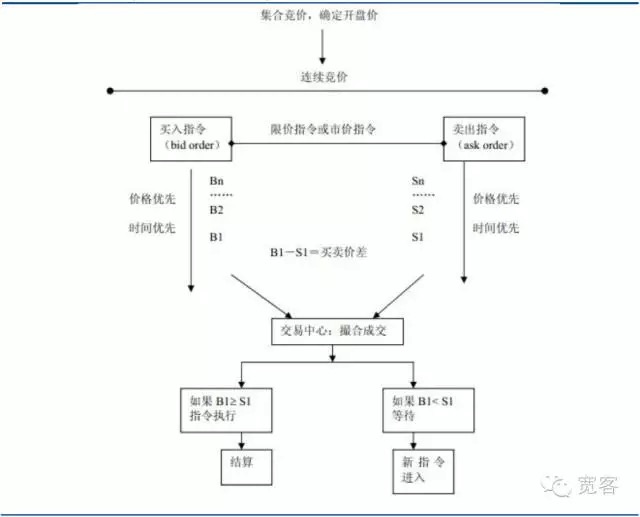 Рисунок 1 - График рынка с заказами
Рисунок 1 - График рынка с заказами
-
(I) Описание книги заказов по ценовым ограничениям
Исследование книги заказов относится к исследованию микроструктуры рынка. Теория микроструктуры рынка основана на теории цен и теории производителей в микроэкономике, а в своем анализе процесса и причин формирования цен на финансовые активы используются различные теории и методы, такие как общее равновесие, локальное равновесие, маржинальная прибыль, маржинальные затраты, непрерывность рынка, теория запасов, теория игр и информационная экономика.
С точки зрения зарубежных исследований, в области микроструктуры рынка, представленной О’Хара, большая часть теорий основана на рыночных рынках (т. е. рынках, управляемых предложением), таких как модели запасов и информационные модели. В этом году, в реальных торговых рынках, заказы постепенно заняли верх, но исследований, направленных на заказы на рынки, было меньше.
Внутренние рынки ценных бумаг и фьючерсные рынки относятся к рынкам, управляемым заказами. На рисунке ниже представлена скриншота счетов заказа Level_1 на фьючерсный контракт IF1312. Недостаточно информации, полученной непосредственно сверху. Основная информация включает в себя цену покупки, цену продажи, количество покупки и количество продажи.
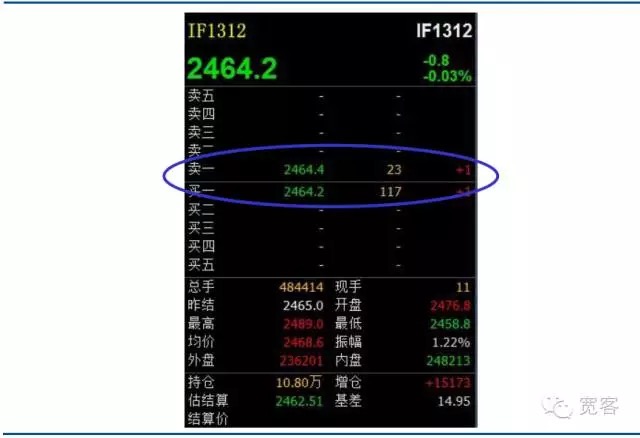 Рисунок 2 Акции Фьючерсные индексы Контракты с преобладанием на уровне-1 Книга заказов
Рисунок 2 Акции Фьючерсные индексы Контракты с преобладанием на уровне-1 Книга заказов -
(ii) Прогресс в исследовании высокочастотных сделок в книге заказов
Динамическое моделирование книг заказов осуществляется двумя основными методами: классическим методом измерения экономики и методом машинного обучения. Метод измерения экономики является классическим методом исследования, например, расщепление MRR для анализа разрыва цен, расщепление Хуанга и Столла, ACD-модели для исследования продолжительности заказов и логистические модели для прогнозирования цен.
Прогнозирование тенденций высокой_частоты KOSPI200 index data using learning classifiers является распространенным исследовательским подходом, использующим общие показатели технического анализа (MA, EMA, RSI и т. Д.) для прогнозирования рынка. Однако эта практика недостаточно извлекает динамическую информацию о книге заказов, то есть исследования, использующие динамическую информацию о книге заказов для проведения высоких продаж, являются менее распространенными в стране и за рубежом. Это поле, которое заслуживает глубокого изучения.
-
Применение машинного обучения в высокочастотных сделках в книге заказов
- #### (a) Карта архитектуры системы
Ниже представлена схема системной архитектуры типичных торговых стратегий машинного обучения, включающая в себя несколько основных модулей: данные книг заказов, обнаружение признаков, создание и проверка моделей и возможности для торговли. Стоит отметить, что процесс торговли инициируется событиями, прибытие которых является одним из них.
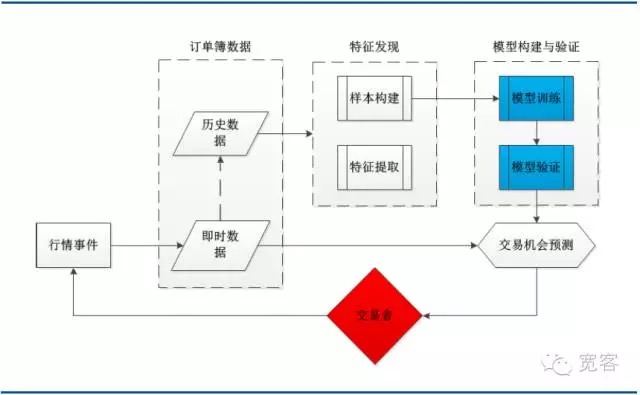 Рисунок 3 Система архитектуры моделирования книги заказов на основе машинного обучения
Рисунок 3 Система архитектуры моделирования книги заказов на основе машинного обучения- #### (II) Описание поддерживаемого вектора
В 1970-х годах Вапник и др. начали создавать более совершенную теоретическую систему статистической теории обучения (SLT), которая используется для исследования статистических закономерностей и характера методов обучения в условиях ограниченной выборки, создает хорошую теоретическую основу для проблем машинного обучения с ограниченной выборкой, лучше решает практические проблемы, такие как небольшая выборка, нелинейность, высокое измерение и локальные минимумы.
SVM развивается из оптимальной классификационной сверхплоскости при линейной делительности. Для вопросов классификации двух классов, набор тренировочных образцов составляет ((xi,yi), i = 1,2…l, l - число тренировочных образцов, xi - тренировочные образцы, yi относится к {-1,+1} - классовой маркировке ввода образца xi ((ожидаемый вывод)). Отправной точкой SVM является поиск оптимальной классификационной сверхплоскости.
Оптимальная классификационная сверхплоскость не только позволяет правильно разделить все образцы, но и позволяет максимально увеличить границу между двумя категориями, которая определяется как сумма минимального расстояния от тренировочного набора данных до этой классификационной сверхплоскости. Оптимальная классификационная сверхплоскость означает минимальную среднюю классификационную ошибку для тестовых данных.
Если в d-мерном векторном пространстве существует гиперплоскость:
F(x)=w*x+b=0
Суперплоскость, способная разделить эти два типа данных, называется интерфейсом.*x {\displaystyle x} - внутреннее поле двух векторов w и x {\displaystyle w} в d-мерном векторном пространстве.
Если интерфейс:
w*x+b=0
Наиболее оптимальным интерфейсом называется интерфейс, находящийся на максимальном расстоянии между двумя наиболее близкими к нему типами проб.
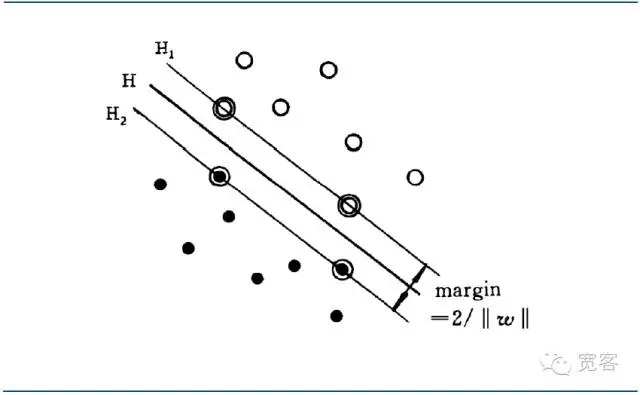 Диаграмма интерфейса SVM
Диаграмма интерфейса SVMИдентификация уравнений оптимального дифференциального интерфейса позволяет сделать расстояние между двумя типами образцов
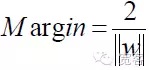
Таким образом, для любой выборки
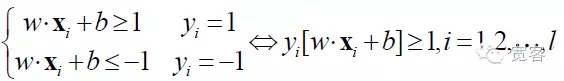
Чтобы получить оптимальный интерфейс, помимо выполнения вышеуказанного формулы, необходимо также его минимизировать.
Таким образом, математическая модель задачи SVM выглядит так:
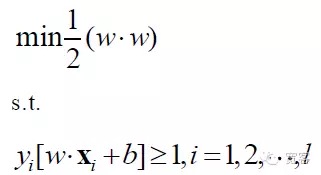
В конечном итоге SVM превратился в наиболее оптимизированную задачу планирования, и в академическом сообществе горячие исследования были сосредоточены в основном на быстром решении, распространении на многоклассные, практические проблемы и т. д.
Первоначально SVM был разработан для решения проблем двойного класса, но в соответствии с требованиями современных практических приложений он был распространен на многоклассные проблемы. Существующие многоклассные алгоритмы включают в себя многопарное, однопарное, корректирующее кодирование, DAG-SVM и классификатор Multi i-class SVM и т. д.
- #### (III) Извлечение показателей книг заказов
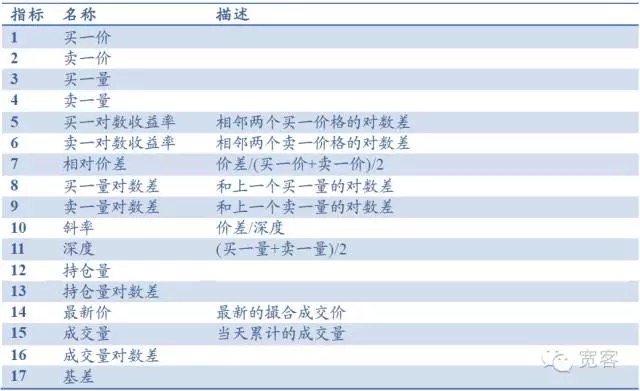
В качестве примера можно взять фьючерсный индекс на уровне 1, в котором основные показатели, такие как цена покупки, цена продажи, количество покупки, количество продажи, и другие показатели, такие как глубина, скольжение, относительная разница в цене, и другие показатели, такие как объем позиций, объем торгов, базовая разница, в общей сложности 17 показателей, как показано в таблице ниже. Также можно ввести показатели технического анализа, такие как RSI, KDJMA, EMA и т. Д.
Таблица 1 База показателей, основанная на книге заказов Level
- #### (iv) Картины динамических характеристик книг заказов и торговые возможности
С точки зрения рыночного микроскопа, существуют два способа измерения движения цены за короткое время, один из которых - средняя динамика цены, а другой - ценовой разрыв. В этой статье выбран более простой и интуитивно понятный средняя динамика цены.
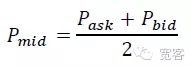
В зависимости от величины изменения средней цены ΔP в Δt в книге заказов, она делится на три категории: взлеты и падения.
На рисунке ниже представлено распределение средней динамики цены на главный контракт IF1311 на 29 октября, с 32400 тиков в день.
В случае Δt=1tick средняя цена изменяется в абсолютных значениях примерно в 6000 раз, в абсолютных значениях примерно в 1500 раз, в абсолютных значениях примерно в 150 раз, в абсолютных значениях больше чем в 50 раз, в абсолютных значениях больше чем в 1 раз, примерно в 10 раз.
В случае Δt=2tick средняя цена изменяется в абсолютных значениях примерно в 7000 раз, в абсолютных значениях примерно в 3000 раз, в абсолютных значениях примерно в 550 раз, в абсолютных значениях примерно в 205 раз, в абсолютных значениях больше 1 примерно в 10 раз.
Мы рассматриваем как потенциальные торговые возможности, если абсолютная величина изменения больше или равна 0,4. В случае Δt = 1 tick, это примерно 1700 возможностей в день; В случае Δt = 2 tick, это примерно 4000 возможностей в день.
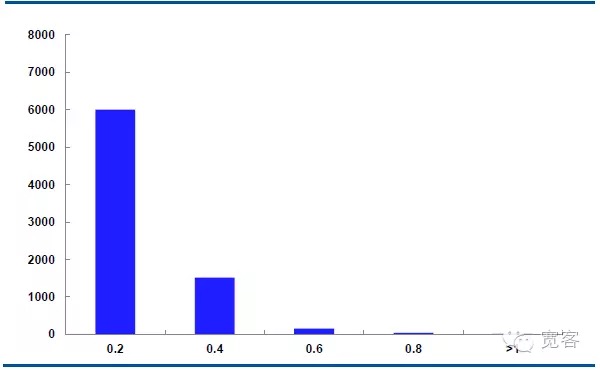
Рисунок 5 IF1311 Распределение средних цен на 29 октября (Δt = 1 tick)
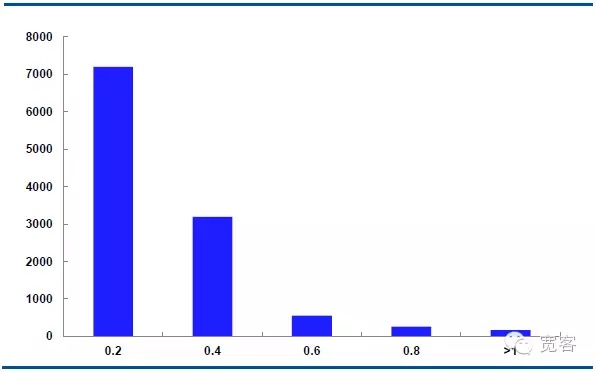
Рисунок 6 IF1311 Распределение средних цен на 29 октября (Δt=2tick)
-
Третье: стратегия и доказательства.
Поскольку модели SVM имеют большую сложность обучения в больших выборках и более длительный период обучения, мы выбрали сравнительно короткий промежуток времени исторических ситуационных данных, чтобы проверить эффективность модели на примере ситуационных данных Level_1 контракта IF1311 в октябре.
-
(a) Эффективность моделирования
Цикл данных: данные о состоянии контрактов IF1311 в октябре;
Δt-оценка: чем меньше Δt, тем больше требований к деталям сделки, когда Δt = 1 tick, в реальной сделке трудно получить прибыль, для сравнения эффективности модели здесь оценена 1 tick, 2 tick, 3 tick;
Показатели оценки модели: точность выборки, точность проверки, время прогнозирования.
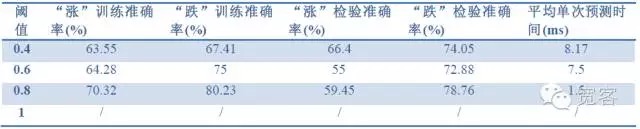 Таблица 2 Прогнозирование эффекта 1 tick с помощью данных 1 tick
Таблица 2 Прогнозирование эффекта 1 tick с помощью данных 1 tick Таблица 3 Прогнозирование эффекта tick2 с данными tick1
Таблица 3 Прогнозирование эффекта tick2 с данными tick1 Таблица 4 Прогнозирование эффекта 2tick с использованием данных 2tick
Таблица 4 Прогнозирование эффекта 2tick с использованием данных 2tickИз данных, представленных в трех таблицах, можно сделать следующие выводы: При максимальной точности около 70%, при точности до 60% можно перевести в торговую стратегию.
-
(ii) Стратегия имитации доходов
Например, 31 октября, мы проводим имитационную торговлю, комиссионные по сделкам с фьючерсами на фондовые индексы, как правило, составляют комиссионные по сделкам с фьючерсами на фондовые индексы, как правило, составляют 0,26⁄10000, и мы предполагаем, что количество сделок не ограничено, что цена на одну сделку колеблется на 0,2 пункта, а количество сделок - на одну руку.
Таблица 5 Аналогичная стратегия на 31 октября

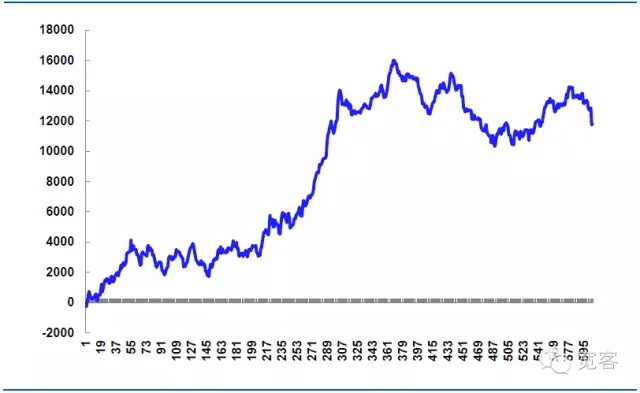
За весь день было совершено 605 сделок, включая процедуры, 339 выигрышей, 56% выигрышей, чистая прибыль 11814,99 юаней.
Теоретическая потеря цены составляет 14520 юаней, что является ключевым элементом стратегии в реальном бою. Если детали заказа контролируются более тщательно, то можно уменьшить потерю цены и повысить чистую прибыль. Если детали заказа не контролируются должным образом или рынок колеблется аномально, потеря цены будет больше, а чистая прибыль будет уменьшена, поэтому успех высокочастотных сделок часто зависит от выполнения деталей.
График 7 Прибыль от аналогичной стратегии на 31 октября
Примечание: В статье содержится информация о том, что в настоящее время в Китае действует запрет на торговлю наркотиками и наркотическими средствами.